Acerca de los discos compartidos de Azure
Supongamos que quiere migrar muchos servidores que ejecutan cargas de trabajo en clúster de la red local a Azure. Puede crear discos compartidos de Azure y conectarlos a varias máquinas virtuales simultáneamente.
Los discos compartidos de Azure ofrecen almacenamiento en bloque compartido basado en la nube. Este almacenamiento compartido admite aplicaciones en clúster basadas tanto en Windows como en Linux.
Azure muestra un disco compartido como un número de unidad lógica (LUN) a la máquina virtual de destino, que lo usa como almacenamiento conectado directamente.
Las aplicaciones que usan discos compartidos de Azure usan un estándar de reserva persistente SCSI (SCSI PR) para habilitar la conmutación por error de un nodo a otro. Las máquinas virtuales del clúster pueden leer o escribir en el disco conectado, en función de la reserva elegida de la aplicación en clúster que usa SCSI PR.
Nota:
SCSI PR es un estándar del sector que usan las aplicaciones que se ejecutan en redes de área de sistema (SAN) locales.
Los discos compartidos de Azure se usan para ejecutar bases de datos en clúster, sistemas de archivos paralelos, volúmenes de contenedores persistentes y aplicaciones de aprendizaje automático.
Características de los discos compartidos de Azure
Los discos compartidos de Azure se crean como discos administrados. Un disco administrado es un disco duro virtual para el que Azure administra toda la infraestructura física necesaria. Como Azure se ocupa de la complejidad subyacente, los discos administrados son fáciles de usar. Basta con configurarlo y asociarlo a las máquinas virtuales.
Los discos compartidos de Azure están disponibles en los siguientes tipos de disco:
- Discos Ultra. Estos discos ofrecen un alto rendimiento, un elevado número de operaciones de E/S por segundo (IOPS) y almacenamiento en disco coherente de baja latencia para máquinas virtuales de infraestructura como servicio (IaaS) de Azure. Mediante el uso de discos Ultra, puede cambiar dinámicamente el rendimiento de un disco sin reiniciar las máquinas virtuales. Los discos Ultra tienen el rendimiento más rápido de Azure y latencias inferiores a milisegundos. Son escalables a 64 tebibytes (TiB).
- SSD prémium v2 ofrece mayor rendimiento que el SSD prémium y, en general, es menos costoso. Puede ajustar individualmente el rendimiento de SSD prémium v2 en cualquier momento, lo que permite que sus cargas de trabajo sean más rentables.
- SSD prémium (P15 y superiores). Los discos SSD prémium cuentan con el respaldo de unidades de estado sólido (SSD). Ofrecen compatibilidad con los discos de alto rendimiento y latencia baja para máquinas virtuales que ejecutan cargas de trabajo con muchas operaciones de E/S.
- Los SSD estándar están optimizados para cargas de trabajo que necesitan un rendimiento coherente en niveles inferiores de IOPS que SSD prémium o SSD prémium v2.
En el caso de los discos SSD prémium y SSD estándar, el tamaño del disco define el número máximo de usos compartidos, que no puede ser superior a 10. Cada disco tiene un valor maxShares que representa el número máximo de nodos que puede compartir simultáneamente.
Ultra Disks y SSD prémium v2 no tienen restricciones de tamaño. El valor máximo de la opción maxShares es 5.
Nota:
Los discos compartidos de Azure solo se pueden compartir como discos de datos, no como discos del sistema operativo.
Escenarios de casos de uso de los discos compartidos de Azure
Los discos compartidos de Azure ofrecen flexibilidad para migrar entornos en clúster locales que se ejecutan Windows o Linux. Las aplicaciones que se ejecutan en instancias de Windows Server pueden usar el servicio de clúster de conmutación por error para controlar la operación de lectura y escritura de los discos compartidos de Azure.
