Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se presenta cómo resolver los problemas por los que se eliminan de forma aleatoria los nodos de la pertenencia activa a clústeres de conmutación por error.
Síntomas
Cuando se produce el problema, verá eventos como este evento registrado en el registro de eventos del sistema:
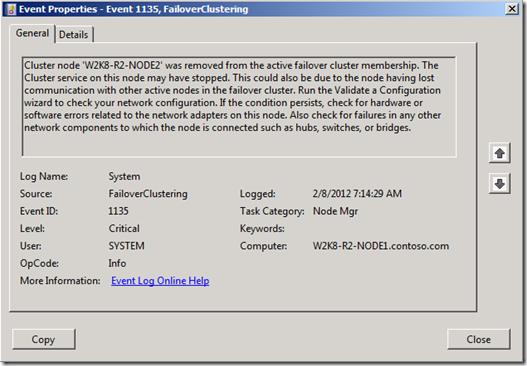
Este evento se registra en todos los nodos del clúster, excepto en el nodo que se quitó. El motivo de este evento es que uno de los nodos del clúster marcó ese nodo como inactivo. A continuación, notifica al resto de nodos del evento. Cuando se envía la notificación a los nodos, estos se interrumpen y eliminan sus conexiones de latido al nodo inactivo.
Causas de que el nodo se marcara como inactivo
Todos los nodos de un clúster de conmutación por error de Windows Server se comuniquen entre sí a través de las redes establecidas para permitir la comunicación de red de clúster en esta red. Los nodos envían paquetes de latido a través de estas redes a todos los demás nodos. Se supone que los demás nodos reciben estos paquetes y, a continuación, devuelven una respuesta. Cada nodo del clúster tiene sus propios latidos que va a supervisar para asegurarse de que la red está activo y los demás nodos están activos. El ejemplo siguiente debe ayudar a aclarar este comportamiento:
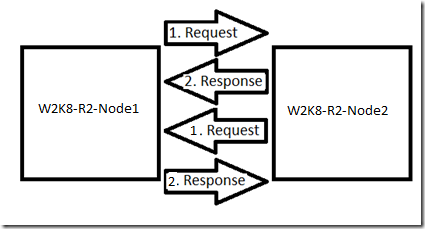
Si no se devuelve alguno de estos paquetes, se considera que se produjo un error en el latido específico. Por ejemplo, W2K8-R2-NODE2 envía una solicitud y recibe una respuesta de W2K8-R2-NODE1 a un paquete de latidos, por lo que determina que la red y el nodo están activos. Si W2K8-R2-NODE1 envía una solicitud a W2K8-R2-NODE2 y W2K8-R2-NODE1 no obtiene la respuesta, se considera un latido perdido y W2K8-R2-NODE1 realiza un seguimiento de ella. Esta respuesta perdida puede hacer que W2K8-R2-NODE1 muestre la red como inactiva hasta que se reciba otra solicitud de latido.
De forma predeterminada, los nodos de clúster tienen un límite de cinco errores en 5 segundos antes de que la conexión se marque como inactiva. Por lo tanto, si W2K8-R2-NODE1 no recibe la respuesta cinco veces en el período de tiempo, considera que la ruta concreta a W2K8-R2-NODE2 está inactiva. Si todavía se considera que otras rutas están activas, W2K8-R2-NODE2 permanecerá como miembro activo.
Si todas las rutas están marcadas para W2K8-R2-NODE2, se quita de la pertenencia activa al clúster de conmutación por error y se registra el evento 1135 que ve en la primera sección. En W2K8-R2-NODE2, se finaliza el servicio de clúster y, a continuación, se reinicia para que pueda intentar volver a unirse al clúster.
Para más información sobre cómo se controlan las rutas específicas que se vuelven inactivas con tres o más nodos, consulte el blog Redes en clúster con particiones escrito por Jeff Hughes.
Ahora que sabemos cómo funciona el proceso de latido, veamos cuales son algunas de las causas conocidas de que se produzca un error durante el proceso
Errores reales del hardware de red. Si el paquete se pierde en la conexión en algún lugar entre los nodos, se producirá un error en los latidos. Un seguimiento de red de los nodos implicados permitirá detectar este problema.
