Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe el objeto de sincronización de barrera de GPU que se puede usar para la sincronización real de GPU a GPU en la fase 2 de programación de hardware de GPU. Esta característica se añade a partir de Windows 11, versión 24H2 (WDDM 3.2). Los desarrolladores de controladores gráficos deben conocer bien WDDM 2.0 y la fase 1 de programación de hardware de GPU
Objeto de sincronización de barrera supervisada de WDDM 2.x
El objeto de sincronización de barrera supervisado de WDDM 2.x admite las siguientes operaciones:
- La CPU espera en un valor de barrera supervisado, ya sea por:
- Buscando mediante una dirección virtual de CPU (VA).
- Poniendo en cola una espera de bloqueo dentro de Dxgkrnl que indica una señal cuando la CPU observa el nuevo valor de barrera supervisado.
- Señal de CPU de un valor supervisado.
- Señal de GPU de un valor supervisado escribiendo en la VA de GPU supervisada y creando una interrupción señalizada de barrera supervisada para notificar a la CPU del cambio del valor.
Lo que no se admitía era una espera nativa en la GPU para un valor de barrera supervisado. En su lugar, el sistema operativo mantuvo el trabajo de GPU que depende del valor esperado en la CPU. Solo se libera este trabajo en la GPU cuando se señala el valor.
Se ha agregado el objeto de sincronización de barreras nativas de GPU.
A partir de WDDM 3.2, el objeto de barrera supervisado se extendió para admitir las siguientes características agregadas:
- Espera de GPU en un valor de barrera supervisado, lo que permite una sincronización de motor a motor de alto rendimiento sin necesidad de un ciclo de ida y vuelta de la CPU.
- Notificación de interrupción condicional solo para señales de barrera de GPU que tienen tareas de espera de CPU. Esta característica permite ahorrar energía considerablemente al permitir que la CPU entre en un estado de bajo consumo cuando se pone en cola todo el trabajo de GPU.
- Almacenamiento de valores de barrera en la memoria local de la GPU (en lugar de la memoria del sistema).
Diseño de objetos de sincronización de barreras nativos de GPU
En el diagrama siguiente figura la arquitectura básica de un objeto de barrera nativo de GPU, destacando el estado del objeto de sincronización compartido entre la CPU y la GPU.
: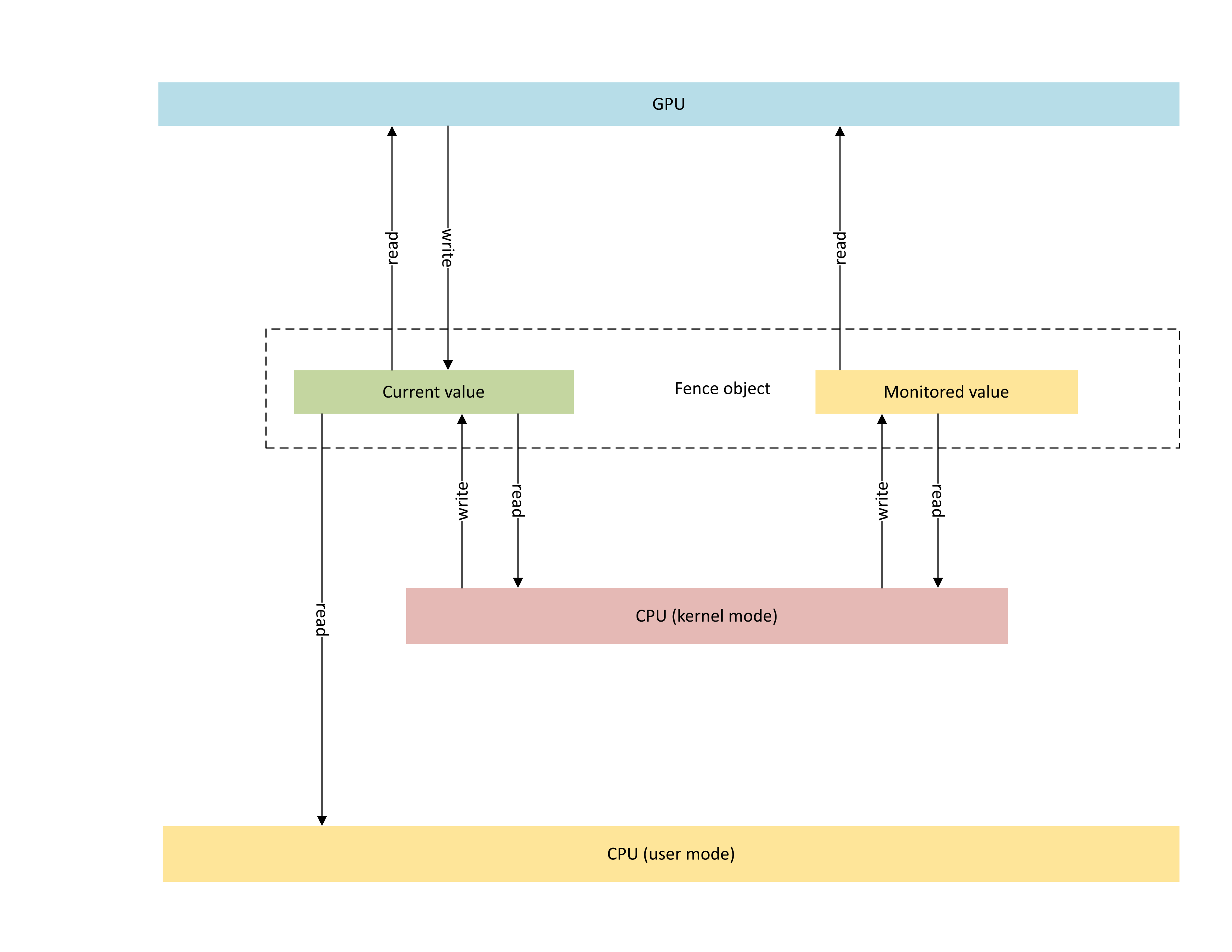
El diagrama incluye dos componentes principales:
Valor actual (denominado CurrentValue en este artículo). Esta ubicación de memoria incluye el valor de barrera de 64 bits señalado en el momento. CurrentValue lo puede asignar la CPU (se puede escribir a través del modo kernel, leer a través del modo de usuario y el modo kernel) y a la GPU (se puede leer y escribir mediante la dirección virtual de la GPU) y pueden acceder a él. CurrentValue requiere que las tareas de escritura de 64 bits sean atómicas tanto a través de la CPU como desde el punto de vista de la GPU. Es decir, las actualizaciones de 32 bits altos y bajos no se pueden romper y deben ser visibles al mismo tiempo. Este concepto ya está presente en el objeto de barrera supervisado existente.