Escenario de clúster de conmutación por error
En un escenario de clúster de conmutación por error, se usan varias máquinas virtuales para acceder a un disco compartido de Azure. Una de las máquinas virtuales actúa como nodo principal y lee y escribe en el disco. Las demás máquinas virtuales actúan como nodos secundarios. Si el nodo principal pierde el acceso al disco, los nodos secundarios pueden asumir las operaciones de lectura y escritura. Un escenario de caso de uso común que emplea un clúster de conmutación por error con el modo activo/pasivo es una base de datos en clúster, como una instancia de clúster de conmutación por error (FCI) de SQL Server.
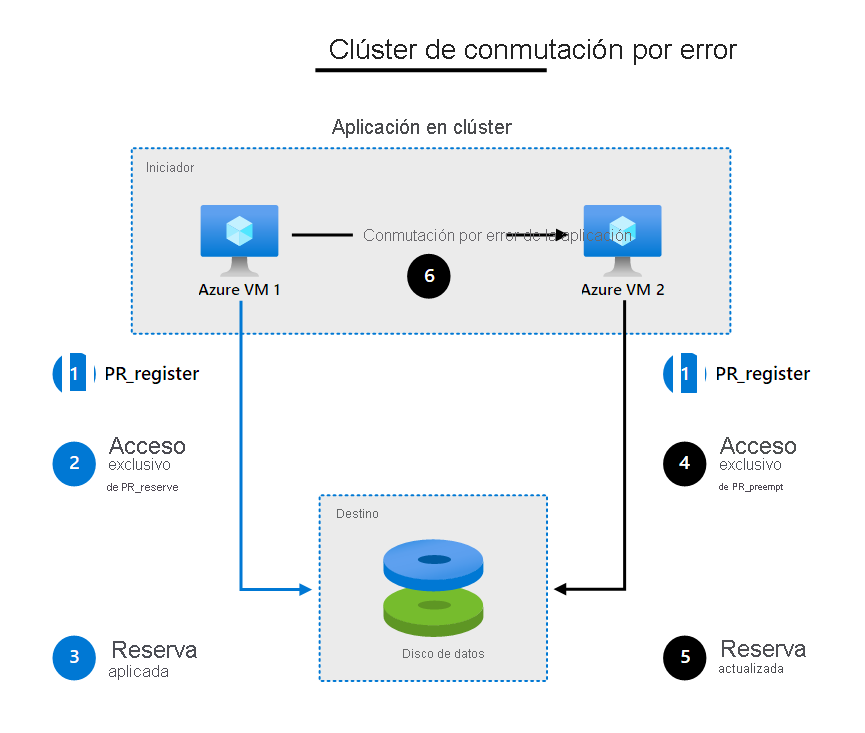
Para que entienda cómo funcionan los discos compartidos, veamos el siguiente ejemplo paso a paso:
- La aplicación en clúster que se ejecuta en las máquinas virtuales usa el protocolo SCSI PR para registrar su intención de lectura o escritura en el disco. En este paso, cada máquina virtual lee información en el destino sobre las reservas y los registros existentes.
- La instancia de la aplicación en VM1 toma una reserva exclusiva para escribir en el disco.
- Después de aplicar esa reserva, solo VM1 puede escribir en el disco. Esta acción impide que otras máquinas virtuales escriban en el disco al mismo tiempo.
- Si la instancia de la aplicación en VM1 se queda sin servicio, VM2 emite un comando de priorización y anulación y asume el control del disco.
- La reserva para escribir ahora se aplica en VM2 y las demás máquinas virtuales no pueden escribir en el disco.
- Las aplicaciones que se estaban ejecutando en VM1 ahora conmutan por error a VM2.
Instancia de clúster de conmutación por error de SQL Server
Puede crear una FCI de SQL Server mediante dos o más máquinas virtuales de Microsoft Azure. Para lograr una alta disponibilidad, use discos SSD prémium que admitan conjuntos de disponibilidad y grupos con ubicación por proximidad. Como alternativa, puede usar discos Ultra que incluyan compatibilidad con zonas de disponibilidad. Debe usar discos compartidos de Azure para almacenar directorios de datos de FCI de SQL Server. También puede implementar franjas en varios discos compartidos si crea un bloque de almacenamiento compartido.
