Realización de puntos de referencia en HBase
The Yahoo! Cloud Serving Benchmark (YCSB) es un conjunto de programas y especificaciones de código abierto para evaluar el rendimiento relativo de los sistemas del administrador de base de datos NoSQL. En este ejercicio, ejecutará el punto de referencia para el rendimiento de dos clústeres de HBase, uno de los cuales usa la característica de escritura acelerada. La tarea es comprender las diferencias de rendimiento entre las dos opciones. Requisitos previos de los ejercicios
Si desea realizar los pasos del ejercicio, asegúrese de que tiene lo siguiente:
- Suscripción de Azure con autorización para crear un clúster de HBase de HDInsight.
- Acceso a un cliente SSH como Putty (Windows) /Terminal(Mac book)
Aprovisionamiento de un clúster de HDInsight HBase con Portal de administración de Azure
Para aprovisionar HBase de HDInsight con la nueva experiencia en el Portal de administración de Azure, realice los pasos siguientes.
Vaya a Azure Portal. Inicie sesión con las credenciales de su cuenta de Azure.
Comenzaremos por crear una cuenta de almacenamiento Premium de blob en bloques. En la página Nuevo, haga clic en Cuenta de almacenamiento.
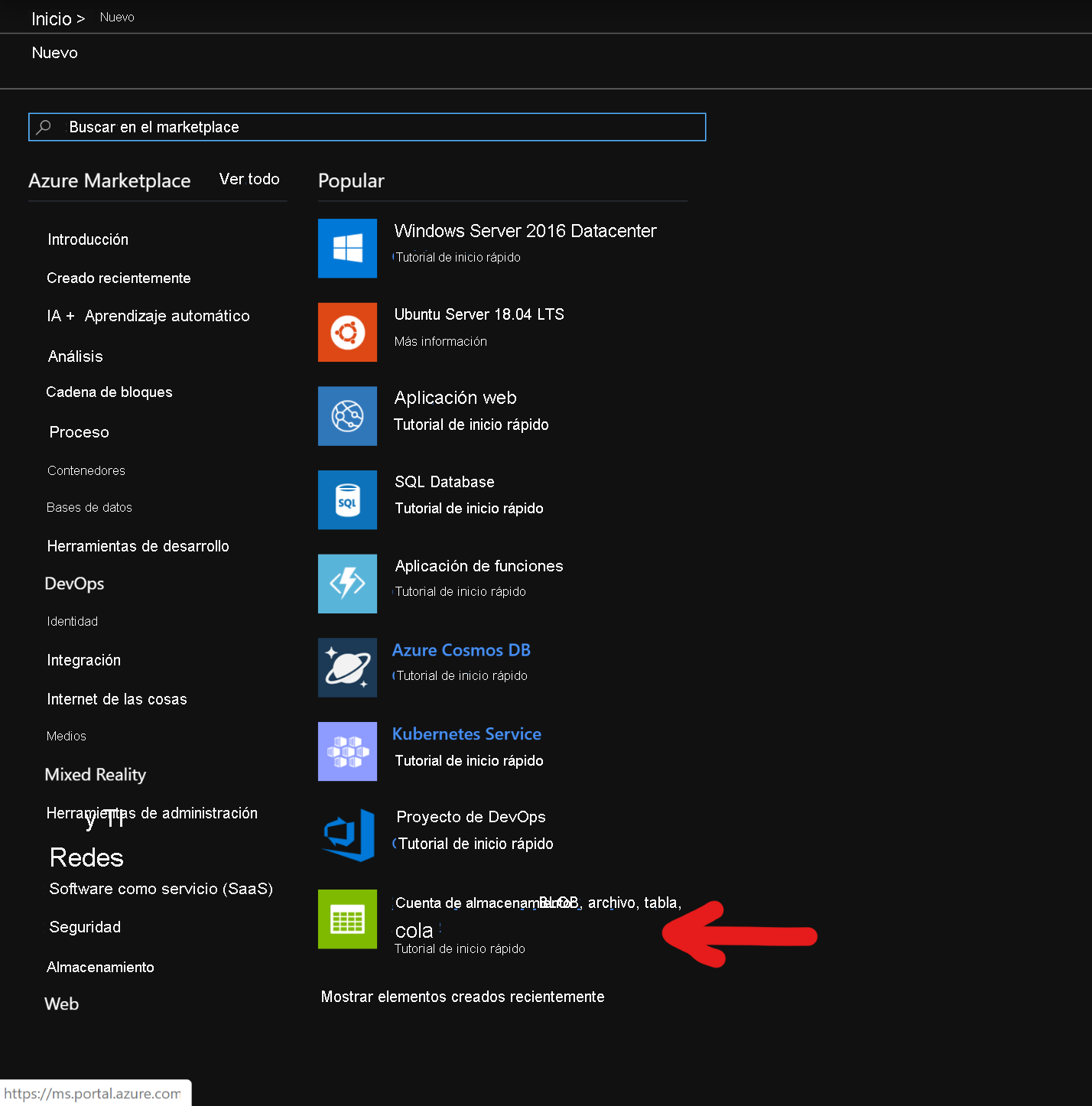
En la página Crear cuenta de almacenamiento, rellene los campos siguientes
Suscripción: debe rellenarse automáticamente con los detalles de la suscripción
Grupo de recursos: escriba un grupo de recursos para almacenar la implementación de HBase de HDInsight
Nombre de la cuenta de almacenamiento: escriba un nombre para la cuenta de almacenamiento que se usará en el clúster Premium.
Región: escriba el nombre de la región de implementación (asegúrese de que el clúster y la cuenta de almacenamiento estén en la misma región)
Rendimiento: Premium
Tipo de cuenta: BlockBlobStorage
Replicación: Almacenamiento con redundancia local (LRS)
Nombre de usuario del registro del clúster: escriba el nombre de usuario del administrador de clústeres (predeterminado: admin)
Deje las demás pestañas en el valor predeterminado y haga clic en Revisar y crear para crear la cuenta de almacenamiento.
Una vez creada la cuenta de almacenamiento, haga clic en claves de acceso a la izquierda y copie key1. Lo utilizaremos más adelante en el proceso de creación del clúster.
