Descripción de Apache HBase
Apache HBase es una base de datos NoSQL de código abierto que se basa en Apache Hadoop. HBase proporciona acceso aleatorio y alta coherencia para grandes cantidades de datos no estructurados y semiestructurados en una base de datos sin esquemas organizada por familias de columnas. Los clústeres de HBase de HDInsight 4.0 ofrecen Apache HBase 2.1.6 y Apache Phoenix 5.
Desde la perspectiva del usuario, HBase es similar a una base de datos. Los datos se almacenan en las filas y las columnas de una tabla, mientras que los datos de una fila se agrupan por familia de columnas. HBase es una base de datos sin esquemas en el sentido de que no es preciso que ni las columnas ni el tipo de datos almacenados en ellas se definan antes de usarlos. El código abierto se escala linealmente para controlar petabytes de datos en miles de nodos.
HBase tiene las siguientes características que lo hacen único
Lectura y escrituras coherentes
Operaciones de baja latencia
Particionamiento automático
Conmutaciones por error del servidor de regiones automáticas
Integración de Hadoop/HDFS/MapReduce
API de cliente de Java
Admite Thrift y REST para front-ends distintos de Java
Bloquea caché y filtros Bloom
HBase de Azure HDInsight con Apache Phoenix aporta las siguientes ventajas adicionales:
SQL y ninguna interfaz de SQL
Planeamiento de capacidad flexible
Distribución y replicación globales con redes de Azure
Separación de proceso y almacenamiento
Integración estrecha con las características de seguridad de la empresa de HDInsight
Escrituras aceleradas de HBase de HDInsight para lecturas y escrituras de latencia ultra bajas
Apache Phoenix para SQL en tiempo real como consultas
El uso de HDInsight de Azure con HBase le permite ejecutar bases de datos NoSQL a gran escala. Como Ingeniero de datos de un Contoso, debe ser capaz de ejecutar puntos de referencia para comprender el rendimiento y la escala de HBase de HDInsight antes de usar la plataforma para escenarios de producción de misión crítica.
HBase en HDInsight se ejecuta con la separación del proceso y el almacenamiento. Los clústeres de HDInsight HBase están configurados para almacenar datos directamente en Azure Storage, lo que proporciona una baja latencia y una mayor elasticidad en las opciones de rendimiento y costos. Esta propiedad permite a los clientes crear sitios web interactivos que funcionan con grandes conjuntos de datos, Crear servicios que almacenen datos de sensores y telemetría de millones de puntos de conexión y analizar estos datos con trabajos de Hadoop. HBase y Hadoop son buenos puntos iniciales para proyectos de macrodatos de Azure. Los servicios pueden permitir que las aplicaciones en tiempo real trabajen con grandes conjuntos de datos. Las implementaciones de HBase de HDInsight usan una arquitectura de escalabilidad horizontal de HBase para proporcionar particionamiento automático de tablas. También proporciona una gran coherencia para las lecturas y escrituras y la conmutación automática por error. Se mejora el rendimiento mediante el almacenamiento en caché de memoria para lecturas y streaming de alto rendimiento para escrituras. Se puede crear un clúster de HBase dentro de la red virtual. Para obtener detalles, consulte Creación de clústeres de HDInsight en Azure Virtual Network.
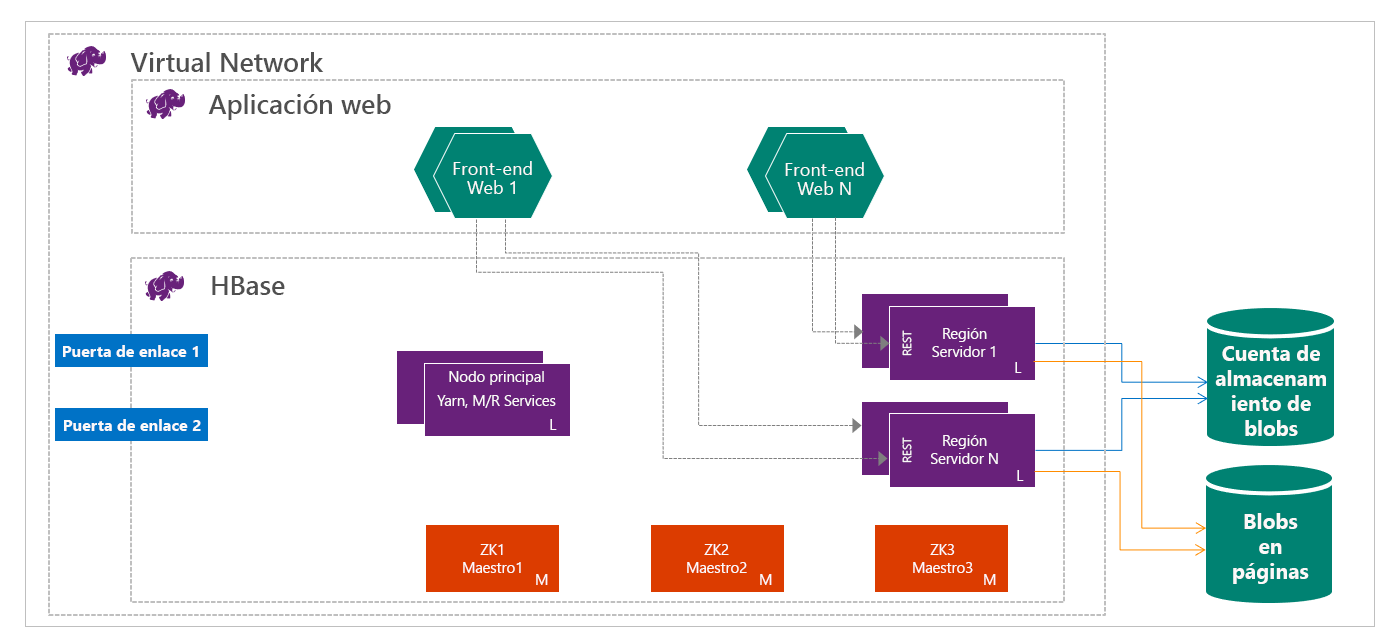
Como ingeniero de datos, debe determinar el tipo más adecuado de clúster de HDInsight que se va a crear para compilar la solución. Usará los clústeres de HBase en HDInsight para una base de datos NoSQL que se escale linealmente, logrando un rendimiento extraordinario, y que proporcione lecturas de baja latencia y almacenamiento ilimitado a una fracción del costo.
