Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
¿Qué es el protocolo de servidor de lenguaje?
La admisión de características de edición enriquecidas como las compleciones automáticas de código fuente o Ir a definición para un lenguaje de programación en un editor o IDE suele ser muy difícil y lenta. Normalmente, requiere escribir un modelo de dominio (un examinador, un analizador, un comprobador de tipos, un generador, etc.) en el lenguaje de programación del editor o IDE. Por ejemplo, el complemento de Eclipse CDT, que proporciona compatibilidad con C/C++ en el IDE de Eclipse, se escribe en Java, ya que el propio IDE de Eclipse está escrito en Java. Siguiendo este enfoque, habría que implementar un modelo de dominio de C/C++ en TypeScript para Visual Studio Code y un modelo de dominio independiente en C# para Visual Studio.
La creación de modelos de dominio específicos del lenguaje también es mucho más fácil si una herramienta de desarrollo puede reutilizar las bibliotecas específicas del lenguaje existentes. Sin embargo, estas bibliotecas se suelen implementar en el propio lenguaje de programación (por ejemplo, los buenos modelos de dominio de C/C++ se implementan en C/C++). La integración de una biblioteca de C/C++ en un editor escrito en TypeScript es técnicamente posible pero difícil de realizar.
Servidores de lenguaje
Otro enfoque consiste en ejecutar la biblioteca en su propio proceso y usar la comunicación entre procesos para comunicarse con ella. Los mensajes enviados de ida y vuelta forman un protocolo. El protocolo de servidor de lenguaje (LSP) es el producto de estandarizar los mensajes intercambiados entre una herramienta de desarrollo y un proceso del servidor de lenguaje. El uso de servidores de lenguaje o demonios no es una idea nueva ni innovadora. Los editores como Vim y Emacs lo han estado haciendo durante algún tiempo para proporcionar compatibilidad con la compleción automática semántica. El objetivo del LSP era simplificar este tipo de integraciones y proporcionar un marco útil para exponer las características del lenguaje a varias herramientas.
Tener un protocolo común permite la integración de características del lenguaje de programación en una herramienta de desarrollo con un mínimo de problemas, ya que se reutiliza una implementación existente del modelo de dominio del lenguaje. Un back-end de servidor de lenguaje podría estar escrito en PHP, Python o Java y el LSP le permitiría integrarse fácilmente en varias herramientas. El protocolo funciona en un nivel común de abstracción para que una herramienta pueda ofrecer servicios de lenguaje enriquecidos sin necesidad de comprender completamente los matices específicos del modelo de dominio subyacente.
Cómo empezó el trabajo con el LSP
El LSP ha evolucionado con el tiempo y hoy está en la versión 3.0. Empezó cuando OmniSharp tomó el concepto de servidor de lenguaje para proporcionar características de edición enriquecidas para C#. Inicialmente, OmniSharp usó el protocolo HTTP con una carga JSON, lo que se ha integrado en varios editores, incluido Visual Studio Code.
Aproximadamente al mismo tiempo, Microsoft comenzó a trabajar en un servidor de lenguaje TypeScript, con la idea de admitir TypeScript en editores como Emacs y Sublime Text. En esta implementación, un editor se comunica a través de stdin/stdout con el proceso del servidor TypeScript y usa una carga JSON inspirada en el protocolo del depurador V8 para las solicitudes y respuestas. El servidor TypeScript se ha integrado en el complemento Sublime de TypeScript y VS Code para la edición enriquecida de TypeScript.
Después de haber integrado dos servidores de lenguaje diferentes, el equipo de VS Code comenzó a explorar un protocolo de servidor de lenguaje común para los editores e IDE. Un protocolo común permite a un proveedor de lenguaje crear un único servidor de lenguaje que los distintos IDE puedan consumir. Un consumidor de servidor de lenguaje solo tiene que implementar el lado cliente del protocolo una vez. Esto da como resultado una situación beneficiosa tanto para el proveedor de lenguaje como para el consumidor de lenguaje.