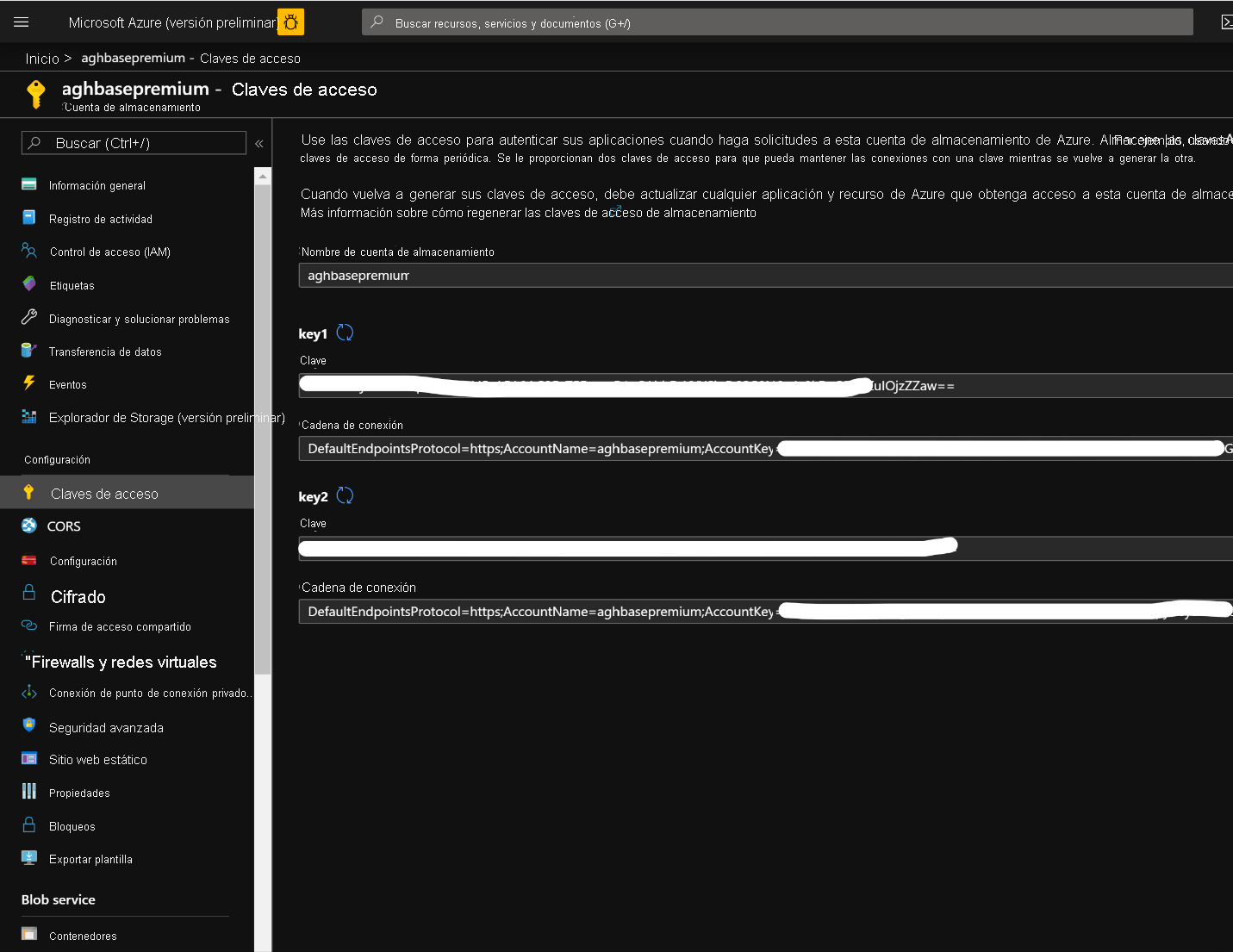
Ahora, empiece a implementar un clúster de HBase de HDInsight con escrituras aceleradas. Seleccione Crear un recurso -> Análisis -> HDInsight.
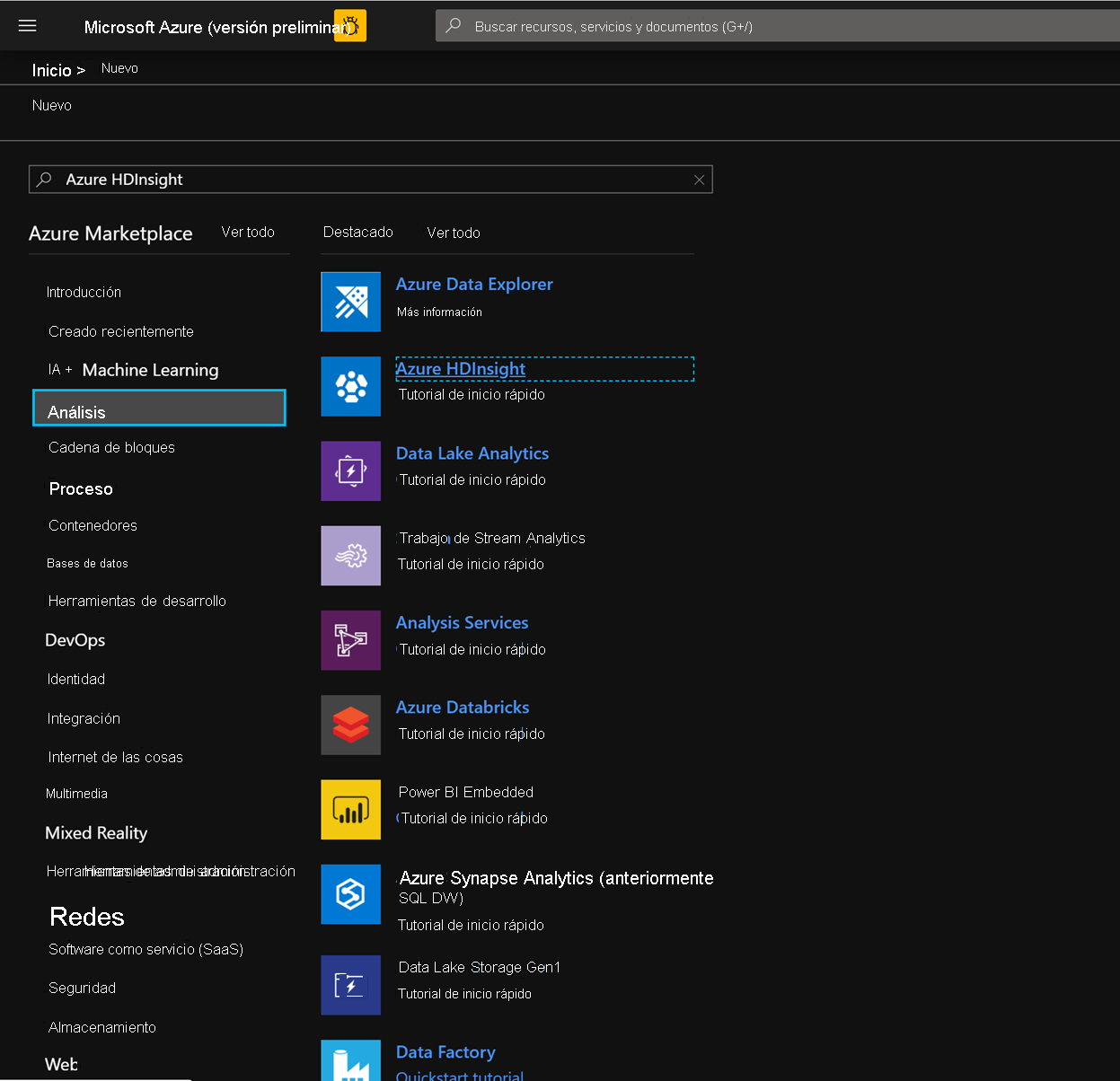
En la pestaña básico, rellene los campos siguientes para la creación de un clúster de HBase.