Estos son los escenarios clave para el uso de HBase en HDInsight.
almacén de pares clave-valor
HBase se utiliza normalmente como almacén de valores clave y es adecuado para la administración de sistemas de mensajes.
datos del sensor
HBase es útil para capturar datos que se recopilan de forma incremental desde diversos orígenes, lo que incluye análisis social, series temporales, mantenimiento de paneles interactivos con tendencias y contadores y administración de sistemas de registro de auditoría.
consulta en tiempo real
Apache Phoenix es un motor de consultas SQL para Apache HBase. Se obtiene acceso a él como controlador de JDBC y permite consultar y administrar tablas de HBase usando SQL.
HBase como plataforma
Las aplicaciones pueden ejecutarse en de HBase usándolo como almacén de datos. Entre los ejemplos se incluyen Phoenix, OpenTSDB, Kiji y Titan. Las aplicaciones también pueden integrarse con HBase. Algunos ejemplos son Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia y Apache Drill.
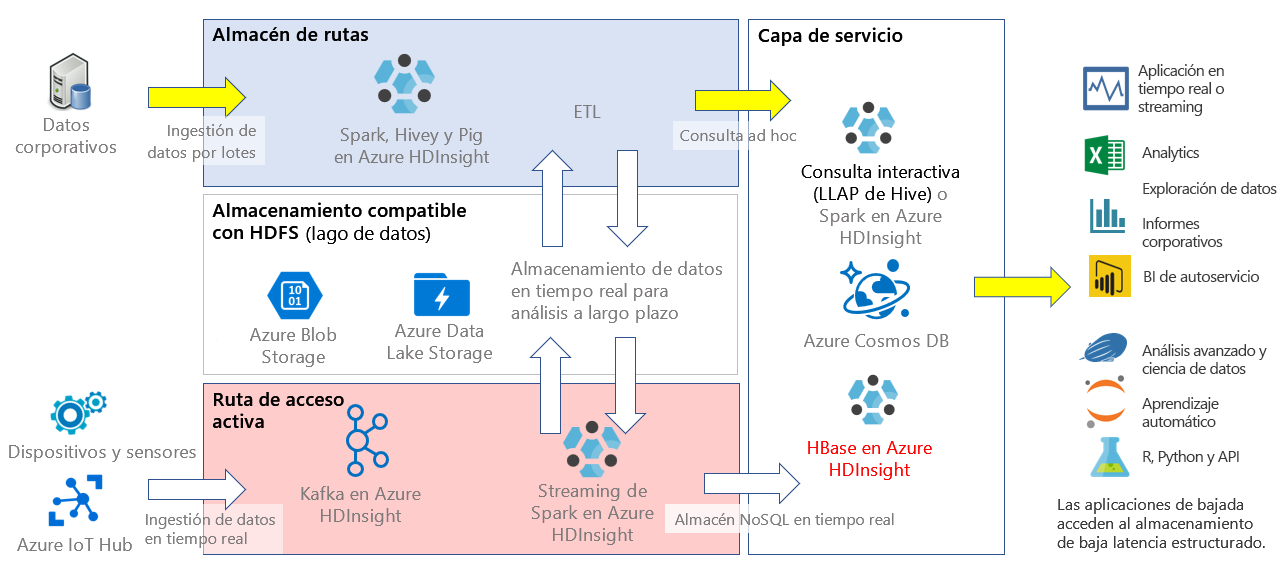
En HDInsight, HBase se puede usar como aplicación independiente o implementarse junto con otras aplicaciones de análisis de macrodatos como Spark, Hadoop, Hive o Kafka.
El modelo de datos de HBase almacena datos semiestructurados con distintos tipos de datos, tamaño de columna y tamaño de campo diferentes. El diseño del modelo de datos de HBase facilita la distribución y la creación de particiones de datos en el clúster. El modelo de datos de HBase consta de varios componentes lógicos: claves de fila, familia de columnas, nombre de tabla, marca de tiempo, etc.
Una clave de fila se usa para identificar de forma única las filas de las tablas de HBase. En HDInsight, puede escribir los datos en HBase directamente mediante varias API disponibles, como REST de HBase, RPC de HBase, Phoenix Query Server, la carga masiva de HBase, o bien usar la integración con varios marcos de macrodatos, como Apache Spark, Hive, etc.
Puede aprovechar la característica de escrituras aceleradas de HBase para habilitar un alto rendimiento de escritura. Para obtener más información acerca de la arquitectura de HBase y los procedimientos recomendados, consulte el Libro de HBase.