Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Este artículo le ayuda a resolver problemas que se producen durante la conmutación automática por error en Microsoft SQL Server.
Versión del producto original: SQL Server
Número de KB original: 2833707
Resumen
Los grupos de disponibilidad AlwaysOn de SQL Server se pueden configurar para la conmutación automática por error. Si se detecta un problema de mantenimiento en la instancia de SQL Server que hospeda la réplica principal, el rol principal se puede pasar al asociado de conmutación automática por error (réplica secundaria). Sin embargo, la réplica secundaria no siempre se puede realizar la transición al rol principal. En algunos casos, solo se puede realizar la RESOLVING transición al rol. En esta situación, ninguna réplica tendrá el rol principal a menos que la réplica principal vuelva a un estado correcto. Además, las bases de datos de disponibilidad serán inaccesibles.
En este artículo se enumeran algunas causas comunes de la conmutación automática por error incorrecta y se describen los pasos que puede seguir para diagnosticar la causa de estos errores.
Síntomas si se desencadena correctamente una conmutación automática por error
Cuando se desencadena una conmutación automática por error en la instancia de SQL Server que hospeda la réplica principal, la réplica secundaria pasa al RESOLVING rol y, a continuación, al rol principal. Aunque el proceso se realiza correctamente, las entradas de error se registran en el informe de registro de SQL Server similar al texto siguiente:
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

Nota:
La réplica secundaria realiza una transición correcta de un RESOLVING_NORMAL estado a un PRIMARY_NORMAL estado.
Síntomas si una conmutación automática por error no se realiza correctamente
Si un evento de conmutación automática por error no se realiza correctamente, la réplica secundaria no realiza correctamente la transición al rol principal. Por lo tanto, la réplica de disponibilidad notificará que esta réplica está en un RESOLVING estado. Además, las bases de datos de disponibilidad notifican que están en un NOT SYNCHRONIZING estado y las aplicaciones no pueden acceder a estas bases de datos.
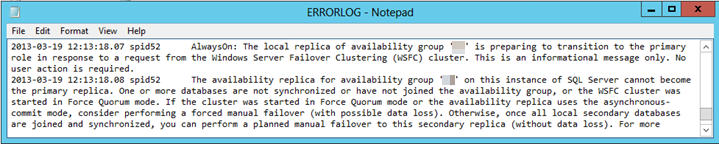
Por ejemplo, en la siguiente imagen, SQL Server Management Studio informa de que la réplica secundaria está en un RESOLVING estado porque el proceso de conmutación automática por error no pudo realizar la transición de la réplica secundaria al rol principal.
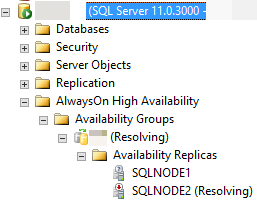
En las secciones siguientes se describen varias posibles razones por las que es posible que la conmutación automática por error no se realice correctamente y cómo diagnosticar cada causa.
Caso 1: se agota el valor "Errores máximos en el período especificado"
El grupo de disponibilidad tiene propiedades de recursos de clúster de Windows, como errores máximos en la propiedad Período especificado. Esta propiedad se usa para evitar el movimiento indefinido de un recurso agrupado cuando se producen varios errores de nodo.
Para investigar y diagnosticar si se trata de la causa de una conmutación por error incorrecta, revise el registro del clúster de Windows (Cluster.log) y, a continuación, compruebe la propiedad .
Paso 1: Revisar los datos en el registro del clúster de Windows (Cluster.log)
Use Windows PowerShell para generar el registro del clúster de Windows en el nodo de clúster que hospeda la réplica principal. Para ello, ejecute el siguiente cmdlet en una ventana de PowerShell con privilegios elevados en la instancia de SQL Server que hospeda la réplica principal:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
[NOTAS]
- El
-TimeSpan 15parámetro de este paso supone que el problema que se está diagnosticando se produjo durante los 15 minutos anteriores. - De forma predeterminada, el archivo de registro se crea en %WINDIR%\cluster\reports.
- El
Abra el archivo Cluster.log en el Bloc de notas para revisar el registro del clúster de Windows.