Suscripción: debe rellenarse automáticamente con los detalles de la suscripción
Grupo de recursos: escriba un grupo de recursos para almacenar la implementación de HBase de HDInsight
Nombre del clúster: escriba el nombre del clúster. Aparecerá una marca verde si el nombre del clúster está disponible.
Región: escriba el nombre de la región de implementación
Tipo de clúster: tipo de clúster-HBase. Versión: HBase 2.0.0 (HDI 4.0)
Nombre de usuario del registro del clúster: escriba el nombre de usuario del administrador de clústeres (predeterminado: admin)
Contraseña de registro del clúster: escriba la contraseña para el registro del clúster (valor predeterminado: sshuser)
Confirmar contraseña de registro del clúster: confirme la contraseña que escribió en el último paso
Nombre de usuario de Secure Shell (SSH): escriba el usuario de inicio de sesión de SSH (valor predeterminado: sshuser)
Usar contraseña de registro del clúster para SSH: active la casilla para usar la misma contraseña para inicios de sesión de SSH e inicios de sesión de Ambari, etc.

Haga clic en siguiente: almacenamiento para iniciar la pestaña Almacenamiento y rellenar los campos siguientes
Tipo de almacenamiento principal: Azure Storage.
Método de selección: elegir el botón de radio usar tecla de acceso
Nombre de la cuenta de almacenamiento: escriba el nombre de la cuenta de almacenamiento de blobs en bloques Premium creada anteriormente
Clave de acceso: escriba la clave de acceso key1 que copió anteriormente
Contenedor: HDInsight debe proponer un nombre de contenedor predeterminado. Puede elegir esto o crear un nombre propio.
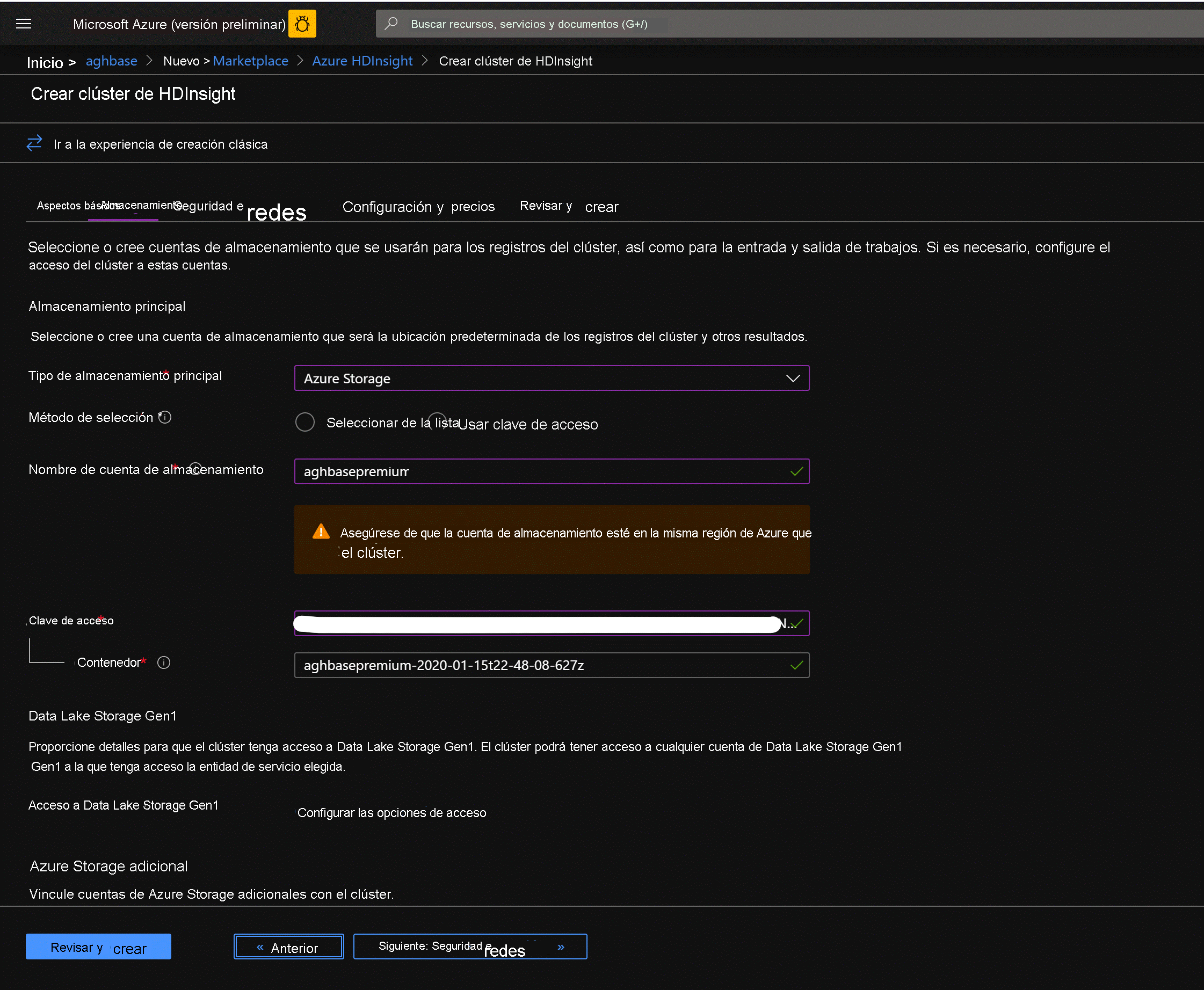
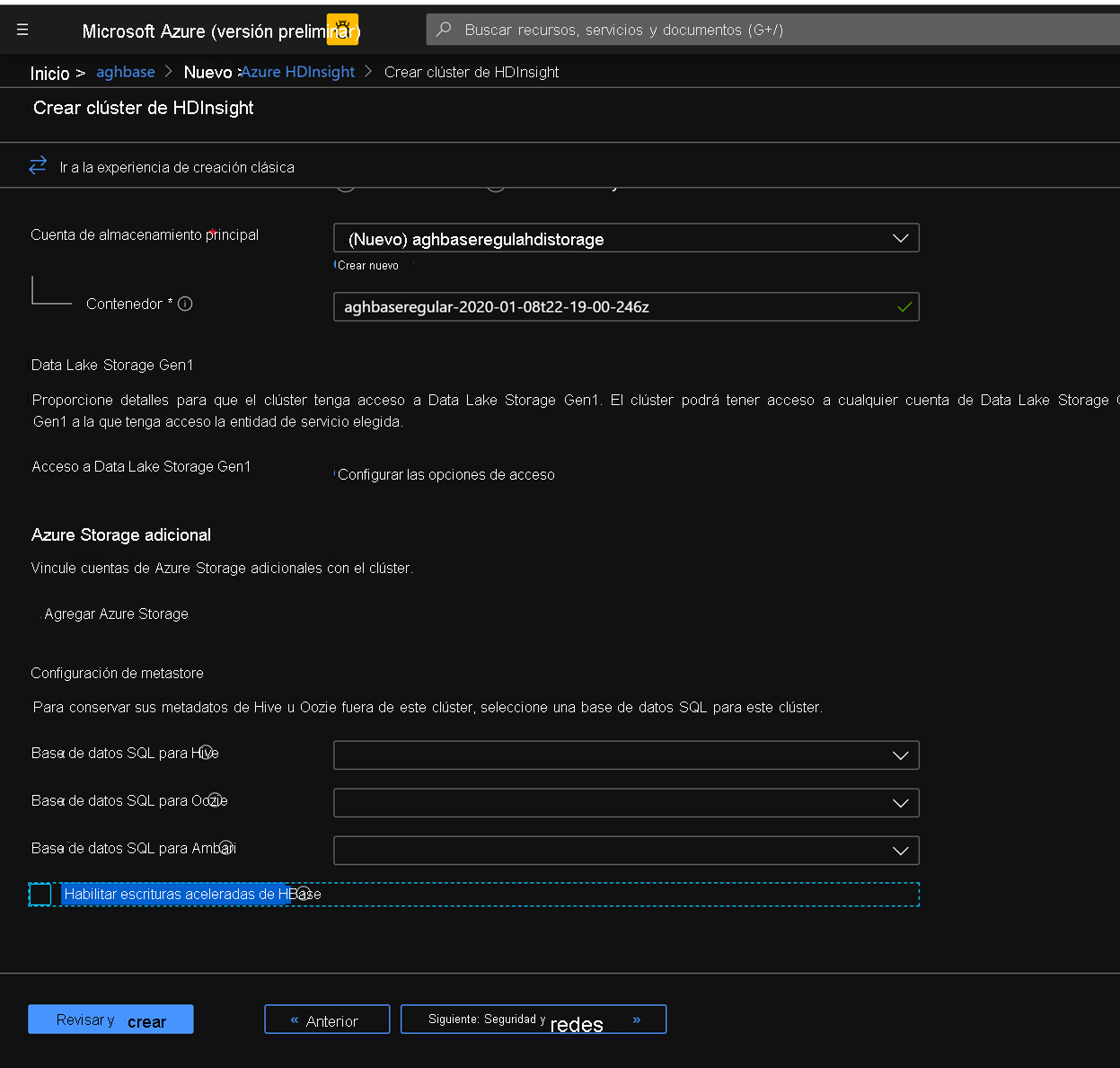
Deje las demás opciones sin tocar y desplácese hacia abajo para activar la casilla Habilitar escrituras aceleradas de HBase. (Tenga en cuenta que más adelante crearía un segundo clúster sin escrituras aceleradas con los mismos pasos, pero con esta casilla desactivada).
Deje el panel Seguridad y Redes a su configuración predeterminada sin cambios y vaya a la pestaña Configuración y Precios.
En la pestaña Configuración y Precios, observe que la sección Configuración de nodo ahora tiene un elemento de línea titulado Discos Premium por nodo de trabajo.
