Exploración de la arquitectura de la solución
Antes de empezar, exploremos la arquitectura para comprender todos los requisitos. La incorporación de un modelo a la producción significa que necesita escalar la solución y trabajar conjuntamente con otros equipos. Junto con los científicos de datos, los ingenieros de datos y el equipo de infraestructura, ha decidido usar el siguiente enfoque:
- Todos los datos se almacenarán en un Azure Blob Storage, que será administrado por el ingeniero de datos.
- El equipo de infraestructura creará los recursos de Azure necesarios, como el área de trabajo de Azure Machine Learning.
- El científico de datos se centrará en el bucle interno: desarrollar y entrenar el modelo.
- El ingeniero de aprendizaje automático tomará el modelo entrenado y lo implementará en el bucle externo.
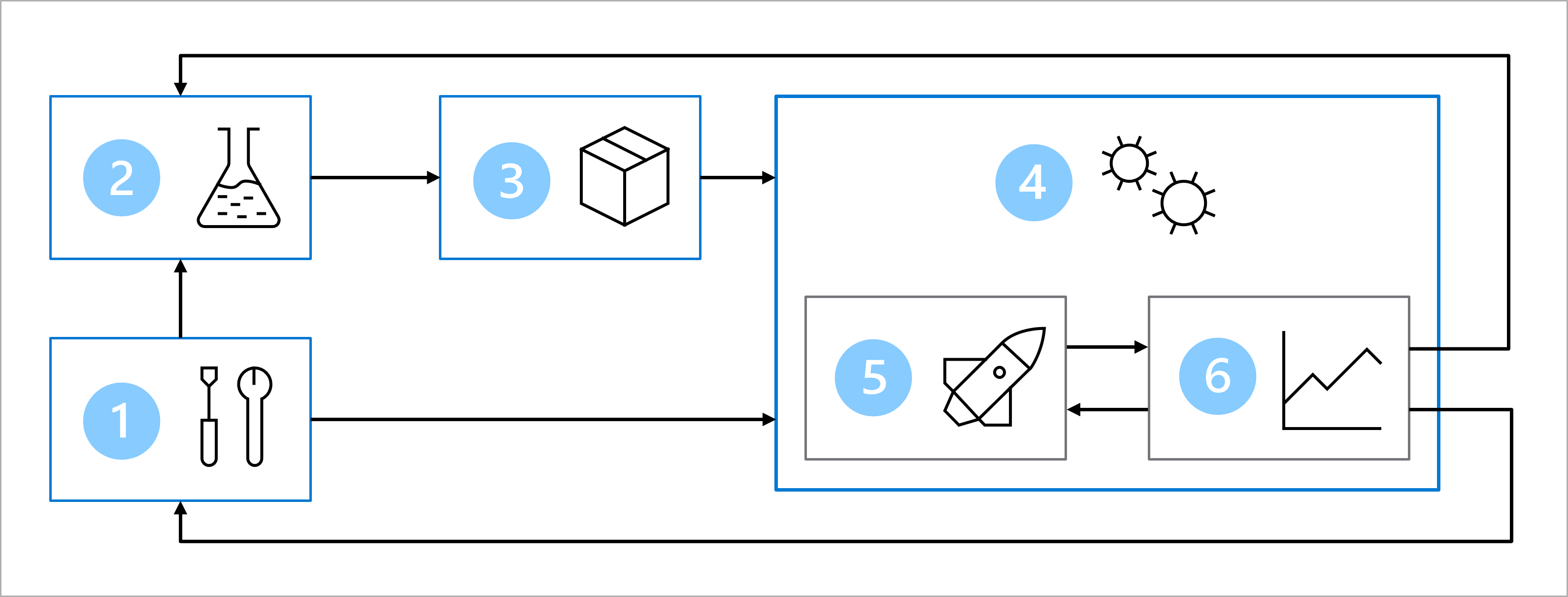
Junto con el equipo más grande, ha diseñado una arquitectura para obtener operaciones de aprendizaje automático (MLOps).
Nota:
El diagrama es una representación simplificada de una arquitectura de MLOps. Para ver una arquitectura más detallada, explore los distintos casos de uso del acelerador de soluciones MLOps (v2).
El objetivo principal de la arquitectura de MLOps es crear una solución sólida y reproducible. Para lograrlo, la arquitectura incluye:
- Configuración: creación de todos los recursos de Azure necesarios para la solución.
- Desarrollo de modelos (bucle interno): análisis y procesamiento de los datos para entrenar y evaluar el modelo.
- Integración continua: empaquetado y registro del modelo.
- Implementación de modelos (bucle externo): implementación del modelo.
- Implementación continua: prueba del modelo y promoción al entorno de producción.
- Supervisión: supervisión del rendimiento del modelo y del punto de conexión.
En este momento del proyecto, se crea el área de trabajo de Azure Machine Learning, los datos se almacenan en un Azure Blob Storage y el equipo de ciencia de datos ha entrenado el modelo.
Quiere pasar del bucle interno y el desarrollo del modelo al bucle externo mediante la implementación del modelo en producción. Por lo tanto, debe convertir la salida del equipo de ciencia de datos en una canalización sólida y reproducible en Azure Machine Learning.
