Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Nota:
En este artículo se hace referencia principalmente a las experiencias de consumidor que se entregan en Windows 10 (versión 1909 y anteriores). Para obtener más información, consulte Fin de soporte técnico para Cortana.
Cortana, la plataforma de voz de Windows, impulsa todas las experiencias de voz en Windows 10, como Cortana y dictado. La activación por voz es una característica que permite a los usuarios invocar un motor de reconocimiento de voz desde varios estados de energía del dispositivo diciendo una frase específica: "Hey Cortana". Para crear hardware que admita la tecnología de activación de voz, revise la información de este artículo.
Nota:
La implementación de la activación por voz es un proyecto significativo y es una tarea completada por los proveedores de SoC. Los OEM pueden ponerse en contacto con su proveedor de SoC para obtener información sobre la implementación de la activación de voz de SoC.
Experiencia del usuario final de Cortana
Para comprender la experiencia de interacción de voz disponible en Windows, revise estos artículos.
| Artículo | Description |
|---|---|
| ¿Qué es Cortana? | Proporciona información general y dirección de uso para Cortana |
Introducción a la activación de voz "Hola Cortana" y "Aprender mi voz"
Activación por voz de Hey Cortana
La característica "Hey Cortana" Voice Activation (VA) permite a los usuarios interactuar rápidamente con la experiencia de Cortana fuera de su contexto activo (es decir, lo que está actualmente en pantalla) mediante su voz. A menudo, los usuarios quieren tener acceso instantáneo a una experiencia sin tener que interactuar físicamente ni tocar un dispositivo. Los usuarios de teléfono pueden estar conduciendo y tener su atención y manos ocupadas en la conducción del vehículo. Es posible que un usuario de Xbox no quiera buscar y conectar un controlador. Es posible que los usuarios de PC quieran acceder rápidamente a una experiencia sin tener que realizar varias acciones del mouse, la entrada táctil o el teclado. Por ejemplo, un ordenador de la cocina que se utiliza mientras cocina.
La activación por voz permite una escucha continua de la entrada de voz mediante frases clave predefinidas o frases de activación. Las frases clave se pueden pronunciar por sí mismas ("Hey Cortana") como un comando preconfigurado o seguidas de una acción de voz, por ejemplo, "Hey Cortana, ¿dónde está mi próxima reunión?", un comando encadenado.
El término Detección de palabras clave describe la detección de la palabra clave por hardware o software.
La activación mediante solo palabras clave se produce cuando solo se dice la palabra clave Cortana, Cortana inicia y reproduce el sonido EarCon para indicar que está en modo de escucha.
Un comando encadenado describe la capacidad de emitir un comando inmediatamente después de la palabra clave (como "Hey Cortana, llamar a John") y hacer que Cortana inicie (si aún no se ha iniciado) y siga el comando (iniciando una llamada telefónica con John).
En este diagrama se ilustra la activación encadenada y solo por palabras clave.
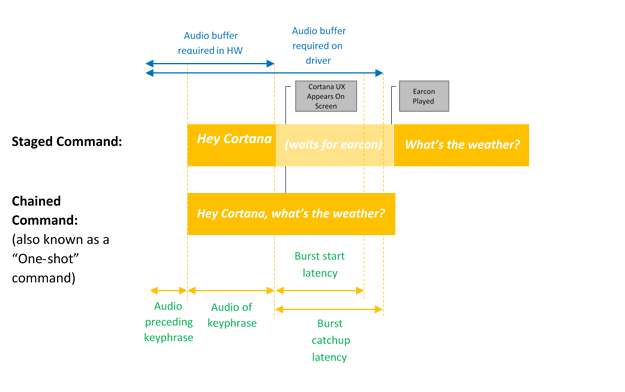
Microsoft proporciona un spotter de palabra clave predeterminado del sistema operativo (spotter de palabra clave de software) que se utiliza para garantizar la calidad de las detecciones de palabras clave de hardware y proporcionar la experiencia de Hey Cortana en los casos en que la detección de palabras clave de hardware está ausente o no está disponible.
La característica "Aprender mi voz"
La característica "Aprender mi voz" permite al usuario entrenar a Cortana para reconocer su voz única. Para ello, el usuario selecciona Learn how I say "Hey Cortana" (Hey Cortana) en la pantalla de configuración de Cortana. A continuación, el usuario repite seis frases elegidas cuidadosamente que proporcionan una variedad suficiente de patrones fonéticos para identificar los atributos únicos de la voz del usuario.