Elija el nodo de la región a 10 y el tamaño del nodo a DS14v2(puede seleccionar un número más pequeño de máquinas virtuales y una SKU de máquina virtual más pequeña, pero asegúrese de que ambos clústeres tienen el mismo número de nodos y SKU de máquina virtual para garantizar la paridad en la comparación)
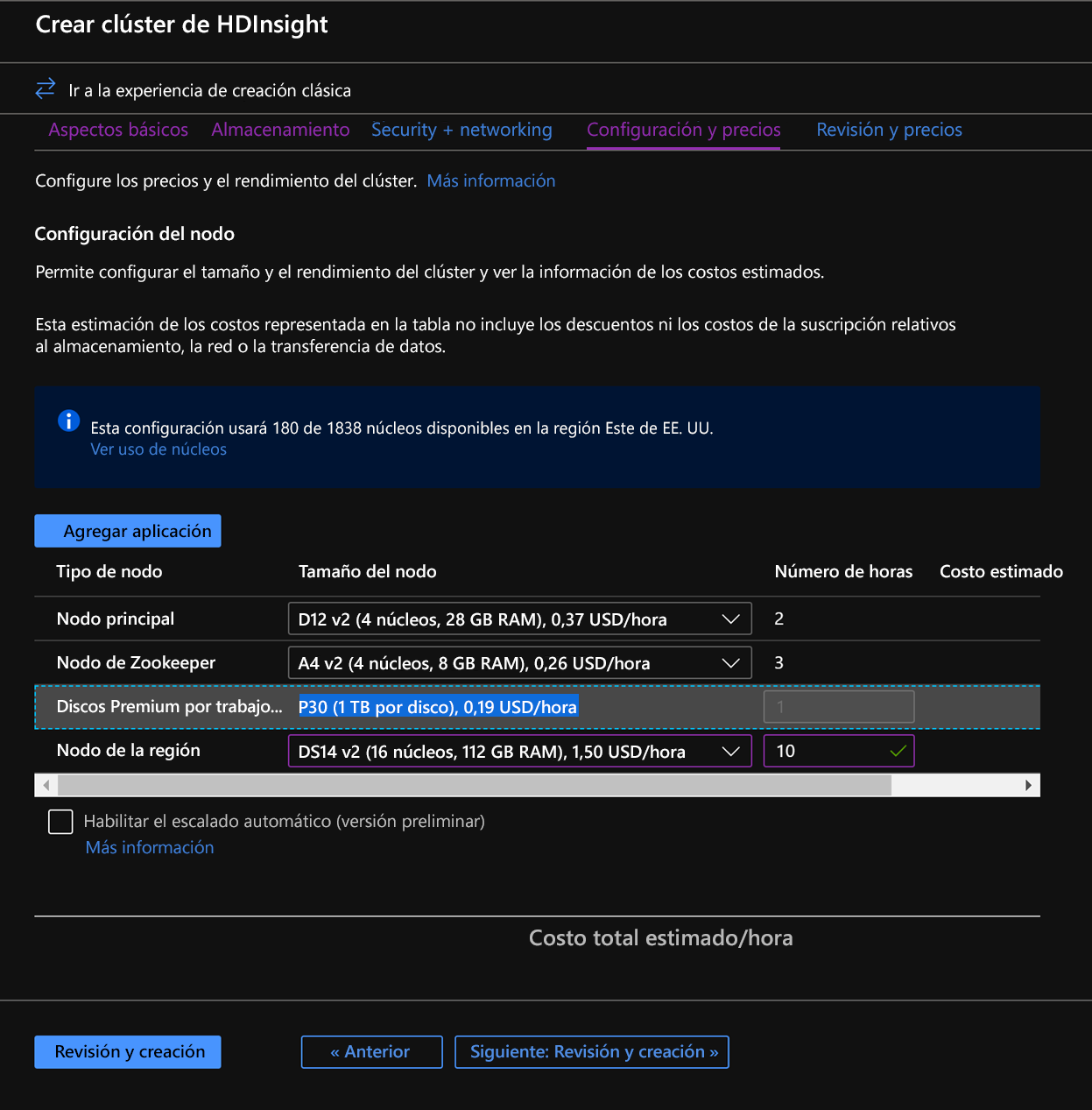
Haga clic en Siguiente: Revisar y Crear
En la pestaña Revisar y Crear, asegúrese de que la opción de Escritura acelerada de HBase está habilitada en la sección Almacenamiento.
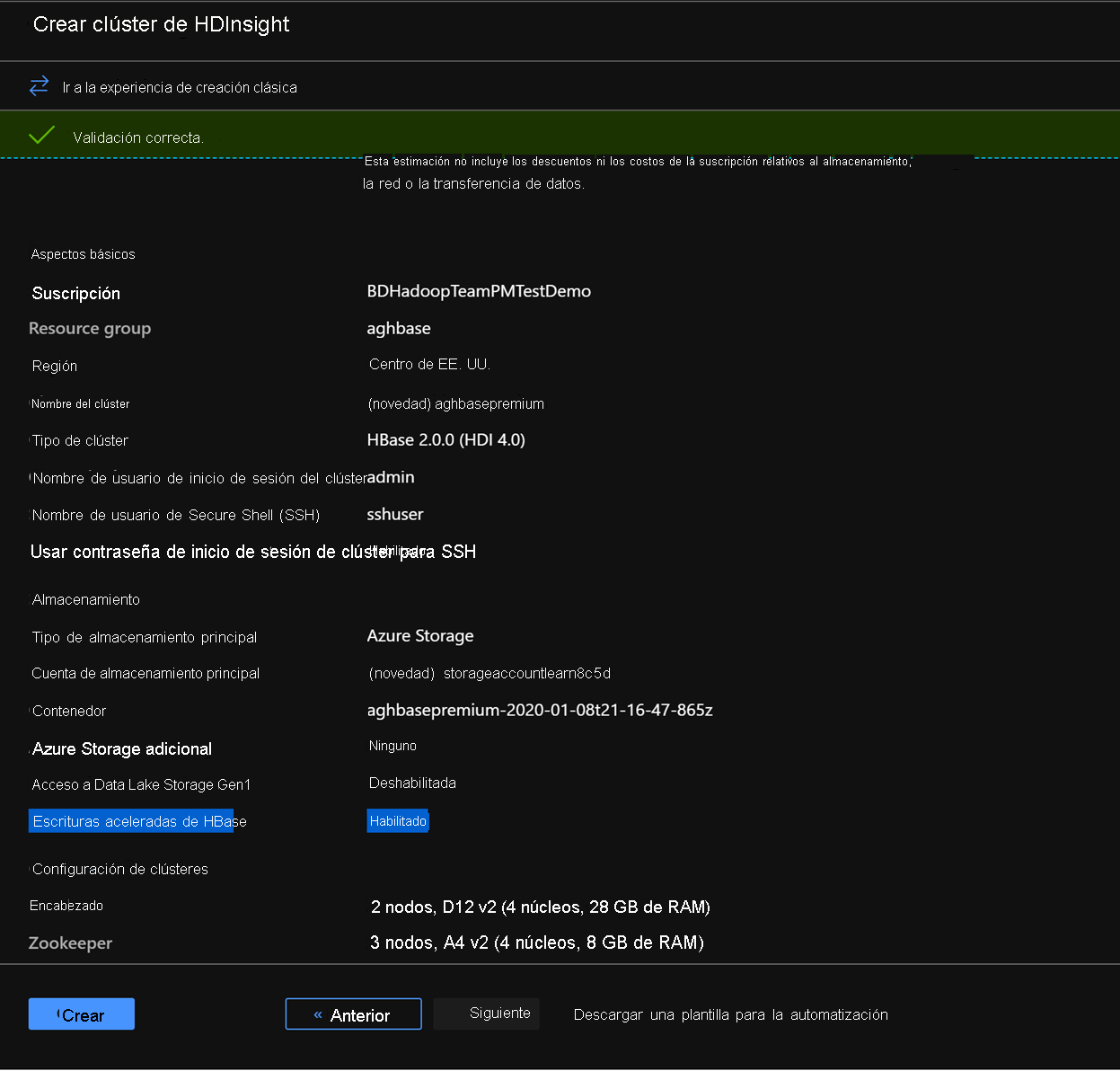
Haga clic en Crear para iniciar la implementación del primer clúster con escrituras aceleradas.
