Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a: ✔️ Máquinas virtuales Linux
En este artículo se describe cómo solucionar problemas de rendimiento de memoria que se producen en máquinas virtuales Linux (VM) en Microsoft Azure.
El primer paso para trabajar en problemas relacionados con la memoria es evaluar los siguientes elementos:
- Uso de la memoria por parte de las aplicaciones hospedadas en el sistema
- El nivel adecuado de memoria disponible en el sistema
Puede comenzar mediante el análisis de patrones de carga de trabajo para determinar si el sistema está configurado correctamente. A continuación, es posible que tenga que considerar la posibilidad de escalar la máquina virtual o elegir entre una arquitectura nuMA (acceso a memoria no uniforme) y UMA (acceso uniforme a memoria). Además, vale la pena considerar si el rendimiento de la aplicación se beneficiaría de Transparent HugePages (THP). El mejor enfoque es colaborar con el proveedor de aplicaciones para comprender los requisitos de memoria recomendados.
Áreas clave afectadas por la memoria
Asignación de memoria de proceso: la memoria es un recurso necesario para cada proceso, incluido el kernel. La cantidad de memoria necesaria depende del diseño y el propósito del proceso. La memoria normalmente se asigna a la pila o al montón. Por ejemplo, las bases de datos en memoria, como SAP HANA, dependen en gran medida de la memoria para almacenar y procesar datos de forma eficaz.
Uso de caché de páginas: la memoria también se puede consumir indirectamente a través de un aumento de la memoria caché de páginas. La caché de páginas es una representación en memoria de un archivo que se leyó anteriormente desde un disco. Esta caché ayuda a evitar lecturas repetidas de disco. El mejor ejemplo de este proceso es un servidor de archivos que se beneficia de esta funcionalidad de kernel subyacente.
Arquitectura de memoria : es importante saber qué aplicación o aplicaciones se ejecutan en la misma máquina virtual y si pueden competir por la memoria disponible. Es posible que también tenga que comprobar si la máquina virtual está configurada para usar la arquitectura de NUMA o UMA. En función de los requisitos de memoria de un proceso, la arquitectura UMA puede ser preferible para que se pueda acceder a toda la RAM sin pérdida de rendimiento. Por otro lado, para la informática de alto rendimiento (HPC) que implica muchos procesos o procesos pequeños que caben en uno de los nodos NUMA, puede beneficiarse de la localidad de caché de CPU.