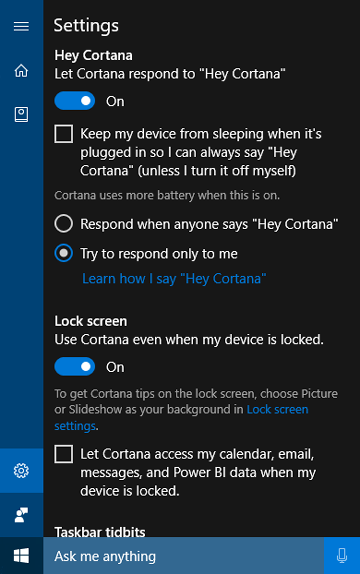
Cuando la activación por voz se empareja con "Learn my voice", los dos algoritmos funcionan juntos para reducir las activaciones falsas. Esto es especialmente valioso para el escenario de la sala de reuniones, donde una persona dice "Hey Cortana" en una sala llena de dispositivos. Esta característica solo está disponible para Windows 10 versión 1903 y anteriores.
La activación por voz se basa en un spotter de palabras clave (KWS) que reacciona si se detecta la frase clave. Si el KWS debe reactivar el dispositivo desde un estado de bajo consumo de energía, la solución se conoce como Wake on Voice (WoV). Para obtener más información, consulte Wake on Voice.
Glosario de términos
En este glosario se resumen los términos relacionados con la activación por voz.
| Término | Ejemplo o definición |
|---|---|
| Comando en fases | Ejemplo: Hey Cortana <pause, espere a que EarCon suene> ¿Cuál es el tiempo? Esto a veces se conoce como "Comando de dos disparos" o "Solo palabra clave" |
| Comando encadenado | Ejemplo: Oye Cortana, ¿cuál es el clima? Esto se conoce a veces como un "comando one-shot" |
| Activación por voz | Escenario de proporcionar la detección de palabras clave de una frase clave de activación predefinida. Por ejemplo, "Hey Cortana" es el escenario de activación por voz de Microsoft. |
| WoV | Wake-on-Voice: tecnología que permite la activación de voz desde una pantalla apagada, en estado de bajo consumo, a una pantalla en estado de alimentación completa. |
| WoV desde el modo de espera moderno | Despertar por Voz desde un estado de reposo moderno (S0ix) con pantalla apagada a un estado de pantalla encendida con máxima potencia (S0). |
| Modo de espera moderno | Infraestructura de inactividad de bajo consumo de Windows: sucesora de Connected Standby (CS) en Windows 10. El primer estado de espera moderno es cuando la pantalla está desactivada. El estado de suspensión más profundo es al estar en DRIPS/Resiliencia. Para obtener más información, consulte Modern Standby. |
| KWS | Detector de palabras clave: el algoritmo que proporciona la detección de "Hey Cortana" |
| SW KWS | Detector de palabras clave de software: una implementación de detección de palabras clave (KWS) que se ejecuta en el procesador host (CPU). Para "Hey Cortana", SW KWS se incluye como parte de Windows. |
| HW KWS | Buscador de palabras clave desplazado por hardware: una implementación de KWS que se ejecuta desplazado en hardware. |
| Búfer de ráfaga | Un búfer circular usado para almacenar datos PCM que pueden "expandirse" en una detección de KWS, de modo que se incluya todo el audio que desencadenó una detección de KWS. |
| Adaptador OEM para el Detector de Palabras Clave | Una capa de adaptación a nivel de controlador que permite que el hardware compatible con WoV se comunique con Windows y la pila de Cortana. |
| Modelo | El archivo de datos del modelo acústico usado por el algoritmo KWS. El archivo de datos es estático. Los modelos están localizados, uno por localidad. |
Integración de un detector de palabras clave de hardware
Para implementar un spotter de palabra clave de hardware (HW KWS), complete las siguientes tareas.
- Cree un detector de palabras clave personalizado basado en el ejemplo SYSVAD descrito más adelante en este artículo. Implementará estos métodos en un archivo DLL COM, que se describe en Keyword Detector OEM Adapter Interface (Interfaz del adaptador oem del Detector de palabras clave).
- Implemente mejoras de WAVE RT descritas en Mejoras de WAVERT.
- Proporcione entradas de archivo INF para describir las API personalizadas que se usan para la detección de palabras clave.
- PKEY_FX_KeywordDetector_StreamEffectClsid
- PKEY_FX_KeywordDetector_ModeEffectClsid
- PKEY_FX_KeywordDetector_EndpointEffectClsid
- PKEY_SFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- Clave_MFX_DetectorDePalabrasClave_ModosDeProcesamiento_Soportados_Para_Transmisión
- PKEY_EFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- Revise las recomendaciones de hardware y las instrucciones de prueba en Recomendación de dispositivos de audio. En este artículo se proporcionan instrucciones y recomendaciones para el diseño y desarrollo de dispositivos de entrada de audio diseñados para su uso con la Plataforma de voz de Microsoft.