En el Bloc de notas, seleccione Editar>búsqueda y busque la cadena "failoverCount" al final del archivo. En los resultados, debe encontrar un mensaje similar al siguiente:
No conmutar por error el nombre> de recurso del grupo<, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2

Paso 2: Comprobar los errores máximos en la propiedad Período especificado
Inicie el Administrador de clústeres de conmutación por error.
En el panel de navegación, seleccione Roles.
En el panel Roles , haga clic con el botón derecho en el recurso agrupado y, a continuación, seleccione Propiedades.
Seleccione la pestaña Conmutación por error y seleccione los errores máximos en el valor Período especificado.
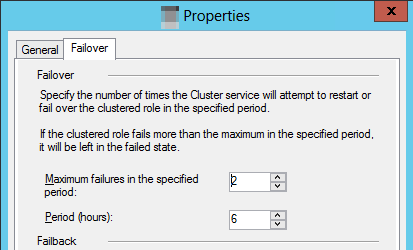
Nota:
El comportamiento predeterminado especifica que si se produce un error en el recurso agrupado tres veces en seis horas, debe permanecer en estado de error. Para un grupo de disponibilidad, esto significa que la réplica se deja en el
RESOLVINGestado .
Conclusión
Después de analizar el registro, verá que el valor failoverCount de 3 es mayor que el valor computedFailoverThreshold de 2. Por lo tanto, el clúster de Windows no puede completar la operación de conmutación por error del recurso del grupo de disponibilidad al asociado de conmutación por error.
Resolución
Para resolver este problema, aumente los errores máximos en el valor período especificado.
Nota:
Aumentar este valor podría no resolver el problema. Puede haber un problema más crítico que hace que el grupo de disponibilidad produzca errores muchas veces en un breve período. De forma predeterminada, este período es de 15 minutos. Aumentar este valor podría simplemente hacer que el grupo de disponibilidad produzca un error más veces y permanezca en estado de error. Se recomienda usar una solución de problemas agresiva para determinar por qué se sigue produciendo la conmutación automática por error.
Caso 2: Permisos de cuenta de NT Authority\SYSTEM insuficientes
El archivo DLL de recursos de SQL Server Motor de base de datos se conecta a la instancia de SQL Server que hospeda la réplica principal mediante ODBC para supervisar el estado. Las credenciales de inicio de sesión que se usan para esta conexión son la cuenta de inicio de sesión de SQL Server NT AUTHORITY\SYSTEM local. De forma predeterminada, a esta cuenta de inicio de sesión local se le conceden los siguientes permisos:
- Modificar cualquier grupo de disponibilidad
- Conexión de SQL
- Ver el estado del servidor
Si la NT AUTHORITY\SYSTEM cuenta de inicio de sesión no tiene ninguno de estos permisos en el asociado de conmutación automática por error (la réplica secundaria), SQL Server no puede iniciar la detección de estado cuando se produce una conmutación automática por error. Por lo tanto, la réplica secundaria no puede realizar la transición al rol principal. Para investigar y diagnosticar si esta es la causa, revise el registro del clúster de Windows. Para ello, siga estos pasos:
Use Windows PowerShell para generar el registro del clúster de Windows en el nodo del clúster. Para ello, ejecute el siguiente cmdlet en una ventana de PowerShell con privilegios elevados en la instancia de SQL Server que hospeda la réplica secundaria que no ha pasado al rol principal:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
Abra el archivo Cluster.log en el Bloc de notas para revisar el registro del clúster de Windows.
Busque la entrada de error similar al texto siguiente:
No se pudo ejecutar el comando diagnostics. El usuario no tiene permiso para realizar esta acción.
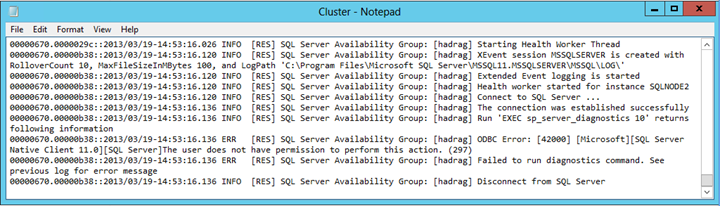
Conclusión
El archivo Cluster.log informa de que existe un problema de permisos cuando SQL Server ejecuta el comando de diagnóstico. En este ejemplo, el error se debió a la eliminación del permiso ver estado del servidor de la NT AUTHORITY\SYSTEM cuenta de inicio de sesión en la instancia de SQL Server que hospeda la réplica secundaria de un par de conmutación automática por error.