Valor supervisado (denominado MonitoredValue en este artículo). Esta ubicación de memoria contiene el valor menos esperado actualmente por la CPU restada por uno (1). MonitoredValue lo puede asignar la CPU (se puede leer y escribir a través del modo kernel, pero no a través del modo de usuario) y la GPU (se puede leer a través de la VA de la GPU y no tiene acceso de escritura) y pueden acceder a él. El sistema operativo mantiene la lista de tareas de espera de la CPU pendientes en un objeto de barrera determinado y actualiza MonitoredValue a medida que se agregan y quitan las tareas de espera. Cuando no hay tareas de espera pendientes, el valor pasa a UINT64_MAX. Este concepto es nuevo en el objeto de sincronización de barreras nativo de GPU.
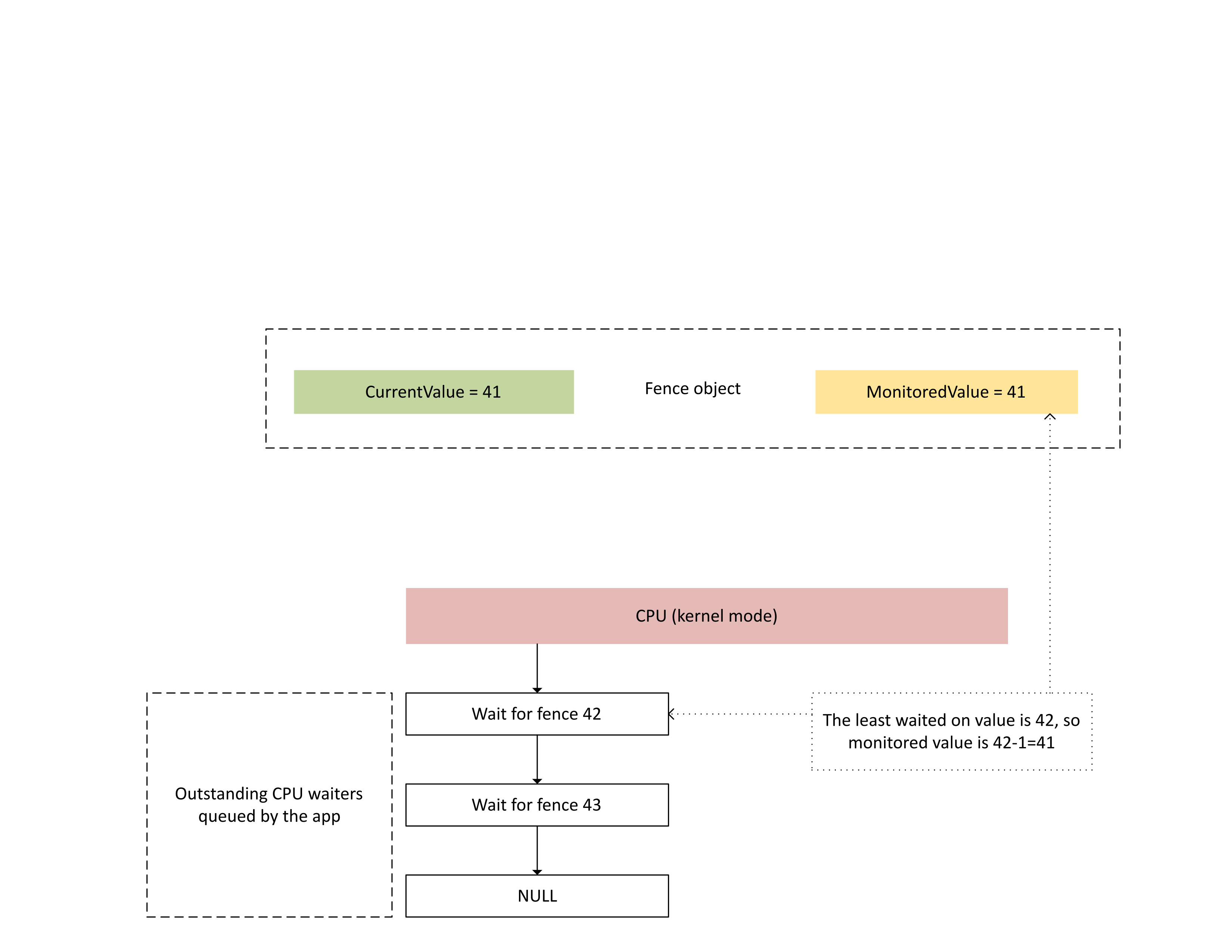
En el diagrama siguiente se muestra cómo Dxgkrnl realiza un seguimiento de las tareas de espera de ña CPU pendientes en un valor específico de barrera supervisado. También aparece el valor de barrera supervisado creado en un momento dado. CurrentValue y MonitoredValue son 41, lo que significa que:
- La GPU ha completado todas las tareas hasta el valor de barrera de 41.