- Admite comandos escalonados y encadenados.
- Admite "Hey Cortana" para cada una de las configuraciones regionales de Cortana admitidas.
- Las API (objetos de procesamiento de audio) deben proporcionar los siguientes efectos:
- AEC
- AGC
- NS
- El APO de MFX debe notificar los efectos del modo de procesamiento de voz.
- El APO puede realizar la conversión de formato como MFX.
- El APO debe generar el siguiente formato:
- 16 kHz, mono, FLOAT.
- Opcionalmente, diseñe las API personalizadas para mejorar el proceso de captura de audio. Para obtener más información, vea Objetos de procesamiento de audio de Windows.
Requisitos de hardware de WoV para el detector de palabras clave con descarga por hardware (HW KWS)
- HW KWS WoV se admite tanto en el estado de trabajo S0 como en el estado de suspensión S0, conocido también como "Modern Standby".
- HW KWS WoV no es compatible con S3.
Requisitos de AEC para HW KWS
Para Windows versión 1709
- Para admitir HW KWS WoV para el estado de suspensión S0 (espera moderna) AEC no es necesario.
- HW KWS WoV para el estado de trabajo S0 no se admite en windows versión 1709.
Para Windows versión 1803
- Se admite HW KWS WoV para el estado operativo S0.
- Para habilitar HW KWS WoV para el estado de trabajo S0, el APO debe admitir AEC.
Introducción al código de ejemplo
Hay código de ejemplo para un controlador de audio que implementa la activación por voz en GitHub como parte del ejemplo de adaptador de audio virtual SYSVAD. Se recomienda usar este código como punto de partida. El código está disponible en esta ubicación.
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
Para obtener más información sobre el controlador de audio de ejemplo SYSVAD, consulte Controladores de audio de ejemplo.
Información del sistema de reconocimiento de palabras clave
Compatibilidad con la pila de audio de activación de voz
Las interfaces externas de pila de audio para habilitar la activación por voz sirven como canalización de comunicación para la plataforma de voz y los controladores de audio. Las interfaces externas se dividen en tres partes.
- Interfaz del controlador de dispositivo (DDI) del detector de palabras clave. La interfaz de controlador del dispositivo del detector de palabras clave es responsable de configurar y activar el detector de palabras clave por hardware (KWS). También lo usa el controlador para notificar al sistema un evento de detección.
- DLL del Adaptador OEM de Detección de Palabras Clave. Este archivo DLL implementa una interfaz COM para adaptar los datos opacos específicos del controlador para que los use el sistema operativo para ayudar con la detección de palabras clave.
- Mejoras de streaming de WaveRT. Las mejoras permiten al controlador de audio transmitir de forma rápida los datos de audio almacenados en búfer provenientes de la detección de palabras clave.
Propiedades del punto de conexión de audio
La construcción de gráficos de extremos de audio se produce normalmente. El gráfico está preparado para gestionar la captura más rápido que en tiempo real. Las marcas de tiempo en los búferes capturados siguen siendo verdaderas. En concreto, las marcas de tiempo reflejan correctamente los datos que fueron capturados en el pasado y almacenados en búfer, y ahora se están liberando.
Teoría del desvío de streaming de audio por Bluetooth
El controlador expone un filtro KS para su dispositivo de captura, como es habitual. Este filtro admite varias propiedades KS y un evento KS para configurar, habilitar y indicar un evento de detección. El filtro también incluye otra fábrica de pines identificada como un pin detector de palabras clave (KWS). Este pin se usa para transmitir audio desde el spotter de palabras clave.
Las propiedades son:
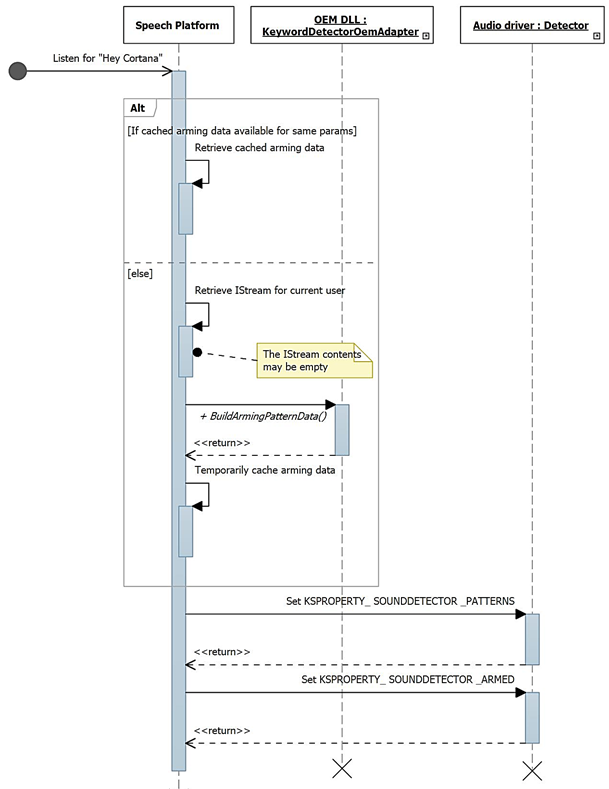
- Tipos de palabras clave admitidos : KSPROPERTY_SOUNDDETECTOR_PATTERNS. El sistema operativo establece esta propiedad para configurar las palabras clave que se van a detectar.
