Ejercicio: Limpieza y preparación de los datos
Antes de poder preparar un conjunto de datos, tendrá que comprender su contenido y estructura. En el laboratorio anterior, ha importado un conjunto de datos con información sobre la puntualidad de las llegadas de una gran aerolínea de Estados Unidos. Esos datos incluían 26 columnas y miles de filas, y cada fila representa un vuelo y contiene información como el origen del vuelo, el destino y la hora de salida programada. También ha cargado los datos en un cuaderno de Jupyter y ha usado un sencillo script de Python para crear un elemento DataFrame de Pandas a partir de él.
DataFrame es una estructura de datos etiquetada bidimensional. Las columnas de un elemento DataFrame pueden ser de tipos diferentes, como las de una hoja de cálculo o una tabla de base de datos. Es el objeto que más se usa en Pandas. En este ejercicio, examinará con más detalle el elemento DataFrame y los datos que contiene.
Cambie al cuaderno de Azure que ha creado en la sección anterior. Si ha cerrado el cuaderno, puede volver a iniciar sesión en el portal de Microsoft Azure Notebooks, abrir el cuaderno y usar Celda>Ejecutar todo para volver a ejecutar todas las celdas del cuaderno después de abrirlo.
El cuaderno FlightData
El código que ha agregado al cuaderno en el laboratorio anterior crea un elemento DataFrame a partir de flightdata.csv y llama a DataFrame.head en él para mostrar las cinco primeras filas. Uno de los primeros aspectos que normalmente querrá saber sobre un conjunto de datos es cuántas filas contiene. Para obtener un recuento, escriba la instrucción siguiente en una celda vacía al final del cuaderno y ejecútela:
df.shapeConfirme que el elemento DataFrame contiene 11 231 filas y 26 columnas:

Obtención de un recuento de filas y columnas
Ahora, dedique un momento a examinar las 26 columnas del conjunto de datos. Contienen información importante como la fecha en la que se realizó el vuelo (YEAR, MONTH y DAY_OF_MONTH), el origen y el destino (ORIGIN y DEST), las horas de salida y llegada programadas (CRS_DEP_TIME y CRS_ARR_TIME), la diferencia entre la hora de llegada programada y la hora de llegada real expresada en minutos (ARR_DELAY), y si el vuelo se ha retrasado 15 minutos o más (ARR_DEL15).
Esta es una lista completa de las columnas del conjunto de datos. Las horas se expresan en el reloj de 24 horas. Por ejemplo, 1130 es igual a las 11:30 a. m. y 1500 es igual a las 3:00 p.m.
Columna Descripción AÑO El año en el que se realizó el vuelo QUARTER El trimestre en el que se realizó el vuelo (1-4) MES El mes en el que se realizó el vuelo (1-12) DÍA_DEL_MES Día del mes en el que se realizó el vuelo (1-31) DÍA_DE_LA_SEMANA Día de la semana en el que se realizó el vuelo (1= lunes, 2= martes, etc.) UNIQUE_CARRIER Código de la compañía aérea (p. ej., DL) TAIL_NUM Número de cola del avión FL_NUM Número del vuelo ORIGIN_AIRPORT_ID Identificador del aeropuerto de origen ORIGEN Código del aeropuerto de origen (ATL, DFW, SEA, etc.) DEST_AIRPORT_ID Identificador del aeropuerto de destino DEST Código del aeropuerto de destino (ATL, DFW, SEA, etc.) CRS_DEP_TIME Hora de salida programada DEP_TIME Hora de salida real DEP_DELAY Número de minutos de retraso de la salida DEP_DEL15 0 = la salida se ha retrasado menos de 15 minutos, 1 = la salida se ha retrasado 15 minutos o más CRS_ARR_TIME Hora de llegada programada ARR_TIME Hora de llegada real ARR_DELAY Número de minutos de retraso de la llegada del vuelo ARR_DEL15 0 = retraso de menos de 15 minutos en la llegada, 1 = 15 minutos o más de retraso ANULADO 0 = el vuelo no se ha cancelado, 1 = el vuelo se ha cancelado DIVERTED 0 = el vuelo no se ha desviado, 1 = el vuelo se ha desviado CRS_ELAPSED_TIME Duración programada del vuelo, en minutos ACTUAL_ELAPSED_TIME Duración real del vuelo, en minutos DISTANCIA Distancia recorrida en millas
El conjunto de datos incluye una distribución uniforme aproximada de fechas a lo largo del año, lo que es importante, ya que un vuelo desde Minneapolis tiene menos probabilidades de retrasarse debido a nevadas en julio que en enero. Pero este conjunto de datos está lejos de ser "limpio" y estar listo para usarse. Para limpiarlo, se escribirá código de Pandas.
