Exploración de la arquitectura de la solución
Vamos a revisar la arquitectura de operaciones de aprendizaje automático (MLOps) para comprender el propósito de lo que estamos intentando lograr.
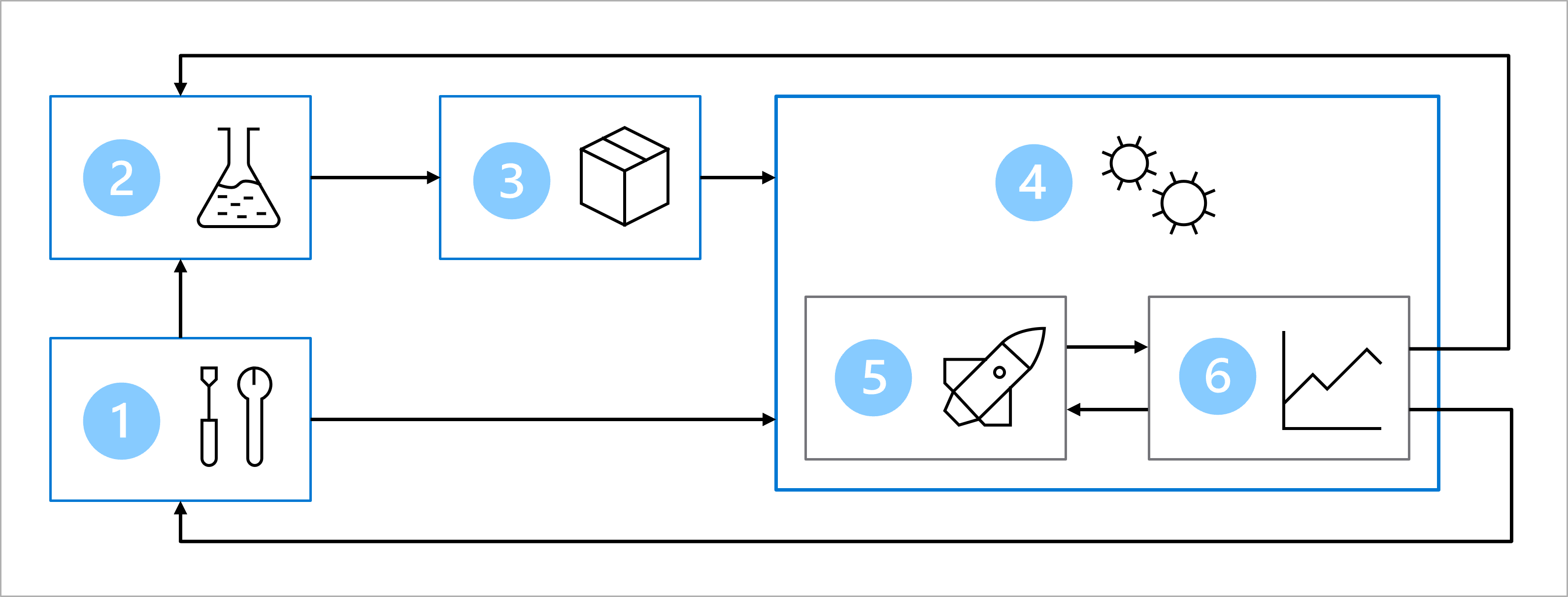
Imagine que, junto con el equipo de desarrollo de software y ciencia de datos, ha acordado la siguiente arquitectura para entrenar, probar e implementar el modelo de clasificación de diabetes:
Nota
El diagrama es una representación simplificada de una arquitectura de MLOps. Para ver una arquitectura más detallada, explore los distintos casos de uso del acelerador de soluciones MLOps (v2).
La arquitectura incluye:
- Configuración: creación de todos los recursos de Azure necesarios para la solución.
- Desarrollo de modelos (bucle interno): análisis y procesamiento de los datos para entrenar y evaluar el modelo.
- Integración continua: empaquetado y registro del modelo.
- Implementación de modelos (bucle externo): implementación del modelo.
- Implementación continua: prueba del modelo y promoción al entorno de producción.
- Supervisión: supervisión del rendimiento del modelo y del punto de conexión.
El equipo de ciencia de datos es responsable del desarrollo del modelo. El equipo de desarrollo de software es responsable de integrar el modelo implementado con la aplicación web que usan los profesionales para evaluar si un paciente tiene diabetes. Usted es responsable llevar el modelo desde su desarrollo hasta su implementación.
Espera que el equipo de ciencia de datos proponga de manera constante cambios en los scripts usados para entrenar el modelo. Cada vez que haya un cambio en el script de entrenamiento, debe volver a entrenar el modelo y volver a implementarlo en el punto de conexión existente.
Quiere permitir que el equipo de ciencia de datos experimente, sin tocar el código listo para producción. También quiere asegurarse de que cualquier código nuevo o actualizado pasa de forma automática por las comprobaciones de calidad acordadas. Después de comprobar el código para entrenar el modelo, usará el script de entrenamiento actualizado para entrenar un nuevo modelo e implementarlo.
Para realizar un seguimiento de los cambios y comprobar el código antes de actualizar el código de producción, es necesario trabajar con ramas. Ha acordado con el equipo de ciencia de datos que cada vez que quieran realizar un cambio, crearán una rama de características para crear una copia del código y realizar sus cambios en esta.
Cualquier científico de datos puede crear una rama de características y trabajar allí. Una vez que hayan actualizado el código y quieran que ese código sea el nuevo código de producción, tendrán que crear una solicitud de incorporación de cambios. En la solicitud de incorporación de cambios, los cambios propuestos serán visibles para los otros usuarios, dándoles la oportunidad de revisarlos y analizarlos.
Cada vez que se crea una solicitud de incorporación de cambios, querrá que se compruebe de forma automática si el código funciona y que la calidad del código cumple los estándares de la organización. Una vez que el código pasa las comprobaciones de calidad, el científico de datos principal debe revisar los cambios y aprobar las actualizaciones antes de que se pueda combinar la solicitud de incorporación de cambios: entonces, el código de la rama principal se puede actualizar en consecuencia.
Importante
Nadie debería poder insertar cambios en la rama principal. Para proteger el código, especialmente el código de producción, querrá exigir que la rama principal solo se pueda actualizar mediante solicitudes de incorporación de cambios que deban aprobarse.