- La CPU no está esperando ningún valor de barrera menor o igual que 41.
:
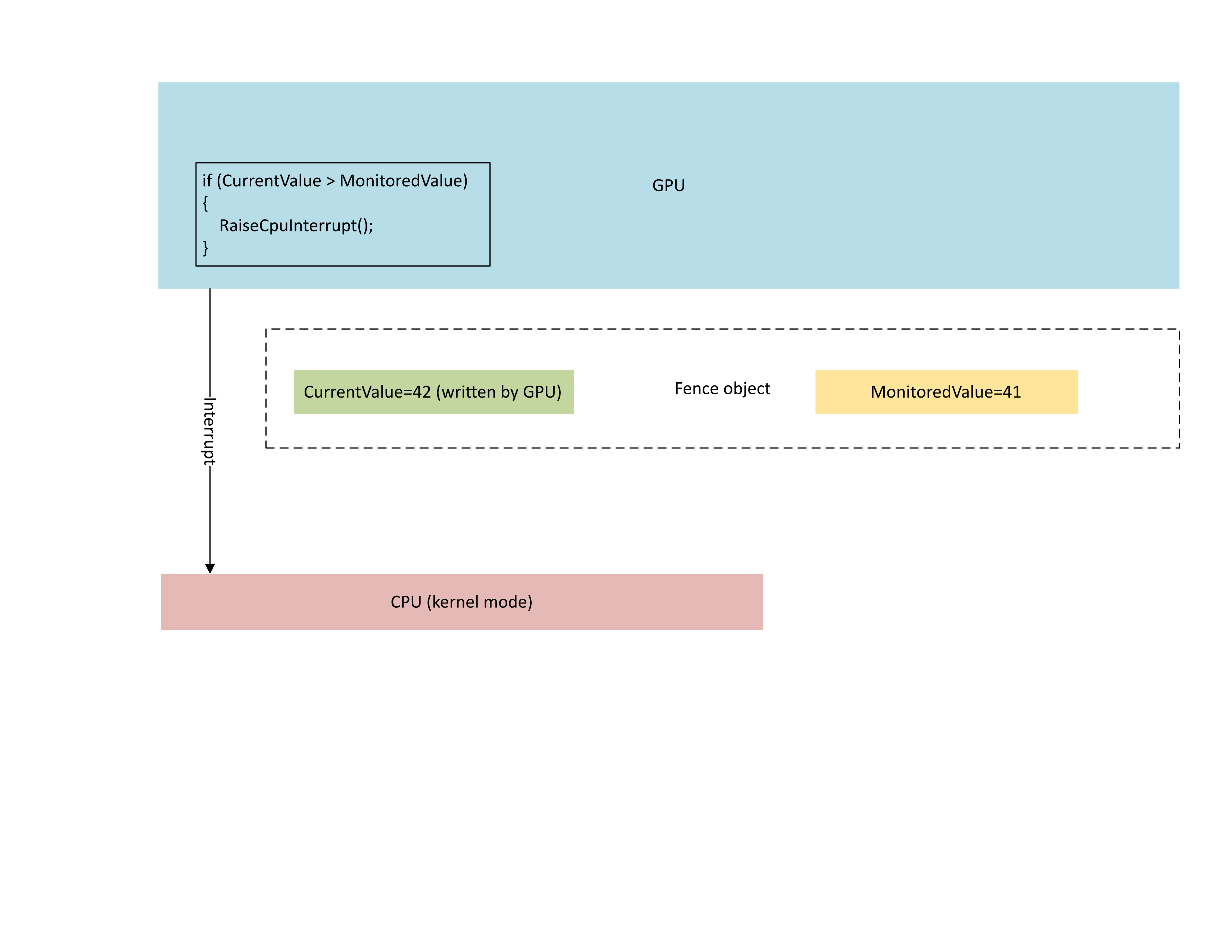
En el diagrama siguiente se ve que el procesador de administración de contextos (CMP) de la GPU genera condicionalmente una interrupción de CPU solo si el nuevo valor de barrera es mayor que el valor supervisado. Esta interrupción significa que hay tareas de espera de CPU pendientes que se pueden completar con el valor recién escrito.