El protocolo de servidor de lenguaje se inició con el protocolo usado por el servidor TypeScript, que se expandió con más características de lenguaje inspiradas en la API del lenguaje de VS Code. El protocolo está respaldado por JSON-RPC para la invocación remota debido a su simplicidad y a las bibliotecas existentes.
El equipo de VS Code ha creado un prototipo del protocolo mediante la implementación de varios servidores de lenguaje linter que responden a las solicitudes de lint (examen) de un archivo y devuelven un conjunto de advertencias y errores detectados. El objetivo era realizar el linting de un archivo a medida que el usuario edita en un documento, lo que significa que habrá muchas solicitudes de linting durante una sesión del editor. Tiene sentido mantener un servidor en funcionamiento para que no sea necesario iniciar un nuevo proceso de linting para cada edición de usuario. Se implementaron varios servidores linter, incluidas las extensiones ESLint y TSLint de VS Code. Estos dos servidores linter se implementan en TypeScript/JavaScript y se ejecutan en Node.js. Comparten una biblioteca que implementa la parte cliente y servidor del protocolo.
Funcionamiento del LSP
Un servidor de lenguaje se ejecuta en su propio proceso y herramientas como Visual Studio o VS Code se comunican con el servidor mediante el protocolo de lenguaje a través de JSON-RPC. Otra ventaja del servidor de lenguaje que funciona en un proceso dedicado es que se evitan incidencias de rendimiento relacionadas con un único modelo de proceso. El canal de transporte real puede ser stdio, sockets, canalizaciones con nombre o ipc de nodo si el cliente y el servidor se escriben en Node.js.
A continuación se muestra un ejemplo de cómo se comunican una herramienta y un servidor de lenguaje durante una sesión de edición rutinaria:

El usuario abre un archivo (denominado documento) en la herramienta: la herramienta notifica al servidor de lenguaje que un documento está abierto ("textDocument/didOpen"). A partir de ahora, la verdad sobre el contenido del documento ya no está en el sistema de archivos, sino que se conserva en la memoria de la herramienta.
El usuario realiza modificaciones: la herramienta notifica al servidor el cambio en el documento ("textDocument/didChange") y el servidor de lenguaje actualiza la información semántica del programa. A medida que esto sucede, el servidor de lenguaje analiza esta información y notifica a la herramienta los errores y advertencias detectados ("textDocument/publishDiagnostics").
El usuario ejecuta "Ir a definición" en un símbolo del editor: la herramienta envía una solicitud "textDocument/definition" con dos parámetros: (1) el URI del documento y (2) la posición de texto desde donde se inició la solicitud Ir a definición al servidor. El servidor responde con el URI del documento y la posición de la definición del símbolo dentro del documento.
El usuario cierra el documento (archivo): se envía una notificación "textDocument/didClose" desde la herramienta, que informa al servidor de lenguaje de que el documento ya no está en memoria y que el contenido actual está ahora actualizado en el sistema de archivos.
En este ejemplo se muestra cómo se comunica el protocolo con el servidor de lenguaje en el nivel de características del editor como "Ir a definición" o "Buscar todas las referencias". Los tipos de datos utilizados por el protocolo son "tipos de datos" del IDE o del editor, como el documento de texto abierto actualmente y la posición del cursor. Los tipos de datos no están en el nivel de un modelo de dominio del lenguaje de programación que normalmente proporcionaría árboles de sintaxis abstractos y símbolos del compilador (por ejemplo, tipos resueltos, espacios de nombres...). Esto simplifica significativamente el protocolo.
Ahora echemos un vistazo a la solicitud "textDocument/definition" con más detalle. A continuación se muestran las cargas que van entre la herramienta cliente y el servidor de lenguaje para la solicitud "Ir a definición" en un documento de C++.