Sobrecommitimiento de memoria: también es importante determinar si el kernel permite la sobreasignación de memoria. Dependiendo de la configuración, cada solicitud de memoria se cumple hasta que la cantidad solicitada ya no esté disponible.
Espacio de intercambio La habilitación del intercambio mejora la estabilidad general del sistema al proporcionar un búfer durante las condiciones de memoria baja. Este búfer ayuda al sistema a permanecer resistente bajo presión. Para obtener más información, consulte este artículo de Kernel de Linux.
Descripción de las herramientas de solución de problemas de memoria
Puede usar las siguientes herramientas de línea de comandos para solucionar problemas.
Gratis
Para ver la cantidad de memoria disponible y usada en un sistema, use el free comando .

Este comando genera un resumen de la memoria reservada y disponible, incluido el espacio de intercambio total y usado.
pidstat y vmstat
Para obtener una vista más detallada del uso de memoria por procesos individuales, use el pidstat -r comando .
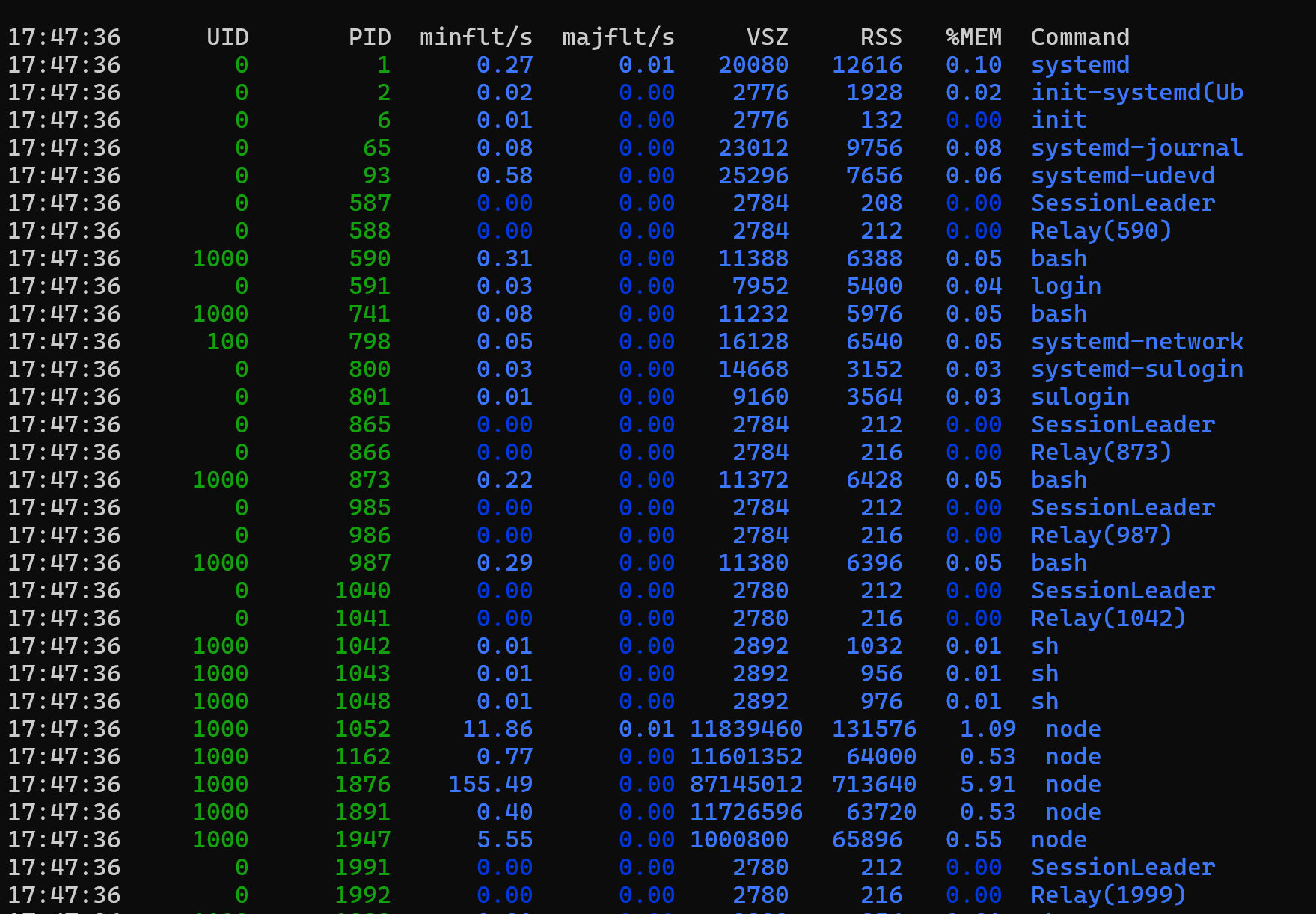
Al analizar los informes de uso de memoria, dos columnas importantes que se deben observar son VSZ y RSS:
- VSZ (tamaño del conjunto virtual) muestra la cantidad total de memoria virtual (en kilobytes) que se reserva un proceso.
- RSS (tamaño del conjunto residente) indica la cantidad de memoria virtual que se mantiene actualmente en la RAM (por ejemplo, memoria comprometida).
Otra métrica útil es majflt/s (el número de errores de página principales por segundo). Este número mide la frecuencia con la que se debe leer una página de memoria desde un dispositivo de intercambio. Si tiene dudas sobre el uso elevado de la memoria de intercambio, compruebe la cantidad mediante la herramienta vmstat para supervisar las estadísticas de entrada y salida de páginas a lo largo del tiempo.
Ejemplo de salida de vmstat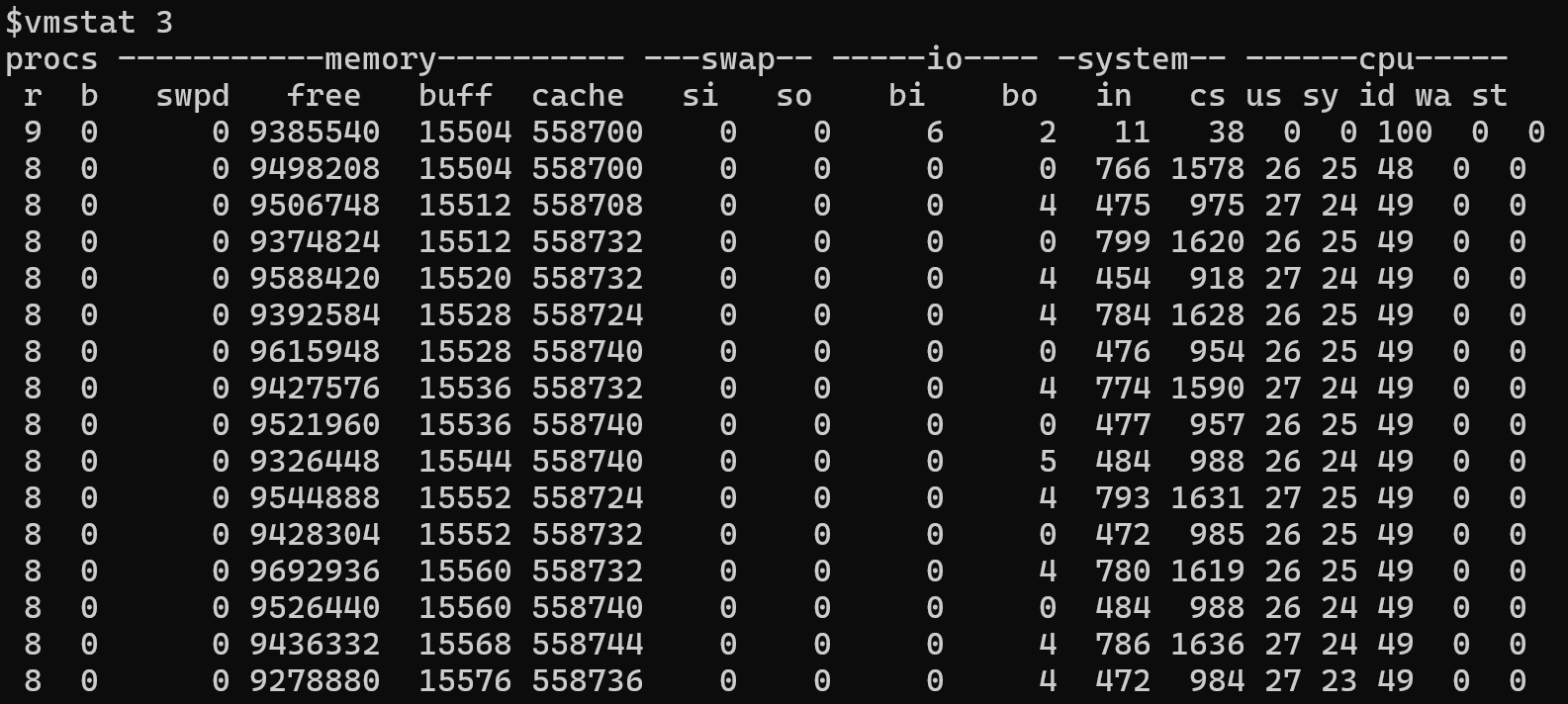
En este ejemplo, es posible que observe que muchas páginas de memoria se leen o escriben para intercambiar. Estos valores altos suelen indicar que el sistema se está ejecutando con poca memoria disponible. Esta condición puede producirse porque varios procesos compiten por la memoria o porque la mayoría de las aplicaciones no pueden usar la memoria disponible.