:
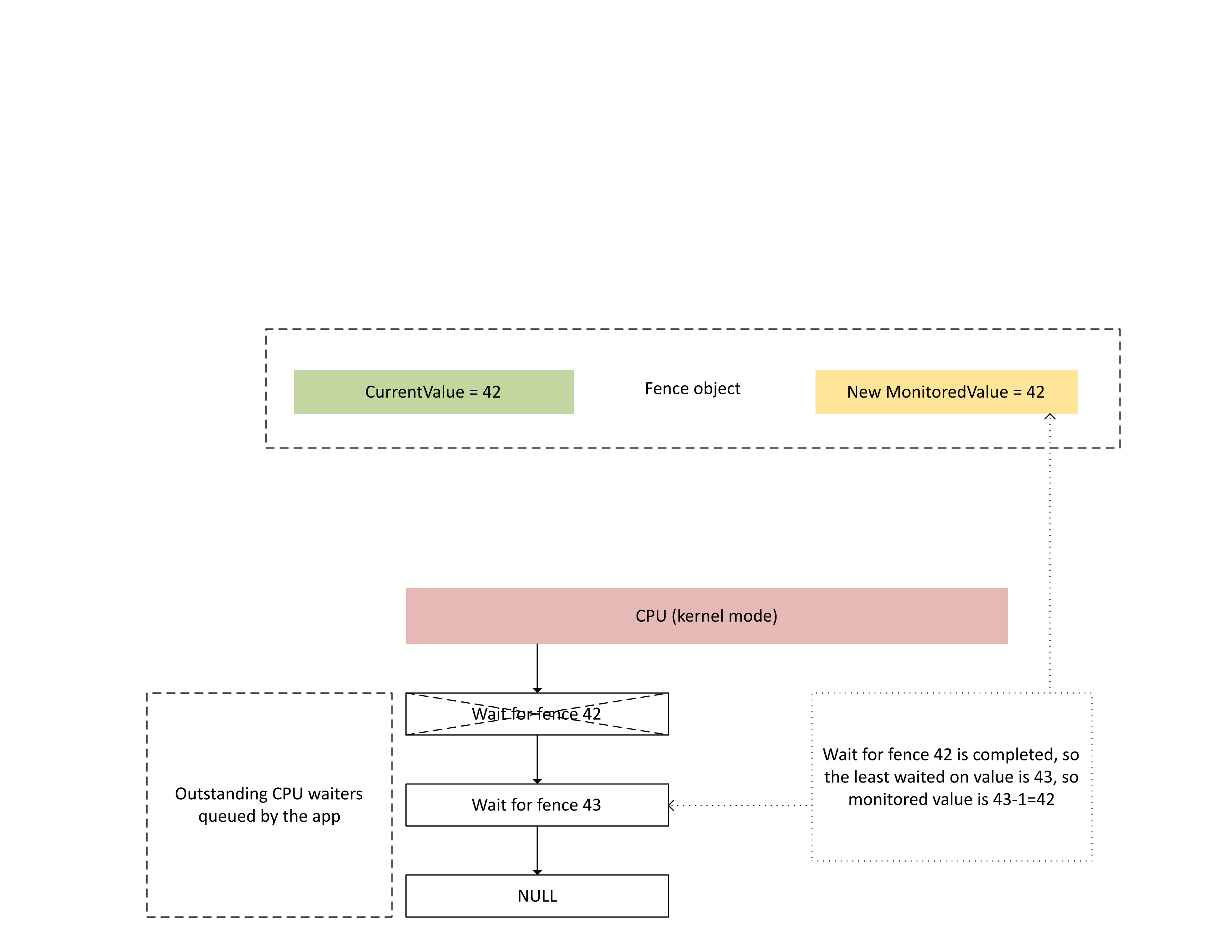
Cuando la CPU procesa esta interrupción, Dxgkrnl realiza las siguientes acciones, tal como se muestra en el diagrama siguiente:
- Desbloquea las tareas de espera de la CPU que se han completado con la barrera recién escrita.
- Hace avanzar el valor supervisado para que se corresponda con el valor menos pendiente esperado menos 1.
:
Almacenamiento de memoria física para valores de barrera actuales y supervisados
En un objeto de barrera determinado, CurrentValue y MonitoredValue se almacenan en ubicaciones independientes.
Los objetos de barrera que no se pueden compartir tienen almacenamiento de valores de barrera para objetos de barrera diferentes dentro del mismo proceso empaquetado en la misma página de memoria. Los valores se empaquetan según los valores de intervalo especificados en los límites de KMD de barrera nativa descritos más adelante en este artículo.
Los objetos de barrera que se pueden compartir tienen sus valores actuales y supervisados colocados en páginas de memoria que no se comparten con otros objetos de barrera.
Valor actual
El valor actual puede residir en la memoria del sistema o en la memoria local de GPU, en función del tipo de barrera especificado por D3DDDI_NATIVEFENCE_TYPE.
El valor actual de las vallas del adaptador cruzado siempre está en la memoria del sistema.
Cuando el valor actual se almacena en la memoria del sistema, el almacenamiento se asigna desde el grupo de memoria del sistema interno.
Cuando el valor actual se almacena en la memoria local, el almacenamiento se asigna a partir de segmentos de memoria que el controlador especificó en D3DKMDT_FENCESTORAGESURFACEDATA.
Valor supervisado
El valor supervisado también puede residir en la memoria local del sistema o de la GPU, en función de D3DDDI_NATIVEFENCE_TYPE.
Cuando el valor supervisado se almacena en la memoria del sistema, el sistema operativo asigna almacenamiento desde el grupo de memoria del sistema interno.
Cuando el valor supervisado se almacena en la memoria local, el sistema operativo asigna almacenamiento a partir de segmentos de memoria que el controlador especificó en D3DKMDT_FENCESTORAGESURFACEDATA.
Cuando cambian las condiciones de espera de CPU del sistema operativo, llama a la devolución de llamada DxgkDdiUpdateMonitoredValues de KMD para indicar a KMD que actualice el valor supervisado a un valor especificado.
Problemas de sincronización
El mecanismo descrito anteriormente tiene una condición de carrera inherente entre las lecturas y escrituras de CPU y GPU del valor actual y el valor supervisado. Si no se tiene especial cuidado, podrían producirse los siguientes problemas:
- La GPU podría leer un MonitoredValue obsoleto y no generar una interrupción según lo previsto por la CPU.
- Un motor de GPU podría escribir un valor CurrentValue más nuevo mientras el CMP está en proceso de decidir la condición de interrupción. Es posible que este CurrentValue más nuevo no genere la interrupción según lo previsto o que no sea visible para la CPU, ya que obtiene el valor actual.
Sincronización dentro de la GPU entre el motor y el CMP
Para mejorar la eficacia, muchas GPU discretas implementan la semántica de señal de barrera supervisada mediante el estado de sombra que reside en la memoria local de la GPU entre:
El motor de GPU que ejecuta la secuencia de búfer de comandos y genera condicionalmente una señal de hardware para el CMP.
El CMP de la GPU que decide si se debe generar una interrupción de CPU.