- Lista de GUIDs de patrones de palabras clave KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. Esta propiedad se usa para obtener una lista de GUID que identifican los tipos de patrones admitidos.
- Armado - KSPROPERTY_SOUNDDETECTOR_ARMED. Esta propiedad de lectura y escritura es un estado booleano que indica si el detector está armado. El sistema operativo establece esto para interactuar con el detector de palabras clave. El sistema operativo puede borrar esto para desconectarse. El controlador borra esto automáticamente cuando se establecen patrones de palabra clave y también después de detectar una palabra clave. (El sistema operativo debe rearmarse).
- Resultado de coincidencia - KSPROPERTY_SOUNDDETECTOR_MATCHRESULT. Esta propiedad de lectura contiene los datos de resultado después de que se haya producido la detección.
El evento que se desencadena cuando se detecta una palabra clave es un evento KSEVENT_SOUNDDETECTOR_MATCHDETECTED .
Secuencia de operación
Inicio del sistema
- El sistema operativo lee los tipos de palabra clave admitidos para comprobar que tiene palabras clave en ese formato.
- El sistema operativo registra el evento de cambio del estado del detector.
- El sistema operativo establece los patrones de palabra clave.
- El sistema operativo arma el detector.
Al recibir el evento KS
- El conductor desarme el detector.
- El sistema operativo lee el estado del detector de palabras clave, analiza los datos devueltos y determina qué patrón se detectó.
- El sistema operativo rearma el detector.
Controlador interno y operación de hardware
Mientras el detector está armado, el hardware puede capturar y almacenar en búfer continuamente datos de audio en un pequeño búfer FIFO. (El tamaño de este búfer FIFO viene determinado por los requisitos fuera de este documento, pero normalmente puede ser cientos de milisegundos a varios segundos). El algoritmo de detección funciona en el streaming de datos a través de este búfer. El diseño del controlador y el hardware son tales que, mientras está armado, no hay ninguna interacción entre el controlador y el hardware y no hay interrupciones en los procesadores de 'aplicación' hasta que se detecte una palabra clave. Esto permite que el sistema alcance un estado de potencia inferior si no hay ninguna otra actividad.
Cuando el hardware detecta una palabra clave, genera una interrupción. Mientras espera a que el controlador atienda la interrupción, el hardware continúa capturando audio en la memoria intermedia, asegurándose de que no se pierdan datos después de la palabra clave, dentro de los límites de almacenamiento en búfer.
Marcas de tiempo de palabras clave
Después de detectar una palabra clave, todas las soluciones de activación de voz deben almacenar en búfer todas las palabras clave habladas, incluidas las 250 ms antes del inicio de la palabra clave. El controlador de audio debe proporcionar marcas de tiempo que identifiquen el inicio y el final de la frase clave en la secuencia.
Para admitir las marcas de tiempo de inicio y fin de la palabra clave, el software DSP puede necesitar usar internamente marcas de tiempo para los eventos basados en un reloj DSP. Una vez detectada una palabra clave, el software DSP interactúa con el controlador para preparar un evento KS. El controlador y el software DSP deben asignar las marcas de tiempo de DSP a un valor de contador de rendimiento de Windows. El método de hacer esto es específico del diseño de hardware. Una posible solución es que el controlador lea el contador de rendimiento actual, consulte la marca de tiempo DSP actual, lea de nuevo el contador de rendimiento actual y, a continuación, calcule una correlación entre el contador de rendimiento y el tiempo de DSP. A continuación, dado que hay una correlación, el controlador puede asignar las marcas de tiempo del término clave DSP a las marcas de tiempo del contador de rendimiento de Windows.
Interfaz del Adaptador OEM del Detector de Palabras Clave
El OEM proporciona una implementación de objetos COM que actúa como intermediario entre el sistema operativo y el controlador, lo que ayuda a calcular o analizar los datos opacos que se escriben y leen en el controlador de audio a través de KSPROPERTY_SOUNDDETECTOR_PATTERNS y KSPROPERTY_SOUNDDETECTOR_MATCHRESULT.