Una razón común para la memoria no disponible es el uso de HugePages. HugePages es memoria reservada. No todas las aplicaciones pueden usar memoria reservada. En algunas situaciones, es posible que tenga que evaluar si las aplicaciones necesitan HugePages o funcionarían de forma más eficaz mediante Transparent HugePages (THP). THP permite que el kernel administre páginas de memoria grandes dinámicamente. Por ejemplo, la máquina virtual Java (JVM) puede aprovechar THP habilitando la marca siguiente:
-XX:+UseTransparentHugePages
Para obtener más información sobre THP, consulte Compatibilidad con HugePage transparente.
Para obtener más información sobre HugePages, consulte Páginas de HugeTLB.
Prueba del uso de THP en un programa de ejemplo
Para observar cómo el sistema usa THP, puede ejecutar un pequeño programa C que asigne aproximadamente 256 MB de RAM. El programa usa la llamada del madvise sistema para indicar al kernel de Linux que esta región de memoria debe usar páginas enormes si se admite el THP.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <unistd.h>
#define LARGE_MEMORY_SIZE (256 * 1024 * 1024) // 256MB
int main() {
char str[2];
// Allocate a large memory area
void *addr = mmap(NULL, LARGE_MEMORY_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (addr == MAP_FAILED) {
perror("mmap");
return 1;
}
// Use madvise to give advice about the memory usage
if (madvise(addr, LARGE_MEMORY_SIZE, MADV_HUGEPAGE) != 0) {
perror("madvise");
munmap(addr, LARGE_MEMORY_SIZE);
return 1;
}
// Initialize the memory
int *array = (int *)addr;
for (int i = 0; i < LARGE_MEMORY_SIZE / sizeof(int); i++) {
array[i] = i;
}
memset(addr, 0, LARGE_MEMORY_SIZE);
printf("Press Enter to continue\n");
fgets(str,2,stdin);
// Clean up
if (munmap(addr, LARGE_MEMORY_SIZE) == -1) {
perror("munmap");
return 1;
}
return 0;
}
Si ejecuta el programa, no es observable directamente si el programa usa THP.
Puede comprobar el uso general de THP en el sistema examinando el /proc/meminfo archivo . Compruebe el AnonHugePages campo para determinar la cantidad de memoria que usa THP. Este archivo solo proporciona estadísticas de todo el sistema.
Para saber si un proceso usa THP, debe inspeccionar el smaps archivo en el /proc directorio del proceso en cuestión. Por ejemplo, en /proc/2275/smaps, busque una línea que contenga la palabra heap (que se muestra aquí en el extremo derecho).