Uno de los aspectos más importantes de la preparación de un conjunto de datos para su uso en Machine Learning consiste en seleccionar las columnas de "característica" que son relevantes para el resultado que se está intentando predecir, al tiempo que se filtran las columnas que no afectan al resultado, que puedan sesgarlo de forma negativa, o bien que puedan generar multicolinealidad. Otra tarea importante es eliminar los valores que faltan, ya sea mediante la eliminación de las filas o columnas que los contienen, o bien reemplazándolos por valores significativos. En este ejercicio, eliminará las columnas extrañas y reemplazará los valores que faltan en las columnas restantes.
Una de las primeras cosas que los científicos de datos suelen buscar en un conjunto de datos son los valores que faltan. Hay una manera fácil de comprobar si hay valores que faltan en Pandas. Para demostrarlo, ejecute el código siguiente en una celda al final del cuaderno:
df.isnull().values.any()Confirme que el resultado es "True", lo que indica que hay al menos un valor que falta en alguna parte del conjunto de datos.

Comprobación de los valores que faltan
El siguiente paso consiste en averiguar dónde están los valores que faltan. Para hacerlo, ejecute el código siguiente:
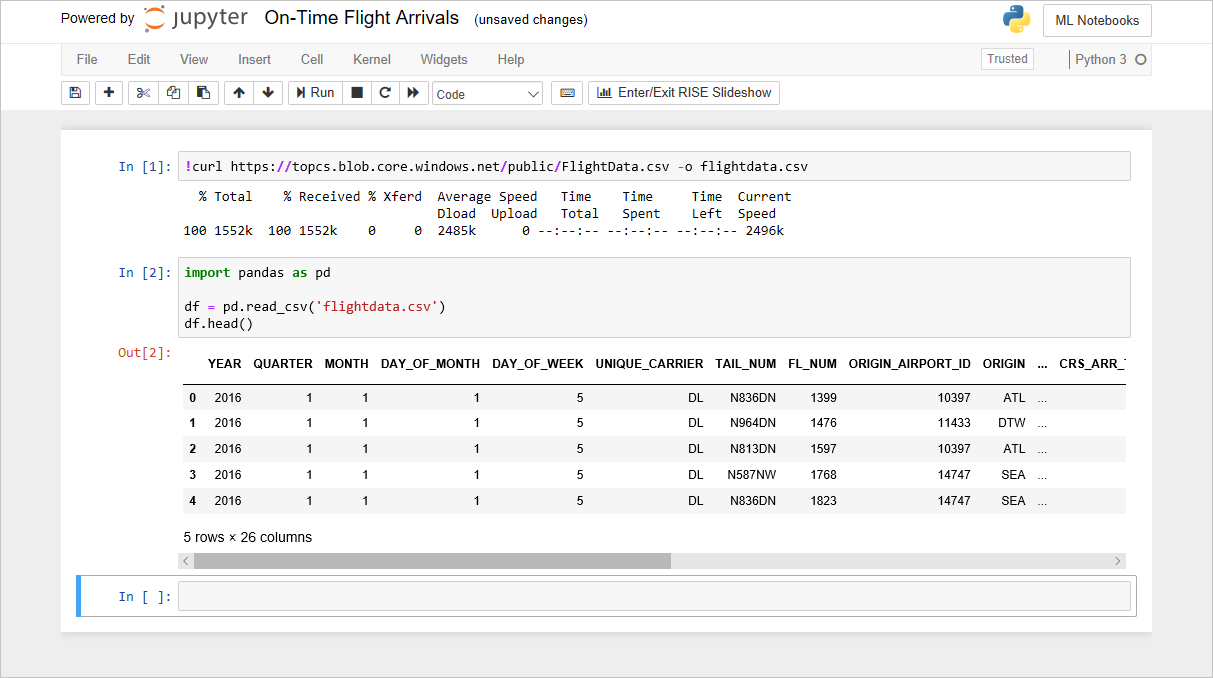
df.isnull().sum()Confirme que ve el resultado siguiente con un recuento de los valores que faltan en cada columna:
Número de valores que faltan en cada columna
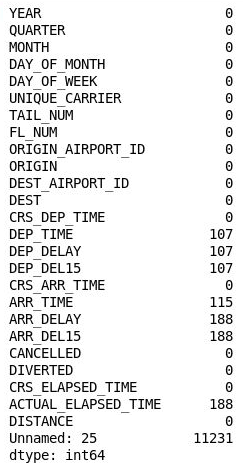
Curiosamente, la columna 26 ("Unnamed: 25") contiene 11 231 valores que faltan, lo que equivale al número de filas del conjunto de datos. Esta columna se ha creado por error porque el archivo CSV que se ha importado contiene una coma al final de cada línea. Para eliminar esa columna, agregue el código siguiente al cuaderno y ejecútelo:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Examine la salida y confirme que la columna 26 ha desaparecido del elemento DataFrame:
El elemento DataFrame con la columna 26 eliminada
El elemento DataFrame todavía contiene una gran cantidad de valores que faltan, pero algunos no son útiles porque las columnas en las que se incluyen no son relevantes para el modelo que se va a generar. El objetivo de ese modelo es predecir si un vuelo que piensa reservar es probable que llegue con puntualidad. Si sabe que es probable que el vuelo se retrase, es posible que elija reservar otro.