El CLSID del objeto COM es un GUID tipo patrón de detección devuelto por el KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. El sistema operativo llama a CoCreateInstance pasando el GUID de tipo de patrón para crear una instancia del objeto COM adecuado compatible con el tipo de patrón de palabra clave y llama a métodos en la interfaz IKeywordDetectorOemAdapter del objeto.
Requisitos del modelo de subprocesos COM
La implementación del OEM puede elegir entre cualquiera de los modelos de subproceso COM.
IKeywordDetectorOemAdapter
El diseño de la interfaz intenta mantener la implementación de objetos sin estado. En otras palabras, la implementación no debe requerir que se almacene ningún estado entre las llamadas al método. De hecho, es probable que las clases internas de C++ no necesiten ninguna variable miembro más allá de las necesarias para implementar un objeto COM en general.
Methods
Implemente los métodos siguientes.
- IKeywordDetectorOemAdapter::BuildArmingPatternData
- IKeywordDetectorOemAdapter::ComputeAndAddUserModelData
- IKeywordDetectorOemAdapter::GetCapabilities
- IKeywordDetectorOemAdapter::ParseDetectionResultData
- IKeywordDetectorOemAdapter::VerifyUserKeyword
KEYWORDID
La enumeración KEYWORDID identifica el texto o la función de frase de una palabra clave y también se usa en los adaptadores del servicio biométrico de Windows. Para obtener más información, consulte Información general sobre el marco biométrico: componentes principales de la plataforma.
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
Selector de Palabras Clave
La estructura KEYWORDSELECTOR es un conjunto de identificadores que seleccionan de forma única una palabra clave y un lenguaje concretos.
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
Control de datos del modelo
Modelo independiente de usuario estático : el archivo DLL de OEM normalmente incluiría algunos datos de modelo independientes del usuario estático integrados en la DLL o en un archivo de datos independiente incluido con el archivo DLL. El conjunto de identificadores de palabras clave admitidos devueltos por la rutina GetCapabilities dependerá de estos datos. Por ejemplo, si la lista de identificadores de palabras clave admitidos devueltos por GetCapabilities incluye KwHeyCortana, los datos del modelo independiente del usuario estático incluirían datos para "Hey Cortana" (o su traducción) para todos los idiomas admitidos.
Modelo dependiente del usuario dinámico : IStream proporciona un modelo de almacenamiento de acceso aleatorio. El sistema operativo pasa un puntero de interfaz IStream a muchos de los métodos de la interfaz IKeywordDetectorOemAdapter. El sistema operativo respalda la implementación de IStream con un almacenamiento adecuado para hasta 1 MB de datos.
El OEM define el contenido y la estructura de los datos dentro de este almacenamiento. El propósito previsto es para almacenar de manera persistente los datos de modelos dependientes del usuario calculados o recuperados por la DLL de OEM.
El sistema operativo puede llamar a los métodos de interfaz con un IStream vacío, especialmente si el usuario nunca ha entrenado una palabra clave. El sistema operativo crea un almacenamiento IStream independiente para cada usuario. En otras palabras, un IStream determinado almacena los datos del modelo para uno y solo un usuario.
El desarrollador de DLL de OEM decide cómo administrar los datos independientes del usuario y dependientes del usuario. Sin embargo, nunca almacenará datos de usuario fuera de IStream. Un posible diseño de la DLL de OEM cambiaría internamente entre acceder a IStream y a los datos estáticos independientes del usuario, según los parámetros del método actual. Un diseño alternativo podría comprobar el IStream al inicio de cada llamada de método y añadir los datos estáticos independientes del usuario a IStream si todavía no están presentes, lo que permitiría que el resto del método acceda únicamente al IStream para todos los datos del modelo.
Procesamiento de audio de entrenamiento y operación
Como se ha descrito anteriormente, el flujo de la interfaz de usuario de entrenamiento da como resultado oraciones fonéticamente enriquecidas disponibles en la secuencia de audio. Cada frase se pasa individualmente a IKeywordDetectorOemAdapter::VerifyUserKeyword para comprobar que contiene la palabra clave esperada y tiene una calidad aceptable. Una vez recopiladas y verificadas todas las oraciones por la interfaz de usuario, todas se pasan en una llamada a IKeywordDetectorOemAdapter::ComputeAndAddUserModelData.