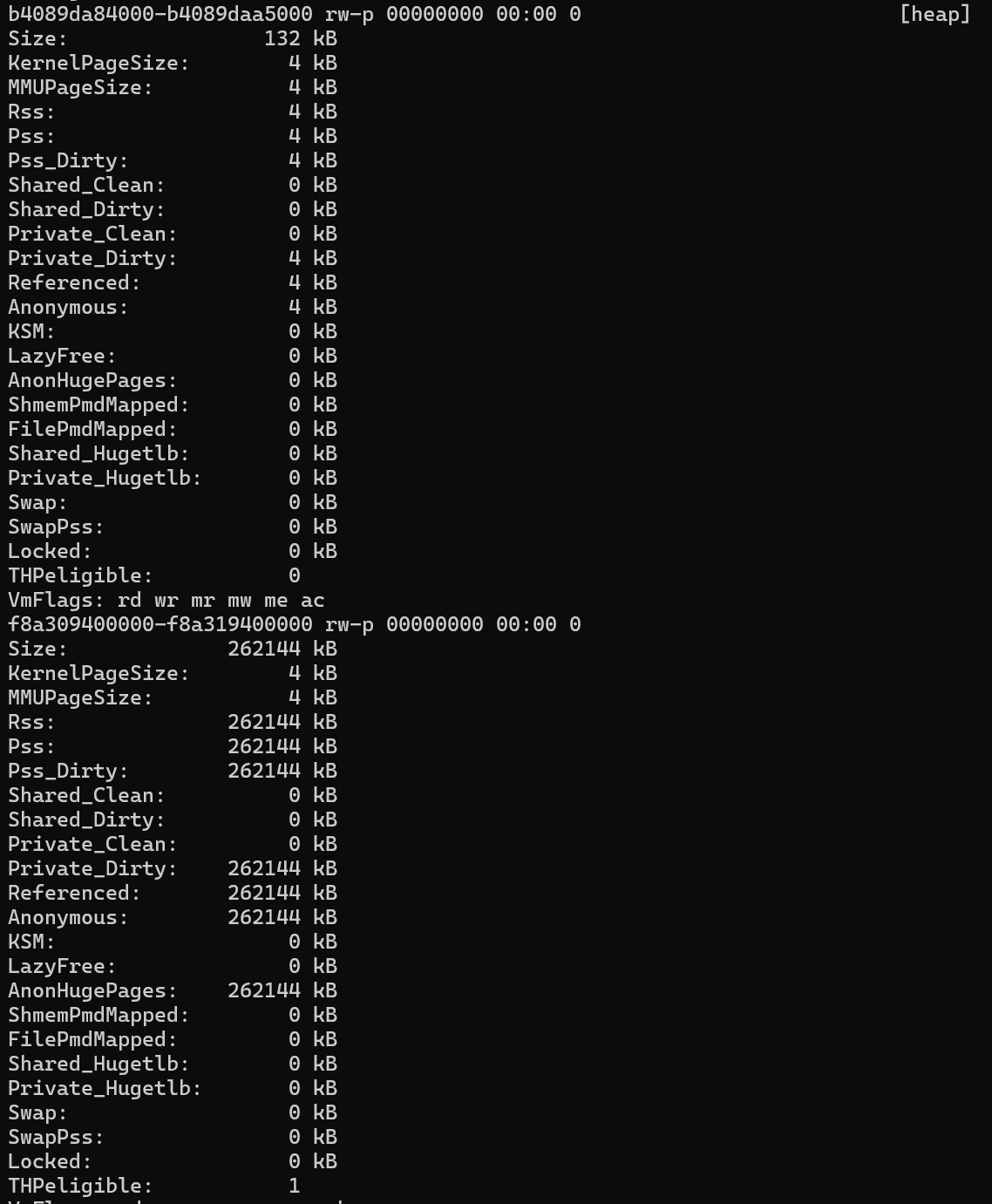
En este ejemplo se muestra que se asignó un segmento de memoria grande y se marcó como THPeligible(THP está en uso). Mediante madvice syscall, la asignación de este bloque de memoria es mucho más eficaz. Podría lograr la misma eficiencia usando Páginas Enormes. Según el tamaño de la asignación, el kernel puede asignar páginas estándar de 4 KB o bloques contiguos más grandes. Esta optimización puede mejorar el rendimiento de las aplicaciones que consumen mucha memoria.
Para obtener más información, vea Soporte de Transparent Hugepage.
NUMA
Si las aplicaciones se ejecutan en un sistema NUMA que tiene varios nodos, es importante conocer la capacidad de memoria de cada nodo. Todos los nodos pueden acceder a la memoria total del sistema. Sin embargo, obtendrá un rendimiento óptimo si los procesos que se ejecutan en un nodo NUMA determinado funcionan en la memoria que está bajo control directo de ese nodo. Si el nodo local no puede cumplir una solicitud de memoria, el sistema asigna memoria de otro nodo. Sin embargo, el acceso a la memoria entre nodos presenta latencia y puede provocar penalizaciones de rendimiento. Por lo tanto, debe supervisar la localización de la memoria para asegurarse de que las cargas de trabajo están alineadas con los recursos de memoria de sus respectivos nodos NUMA asignados.
En la captura de pantalla siguiente se muestra un ejemplo de la configuración de NUMA del sistema.
