Creación de un clúster de Spark
Puede crear uno o varios clústeres en el área de trabajo de Azure Databricks mediante la interfaz de usuario del área de trabajo de Azure Databricks.
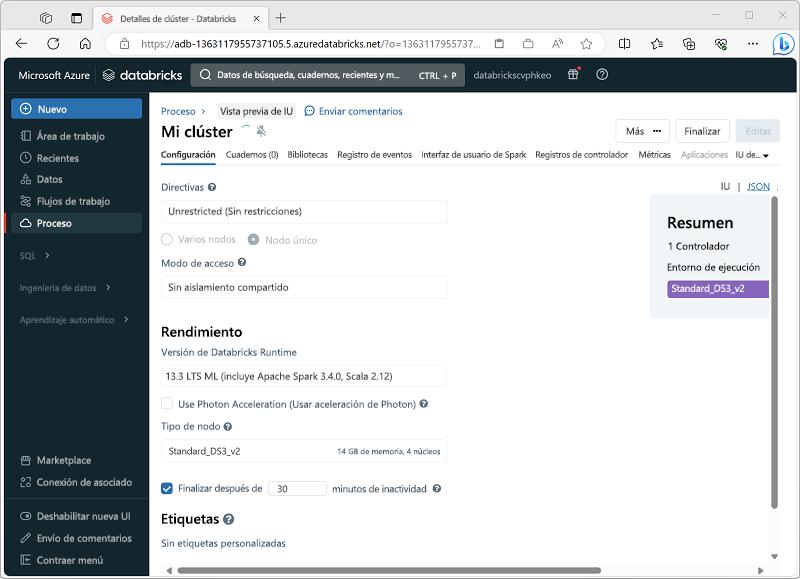
Al crear el clúster, puede especificar las opciones de configuración, entre las que se incluyen:
- Nombre del clúster.
- Modo de clúster, que puede ser:
- Estándar: adecuado para cargas de trabajo de usuario único que requieren varios nodos de trabajo.
- Alta simultaneidad: adecuado para cargas de trabajo en las que varios usuarios usarán el clúster simultáneamente.
- Nodo único: adecuado para cargas de trabajo pequeñas o pruebas, donde solo se requiere un único nodo de trabajo.
- La versión del entorno de ejecución de Databricks que se va a usar en el clúster; que dicta la versión de Spark y componentes individuales, como Python, Scala y otros que se instalan.
- El tipo de máquina virtual (VM) que se usa para los nodos de trabajo del clúster.
- Número mínimo y máximo de nodos de trabajo en el clúster.
- Tipo de máquina virtual que se usa para el nodo de controlador en el clúster.
- Si el clúster admite el escalado automático para cambiar el tamaño dinámico del clúster.
- Cuánto tiempo puede permanecer inactivo el clúster antes de apagarse automáticamente.
Administración de recursos de clúster de Azure
Al crear un área de trabajo de Azure Databricks, un dispositivo de Databricks se implementa como un recurso de Azure en la suscripción. Al crear un clúster en el área de trabajo, especifique los tipos y tamaños de las máquinas virtuales (VM) que se usarán para los nodos de controlador y de trabajo, y otras opciones de configuración, pero Azure Databricks administra todos los demás aspectos del clúster.
El dispositivo de Databricks se implementa en Azure como un grupo de recursos administrado dentro de la suscripción. Este grupo de recursos contiene el controlador y las máquinas virtuales de trabajo para los clústeres, junto con otros recursos necesarios, como una red virtual, un grupo de seguridad y una cuenta de almacenamiento. Todos los metadatos del clúster, como los trabajos programados, se almacenan en una instancia de Azure Database con replicación geográfica para la tolerancia a errores.
Azure Databricks se divide en dos planos principales: el plano de control, que consta de servicios back-end (por ejemplo, la interfaz de usuario web) administrada por Microsoft y el plano de proceso, donde se ejecutan las cargas de trabajo de datos. Hay dos variantes de proceso: el proceso clásico, que usa su propia suscripción y red virtual de Azure (que ofrece aislamiento dentro de la suscripción) y el proceso sin servidor, que se ejecuta en el entorno administrado de Databricks, pero todavía en la misma región de Azure que el área de trabajo, con controles de red y seguridad para aislar entre los clientes. Cada área de trabajo tiene una cuenta de almacenamiento en su suscripción que contiene datos del sistema (cuadernos, registros, metadatos de trabajo), el sistema de archivos distribuido (DBFS) y los recursos de catálogo (si tiene habilitado el catálogo de Unity), con controles adicionales para redes, firewalling y acceso para garantizar la seguridad y el aislamiento adecuado.

Nota:
También tiene la opción de asociar el clúster a un grupo de nodos inactivos para reducir el tiempo de inicio del clúster. Para más detalles, consulte Pools en la documentación de Azure Databricks.