Es posible que el perfil de las conexiones de red rebote de Dominio a Público y vuelva a Dominio. Durante la transición de estos cambios, se puede bloquear la E/S de red. Puede comprobar si este es el caso examinando el registro operativo del perfil de red. Para encontrar este registro, abra el Visor de eventos y vaya a Registros de aplicaciones y servicios\Microsoft\Windows\NetworkProfile\Operational. Examine los eventos de este registro en el nodo que se mencionó en el id. de evento 1135 y compruebe si el perfil estaba cambiando en este momento. Si es así, consulta El perfil de ubicación de red cambia de "Dominio" a "Público" en Windows 7 o en Windows Server 2008 R2.
Tiene IPv6 habilitado en los servidores, pero tiene las dos reglas siguientes deshabilitadas para Entrante y Saliente en el firewall de Windows:
- Redes principales: Anuncio de detección de vecinos
- Redes principales: Solicitud de detección de vecinos
El software antivirus también podría interferir con este proceso. Si sospecha esto, pruebe a deshabilitar o desinstalar el software. Haz esto en tu propio riesgo porque estás desprotegido de virus en este momento.
La latencia en la red también puede provocar que esto suceda. Es posible que los paquetes no se pierdan entre los nodos, pero podrían no llegar a los nodos lo suficientemente rápido antes de que expire el período de tiempo de espera.
IPv6 es el protocolo predeterminado que los clústeres de conmutación por error usarán para sus latidos. El latido en sí es un paquete de redes de unidifusión de UDP que se comunica a través del puerto 3343. Si hay conmutadores, firewalls o enrutadores que no están configurados correctamente para permitir este tráfico, puede experimentar problemas como este.
Las actualizaciones de directivas de seguridad de IPsec también pueden provocar este problema. El problema específico es que, durante una directiva de grupo de IPSec, se descomponen todas las asociaciones de seguridad (SA) de IPsec mediante el firewall de Windows con seguridad avanzada (WFAS). Mientras esto sucede, se bloquea toda la conectividad de red. Al renegociar las asociaciones de seguridad si hay retrasos en realizar la autenticación con Active Directory, estos retrasos (donde se bloquea toda la comunicación de red) también impedirán que los latidos del clúster pasen a través y provoquen que la supervisión del estado del clúster detecte los nodos como inactivos si no responden dentro del umbral de 5 segundos.
Controladores de tarjeta de red o firmware antiguos u obsoletos. En ocasiones, una simple configuración errónea de la tarjeta de red o el conmutador también puede provocar la pérdida de latidos.
Es posible que las tarjetas de red modernas y las tarjetas de red virtual experimenten pérdida de paquetes. Para realizar el seguimiento, abra Monitor de rendimiento y agregue el contador "Interfaz de red\Paquetes recibidos descartados". Este contador es acumulativo y solo aumenta hasta que se reinicia el servidor. Ver un gran número de paquetes descartados aquí podría ser un signo de que los búferes de recepción de la tarjeta de red están establecidos demasiado bajo o que el servidor está funcionando lentamente y no puede controlar el tráfico entrante. Cada fabricante de tarjetas de red decide si desea exponer esta configuración en las propiedades de la tarjeta de red, por lo que debe consultar el sitio web del fabricante para obtener información sobre cómo aumentar estos valores y se deben usar los valores recomendados. Si se ejecuta en VMware, en el blog siguiente se habla de esto con un poco más de detalle, incluido cómo saber si este es el problema, así como le señala al artículo de VMware sobre la configuración que se va a cambiar.
Nodos que se van a quitar de la pertenencia a clústeres de conmutación por error en VMware ESX
Estos son los motivos más comunes por los que se registran estos eventos, pero también puede haber otros. Lo importante de este blog era darle información sobre el proceso y también darle ideas sobre lo que hay que buscar. En algunos casos se elevarán los siguientes valores al máximo para intentar detener este problema.
| Parámetro | Valor predeterminado | Intervalo |
|---|---|---|
| SameSubnetDelay | 1000 milisegundos | 250-2000 milisegundos |
| CrossSubnetDelay | 1000 milisegundos | 250-4000 milisegundos |
| SameSubnetThreshold | 5 | 3-10 |
| CrossSubnetThreshold | 5 | 3-10 |
Aumentar estos valores a su máximo podría hacer que el evento y la eliminación del nodo desaparezcan, simplemente enmascara el problema. No se soluciona nada. Lo mejor que debe hacer es averiguar la causa principal de los errores de latido y corregirlo. La única necesidad real de aumentar estos valores es en un escenario multisitio en el que los nodos residen en diferentes ubicaciones y no se puede superar la latencia de red.