Resolución
Para resolver este problema, conceda permisos suficientes a la NT AUTHORITY\SYSTEM cuenta de inicio de sesión para la detección de estado de la DLL de recursos de SQL Server Motor de base de datos.
Caso 3: Las bases de datos de disponibilidad no están en estado SYNCHRONIZED
Para conmutar por error automáticamente, todas las bases de datos de disponibilidad definidas en el grupo de disponibilidad deben estar en un SYNCHRONIZED estado entre la réplica principal y la réplica secundaria. Cuando se produce una conmutación automática por error, esta condición de sincronización debe cumplirse para asegurarse de que no haya ninguna pérdida de datos. Por lo tanto, si una base de datos de disponibilidad del grupo de disponibilidad está en el estado o NOT SYNCHRONIZED sincronización, la conmutación automática por error no pasará correctamente la réplica secundaria al rol principal.
Para obtener más información sobre las condiciones necesarias para una conmutación automática por error, consulte Las condiciones necesarias para una conmutación automática por error y las réplicas de confirmación sincrónica admiten dos secciones de configuración de conmutación por error y modos de conmutación por error (grupos de disponibilidad AlwaysOn).
Para investigar y diagnosticar si se trata de la causa de la conmutación por error incorrecta, revise el registro de errores de SQL Server. Debe encontrar una entrada de error similar al texto siguiente:
Una o varias bases de datos no están sincronizadas o no se han unido al grupo de disponibilidad.
Para comprobar si las bases de datos de disponibilidad estaban en estado SYNCHRONIZED , siga estos pasos:
Conéctese a la réplica secundaria.
Ejecute el siguiente script SQL para comprobar el
is_failover_readyvalor de todas las bases de datos de disponibilidad del grupo de disponibilidad que no conmutó por error.Nota:
Un valor de cero para cualquiera de las bases de datos de disponibilidad puede impedir la conmutación automática por error. Este valor indica que la base de datos de disponibilidad no
SYNCHRONIZEDera .SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)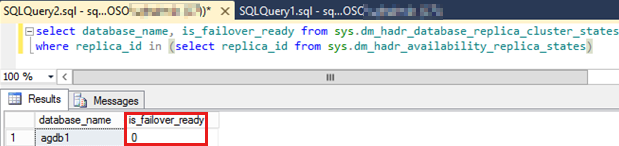
Conclusión
Una conmutación automática por error correcta del grupo de disponibilidad requiere que todas las bases de datos de disponibilidad estén en estado SYNCHRONIZED . Para obtener más información sobre los modos de disponibilidad, consulte Modos de disponibilidad en grupos de disponibilidad AlwaysOn.
Caso 4: la configuración de "Forzar cifrado de protocolo" está seleccionada para los protocolos de cliente en la réplica secundaria (principal de destino), aunque la réplica no está configurada para el cifrado
Durante la conmutación por error, cuando el servidor principal detecta un problema de mantenimiento, el archivo DLL del clúster en el asociado de conmutación por error (réplica secundaria) intenta conectarse a la réplica local para iniciar la supervisión del estado. Esto forma parte de la transición al rol principal. Si la réplica secundaria no está configurada para el cifrado, pero la configuración Forzar cifrado de protocolo se establece involuntariamente en la configuración del cliente, se producirá un error en la conexión y no se puede producir la conmutación por error.