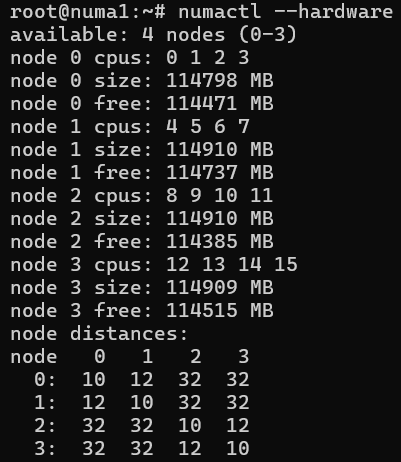
Esta configuración muestra que el acceso a la memoria dentro del mismo nodo tiene un nivel de distancia de 10. Si desea acceder a la memoria en Node 1 desde Node 0, este proceso tiene un valor de distancia alto de 12, pero sigue siendo manejable. Sin embargo, si desea acceder a la memoria en NODE 3 desde NODE 0, el nivel de distancia se convierte en 32. Este proceso sigue siendo factible, pero también es tres veces más lento. Es útil tener en cuenta estas diferencias al diagnosticar problemas de rendimiento o optimizar las cargas de trabajo enlazadas a memoria. Para obtener más información, consulte este artículo de Kernel de Linux. Para obtener una descripción de la numactl herramienta, consulte numactl(8).
Para determinar si existe una realignación de los procesos y se necesitaría un nodo diferente, use la numastat herramienta . La documentación de esta herramienta está disponible en numastat(8). La migratepages herramienta migratepages(8) puede ayudarle a mover las páginas de memoria al nodo correcto.
Sobrecommitimiento y asesino de OOM
La sobrecarga es una opción de diseño importante que puede afectar gravemente al rendimiento y la estabilidad del sistema. El kernel de Linux admite tres modos:
- 'Heurística'
- Siempre comprometerse en exceso
- No se comprometa en exceso
De forma predeterminada, el sistema usa el Heuristic esquema . Este modo ofrece un equilibrio equilibrado entre permitir siempre la sobrecarga de memoria y denegarla estrictamente. Para más información, consulte la documentación del kernel.
Una configuración incorrecta de sobrecompromiso puede impedir la asignación de memoria por parte de las páginas de memoria. Potencialmente, esta condición podría dificultar la creación de nuevos procesos o impedir que las estructuras de kernel internas adquieran suficiente memoria.