Repita los mismos pasos para crear un segundo clúster de HBase de HDInsight, esta vez sin acelerar las escrituras. Tenga en cuenta los siguientes cambios
Usar una cuenta de almacenamiento de blob normal que se recomienda de manera predeterminada
Mantenga activada la casilla Habilitar escrituras aceleradas en la pestaña Almacenamiento.
En la pestaña Configuración y Precios de este clúster, tenga en cuenta que la sección de configuración de nodo no tiene discos Premium por elemento de línea de nodo de trabajo.
Elija el nodo región en 10 y el tamaño del nodo en D14v2. (Tenga en cuenta también la falta de tipos de máquinas virtuales de la serie DS como anteriores). (puede elegir un menor número de máquinas virtuales y una SKU de máquina virtual más pequeña, pero asegúrese de que ambos clústeres tienen el mismo número de nodos y SKU de máquina virtual para garantizar la paridad en la comparación)
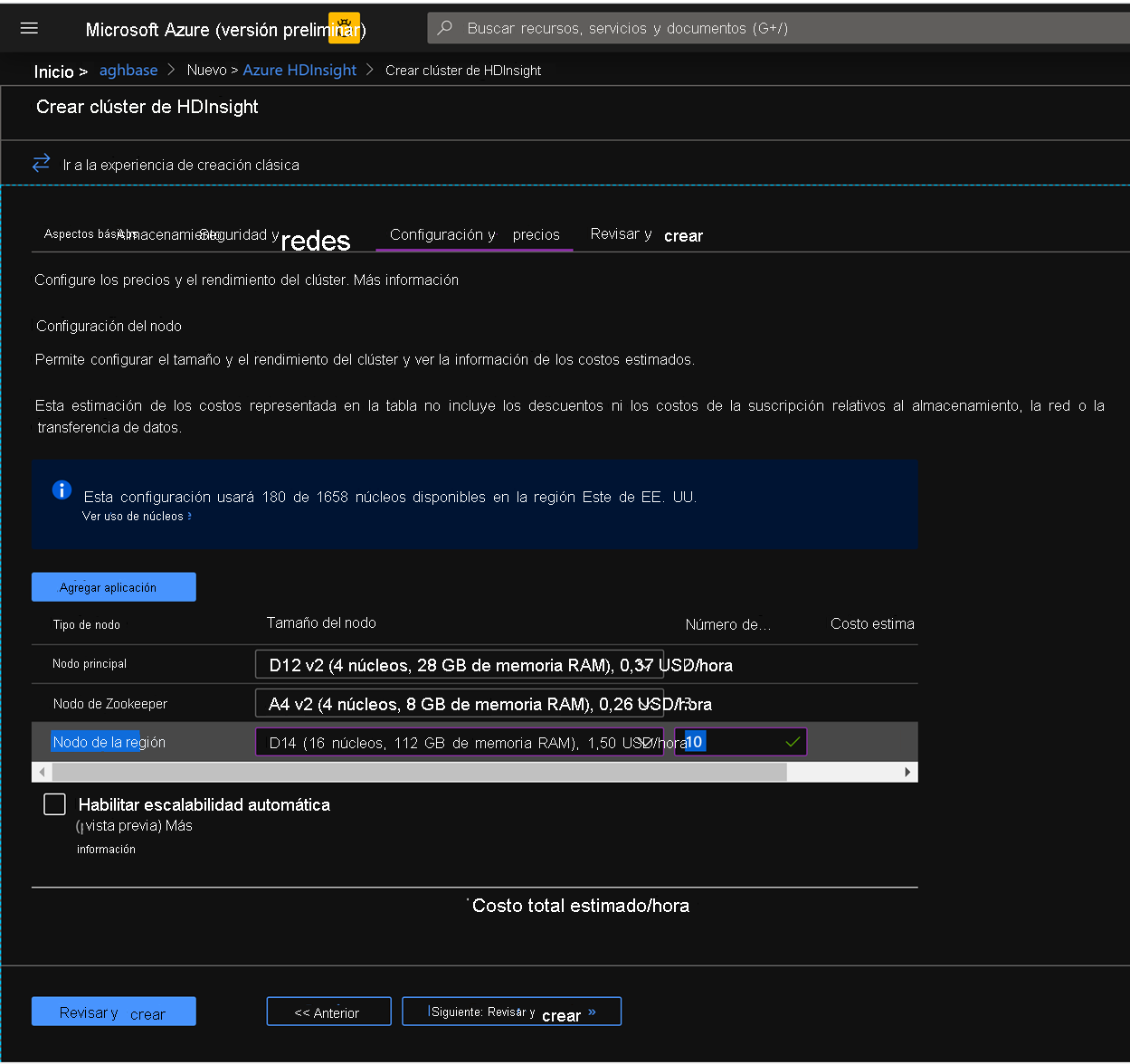
Haga clic en Crear para iniciar la implementación del segundo clúster sin escrituras aceleradas.
Ahora que hemos terminado con las implementaciones de clústeres, en la sección siguiente se pueden configurar y ejecutar pruebas de YCSB en ambos clústeres.