Asegurarse de que todo el código se almacena como scripts y de que los scripts se ejecutan como trabajos de Azure Machine Learning hará que sea más fácil automatizar el entrenamiento del modelo y volver a entrenar el modelo en el futuro.
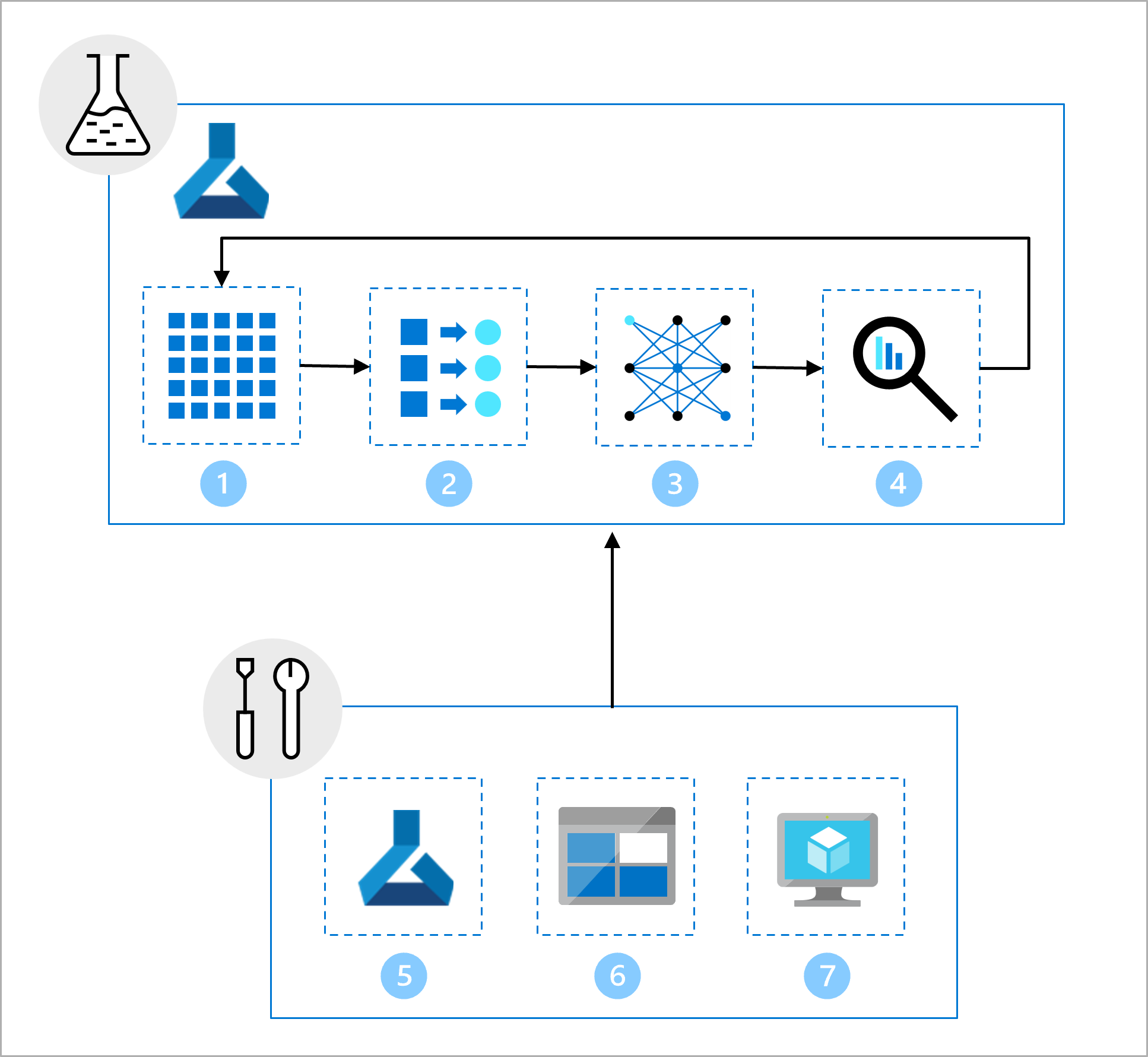
El equipo de ciencia de datos ha estado trabajando en el desarrollo de modelos. Le proporcionan un cuaderno de Jupyter Notebook que incluye las siguientes tareas:
- Leer y explorar los datos.
- Realizar la ingeniería de características.
- Entrene el modelo.
- Evalúe el modelo.
Como parte de la configuración, el equipo de infraestructura ha creado:
- Un área de trabajo de desarrollo (dev) de Azure Machine Learning que puede usar el equipo de ciencia de datos para la exploración y la experimentación.
- Un recurso de datos del área de trabajo, que hace referencia a una carpeta de Azure Blob Storage que contiene los datos.
- Recursos de proceso necesarios para ejecutar cuadernos y scripts.
La primera tarea hacia MLOps es convertir el trabajo de los científicos de datos, de modo que se pueda automatizar fácilmente el desarrollo del modelo. Mientras que el equipo de ciencia de datos trabaja en un cuaderno de Jupyter Notebook, ahora se deben usar scripts y ejecutarlos mediante trabajos de Azure Machine Learning. La entrada del trabajo será el recurso de datos creado por el equipo de infraestructura, que apunta a los datos que residen en Azure Blob Storage, conectados al área de trabajo de Azure Machine Learning.