Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a: SQL Server
En este artículo se proporcionan instrucciones sobre qué problemas de E/S provocan un rendimiento lento de SQL Server y cómo solucionar los problemas.
Definir el rendimiento lento de E/S
Los contadores del monitor de rendimiento se usan para determinar el rendimiento de E/S lento. Estos contadores miden la rapidez con que el subsistema de E/S atiende cada solicitud de E/S en promedio, en términos de tiempo de reloj. Los contadores específicos del monitor de rendimiento que miden la latencia de E/S en Windows son Avg Disk sec/ Read, Avg. Disk sec/Write, y Avg. Disk sec/Transfer (acumulado de las lecturas y escrituras).
En SQL Server, las cosas funcionan de la misma manera. Normalmente, se observa si SQL Server informa de cuellos de botella de E/S medidos en tiempo de CPU (milisegundos). SQL Server realiza solicitudes de E/S al sistema operativo mediante una llamada a las funciones win32 como WriteFile(), ReadFile(), WriteFileGather()y ReadFileScatter(). Cuando publica una solicitud de E/S, SQL Server horas la solicitud e informa de la duración de la solicitud mediante tipos de espera. SQL Server usa tipos de espera para indicar esperas de E/S en diferentes lugares del producto. Las esperas relacionadas con la E/S son:
Si estas esperas superan constantemente los 10-15 milisegundos, la E/S se considera un cuello de botella.
Nota:
Para proporcionar contexto y perspectiva, en el mundo de la solución de problemas de SQL Server, CSS de Microsoft ha observado casos en los que una solicitud de E/S tomó más de un segundo y un máximo de 15 segundos por transferencia, estos sistemas de E/S necesitan optimización. Por el contrario, CSS de Microsoft ha visto sistemas en los que las tasas de transferencia están por debajo de un milisegundo por transferencia. Con la tecnología SSD/NVMe actual, las tasas de rendimiento anunciadas oscilan en decenas de microsegundos por transferencia. Por lo tanto, la figura de transferencia de 10 a 15 milisegundos es un umbral muy aproximado que hemos seleccionado en función de la experiencia colectiva entre los ingenieros de Windows y SQL Server a lo largo de los años. Normalmente, cuando los números superan este umbral aproximado, los usuarios de SQL Server empiezan a ver la latencia en sus cargas de trabajo y los notifican. En última instancia, el rendimiento esperado de un subsistema de E/S está definido por el fabricante, el modelo, la configuración, la carga de trabajo y potencialmente varios otros factores.