Ejecutar pruebas de YCSB
Inicio de sesión en el shell de HDInsight
Los pasos para configurar y ejecutar pruebas de YCSB en ambos clústeres son idénticos.
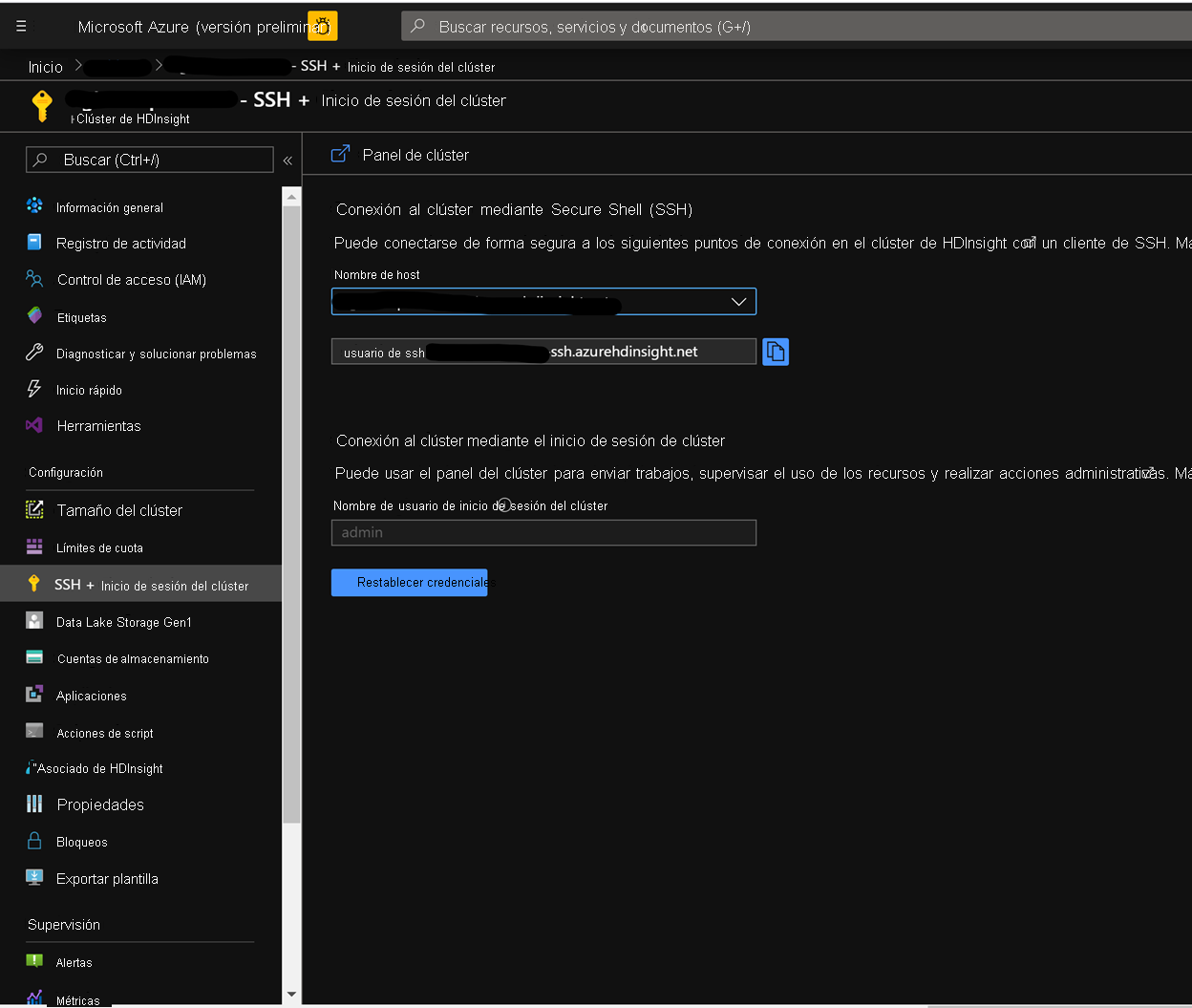
En la página clúster en Azure Portal, navegue hasta el inicio de sesión de SSH y Registro del clúster y use el nombre de host y la ruta de acceso SSH para ssh en el clúster. La ruta de acceso debe tener el formato siguiente.
ssh <sshuser>@<clustername>.azurehdinsight.net
Creación de la Tabla
Ejecute los pasos siguientes para crear las tablas de HBase, que se usarán para cargar los conjuntos de datos
Inicie el shell de HBase y establezca un parámetro para el número de divisiones de tabla. Establecer divisiones de tabla (10 * Número de servidores de regiones)
Crear la tabla de HBase, que se utilizaría para ejecutar las pruebas
Salir del shell de HBase
hbase(main):018:0> n_splits = 100 hbase(main):019:0> create 'usertable', 'cf', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}} hbase(main):020:0> exit
Descargar el repositorio de YSCB
Descargar el repositorio de YCSB desde el siguiente destino
$ curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gzDescomprima la carpeta para tener acceso al contenido
$ tar xfvz ycsb-0.17.0.tar.gzEsto crearía una carpeta ycsb-0.17.0. Mover a esta carpeta
Ejecutar una carga de trabajo pesada de escritura en ambos clústeres
Use el comando siguiente para iniciar una carga de trabajo pesada de escritura con los parámetros siguientes
workloads/workloada: indica que es necesario ejecutar la anexión workloads/workloada
tabla: Rellene el nombre de la tabla de HBase creada anteriormente
columnfamily: Rellene el valor del nombre de columfamily de HBase a partir de la tabla que ha creado
recordcount: número de registros que se van a insertar (usamos 1 millón)
threadcount: número de subprocesos (esto puede variar, pero debe mantenerse constante en todos los experimentos)
-cp /etc/hbase/conf: puntero a los valores de configuración de HBase
-s | Tee-a: proporcione un nombre de archivo para escribir la salida.
bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat
Ejecute la carga de trabajo pesada de escritura para cargar 1 millón filas en la tabla de HBase creada anteriormente.
Nota:
Omitir las advertencias que puede ver después de enviar el comando.