Si comprueba que el problema está relacionado con la asignación de memoria, la causa más probable de este problema es la falta de recursos disponibles para el kernel. En este tipo de situación, el asesino OOM (Out-Of-Memory) podría invocarse. Su trabajo consiste en liberar algunas páginas de memoria para usarlas por tareas de kernel u otras aplicaciones. Al invocar al asesino de OOM, el sistema le advierte de que alcanzó sus límites de recursos. Si puede eliminar la posibilidad de una pérdida de memoria, la causa de esta condición podría ser que hay demasiados procesos en ejecución o que los procesos que consumen mucha memoria. Para resolver el problema, considere la posibilidad de aumentar el tamaño de la máquina virtual o mover algunas aplicaciones a otro servidor.
Registros del sistema generados durante eventos de OOM
En esta sección se presenta una técnica para identificar el momento en que se desencadena OOM Killer y para aprender qué información registra el sistema.
El siguiente programa sencillo de C comprueba la cantidad de memoria que se puede asignar dinámicamente en un sistema antes de que se produzca un error.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define ONEGB (1 << 30)
int main() {
int count = 0;
while (1) {
int *p = malloc(ONEGB);
if (p == NULL) {
printf("malloc refused after %d GB\n", count);
return 0;
}
memset(p,1,ONEGB);
printf("got %d GB\n", ++count);
}
}
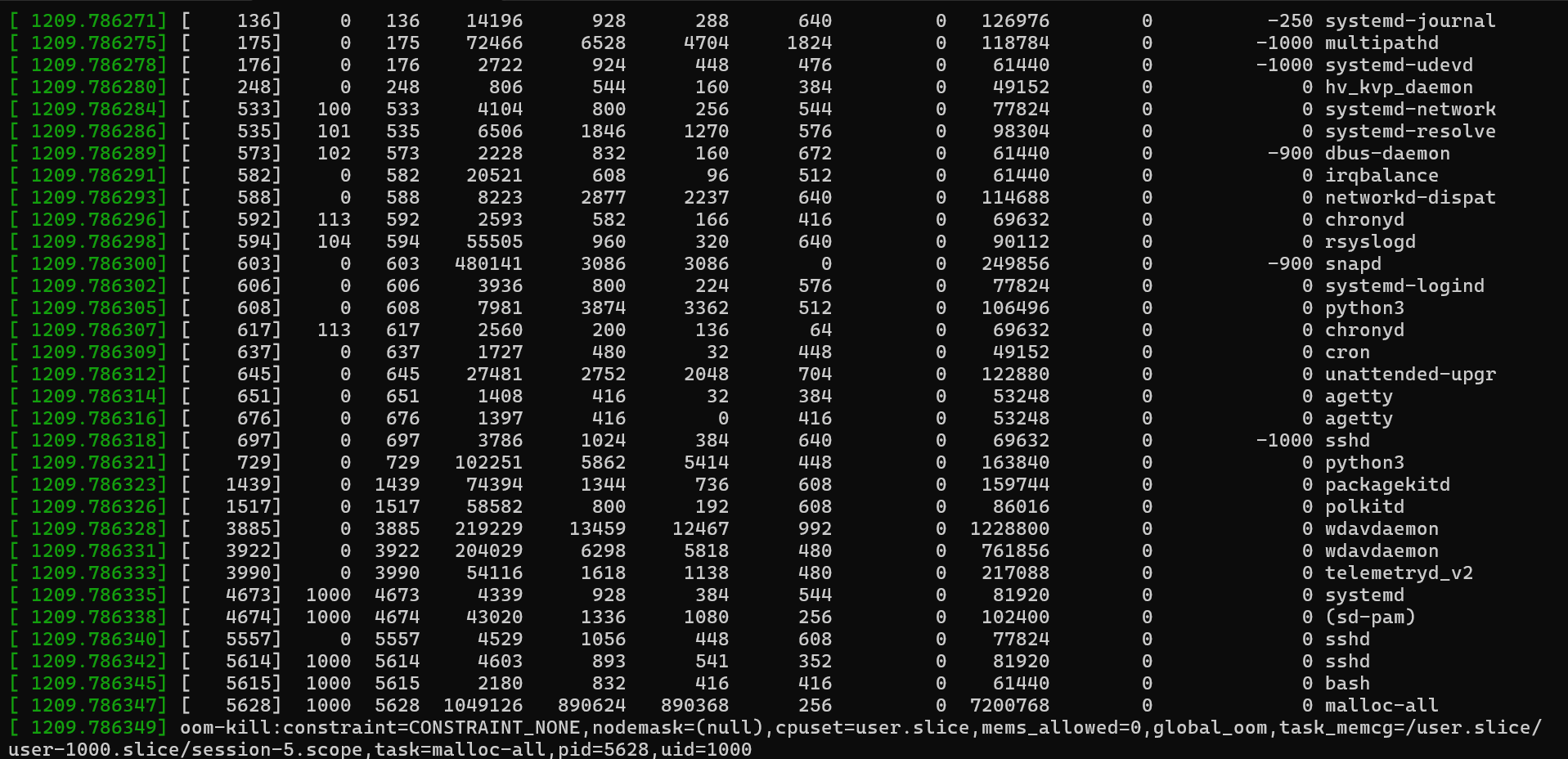
Este programa indica que se produce un error en la asignación de memoria después de aproximadamente 3 GB.

Cuando el sistema se queda sin memoria, se invoca al asesino de OOM. Puede ver los registros relacionados mediante el dmesg comando . Las entradas de registro normalmente comienzan como se muestra en la captura de pantalla siguiente.

Las entradas suelen terminar en un resumen del estado de memoria.

Entre esas entradas, puede encontrar información detallada sobre el uso de memoria y el proceso seleccionado para la finalización.
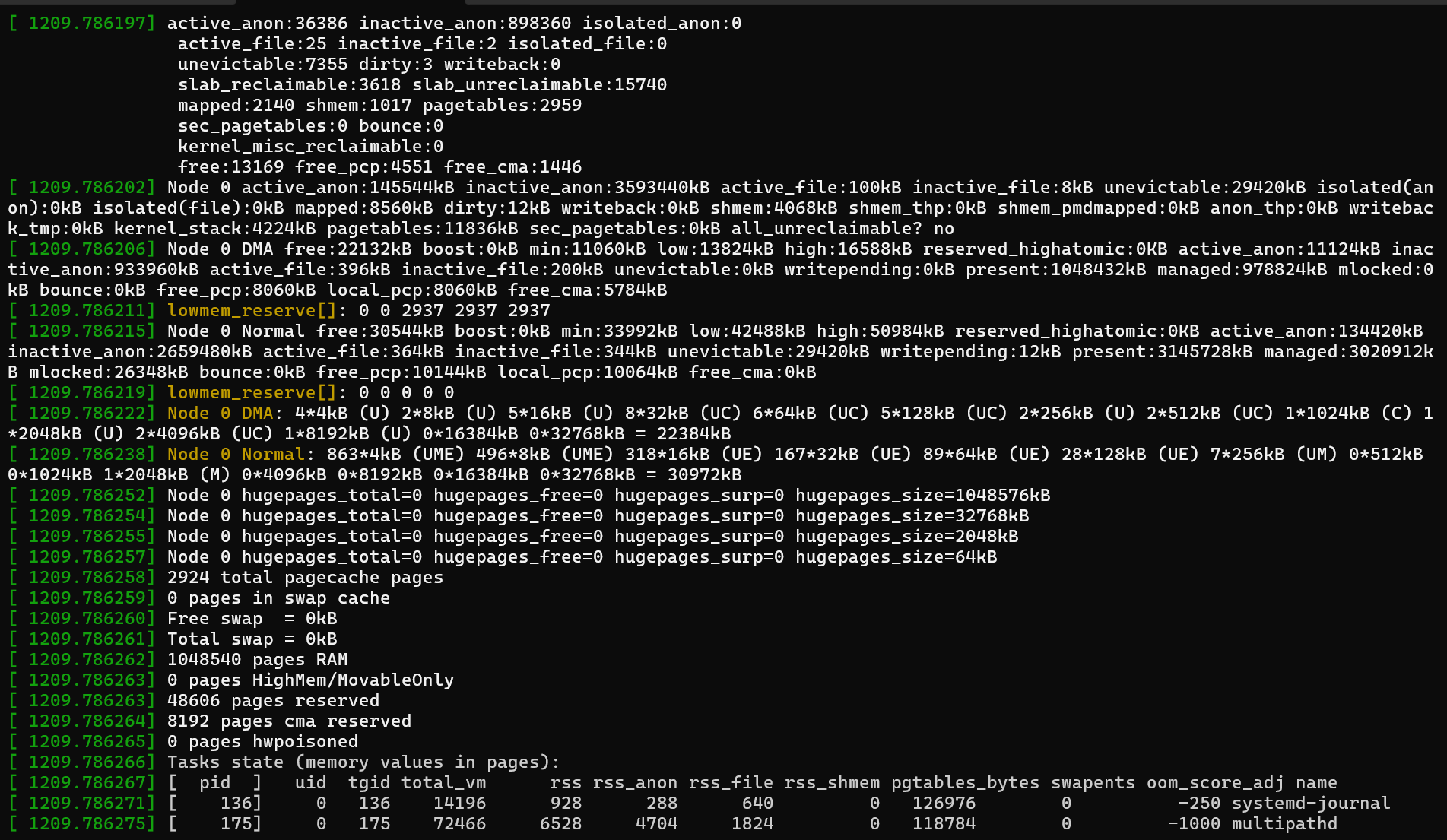
A partir de esta información, puede extraer las siguientes conclusiones:
4194160 kBytes physical memory