Metodología
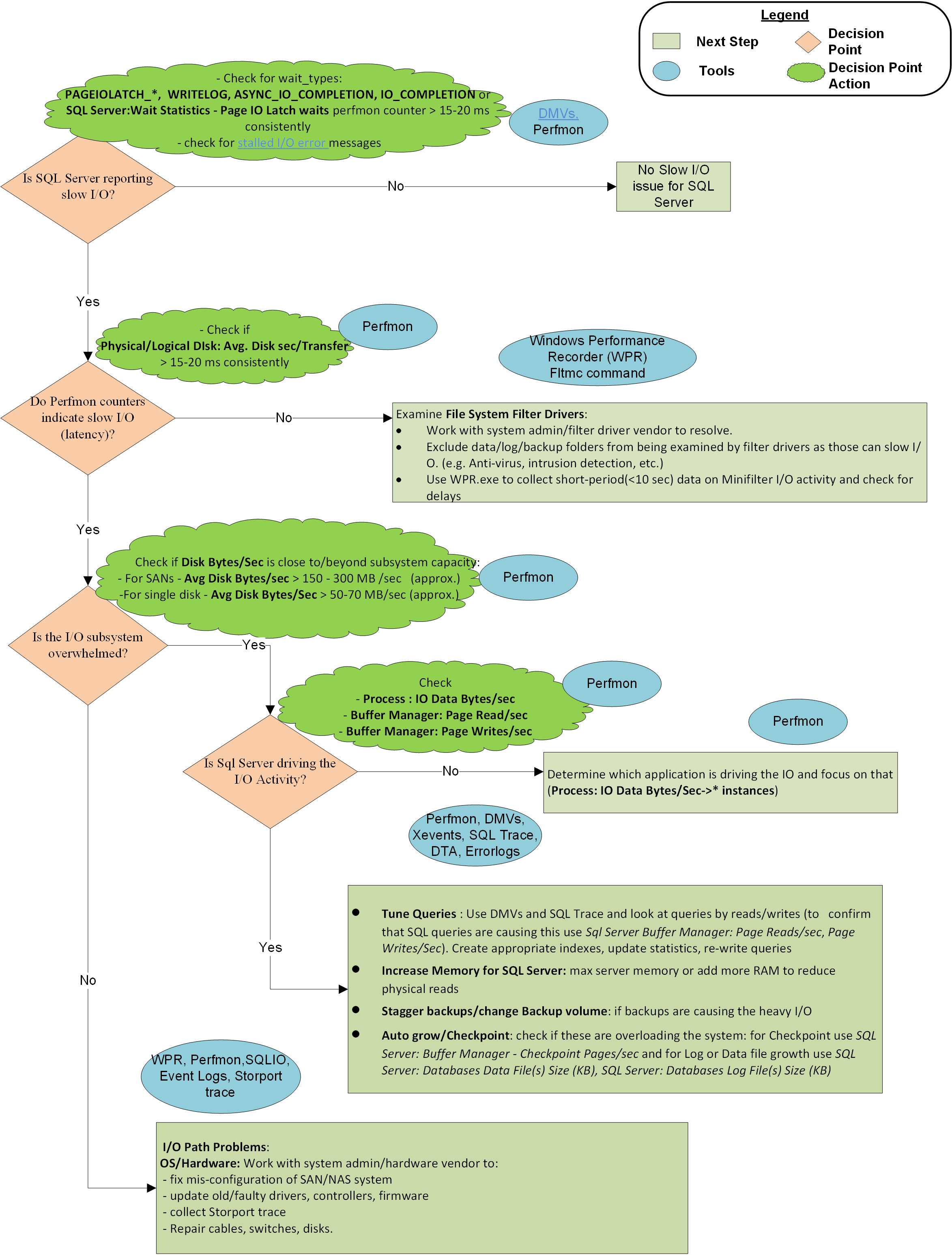
Un gráfico de flujo al final de este artículo describe la metodología que usa Microsoft CSS para abordar problemas de E/S lentos con SQL Server. No es un enfoque exhaustivo o exclusivo, pero ha demostrado ser útil para aislar el problema y resolverlo.
La metodología se describe en estos pasos:
Paso 1: ¿SQL Server informa de una E/S lenta?
SQL Server puede notificar latencia de E/S de varias maneras:
- Tipos de espera de E/S
- DMV
sys.dm_io_virtual_file_stats - Registro de errores o registro de eventos de aplicación
Tipos de espera de E/S
Determine si hay latencia de E/S notificada por los tipos de espera de SQL Server. Los valores PAGEIOLATCH_*, WRITELOG y ASYNC_IO_COMPLETION y los valores de varios otros tipos de espera menos comunes deben mantenerse por debajo de 10-15 milisegundos por solicitud de E/S. Si estos valores son mayores de forma coherente, existe un problema de rendimiento de E/S y requiere una investigación adicional. La consulta siguiente puede ayudarle a recopilar esta información de diagnóstico en el sistema:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
Estadísticas de archivos en sys.dm_io_virtual_file_stats
Para ver la latencia de nivel de archivo de base de datos como se indica en SQL Server, ejecute la consulta siguiente:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Examine las AvgLatency columnas y LatencyAssessment para comprender los detalles de latencia.
Error 833 notificado en registro de errores o registro de eventos de aplicación
En algunos casos, puede observar el error 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) en el registro de errores. Para comprobar los registros de errores de SQL Server en el sistema, ejecute el siguiente comando de PowerShell:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Además, para obtener más información sobre este error, consulte la sección MSSQLSERVER_833 .