El audio se procesa de forma única para el entrenamiento de activación por voz. En la tabla siguiente se resumen las diferencias entre el entrenamiento de activación por voz y el uso normal del reconocimiento de voz.
| Entrenamiento de voz | Reconocimiento de voz | |
|---|---|---|
| Modo | Crudo | Crudo o voz |
| Anclar | Normal | KWS |
| Formato de audio | Float de 32 bits (Tipo = Audio, Subtipo = IEEE_FLOAT, Frecuencia de muestreo = 16 kHz, bits = 32) | Administrado por la pila de audio del sistema operativo |
| Mic | Micrófono 0 | Todos los micrófonos del conjunto o mono |
Introducción al sistema de reconocimiento de palabras clave
En este diagrama se proporciona información general sobre el sistema de reconocimiento de palabras clave.
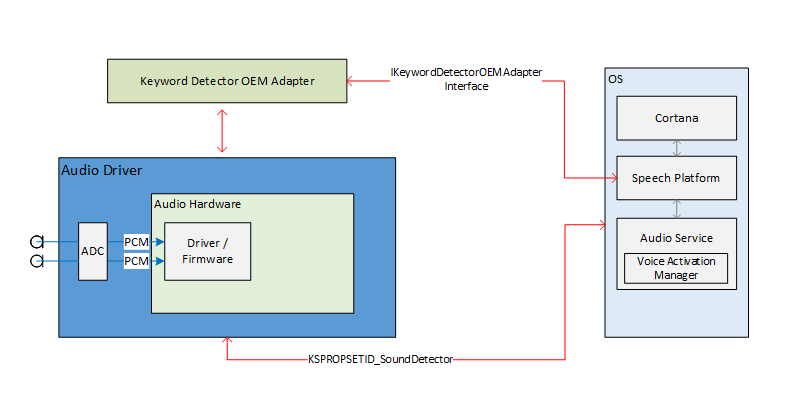
Diagramas de secuencia de reconocimiento de palabras clave
En estos diagramas, el módulo de tiempo de ejecución de voz se muestra como la plataforma de voz. Como se mencionó anteriormente, la plataforma de voz de Windows se usa para impulsar todas las experiencias de voz en Windows 10, como Cortana y dictado.
Durante el inicio, las funcionalidades se recopilan mediante IKeywordDetectorOemAdapter::GetCapabilities.
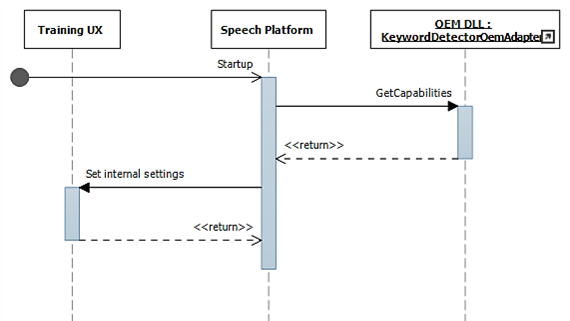
Más adelante, cuando el usuario selecciona "Learn my voice", se invoca el flujo de entrenamiento.
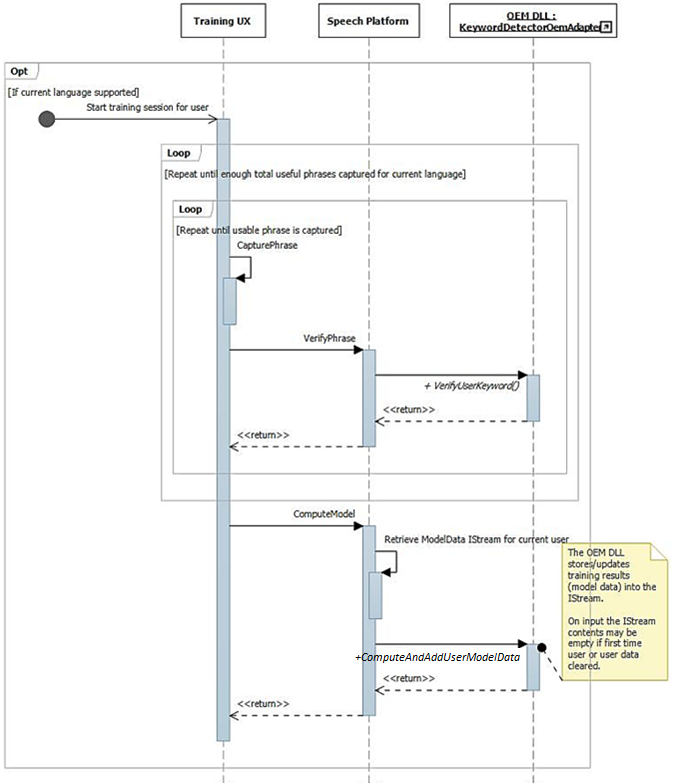
En este diagrama se describe el proceso de configuración para la detección de palabras clave.