No swap space
3829648 kBytes are in use
En el ejemplo de registro siguiente, el proceso malloc solicitó una sola página de 4 KB (order=0). Aunque la página de 4 KB es pequeña, el sistema ya estaba bajo presión. El registro muestra que se asignó memoria desde la "Zona normal".

La memoria disponible (free) es de 29 500 KB. Sin embargo, la marca de agua mínima (min) es de 34 628 KB. Dado que el sistema está por debajo de este umbral, solo el kernel puede usar la memoria restante y se deniegan las aplicaciones de espacio de usuario. El asesino de OOM se invoca en este momento. Selecciona el proceso que tiene el uso más alto oom_score y de memoria ("RSS"). En este ejemplo, el proceso de malloc tenía un oom_score valor de 0, pero también tiene el valor más alto RSS (917760). Por lo tanto, se selecciona como destino para la finalización.
Supervisión del crecimiento gradual de la memoria
Los eventos de OOM son fáciles de detectar porque los mensajes relacionados se registran en la consola y los registros del sistema. Sin embargo, los aumentos graduales del uso de memoria que no provocan un evento OOM pueden ser más difíciles de detectar.
Para supervisar el uso de memoria con el tiempo, use la sar herramienta del sysstat paquete. Para centrarse en los detalles de la memoria, use la opción "r" (por ejemplo, "sar -r").
Salida del ejemplo
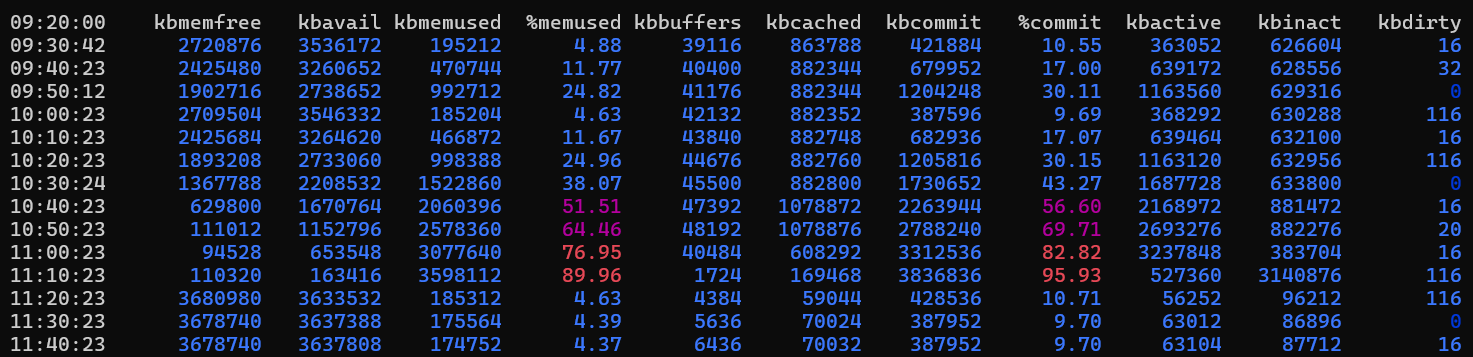
En este caso, el uso de memoria aumenta durante aproximadamente dos horas. Después, vuelve al cuatro por ciento. Este comportamiento puede esperarse, como durante las horas de inicio de sesión punta o las tareas de informes que consumen muchos recursos. Para determinar si este comportamiento es normal, es posible que tenga que supervisar el uso durante varios días y, a continuación, correlacionarlo con la actividad de la aplicación. El uso elevado de memoria no es necesariamente un problema. Depende de la carga de trabajo y de cómo las aplicaciones están diseñadas para usar memoria.