Paso 2: ¿Los contadores perfmon indican latencia de E/S?
Si SQL Server notifica latencia de E/S, consulte contadores del sistema operativo. Puede determinar si hay un problema de E/S examinando el contador Avg Disk Sec/Transferde latencia . El siguiente fragmento de código indica una manera de recopilar esta información a través de PowerShell. Recopila contadores en todos los volúmenes de disco: "_total". Cambie a un volumen de unidad específico (por ejemplo, "D:"). Para buscar qué volúmenes hospedan los archivos de base de datos, ejecute la consulta siguiente en SQL Server:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Reúna Avg Disk Sec/Transfer métricas sobre el volumen de su elección.
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
Si los valores de este contador están constantemente por encima de 10-15 milisegundos, debe examinar el problema más a fondo. Los picos ocasionales no cuentan en la mayoría de los casos, pero asegúrese de comprobar la duración de un pico. Si el pico duró un minuto o más, es más bien una meseta que un pico.
Si los contadores del monitor de rendimiento no notifican latencia, pero SQL Server sí, el problema se produce entre SQL Server y el Administrador de particiones, es decir, los controladores de filtro. El Administrador de particiones es una capa de E/S donde el sistema operativo recopila contadores de Perfmon . Para solucionar la latencia, asegúrese de que se realicen adecuadamente las exclusiones de los controladores de filtro y resuelva los problemas del controlador de filtro. Los controladores de filtro se usan en programas como software antivirus, soluciones de copia de seguridad, cifrado, compresión, etc. Puede usar este comando para enumerar los controladores de filtro en los sistemas y los volúmenes a los que están asociados. A continuación, podrá buscar los nombres de controladores y proveedores de software en el artículo Altitudes de filtro asignadas.
fltmc instances
Para obtener más información, vea Cómo elegir software antivirus para ejecutarse en equipos que ejecutan SQL Server.
Evite usar el sistema de cifrado de archivos (EFS) y la compresión del sistema de archivos porque hacen que la E/S asincrónica se convierta en sincrónica y, por lo tanto, sea más lenta. Para obtener más información, consulte el artículo sobre cómo la E/S de disco asíncrona aparece como sincrónica en Windows.
Paso 3: ¿El subsistema de E/S está sobrecargado más allá de la capacidad?
Si SQL Server y el sistema operativo indican que el subsistema de E/S es lento, compruebe si la causa es que el sistema está sobrecargado más allá de la capacidad. Puede comprobar la capacidad examinando los contadores de E/SDisk Bytes/Sec, Disk Read Bytes/Sec o Disk Write Bytes/Sec. Asegúrese de consultar con el administrador del sistema o el proveedor de hardware las especificaciones de rendimiento esperadas para la SAN (u otro subsistema de E/S). Por ejemplo, no puede insertar más de 200 MB/s de E/S a través de una tarjeta HBA de 2 GB/s o un puerto dedicado de 2 GB/s en un conmutador SAN. La capacidad de rendimiento esperada definida por un fabricante de hardware define cómo proceder desde aquí.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Paso 4: ¿SQL Server impulsa la actividad de E/S pesada?
Si el subsistema de E/S está sobrecargado más allá de la capacidad, averigüe si SQL Server es el culpable examinando Buffer Manager: Page Reads/Sec (culpable más común) y Page Writes/Sec (mucho menos común) para la instancia específica. Si SQL Server es el controlador de E/S principal y el volumen de E/S va más allá de lo que el sistema puede controlar, trabaje con los equipos de desarrollo de aplicaciones o con el proveedor de aplicaciones para:
- Ajuste de consultas, por ejemplo: mejores índices, actualizar estadísticas, reescribir consultas y rediseñar la base de datos.