Nota:
Los conjuntos de disponibilidad y los grupos de ubicación por proximidad no son necesarios para implementar una FCI de SQL Server con un disco compartido. Se usan para aumentar la disponibilidad y el rendimiento de la FCI de SQL Server.
ASCS/SCS de SAP
Los servidores de aplicaciones de SAP usan discos compartidos en clúster para colocar los archivos de ASCS/SCS de SAP y los archivos de host global de SAP. Puede implementar aplicaciones de SAP tanto en Windows como en Linux.
La agrupación en clústeres de conmutación por error con máquinas virtuales de Azure requiere pasos adicionales de configuración. Al crear un clúster, debe configurar varias direcciones IP y nombres de host virtual para la instancia de ASCS/SCS de SAP. Puede implementar opciones de identificador de seguridad (SID) único y múltiple para ASCS/SCS de SAP. Solo puede usar discos SSD prémium como discos compartidos de Azure para una instancia de ASCS/SCS de SAP.
Servidores de archivos
Los servidores de archivos para uso general pueden usar el disco compartido para habilitar la alta disponibilidad para el rol de servicio de archivos. También puede usar las características del Servidor de archivos de escalabilidad horizontal implementado en un clúster de conmutación por error de Windows Server, que usa discos compartidos de Azure en modo activo/activo. Los recursos del testigo de clúster se almacenan en discos compartidos de Azure. Todos los recursos compartidos de archivos se encuentran en línea en todos los nodos de forma simultánea.
Use una plantilla de Azure Resource Manager (plantilla de ARM) para implementar un clúster de Servidor de archivos de escalabilidad horizontal de Windows Server 2019 con discos compartidos de Azure.
Aplicaciones distribuidas con requisitos de lectura múltiple o escritura múltiple
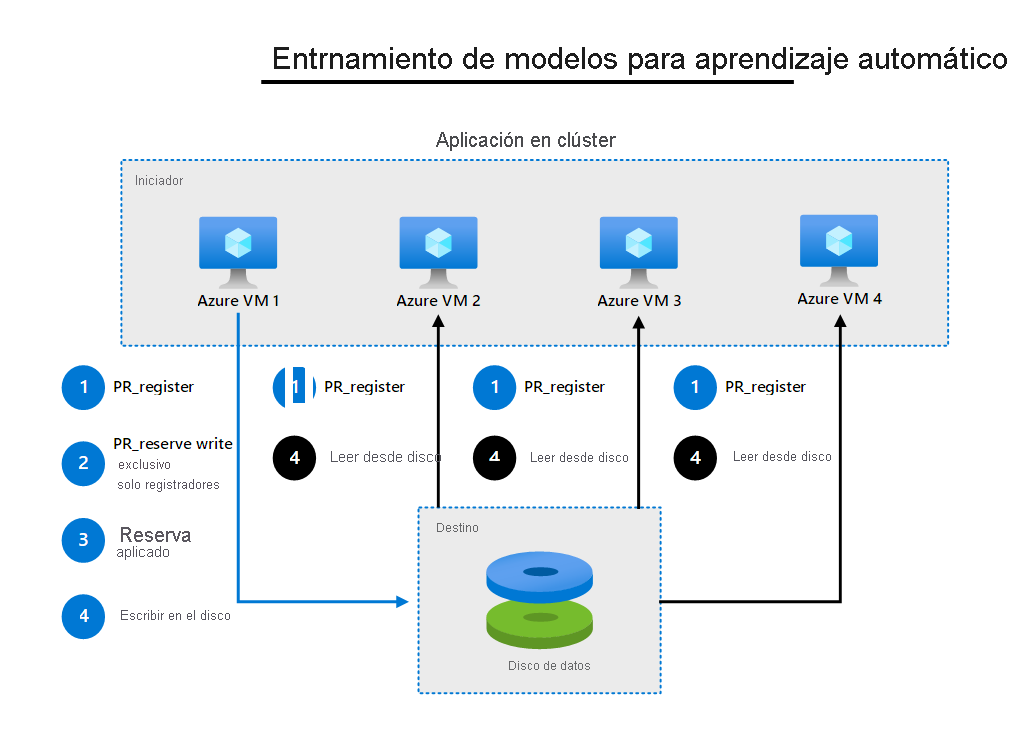
La aplicación en clúster que se ejecuta en varias máquinas virtuales puede acceder al disco compartido de Azure mediante la estrategia de "una sola escritura y varias lecturas". Una máquina virtual tiene una reserva exclusiva para escribir en el disco compartido mediante la reserva persistente SCSI. Mientras tanto, otras máquinas virtuales pueden leer simultáneamente desde el disco. Solo un nodo escribe resultados en el disco para todos los nodos de clúster.