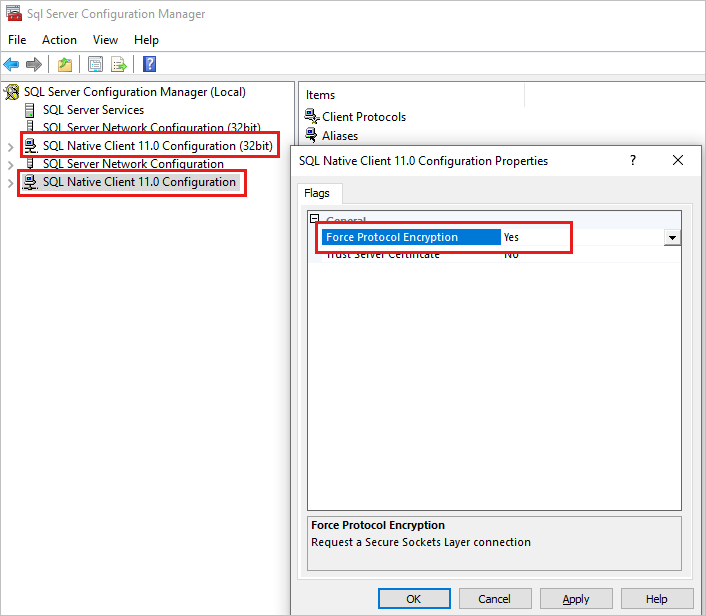
Para comprobar esta configuración:
- Inicie el Administrador de configuración de SQL Server.
- En el panel izquierdo, haga clic con el botón derecho en la configuración de SQL Native Client 11.0 y, a continuación, seleccione Propiedades.
- En el cuadro de diálogo, active la opción Forzar cifrado de protocolo. Si se establece en Sí, cambie el valor a No.
- Vuelva a probar la conmutación por error.
Conclusión
La supervisión del estado AlwaysOn de SQL Server usa una conexión ODBC local para supervisar el estado de SQL Server. Forzar el cifrado de protocolo debe estar habilitado en la sección Configuración del cliente de Administrador de configuración de SQL Server solo si SQL Server se configuró para forzar cifrados en Administrador de configuración de SQL Server en la red de SQL Server Sección configuración. Para más información, vea Habilitación de conexiones cifradas en Motor de base de datos.
Caso 5: Los problemas de rendimiento en la réplica secundaria o el nodo provocan un error en las comprobaciones de estado de AlwaysOn
Antes de conmutar por error desde la réplica principal a la réplica secundaria, SQL Server Motor de base de datos dll de recursos se conecta a la réplica secundaria para determinar el estado de la réplica. Si se produce un error en esta conexión debido a problemas de rendimiento en la réplica secundaria, no se produce la conmutación automática por error.
Para investigar y diagnosticar si esta es la causa, siga estos pasos:
Revise el registro de clúster en la réplica secundaria para comprobar el mensaje de error "No se puede completar el proceso de inicio de sesión debido a un retraso en la apertura de la conexión del servidor".
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.Esta situación puede producirse si la conmutación por error se realiza en una réplica secundaria de SQL Server que tiene una carga de trabajo existente ocupada. Esto podría retrasar la respuesta de SQL Server al intento de solicitud de conexión de mantenimiento hadR y evitar un intento de conmutación por error correcto.
Para determinar si hay presión en los programadores del sistema, use SQL Server Management Studio para ejecutar el siguiente script en la réplica secundaria:
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' ENDA continuación se muestra la salida de ejemplo de la consulta anterior:
CurrentDate TotalThreads CurrentThreads AvailableThreads WorkersWaitingForCpu RequestWaitingForThreads 2020-10-06 01:27:01.337 1216 361 855 33 0 2020-10-06 01:27:08.340 1216 1412 -196 22 76 2020-10-06 01:27:15.340 1216 1304 -88 2 161 2020-10-06 01:27:22.340 1216 1242 26- 21 185 2020-10-06 01:27:29.343 1216 13:46 -130 19 476 2020-10-06 01:27:36.350 1216 1350 -134 9 630 2020-10-06 01:27:43.353 1216 13:46 -130 13 539 2020-10-06 01:27:50.360 1216 1378 -162 5 328 2020-10-06 01:27:57.360 1216 197 1019 0 0 Valores altos notificados para
WorkersWaitingForCpueRequestWaitingForThreadsindican que se está produciendo contención de programación y que SQL Server no puede atender la carga de trabajo actual de forma oportuna.
Resolución
Si experimenta este problema, reequilibra la carga de trabajo en la réplica secundaria o considere la posibilidad de aumentar la potencia de procesamiento (agregar procesadores) en los equipos que ejecutan estas cargas de trabajo.