- Aumente la memoria máxima del servidor o agregue más RAM en el sistema. Más memoria RAM almacenará más datos o páginas de índice sin volver a leer con frecuencia desde el disco, lo que reducirá la actividad de entrada/salida. El aumento de la memoria también puede reducir
Lazy Writes/sec, que son impulsados por los vaciados del Lazy Writer cuando hay una necesidad frecuente de almacenar más páginas de base de datos en la memoria limitada. - Si encuentra que las escrituras de páginas son el origen de una actividad de E/S intensiva, examine
Buffer Manager: Checkpoint pages/secpara ver si se debe a vaciados masivos de página necesarios para satisfacer las demandas de configuración del intervalo de recuperación. Puede usar puntos de control indirectos para nivelar la E/S a lo largo del tiempo o aumentar el rendimiento de la E/S del hardware.
Causas
En general, los siguientes problemas son las razones de alto nivel por las que las consultas de SQL Server sufren de latencia de E/S:
Problemas de hardware:
Una configuración incorrecta de SAN (conmutador, cables, HBA, almacenamiento)
Capacidad de E/S superada (desequilibrada en toda la red SAN, no solo almacenamiento back-end)
Problemas de controladores o firmware
Los proveedores de hardware o los administradores del sistema deben participar en esta fase.
Problemas de consulta: SQL Server satura los volúmenes de disco con solicitudes de E/S e inserta el subsistema de E/S más allá de la capacidad, lo que hace que las tasas de transferencia de E/S sean altas. En este caso, la solución consiste en buscar las consultas que causan un gran número de lecturas lógicas (o escrituras) y ajustar esas consultas para minimizar la E/S del disco mediante índices adecuados es el primer paso para hacerlo. Además, mantenga actualizadas las estadísticas a medida que proporcionan al optimizador de consultas información suficiente para elegir el mejor plan. Además, el diseño incorrecto de la base de datos y el diseño de consultas pueden provocar un aumento en los problemas de E/S. Por lo tanto, rediseñar las consultas y, a veces, las tablas pueden ayudar con una E/S mejorada.
Controladores de filtro: la respuesta de E/S de SQL Server puede verse afectada gravemente si los controladores de filtro del sistema de archivos procesan tráfico intensivo de E/S. Se recomiendan exclusiones de archivos adecuadas del examen antivirus y el diseño correcto del controlador de filtro por parte de los proveedores de software para evitar el impacto en el rendimiento de E/S.
Otras aplicaciones: otra aplicación de la misma máquina con SQL Server puede saturar la ruta de acceso de E/S con solicitudes de lectura o escritura excesivas. Esta situación puede llevar al subsistema de E/S más allá de los límites de capacidad y provocar lentitud en las operaciones de E/S para SQL Server. Identifique la aplicación y ajustela o muévala en otro lugar para eliminar su impacto en la pila de E/S.
Representación gráfica de la metodología
Información sobre los tipos de espera relacionados con E/S
A continuación se describen los tipos de espera comunes observados en SQL Server cuando se notifican problemas de E/S de disco.
PAGEIOLATCH_EX
Se produce cuando una tarea espera un bloqueo temporal para una página de datos o de índice (búfer) en una solicitud de E/S. La solicitud de bloqueo temporal está en modo exclusivo. Se usa un modo exclusivo cuando el búfer se escribe en el disco. Las esperas largas pueden indicar problemas en el subsistema del disco.
PAGEIOLATCH_SH
Se produce cuando una tarea está esperando un bloqueo temporal para una página de datos o índice (búfer) en una solicitud de E/S. La solicitud de cerrojo está en modo compartido. El modo compartido se usa cuando el búfer se lee desde el disco. Las esperas largas pueden indicar problemas en el subsistema del disco.
PAGEIOLATCH_UP
Se produce cuando una tarea está esperando un bloqueo temporal para un búfer en una solicitud de E/S. La solicitud de bloqueo temporal está en modo de actualización. Las esperas largas pueden indicar problemas en el subsistema del disco.
WRITELOG
Se produce cuando una tarea está esperando a que se complete un vaciado del registro de transacciones. Un vaciado se produce cuando el Administrador de registros escribe su contenido temporal en el disco. Las operaciones comunes que provocan vaciados de registro son confirmaciones de transacciones y puntos de comprobación.