Por tanto, el paso siguiente consiste en filtrar el conjunto de datos para eliminar las columnas que no son pertinentes para un modelo predictivo. Por ejemplo, probablemente el número de cola del avión apenas afecte a la puntualidad del vuelo, y en el momento de reservar un billete, no podrá saber si un vuelo se va a cancelar, desviar o retrasar. Por el contrario, la hora de salida programada podría tener mucho que ver con la puntualidad de la llegada. Debido al sistema de concentrador y radio (hub-and-spoke) que usan la mayoría de las líneas aéreas, los vuelos de la mañana suelen ser más puntuales que los que salen por la tarde o la noche. Y en algunos grandes aeropuertos, el tráfico se acumula durante el día, lo que aumenta la probabilidad de que se retrasen los vuelos que salen más tarde.
Pandas proporciona una manera fácil de filtrar las columnas que no quiere. Ejecute el código siguiente en una celda nueva al final del cuaderno:
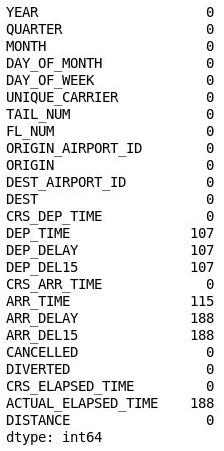
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()En el resultado se muestra que ahora el elemento DataFrame incluye solo las columnas que son pertinentes para el modelo y que el número de valores que faltan se reduce considerablemente:
El elemento DataFrame filtrado
La única columna que ahora contiene valores que faltan es ARR_DEL15, en la que se usan ceros (0) para identificar los vuelos que han llegado puntuales y unos (1) para los que no. Use el código siguiente para mostrar las cinco primeras filas con valores que faltan:
df[df.isnull().values.any(axis=1)].head()Pandas representa los valores que faltan con
NaN, que es el acrónimo de No es un número. En el resultado se muestra que en estas filas realmente faltan valores en la columna ARR_DEL15: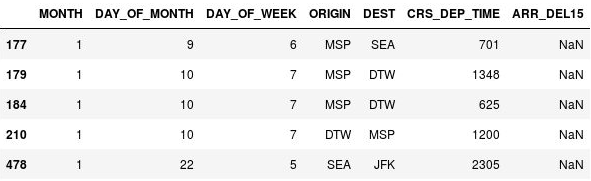
Filas con valores que faltan
El motivo por el que en estas filas faltan valores ARR_DEL15 es que todos ellos se corresponden con vuelos que se han cancelado o desviado. Podría llamar a dropna en el elemento DataFrame para quitar estas filas. Pero como un vuelo que se cancela o desvía a otro aeropuerto se podría considerar "retrasado", se usará el método fillna para reemplazar los valores que faltan con unos.
Use el código siguiente para reemplazar los valores que faltan en la columna ARR_DEL15 con unos y mostrar las filas 177 a 184:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Confirme que los elementos
NaNde las filas 177, 179 y 184 se han reemplazado por unos para indicar que los vuelos han llegado tarde: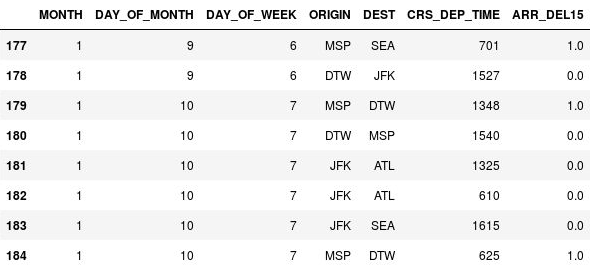
Valores NaN reemplazados por unos
Ahora el conjunto de datos ya está "limpio", en el sentido de que los valores que faltan se han reemplazado y la lista de columnas se ha reducido a las más relevantes para el modelo. Pero todavía no ha terminado. Hay mucho más que hacer para preparar el conjunto de datos para su uso en el aprendizaje automático.