Esta es la solicitud:
{
"jsonrpc": "2.0",
"id" : 1,
"method": "textDocument/definition",
"params": {
"textDocument": {
"uri": "file:///p%3A/mseng/VSCode/Playgrounds/cpp/use.cpp"
},
"position": {
"line": 3,
"character": 12
}
}
}
Esta es la respuesta:
{
"jsonrpc": "2.0",
"id": "1",
"result": {
"uri": "file:///p%3A/mseng/VSCode/Playgrounds/cpp/provide.cpp",
"range": {
"start": {
"line": 0,
"character": 4
},
"end": {
"line": 0,
"character": 11
}
}
}
}
En retrospectiva, describir los tipos de datos en el nivel del editor en lugar de hacerlo en el nivel del modelo de lenguaje de programación es una de las razones para el éxito del protocolo de servidor de lenguaje. Es mucho más sencillo estandarizar un URI de documento de texto o una posición de cursor en comparación con la estandarización de un árbol de sintaxis abstracta y símbolos del compilador en distintos lenguajes de programación.
Cuando un usuario trabaja con diferentes lenguajes, VS Code normalmente inicia un servidor de lenguaje para cada lenguaje de programación. En el ejemplo siguiente se muestra una sesión en la que el usuario trabaja en archivos Java y SASS.
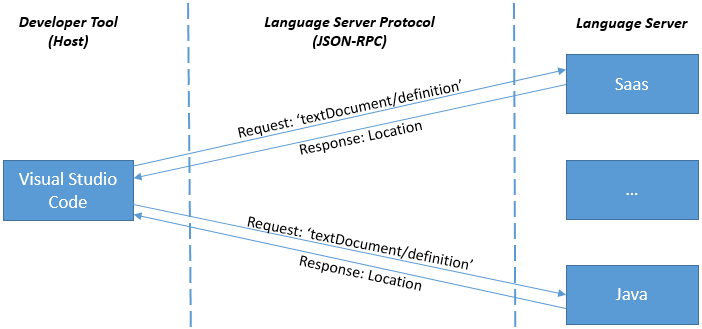
Funcionalidades
No todos los servidores de lenguaje pueden admitir todas las características definidas por el protocolo. Por lo tanto, el cliente y el servidor anuncian su conjunto de características compatible a través de "funcionalidades". Por ejemplo, un servidor anuncia que puede controlar la solicitud "textDocument/definition", pero es posible que no controle la solicitud "workspace/symbol". Del mismo modo, los clientes pueden anunciar que pueden proporcionar notificaciones "a punto de guardar" antes de guardar un documento, de modo que un servidor pueda calcular ediciones textuales para dar formato automáticamente al documento editado.
Integración de un servidor de lenguaje
La integración real de un servidor de lenguaje en una herramienta determinada no está definida por el protocolo de servidor de lenguaje y se deja a los implementadores de herramientas. Algunas herramientas integran servidores de lenguaje de forma genérica mediante una extensión que puede iniciarse y comunicarse con cualquier tipo de servidor de lenguaje. Otros, como VS Code, crean una extensión personalizada por servidor de lenguaje, por lo que una extensión sigue siendo capaz de proporcionar algunas características de lenguaje personalizadas.
Para simplificar la implementación de servidores de lenguaje y clientes, hay bibliotecas o SDK para los elementos de cliente y servidor. Estas bibliotecas se proporcionan para diferentes lenguajes. Por ejemplo, hay un módulo npm de cliente de lenguaje para facilitar la integración de un servidor de lenguaje en una extensión de VS Code y otro módulo npm de servidor de lenguaje para escribir un servidor de lenguaje mediante Node.js. Esta es la lista actual de bibliotecas compatibles.
Uso del protocolo de servidor de lenguaje en Visual Studio
- Agregar una extensión de protocolo de servidor de lenguaje: obtenga información sobre cómo integrar un servidor de lenguaje en Visual Studio.