En este caso, el CMP debe sincronizar el acceso a la memoria con el motor de GPU que realiza la escritura de memoria en el valor de barrera. En concreto, el funcionamiento de la actualización de una sombra MonitoredValue debe ordenarse desde el punto de vista CMP:
- Escriba un nuevo monitoredValue (almacenamiento en sombras de GPU).
- Ejecute una barrera de memoria para sincronizar el acceso a la memoria con el motor de GPU.
- Lea CurrentValue:
- Si CurrentValue>MonitoredValue, genere una interrupción de CPU.
- Si CurrentValue<= MonitoredValue, no genere la interrupción de CPU.
Para que esta condición de carrera se resuelva correctamente, es obligatorio que la barrera de memoria del paso 2 funcione correctamente. No debe haber una operación de escritura de memoria pendiente en CurrentValue en el paso 3 que se creó a partir de un comando que no haya visto el cambio de MonitoredValue en el paso 1. Esta situación generaría una interrupción si la barrera escrita en el paso 3 era mayor que el valor actualizado en el paso 1.
Sincronización entre la GPU y la CPU
La CPU tiene que realizar cambios de MonitoredValue y lecturas de CurrentValue de una manera que no pierda la notificación de interrupción de las señales en curso.
- El sistema operativo tiene que modificar MonitoredValue cuando se agrega una nueva tarea e espera de CPU en el sistema o si se retira una tarea de espera de CPU existente.
- El sistema operativo llama a DxgkDdiUpdateMonitoredValues para notificar a la GPU sobre un nuevo valor supervisado.
- DxgkDdiUpdateMonitoredValue se ejecuta en la interrupción del dispositivo y, por tanto, se sincroniza con la rutina de servicio de interrupción (ISR) señalizada de barrera supervisada.
- DxgkDdiUpdateMonitoredValue debe garantizar que, después de devolverlo, el objeto CurrentValue leído por cualquier núcleo del procesador lo ha escrito el CMP del GPU después de haber observado el nuevo MonitoredValue.
- Tras la devolución de DxgkDdiUpdateMonitoredValue, el sistema operativo vuelve a muestrear CurrentValue y completa las tareas de espera desbloqueadas por el nuevo CurrentValue.
Es perfectamente aceptable que la CPU observe un valor CurrentValue que el usado por la GPU para decidir si se produce la interrupción. En ocasiones, esta situación provocaría una notificación de interrupción que no desbloquea ninguna tarea de espera. Lo que no es aceptable es que la CPU no reciba una notificación de interrupción por la última modificación de CurrentValue que se haya supervisado (es decir, CurrentValue>MonitoredValue.)
Consulta de activación de características de barrera nativa en el sistema operativo
Los controladores deben consultar si la característica de barrera nativa está habilitada en el sistema operativo durante la inicialización del controlador. A partir de WDDM 3.2, el sistema operativo usa la interfaz IsFeatureEnabled agregada para controlar si determinadas características están habilitadas, incluida la característica de barrera nativa.
Como resultado, KMD debe implementar la interfaz IsFeatureEnabled . La implementación de KMD debe consultar si el sistema operativo ha habilitado la característica DXGK_FEATURE_NATIVE_FENCE antes de anunciar la compatibilidad con barreras nativas en DXGK_VIDSCHCAPS. El sistema operativo produce un error en la inicialización del adaptador si KMD anuncia compatibilidad con barreras nativas cuando el sistema operativo no ha habilitado la característica.
Para obtener más información sobre la interfaz de habilitación de características, consulte Consulta de la compatibilidad y habilitación de características de WDDM.
DDIs para consultar la habilitación de la característica de barrera nativa
Se incluyen las siguientes interfaces para que un KMD consulte si el sistema operativo ha activado la característica de barrera nativa:
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
El sistema operativo implementa la tabla de interfaz agregada de DXGKCB_FEATURE_NATIVEFENCE_CAPS_1 destinada a la versión 1 de DXGK_FEATURE_NATIVE_FENCE. KMD debe consultar esta tabla de interfaz de características para determinar las funcionalidades del sistema operativo. En futuras versiones del sistema operativo, el sistema operativo podría introducir versiones avanzadas de esta tabla de interfaz, lo que aportaría más compatibilidad con nuevas funcionalidades.
Código de controlador de ejemplo para consultar compatibilidad con consultas
En el código de ejemplo siguiente se muestra cómo se espera que los controladores usen la característica DXGK_FEATURE_NATIVE_FENCE en la interfaz de DXGK_FEATURE_INTERFACE para consultar la compatibilidad.
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
Funcionalidades de barrera nativa
Las interfaces siguientes se actualizan o se incorporan para consultar los límites de barrera nativa:
El campo NativeGpuFence se agrega a DXGK_VIDSCHCAPS. Si el sistema operativo ha habilitado la característica DXGK_FEATURE_NATIVE_FENCE, el controlador puede declarar la compatibilidad con la funcionalidad barrera nativa de la GPU durante la inicialización del adaptador cambiando el bit de DXGK_VIDSCHCAPS::NativeGpuFence a 1.
DXGKQAITYPE_NATIVE_FENCE_CAPS se agrega a DXGK_QUERYADAPTERINFOTYPE.
Dxgkrnl expone esta característica en el modo de usuario a través de la estructura o bit D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported añadidos correspondientes.
KMTQAITYPE_WDDM_3_1_CAPS se agrega a KMTQUERYADAPTERINFOTYPE.
Se agregan las siguientes entidades para que el KMD indique sus funcionalidades de compatibilidad con la característica de barrera nativa de GPU.
