Comenzar con Visión de Azure AI
La capacidad de los sistemas informáticos para procesar texto escrito e impreso es un área de la IA, en la cual se mezclan la visión artificial con el procesamiento del lenguaje natural. Las funcionalidades de visión son necesarias para "leer" el texto y, a continuación, las funcionalidades de procesamiento de lenguaje natural le dan sentido.
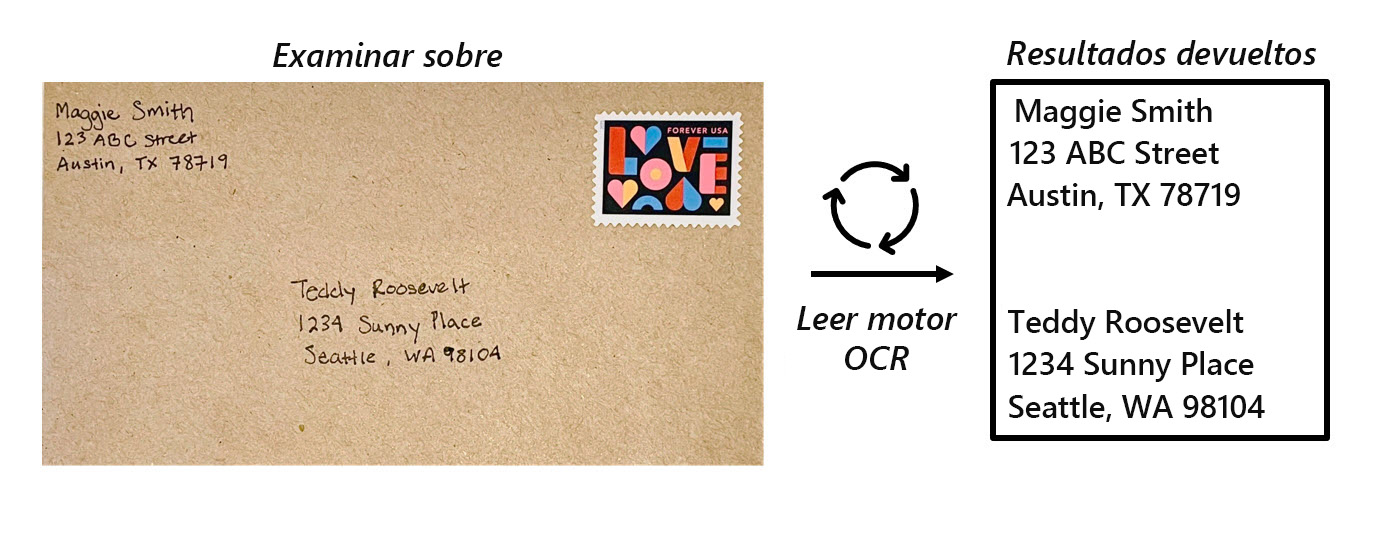
El reconocimiento óptico de caracteres (OCR) es la base del procesamiento de texto en imágenes y usa modelos de Machine Learning entrenados para reconocer formas individuales como letras, números, puntuación u otros elementos de texto. Gran parte del trabajo inicial en la implementación de este tipo de competencia lo llevaron a cabo los servicios postales para respaldar la clasificación automática de correo basado en códigos postales. Desde entonces, la técnica para leer texto ha avanzado y ahora tenemos modelos que detectan texto impreso o escrito a mano en una imagen y que lo leen por renglones y palabra por palabra.
Motor de OCR de Visión de Azure AI
El servicio Visión de Azure AI tiene la capacidad de extraer texto legible por máquina de imágenes. Read API de Visión de Azure AI es el motor de OCR que permite extraer texto de imágenes, archivos PDF y TIFF. El OCR para imágenes está optimizado para imágenes generales, no de documentos, que facilitan la inserción de OCR en escenarios de experiencia de usuario.
Read API, también conocida como motor Read OCR, usa los últimos modelos de reconocimiento y está optimizada para imágenes que tienen una cantidad significativa de texto o un ruido visual considerable. Puede determinar automáticamente el modelo de reconocimiento adecuado que se debe usar, en función del número de líneas de texto, imágenes que incluyen texto y escritura a mano.