Las razones comunes para las largas esperas WRITELOG son:
Latencia del disco del registro de transacciones: esta es la causa más común de
WRITELOGlas esperas. Por lo general, la recomendación es mantener los archivos de datos y de registro en volúmenes independientes. Las escrituras en el registro de transacciones son secuenciales, mientras que la lectura o escritura de datos desde un archivo de datos son aleatorias. La combinación de datos y archivos de registro en un volumen de unidad (especialmente las unidades de disco giratorias convencionales) provocará un movimiento excesivo de la cabeza del disco.Demasiados VLFs: demasiados archivos de registro virtual (VLFs) pueden provocar
WRITELOGesperas. Demasiados VLFs pueden derivar en otros tipos de problemas, como la recuperación prolongada.Demasiadas transacciones pequeñas: aunque las transacciones grandes pueden provocar bloqueos, demasiadas transacciones pequeñas pueden provocar otro conjunto de problemas. Si no inicia explícitamente una transacción, cualquier inserción, eliminación o actualización dará lugar a una transacción (llamamos a esta transacción automática). Si realiza 1000 inserciones en un bucle, habrá 1000 transacciones generadas. Cada transacción de este ejemplo debe confirmarse, lo que da como resultado un vaciado del registro de transacciones y 1000 vaciados de transacción. Cuando sea posible, agrupe actualizaciones individuales, elimine o inserte en una transacción mayor para reducir el vaciado del registro de transacciones y aumentar el rendimiento. Esta operación puede provocar menos
WRITELOGesperas.Los problemas de programación hacen que los subprocesos del escritor de registros no se programe lo suficientemente rápido: antes de SQL Server 2016, un único subproceso del escritor de registros realizó todas las escrituras de registro. Si hay problemas con la programación de subprocesos (por ejemplo, una CPU elevada), tanto el subproceso del sistema de escritura de registros como los vaciados de registro podrían retrasarse. En SQL Server 2016, se agregaron hasta cuatro subprocesos de escritor de registros para aumentar el rendimiento de escritura de registros. Consulte SQL 2016 - Simplemente se ejecuta más rápido: múltiples trabajadores de escritura de registros. En SQL Server 2019, se agregaron hasta ocho subprocesos de escritor de registros, lo que mejora aún más el rendimiento. Además, en SQL Server 2019, cada subproceso de trabajo normal puede realizar escrituras de registro directamente en lugar de publicar en el subproceso escritor de registros. Con estas mejoras,
WRITELOGlas esperas rara vez se desencadenarían debido a problemas de programación.
ASYNC_IO_COMPLETION
Se produce cuando se producen algunas de las siguientes actividades de E/S:
- El proveedor de inserción en bloque ("Insertar en bloque") usa este tipo de espera al realizar E/S.
- Leer el archivo Undo en LogShipping y dirigir la E/S asincrónica para Log Shipping.
- Leer los datos reales de los archivos de datos durante una copia de seguridad de datos.
IO_COMPLETION
Tiene lugar mientras se espera a que se completen las operaciones de E/S. Este tipo de espera generalmente implica I/O que no están concernientes a las páginas de datos (búferes). Algunos ejemplos son:
- Lectura y escritura de resultados de ordenación o hash desde o hacia el disco durante un derramamiento (verificar el rendimiento del almacenamiento tempdb).
- Leer y escribir spools anticipados en disco (compruebe el almacenamiento de tempdb).
- La lectura de bloques de registro del registro de transacciones (durante cualquier operación que haga que el registro se lea desde el disco, por ejemplo, recuperación).
- Leer una página desde el disco cuando la base de datos aún no está configurada.
- Copia de páginas en una instantánea de base de datos (Copy-on-Write).
- Cierre del archivo de base de datos y la descompresión de archivos.
BACKUPIO
Se produce cuando una tarea de copia de seguridad está esperando datos o está esperando que un búfer almacene datos. Este tipo no es típico, excepto cuando una tarea está esperando un montaje de cinta.