La estructura DXGK_NATIVE_FENCE_CAPS describe las funcionalidades de barrera nativa de la GPU. Cuando el KMD crea el bit de la estructura MapToGpuSystemProcess, se indica al sistema operativo que reserve un espacio de direcciones virtuales de GPU de proceso del sistema para el uso del CMP y para crear asignaciones de VA de GPU en ese espacio de direcciones para los CurrentValue y MonitoredValue de barrera nativa. Estas máquinas virtuales de GPU se pasan posteriormente a la devolución de llamada de creación de barreras de KMD como DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa y MonitoredValueSystemProcessGpuVa.
KMD devuelve su estructura DXGK_NATIVE_FENCE_CAPS rellenada cuando se llama a la función DxgkDdiQueryAdapterInfo con el tipo de información de adaptador añadida de la consulta de DXGKQAITYPE_NATIVE_FENCE_CAPS.
DDI de KMD para crear, abrir, cerrar y destruir un objeto de barrera nativa
Los siguientes DDI implementados por KMD se incluyen para crear, abrir, cerrar y destruir un objeto de barrera nativa. Dxgkrnl llama a estos DDI en nombre de los componentes en modo de usuario. Dxgkrnl los llama solo si el sistema operativo ha habilitado la característica DXGK_FEATURE_NATIVE_FENCE.
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
Se han actualizado las siguientes DDI para admitir objetos de barrera nativa:
Los siguientes miembros se han agregado a DRIVER_INITIALIZATION_DATA. Los controladores que admiten objetos de barrera nativa de GPU deben implementar las funciones y facilitar a Dxgkrnl los punteros con enlace a aquellas a través de esta estructura.
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (incluido en WDDM 3.1)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (incluido en WDDM 3.1)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (incluido en WDDM 3.2)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (incluido en WDDM 3.2)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (incluido en WDDM 3.2)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (incluido en WDDM 3.2)
Identificadores globales y locales para barreras compartidas
Imagine que el proceso A crea una barrera nativa compartida y el proceso B abre esta barrera más adelante.
Cuando el proceso A crea la barrera nativa compartida, Dxgkrnl llama a DxgkDdiCreateNativeFence con el controlador del adaptador en el que se crea esta barrera. El identificador de barrera creado y devuelto en hGlobalNativeFence es el identificador de barrera global.
Dxgkrnl sigue posteriormente una llamada a DxgkDdiOpenNativeFence para abrir el identificador local específico de un proceso A (hLocalNativeFenceA).
Cuando el proceso B abre la misma barrera nativa compartida, Dxgkrnl llama a DxgkDdiOpenNativeFence para abrir un identificador local específico del proceso B (hLocalNativeFenceB).
Si el proceso A destruye la instancia de barrera nativa compartida, Dxgkrnl detecta que todavía hay una referencia pendiente a esta barrera global, por lo que solo llama a DxgkDdiCloseNativeFence(hLocalNativeFenceA) para que el controlador limpie las estructuras específicas del proceso A. El identificador hGlobalNativeFence sigue existiendo.
Cuando el proceso B destruye la instancia de barrera, Dxgkrnl llama a DxgkDdiCloseNativeFence(hLocalNativeFenceB) y luego a DxgkDdiDestroyNativeFence(hGlobalNativeFence) para permitir que KMD destruya los datos de barrera global.
Asignaciones de VA de GPU en el espacio de direcciones del proceso de paginación para usar en el CMP
El KMD crea el límite DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess en el hardware que requiere que las VA de de GPU de barrera nativa también se asignen al espacio de direcciones del proceso de paginación de GPU. El bit MapToGpuSystemProcess creado indica al sistema operativo que cree asignaciones de VA de GPU en el espacio de direcciones del proceso de paginación para el CurrentValue de barrera nativa y MonitoredValue para usar con el CMP. Estas máquinas virtuales de GPU se pasan posteriormente a DxgkDdiCreateNativeFence como DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa y MonitoredValueSystemProcessGpuVa.
API de kernel D3DKMT para crear, abrir y destruir barreras nativas
Las siguientes API D3DKMT en modo kernel se incluyen para crear y abrir un objeto de barrera nativa.
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl llama a la función D3DKMTDestroySynchronizationObject existente para cerrar y destruir (liberar) un objeto de barrera nativa.
Las estructuras y enumeraciones compatibles que se incorporan o se actualizan son estas:
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
DDI para admitir la colocación de valores de barrera nativos en la memoria local
Se agregaron o cambiaron las siguientes DDIs para admitir la colocación de valores de barrera nativos en la memoria local:
Se agrega la estructura D3DKMDT_FENCESTORAGESURFACEDATA.
La barrera nativa MonitoredValue y CurrentValue del tipo de barrera nativa D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU se puede colocar en la memoria del dispositivo local. Para ello, el sistema operativo pedirá al controlador que especifique los segmentos de memoria en los que se debe colocar el almacenamiento de barrera. DxgkDdiGetStandardAllocation se extiende para proporcionar dicha información.
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE se agrega a DXGKARG_GETSTANDARDALLOCATIONDRIVERDATA.
Indica una barrera de progreso nativa para las colas de hardware
Se añade la siguiente actualización para indicar un objeto nativo de barrera de progreso de cola de hardware:
Se ha añadido el indicador NativeProgressFence para hacer llamadas a DxgkDdiCreateHwQueue.
- En los sistemas compatibles, el sistema operativo pasa de la barrera de progreso de cola de hardware a una barrera nativa. Cuando el sistema operativo crea NativeProgressFence, indica a KMD que el identificador DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence apunta al identificador del controlador de un objeto de barrera nativa de GPU creado anteriormente mediante DxgkDdiCreateNativeFence.
Interrupción señalada de barrera nativa
Los siguientes cambios se realizan en el mecanismo de interrupción para incluir una interrupción señalada nativa:
Se ha actualizado la enumeración DXGK_INTERRUPT_TYPE para que tenga el tipo de interrupción DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED.