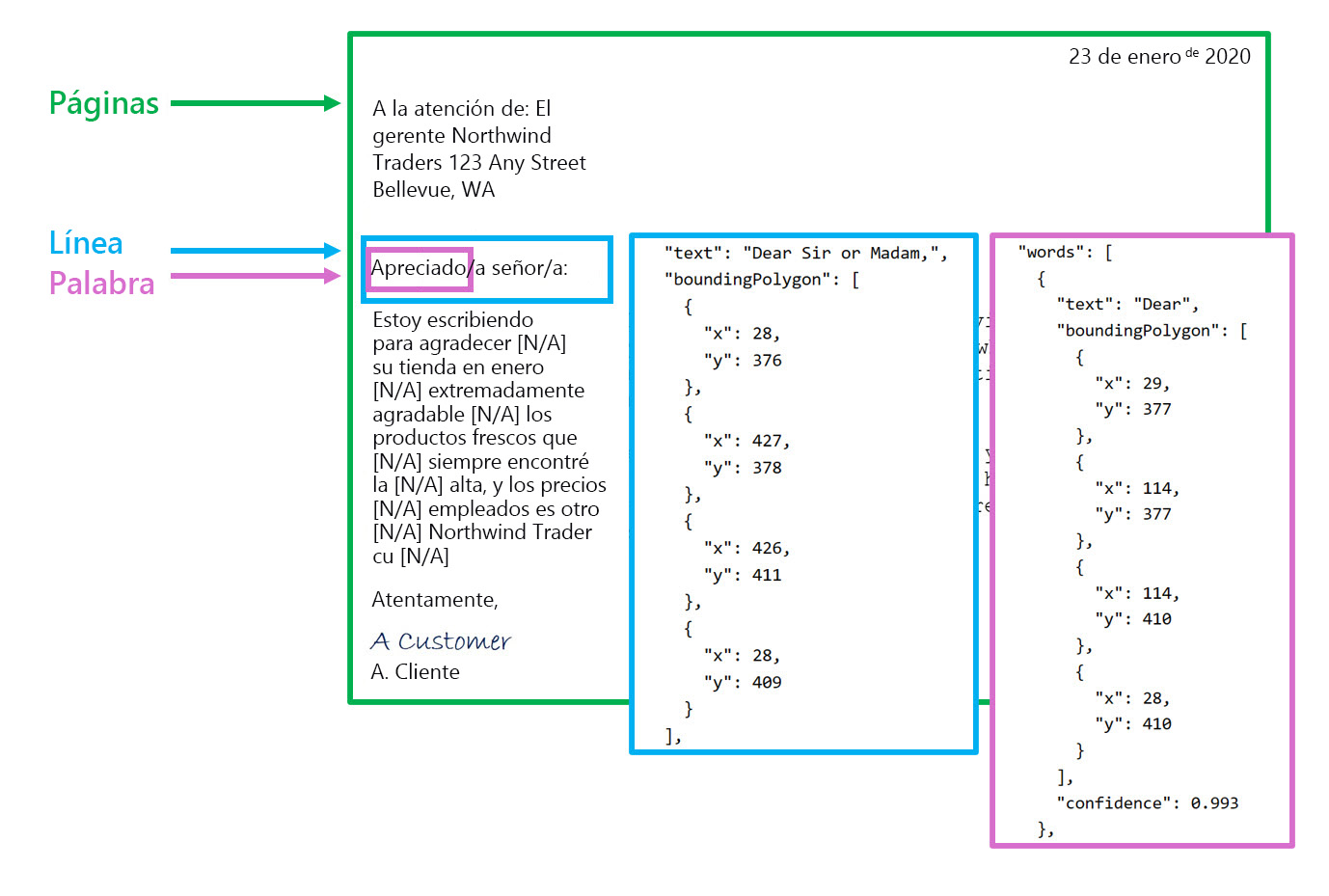
El motor de OCR toma un archivo de imagen e identifica los cuadros de límite, o las coordenadas, donde se encuentran los elementos dentro de una imagen. En OCR, el modelo identifica los cuadros de límite alrededor de todo lo que parezca texto en la imagen.
Al llamar a Read API, se devuelven los resultados organizados en la siguiente jerarquía:
- Páginas: un resultado por cada página de texto, con información sobre el tamaño y la orientación de la página.
- Líneas: las líneas de texto de una página.
- Palabras: palabras de una línea de texto, incluidas las coordenadas del cuadro de límite y el propio texto.
Cada línea y palabra incluye coordenadas de cuadro de límite que indican su posición en la página.