Mejoras de WAVERT
Las interfaces de miniporte se definen para que las implementen los controladores de miniporte de WaveRT. Estas interfaces proporcionan métodos para simplificar el controlador de audio, mejorar el rendimiento y la confiabilidad de la canalización de audio del sistema operativo, o admitir nuevos escenarios. Se define una nueva propiedad de interfaz de dispositivo PnP que permite al controlador proporcionar expresiones estáticas de sus restricciones de tamaño de búfer al sistema operativo.
Tamaños de búfer
Un controlador funciona con varias restricciones al mover datos de audio entre el sistema operativo, el controlador y el hardware. Estas restricciones pueden deberse al transporte de hardware físico que mueve datos entre la memoria y el hardware o debido a los módulos de procesamiento de señal dentro del hardware o DSP asociado.
HW-KWS soluciones deben admitir tamaños de captura de audio de al menos 100 ms y hasta 200 ms.
El controlador expresa las restricciones de tamaño del búfer estableciendo la propiedad de dispositivo DEVPKEY_KsAudio_PacketSize_Constraints en la interfaz de dispositivo PnP de KSCATEGORY_AUDIO del filtro KS que tiene los pines de streaming KS. Esta propiedad debe permanecer válida y estable mientras la interfaz de filtro KS está habilitada. El sistema operativo puede leer este valor en cualquier momento sin necesidad de abrir un identificador y llamar al controlador.
DEVPKEY_KsAudio_PacketSize_Constraints
El valor de la propiedad DEVPKEY_KsAudio_PacketSize_Constraints contiene una estructura KSAUDIO_PACKETSIZE_CONSTRAINTS que describe las restricciones de hardware físico (es decir, debido a la mecánica de transferir datos del búfer de WaveRT al hardware de audio). La estructura incluye una matriz de 0 o más KSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT estructuras que describen restricciones específicas de los modos de procesamiento de señal. El controlador establece esta propiedad antes de llamar a PcRegisterSubdevice o habilitar de otro modo su interfaz de filtro KS para sus pines de streaming.
IMiniportWaveRTInputStream
Un controlador implementa esta interfaz para coordinar mejor el flujo de datos de audio del controlador al sistema operativo. Si esta interfaz está disponible en un flujo de captura, el sistema operativo usa métodos en esta interfaz para acceder a los datos del búfer de WaveRT. Para obtener más información, vea IMiniportWaveRTInputStream::GetReadPacket.
IMiniportWaveRTOutputStream
Un minipuerto WaveRT opcionalmente implementa esta interfaz para recibir notificaciones sobre el progreso de escritura por parte del sistema operativo y para devolver una posición precisa del flujo de datos. Para obtener más información, vea IMiniportWaveRTOutputStream::SetWritePacket, IMiniportWaveRTOutputStream::GetOutputStreamPresentationPosition e IMiniportWaveRTOutputStream::GetPacketCount.
Marcas de tiempo del contador de rendimiento
Varias de las rutinas del controlador devuelven marcas de tiempo del contador de rendimiento de Windows que reflejan la hora en la que el dispositivo captura o presenta las muestras.
En los dispositivos que tienen canalizaciones DSP complejas y procesamiento de señales, calcular una marca de tiempo precisa puede ser difícil y debe realizarse cuidadosamente. Las marcas de tiempo no deben reflejar el momento en que las muestras se transfirieron desde o hacia el sistema operativo al DSP.
- Dentro del DSP, realice un seguimiento de las marcas de tiempo de las muestras mediante un reloj de pared DSP interno.
- Entre el controlador y DSP, calcule una correlación entre el contador de rendimiento de Windows y el reloj de pared DSP. Los procedimientos para esto pueden ir desde simples (pero menos precisos) hasta bastante complejos o noveles (pero más precisos).
- Tenga en cuenta los retrasos constantes debido a algoritmos de procesamiento de señales o transportes de canalización o hardware, a menos que estos retrasos se contabilizan de otra manera.
Operación de lectura de ráfaga
En esta sección se describe la interacción del sistema operativo y del controlador para las lecturas de ráfaga. La lectura de ráfagas puede producirse fuera del escenario de activación de voz siempre que el controlador admita el modelo WaveRT de streaming basado en paquetes, incluida la función IMiniportWaveRTInputStream::GetReadPacket .