La estructura DXGKARGCB_NOTIFY_INTERRUPT_DATA se actualiza para incluir una estructura NativeFenceSignaled para indicar una interrupción señalada de barrera nativa
NativeFenceSignaled sirve para informar al sistema operativo de que un conjunto de objetos de GPU de barrera nativa supervisados por la CPU se han señalizado en un motor de GPU. Si la GPU puede determinar el subconjunto exacto de objetos con tareas de espera de CPU activas, pasa este subconjunto a través de pSignaledNativeFenceArray. Los identificadores de esta matriz deben ser identificadores hGlobalNativeFence válidos que Dxgkrnl haya pasado a KMD en DxgkDdiCreateNativeFence. Si se pasa un identificador a un objeto de barrera nativa destruido, se genera una comprobación de errores.
Se ha actualizado la estructura DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS para incluir un miembro EvaluateLegacyMonitoredFences.
La GPU puede pasar un pSignaledNativeFenceArray de valor NULL en las condiciones siguientes:
- La GPU no puede determinar el subconjunto exacto de objetos con tareas de espera de CPU activas.
- Se ocultan varias interrupciones de señal, lo que hace difícil determinar el conjunto señalado con tareas de espera activas.
Un valor NULL indica al sistema operativo que examine todas las tareas de espera de objetos de barrera nativa de GPU pendientes.
El contrato entre el sistema operativo y el controlador es: si el sistema operativo tiene una tarea de espera de CPU activa (tal como se expresa en MonitoredValue) y el motor de GPU ha señalizado el objeto al valor que pide una interrupción de CPU, la GPU debe realizar una de las siguientes acciones:
- Incluya este identificador de barrera nativa en pSignaledNativeFenceArray.
- Genere una interrupción NativeFenceSignaled con un pSignaledNativeFenceArray de valor NULL.
De forma predeterminada, cuando KMD genera esta interrupción con un pSignaledNativeFenceArray de valor NULL, Dxgkrnl solo examina todas las tareas de espera de barrera nativa pendientes y no examina las tareas de espera de barrera supervisada heredadas. En el hardware que no se pueda distinguir entre los DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED y DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED heredados, el KMD puede generar siempre la interrupción DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED introducida con pSignaledNativeFenceArray = NULL y EvaluateLegacyMonitoredFences = 1, lo que indica al sistema operativo que examine todas las tareas de espera (tarea de espera de barrera supervisada heredada y tareas de espera de barrera nativa).
Indicación a KMD para que actualice lotes de valores
Se incorporan las siguientes interfaces para indicar a KMD que actualice un lote de valores actuales o supervisados:
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
Barreras nativas entre adaptadores
El sistema operativo debe admitir la creación de barreras nativas entre adaptadores porque las aplicaciones DX12 existentes crean y usan barreras supervisadas entre adaptadores. Si las colas subyacentes y la programación de estas aplicaciones cambian al envío en modo de usuario, las barreras supervisadas también deben pasarse a barreras nativas (las colas en modo de usuario no pueden admitir barreras supervisadas).
Se debe crear una barrera entre adaptadores con el tipo D3DDDI_NATIVEFENCE_TYPE_DEFAULT. De lo contrario, se producirá un error en D3DKMTCreateNativeFence.
Todas las GPU comparten la misma copia del almacenamiento de CurrentValue, que siempre se asigna en la memoria del sistema. Cuando el tiempo de ejecución crea una barrera nativa entre adaptadores en GPU1 y la abre en GPU2, las asignaciones de VA de GPU en ambas GPU apuntarán al mismo almacenamiento físico de CurrentValue.
Cada GPU obtiene su propia copia de MonitoredValue. Por lo tanto, el almacenamiento de MonitoredValue se puede asignar en la memoria del sistema o en la memoria local.
Las barreras nativas entre adaptadores deben resolver la condición en la que GPU1 está esperando en una barrera nativa que GPU2 señaliza. Hoy en día, no hay ningún concepto de señales de GPU a GPU; por ello, el sistema operativo resuelve explícitamente esta condición mediante la señalización de GPU1 a través de la CPU. Esta señalización se realiza cambiando MonitoredValue en la barrera entre adaptadores a 0 mientras siga vigente. Después, cuando GPU2 señala la barrera nativa, también genera una interrupción de la CPU, lo que permite que Dxgkrnl actualice CurrentValue en GPU1 (mediante DxgkDdiUpdateCurrentValuesFromCpu con el indicador NotificationOnly con el valor TRUE) y desbloquee las tareas de espera pendientes de CPU/GPU de esa GPU.
Aunque MonitoredValue siempre es 0 en las barreras nativas entre adaptadores, las tareas de espera y las señales enviadas en la misma GPU siguen beneficiándose de una sincronización de GPU más rápida. Sin embargo, la ventaja efectiva en las interrupciones de CPU reducidas se pierde porque las interrupciones de CPU se elevan incondicionalmente, aunque no haya tareas de espera de CPU o tareas de espera en la otra GPU. Esta compensación tiene lugar para mantener al mínimo el coste del diseño e implementación de la barrera nativa entre adaptadores.
El sistema operativo admite el entorno en que se crea un objeto de barrera nativa en GPU1 y se abre en GPU2, donde GPU1 admite la característica y GPU2 no. El objeto de barrera se abre como una MonitoredFence normal en GPU2.
El sistema operativo admite el entorno en que se crea un objeto de barrera supervisada normal en GPU1 y se abre como una barrera nativa en GPU2, que admite la característica. El objeto de barrera se abre como una barrera nativa en GPU2.