Solución de problemas de otros eventos de conmutación por error
Para supervisar el estado de la nueva réplica principal durante la conmutación por error, debe conectar localmente la supervisión del estado AlwaysOn a la instancia de SQL Server que realiza la transición al rol principal.
Además de las razones más comunes que se describen en este artículo, hay muchas otras razones por las que este intento de conexión podría producir un error. Para investigar un intento de conmutación por error con errores, revise el registro del clúster en el asociado de conmutación por error (la réplica a la que no se pudo conmutar por error):
Use Windows PowerShell para generar el registro del clúster de Windows en el nodo del clúster. Para ello, ejecute el siguiente cmdlet en una ventana de PowerShell con privilegios elevados en la instancia de SQL Server que hospeda la réplica secundaria que no ha pasado al rol principal. Se generará un registro de clúster durante los últimos 60 minutos de actividad.
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60Para revisar el registro del clúster de Windows, abra el archivo Cluster.log en el Bloc de notas.
Busque la cadena "Conectar a SQL Server" que se encuentra durante el evento de conmutación por error incorrecto.
Revise los mensajes de inicio de sesión posteriores mediante el identificador de subproceso (consulte la captura de pantalla siguiente) para correlacionar los eventos relacionados con el evento de inicio de sesión. En el ejemplo siguiente se muestra una búsqueda de "Conectar con SQL Server". También se muestra el uso del identificador de subproceso (lado izquierdo) para buscar el otro diagnóstico que describe por qué se produjo un error en el intento de conexión.
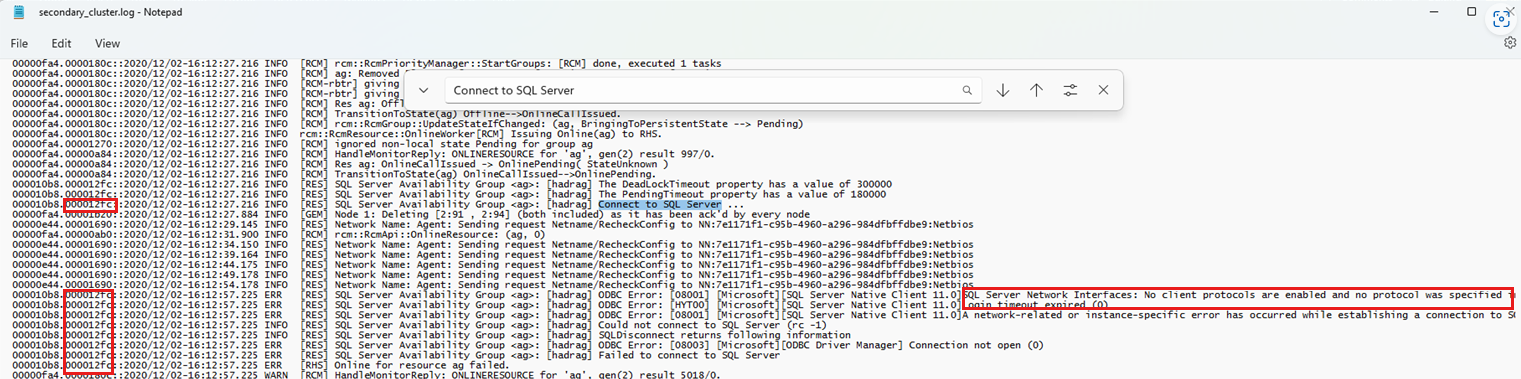

En los ejemplos siguientes se muestran errores de conexión a la nueva réplica principal.
Conjunto de ejemplo 1
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
Resolución
Inicie Administrador de configuración de SQL Server y compruebe que la memoria compartida o TCP/IP está habilitada en Protocolos de cliente para la configuración de SQL Native Client.
Conjunto de ejemplo 2
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
Resolución
Inicie Administrador de configuración de SQL Server y compruebe que la memoria compartida o TCP/IP está habilitada en Protocolos de cliente para la configuración de SQL Native Client.
Conjunto de ejemplo 3
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
Resolución
Revisión caso 2: permisos de cuenta de NT Authority\SYSTEM insuficientes.