Resultados de ejemplo de HDInsight HBase con escrituras aceleradas
Ejecute el siguiente comando:
```CMD $ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat ```Lea los resultados:
```CMD 2020-01-10 16:21:40:213 10 sec: 15451 operations; 1545.1 current ops/sec; est completion in 10 minutes [INSERT: Count=15452, Max=120319, Min=1249, Avg=2312.21, 90=2625, 99=7915, 99.9=19551, 99.99=113855] 2020-01-10 16:21:50:213 20 sec: 34012 operations; 1856.1 current ops/sec; est completion in 9 minutes [INSERT: Count=18560, Max=305663, Min=1230, Avg=2146.57, 90=2341, 99=5975, 99.9=11151, 99.99=296703] .... 2020-01-10 16:30:10:213 520 sec: 972048 operations; 1866.7 current ops/sec; est completion in 15 seconds [INSERT: Count=18667, Max=91199, Min=1209, Avg=2140.52, 90=2469, 99=7091, 99.9=22591, 99.99=66239] 2020-01-10 16:30:20:214 530 sec: 988005 operations; 1595.7 current ops/sec; est completion in 7 second [INSERT: Count=15957, Max=38847, Min=1257, Avg=2502.91, 90=3707, 99=8303, 99.9=21711, 99.99=38015] ... ... 2020-01-11 00:22:06:192 564 sec: 1000000 operations; 1792.97 current ops/sec; [CLEANUP: Count=8, Max=80447, Min=5, Avg=10105.12, 90=268, 99=80447, 99.9=80447, 99.99=80447] [INSERT: Count=8512, Max=16639, Min=1200, Avg=2042.62, 90=2323, 99=6743, 99.9=11487, 99.99=16495] [OVERALL], RunTime(ms), 564748 [OVERALL], Throughput(ops/sec), 1770.7012685303887 [TOTAL_GCS_PS_Scavenge], Count, 871 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3116 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.5517505152740692 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 871 [TOTAL_GC_TIME], Time(ms), 3116 [TOTAL_GC_TIME_%], Time(%), 0.5517505152740692 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 10105.125 [CLEANUP], MinLatency(us), 5 [CLEANUP], MaxLatency(us), 80447 [CLEANUP], 95thPercentileLatency(us), 80447 [CLEANUP], 99thPercentileLatency(us), 80447 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 2248.752362 [INSERT], MinLatency(us), 1120 [INSERT], MaxLatency(us), 498687 [INSERT], 95thPercentileLatency(us), 3623 [INSERT], 99thPercentileLatency(us), 7375 [INSERT], Return=OK, 1000000 ```Explore el resultado de la prueba. Algunas observaciones de ejemplo de los resultados anteriores pueden incluir:
- La prueba tardó 538663 milisegundos (8.97 minutos) en ejecutarse
- Return=OK, 1000000 indica que los 1 millón de entradas se escribieron correctamente, **
- El rendimiento de escritura era de 1856 operaciones por segundo
- 95 % de las inserciones tenían una latencia de 3389 milisegundos
- Pocas inserciones han tardado más tiempo, quizás se bloquean en los servidores de regiones debido a la alta carga de trabajo
Resultados de ejemplo de HDInsight HBase con escrituras aceleradas
Ejecute el siguiente comando:
$ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.datLea los resultados:
2020-01-10 23:58:20:475 2574 sec: 1000000 operations; 333.72 current ops/sec; [CLEANUP: Count=8, Max=79679, Min=4, Avg=9996.38, 90=239, 99=79679, 99.9 =79679, 99.99=79679] [INSERT: Count=1426, Max=39839, Min=6136, Avg=9289.47, 90=13071, 99=27535, 99.9=38655, 99.99=39839] [OVERALL], RunTime(ms), 2574273 [OVERALL], Throughput(ops/sec), 388.45918828344935 [TOTAL_GCS_PS_Scavenge], Count, 908 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3208 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.12461770760133055 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 908 [TOTAL_GC_TIME], Time(ms), 3208 [TOTAL_GC_TIME_%], Time(%), 0.12461770760133055 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 9996.375 [CLEANUP], MinLatency(us), 4 [CLEANUP], MaxLatency(us), 79679 [CLEANUP], 95thPercentileLatency(us), 79679 [CLEANUP], 99thPercentileLatency(us), 79679 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 10285.497832 [INSERT], MinLatency(us), 5568 [INSERT], MaxLatency(us), 1307647 [INSERT], 95thPercentileLatency(us), 18751 [INSERT], 99thPercentileLatency(us), 33759 [INSERT], Return=OK, 1000000Comparación de los resultados:
Parámetro Unidad Con escrituras aceleradas Sin escrituras aceleradas [OVERALL], RunTime(ms) Milisegundos 567478 2574273 [OVERALL], Throughput(ops/sec) Operaciones/s 1770 388 [INSERT], Operaciones n.º de operaciones 1000000 1000000 [INSERT], 95thPercentileLatency(us) Microsegundos 3623 18751 [INSERT], 99thPercentileLatency(us) Microsegundos 7375 33759 [INSERT], Return=OK n.º de registros 1000000 1000000 Algunas observaciones de ejemplo que se pueden realizar en las comparaciones son:
- [OVERALL], RunTime(ms): tiempo total de ejecución en milisegundos
- [OVERALL], Throughput(ops/sec): número de operaciones por segundo en todos los subprocesos
- [INSERT], operaciones: número total de operaciones de inserción, con latencias asociadas promedio, mínimo, máximo, percentiles 95 y 99 a continuación
- [INSERT], 95thPercentileLatency(us): 95 % de las operaciones de INSERCIÓN tienen un punto de datos por debajo de este valor
- [INSERT], 99thPercentileLatency(us): 99 % de las operaciones de INSERCIÓN tienen un punto de datos por debajo de este valor
- [INSERT], Return = OK: el registro OK indica que todas las operaciones de INSERCIÓN se realizaron correctamente junto con el recuento
Considere la posibilidad de probar varias cargas de trabajo para realizar comparaciones. Algunos ejemplos son:
Principalmente lectura (95 % de lectura y 5 % de escritura): workloadb
bin/ycsb run hbase12 -P workloads/workloadb -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadb.datSolo lectura (100 % lectura y 0 % escritura): workloadc
bin/ycsb run hbase12 -P workloads/workloadc -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadc.dat