Para buscar qué procesos consumen más memoria, use pidstat.
Salida del ejemplo
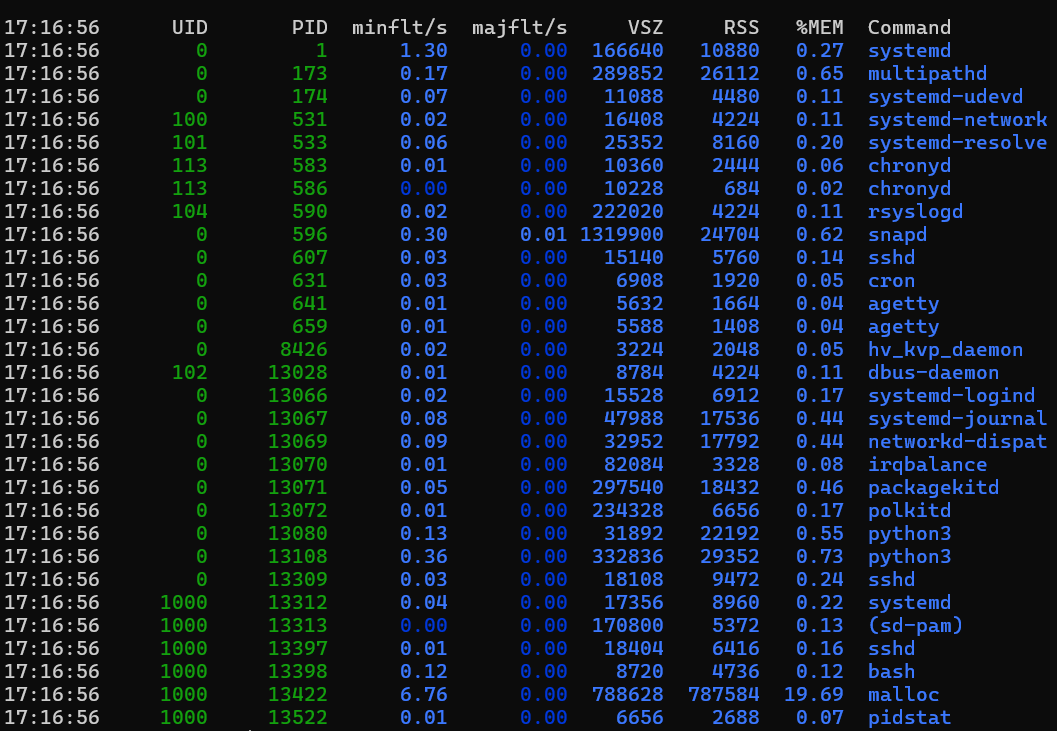
Esta salida muestra todos los procesos en ejecución y sus estadísticas. Otro enfoque consiste en usar la herramienta "ps" para obtener resultados similares: ps aux --sort=-rss | head -n 10
Salida del ejemplo

¿Por qué ordenar por RSS?
El tamaño del conjunto residente (RSS) es la parte de la memoria del proceso que se mantiene en RAM (memoria física que no se intercambia). En cambio, el tamaño del conjunto virtual (VSZ) representa la cantidad total de memoria que reserva el proceso, incluida la memoria que no se compromete.
Committed memory hace referencia a páginas que efectivamente se escriben en la memoria física. Si está intentando identificar qué procesos usan la memoria física más (incluido el intercambio), céntrese en la RSS columna. En la salida del ejemplo, el snapd proceso parece usar una gran cantidad de memoria, pero su RSS valor es bajo. El malloc proceso tiene valores similares VSZ y RSS que indican que usa activamente más de 1,3 GB de memoria.
Descargo de responsabilidad sobre contacto con terceros
Microsoft proporciona información de contacto de terceros para ayudarle a encontrar información adicional sobre este tema. Esta información de contacto puede cambiar sin previo aviso. Microsoft no garantiza la exactitud de la información de contacto de terceros.
Ponte en contacto con nosotros para obtener ayuda
Si tiene preguntas o necesita ayuda, cree una solicitud de soporte o busque consejo en la comunidad de Azure. También puede enviar comentarios sobre el producto a la comunidad de comentarios de Azure.