En el diagrama siguiente se muestra otra carga de trabajo en clúster común. Consta de varios nodos que leen los datos de un disco para ejecutar procesos paralelos.
Nota:
También puede habilitar un escenario de escritura múltiple. Aun así, este escenario requiere que las aplicaciones puedan escribir.
Agrupación en clústeres en Linux
Los clústeres de Linux pueden usar administradores de clústeres como Pacemaker con compatibilidad con sistemas de archivos en clúster comunes, como ocfs2y gf2.
Los siguientes clústeres de Linux admiten discos compartidos de Azure:
- SUSE Linux Enterprise Server (SLES) para SAP
- Ubuntu 18.04 y versiones posteriores
- Versión preliminar para desarrolladores de Red Hat Enterprise Linux (RHEL) en cualquier versión de RHEL 8
- Oracle Enterprise Linux
SLES para SAP
Use la distribución de SLES con discos compartidos de Azure para crear una de las siguientes opciones:
- Un servidor de Network File System (NFS) activo/pasivo.
- Un sistema de archivos de Oracle Cluster File System versión 2 (OCFS2) activo/activo.
Puede controlar el acceso al disco compartido mediante SCSI PR o mediante el dispositivo de bloqueo STONITH (SBD). La agrupación en clústeres en SLES usa un guardián para el restablecimiento del dispositivo. También puede implementar el guardián en un disco compartido de Azure.
Para obtener información detallada sobre cómo crear SLES para SAP, consulte Discos compartidos de Azure con "SLES para SAP/alta disponibilidad de SLE 15 SP2".
Alta disponibilidad de Ubuntu
Los clústeres de Ubuntu usan Pacemaker como administrador de clústeres que se ejecuta sobre Corosync Cluster Engine. Controle la coherencia entre varios recursos de clúster mediante una de las siguientes opciones de barrera:
- SCSI PR
- SBD
De forma similar a SLES, un pequeño modelo de kernel de Linux denominado softdog controla el acceso al disco compartido. Puede implementar tanto un clúster activo/pasivo como un clúster activo/activo. Aun así, para el clúster activo/activo, también es necesario un administrador de bloqueos distribuidos (DLM).
Clúster de RHEL con discos compartidos
Puede usar un disco compartido como almacenamiento en bloque compartido para un clúster de alta disponibilidad de RHEL. Las aplicaciones en clúster que se ejecutan en máquinas virtuales de alta disponibilidad de RHEL acceden al mismo dispositivo de almacenamiento en cada servidor de un clúster mediante Global File System 2 (GFS2). Use Pacemaker para la administración de clústeres, Corosync para las comunicaciones de los miembros y STONITH para la integridad de los datos y las barreras.
Para obtener información detallada sobre cómo crear un clúster de RHEL con discos compartidos, consulte la documentación de Red Hat Enterprise Linux para RHEL 7.9 o RHEL 8.3 y versiones posteriores.
Uso de discos compartidos de Azure en contenedores
Las aplicaciones que se ejecutan en Azure Kubernetes Service (AKS) pueden usar el almacenamiento persistente en discos compartidos de Azure. El archivo YAML del manifiesto debe contener la opción devicePath, en lugar de mountPaths. Esta opción permite que las instancias de contenedor usen el sistema de archivos montado.
Nota:
La característica de disco compartido solo admite dispositivos de bloqueo sin formato. Las aplicaciones de Kubernetes deben administrar la coordinación y el control de las escrituras, las lecturas, los bloqueos, las cachés, los montajes y las barreras en el disco compartido, que se expone como un dispositivo de bloqueo sin formato.