La columna CRS_DEP_TIME del conjunto de datos que usa representa las horas de salida programadas. La granularidad de los números de esta columna (contiene más de 500 valores únicos) podría tener un impacto negativo en la precisión de un modelo de aprendizaje automático. Esto se puede resolver mediante una técnica denominada discretización o cuantificación. ¿Qué ocurre si dividiera cada número de esta columna por 100 y lo redondeara hacia abajo al entero más próximo? 1030 se convertiría en 10, 1925 se convertiría en 19 y así sucesivamente, y se quedaría con un máximo de 24 valores discretos en esta columna. Intuitivamente, tiene sentido, porque probablemente no importa mucho si un vuelo sale a las 10:30 a. m. o a las 10:40 a. m. Importa mucho si sale a las 10:30 a. m. o a las 5:30 p. m.
Además, las columnas ORIGIN y DEST del conjunto de datos contienen códigos de aeropuerto que representan valores de categorías de aprendizaje automático. Estas columnas se deben convertir en columnas discretas que contengan variables de indicador, en ocasiones denominadas variables "ficticias". En definitiva, la columna ORIGIN, que contiene cinco códigos de aeropuerto, se debe convertir en cinco columnas, una por cada aeropuerto, y cada una debe contener unos y ceros que indiquen si un vuelo ha salido del aeropuerto que representa la columna. La columna DEST se debe controlar de forma similar.
En este ejercicio, "discretizará" las horas de salida en la columna CRS_DEP_TIME y usará el método get_dummies de Pandas para crear columnas de indicador a partir de las columnas ORIGIN y DEST.
Use el comando siguiente para mostrar las cinco primeras filas del elemento DataFrame:
df.head()Observe que la columna CRS_DEP_TIME contiene valores de 0 a 2359 que representan el reloj de 24 horas.
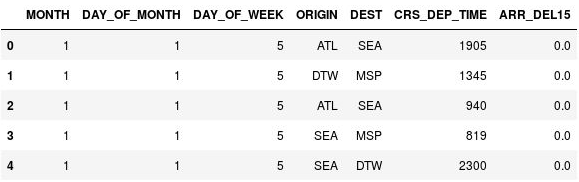
El elemento DataFrame con las horas de salida sin discretizar
Use las instrucciones siguientes para discretizar las horas de salida:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Confirme que los números de la columna CRS_DEP_TIME ahora se encuentran en el intervalo de 0 a 23:
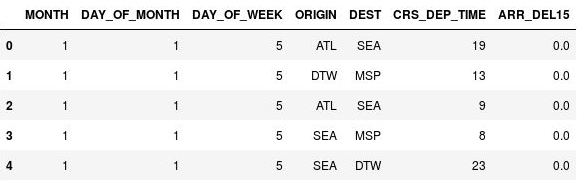
El elemento DataFrame con las horas de salida discretizadas
Ahora puede usar las instrucciones siguientes para generar columnas de indicador a partir de las columnas ORIGIN y DEST, al tiempo que las elimina:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Examine el elemento DataFrame resultante y observe que las columnas ORIGIN y DEST se han reemplazado por columnas que se corresponden con los códigos de aeropuerto presentes en las originales. Las columnas nuevas tienen unos y ceros para indicar si un vuelo concreto ha salido o se dirige al aeropuerto correspondiente.
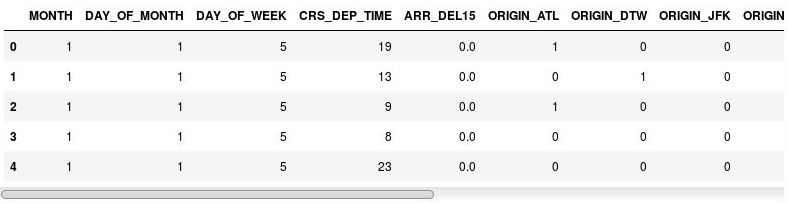
El elemento DataFrame con columnas de indicador
Use el comando Archivo ->Guardar y Punto de control para guardar el cuaderno.
El conjunto de datos tiene un aspecto muy diferente al inicial, pero se ha optimizado para su uso en aprendizaje automático.