Se discuten dos escenarios de ejemplo de lectura en ráfaga. En un escenario, si el miniport admite un pin que tiene la categoría de pin KSNODETYPE_AUDIO_KEYWORDDETECTOR, el controlador comienza a capturar y almacenando en el búfer los datos internamente cuando se detecta una palabra clave. En otro escenario, el controlador puede almacenar internamente datos fuera del búfer de WaveRT si el sistema operativo no lee los datos lo suficientemente rápido llamando a IMiniportWaveRTInputStream::GetReadPacket.
Para expandir los datos capturados antes de realizar la transición a KSSTATE_RUN, el controlador debe conservar información precisa de marca de tiempo de ejemplo junto con los datos de captura almacenados en búfer. Las marcas de tiempo identifican el instante de muestreo de las muestras capturadas.
Después de que la secuencia pase a KSSTATE_RUN, el controlador establece inmediatamente el evento de notificación del búfer porque ya tiene datos disponibles.
En este evento, el sistema operativo llama a GetReadPacket() para obtener información sobre los datos disponibles.
El controlador devuelve el número de paquete de los datos capturados válidos (0 para el primer paquete después de la transición de KSSTATE_STOP a KSSTATE_RUN), desde el que el sistema operativo puede derivar la posición del paquete dentro del búfer de WaveRT y la posición del paquete relativa al inicio de la secuencia.
El controlador también devuelve el valor del contador de rendimiento que corresponde al instante de muestreo del primer ejemplo del paquete. Este valor del contador de rendimiento puede ser relativamente antiguo, en función de la cantidad de datos de captura almacenados en búfer dentro del hardware o controlador (fuera del búfer de WaveRT).
Si hay más datos almacenados en búfer no leídos disponibles, el controlador puede:
- Transfiere inmediatamente esos datos al espacio disponible del búfer de WaveRT (es decir, el espacio no utilizado por el paquete devuelto desde GetReadPacket), devuelve true para MoreData y establece el evento de notificación del búfer antes de volver de esta rutina. O bien,
- Programa el hardware para enviar el siguiente paquete al espacio disponible del búfer WaveRT, devuelve false para MoreData y, posteriormente, activa el evento del búfer cuando se completa la transferencia.
El sistema operativo lee datos del búfer de WaveRT mediante la información devuelta por GetReadPacket().
El sistema operativo espera el siguiente evento de notificación del búfer. La espera puede finalizar inmediatamente si el controlador establece la notificación del búfer en el paso (2c).
Si el controlador no estableció inmediatamente el evento en el paso (2c), el controlador establece el evento después de transferir más datos capturados al búfer de WaveRT y hace que esté disponible para que el sistema operativo lea.
Vaya a (2). Para los KSNODETYPE_AUDIO_KEYWORDDETECTOR pines del detector de palabras clave, los controladores deben asignar suficiente almacenamiento interno en búfer de ráfaga para al menos 5000 ms de datos de audio. Si el sistema operativo no puede crear un flujo en el pin antes de que el búfer se desborde, el controlador puede finalizar la actividad de almacenamiento en búfer interna y liberar los recursos asociados.
Activación por voz
Wake On Voice (WoV) permite al usuario activar y consultar un motor de reconocimiento de voz desde una pantalla apagada, bajar el estado de energía, a una pantalla en estado de energía completa diciendo una palabra clave determinada, como "Hey Cortana".
Esta característica permite que el dispositivo siempre escuche la voz del usuario mientras el dispositivo está en un estado de baja energía, incluido cuando la pantalla está apagada y el dispositivo está inactivo. Para ello, usa un modo de escucha de baja potencia, que consume menos energía en comparación con el mayor uso de energía observado durante la grabación normal con micrófono. El reconocimiento de voz de baja potencia permite al usuario decir una frase clave predefinida como "Hey Cortana", seguida de una frase de voz encadenada como "¿cuál es mi próxima cita?" para invocar la voz de forma manos libres. Esto funciona independientemente de si el dispositivo está en uso o inactivo con la pantalla desactivada.
La pila de audio es responsable de comunicar los datos de reactivación (identificación del altavoz, activación de palabra clave, nivel de confianza) y de notificar a los clientes interesados cuando la palabra clave ha sido detectada.
Validación en sistemas en espera modernos
WoV desde un estado de inactividad del sistema se puede validar en sistemas de Modern Standby utilizando la Prueba Básica de Activación por Voz en Modern Standby con Fuente de Alimentación de CA y la Prueba Básica de Activación por Voz en Modern Standby con Fuente de Alimentación de CC en el HLK. Estas pruebas comprueban que el sistema tiene un detector de palabras clave por hardware (HW-KWS), es capaz de entrar en el Estado de Inactividad de Plataforma en Tiempo de Ejecución más Profundo (DRIPS) y es capaz de reactivarse desde el estado de Modern Standby mediante comando de voz con una latencia de reanudación del sistema de un segundo o menos.