Combinaciones de espera/señal entre adaptadores
Las tablas de las subsecciones siguientes ejemplifican un sistema iGPU y dGPU y aparecen las distintas configuraciones que son posibles para la espera o señal de la barrera nativa de la CPU/GPU. Están los dos casos siguientes:
- Ambas GPU admiten barreras nativas.
- La iGPU no admite barreras nativas, pero la dGPU admite barreras nativas.
El segundo escenario también es similar al caso en el que ambas GPU admiten barreras nativas, pero la espera o señal de barrera nativa se envía a una cola en modo kernel en la iGPU.
Las tablas deben leerse seleccionando un par de espera y señal de las columnas, por ejemplo WaitFromGPU - SignalFromGPU o WaitFromGPU - SignalFromCPU, etc.
Escenario 1
En el escenario 1, tanto dGPU como iGPU admiten barreras nativas.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| UMD inserta una tarea de espera para la instrucción de hfence CurrentValue == 10 en el búfer de comandos | En tiempo de ejecución se llama a D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch realiza un seguimiento de este objeto de sincronización en la lista de tareas de espera de barrera nativa de CPU | |||
| UMD inserta una instrucción de señal de hFence CurrentValue de escritura = 10 en el búfer de comandos | En tiempo de ejecución se llama a D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch recibe un ISR señalizado de barrera nativa cuando se escribe CurrentValue (porque MonitoredValue == 0 siempre) | VidSch llama a DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch propaga la señal (hFence, 10) a la iGPU | VidSch propaga la señal (hFence, 10) a iGPU | ||
| VidSch recibe la señal propagada y llama a DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch recibe la señal propagada y llama a DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD vuelve a examinar la lista de ejecución para desbloquear el canal de HW que estaba esperando a hFence | VidSch desbloquea la condición de espera de la CPU mediante la señalización del KEVENT |
Escenario 2a
En el escenario 2a, iGPU no admite barreras nativas, pero dGPU sí. Se envía una tarea de espera en la iGPU y se envía una señal en la dGPU.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| En tiempo de ejecución se llama a D3DKMTWaitForSynchronizationObjectFromGpu | En tiempo de ejecución se llama a D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch realiza un seguimiento de este objeto de sincronización en la lista de espera de barrera supervisada | VidSch realiza un seguimiento de este objeto de sincronización en el encabezado de lista de tareas de espera de barrera supervisada de CPU | ||
| UMD inserta una instrucción de señal de hFence CurrentValue de escritura = 10 en el búfer de comandos | En tiempo de ejecución se llama a D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch recibe NativeFenceSignaledISR cuando se escribe CurrentValue (porque MV == 0 siempre) | VidSch llama a DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch propaga la señal (hFence, 10) a iGPU | VidSch propaga la señal (hFence, 10) a iGPU | ||
| VidSch recibe la señal propagada y observa el nuevo valor de barrera | VidSch recibe la señal propagada y observa el nuevo valor de barrera | ||
| VidSch examina la lista de espera de barrera supervisada y desbloquea los contextos de software | VidSch examina el encabezado de lista de tareas de espera de barrera supervisada de CPU y desbloquea la espera de CPU mediante la señalización del KEVENT |
Escenario 2b
En el escenario 2b, la compatibilidad con barreras nativas sigue siendo la misma (iGPU no es compatible, dGPU sí). Esta vez, se envía una señal en la iGPU y se envía una espera en la dGPU.
| iGPU señalDesdeGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| UMD inserta una tarea de espera para la instrucción de hfence CurrentValue == 10 en el búfer de comandos | En tiempo de ejecución se llama a D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch realiza un seguimiento de este objeto de sincronización en la lista de tareas de espera de barrera nativa de CPU | |||
| UmD llama a D3DKMTSignalSynchronizationObjectFromGpu | UmD llama a D3DKMTSignalSynchronizationObjectFromCpu | ||
| Cuando el paquete está al principio del contexto de software, VidSch actualiza el valor de barrera directamente desde la CPU | VidSch actualiza el valor de barrera directamente desde la CPU | ||
| VidSch propaga la señal (hFence, 10) a dGPU | VidSch propaga la señal (hFence, 10) a dGPU | ||
| VidSch recibe la señal propagada y llama a DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch recibe la señal propagada y llama a DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD vuelve a examinar la lista de ejecución para desbloquear el canal de HW que estaba esperando a hFence | VidSch desbloquea la condición de espera de la CPU mediante la señalización del KEVENT |
Próxima señalización entre adaptadores de GPU a GPU
Tal como se describe en Problemas de sincronización de las barreras nativas entre adaptadores, se pierde en eficiencia de energía porque se genera una interrupción de CPU incondicionalmente.
En una próxima versión, el sistema operativo desarrollará una infraestructura para permitir que una señal de GPU en una GPU interrumpa otras GPU escribiendo en una memoria común de timbre, lo que permite que otras GPU se activen, procesen la lista de ejecución y desbloqueen las colas de HW listas.
Lo complicado de esto reside en diseñar:
- La memoria común de timbre.
- Una carga inteligente o un controlador que una GPU pueda escribir en el timbre que permita a otras GPU determinar qué barrera se ha señalizado para que solo pueda examinar un subconjunto de colas de HW.
Con esta señal entre adaptadores, es posible que incluso las GPU puedan compartir la misma copia del almacenamiento de barrera nativa (una asignación entre adaptadores de formato lineal, similar a las asignaciones de búsqueda entre adaptadores) en la que todas las GPU leen y escriben.
Diseño de búfer de registros de barreras nativas
Con las barreras nativas y el envío en modo de usuario, Dxgkrnl no puede visualizar el momento en que las señales y las tareas de espera nativas de GPU puestas en cola a través de UMD se desbloquean en la GPU para una cola de HW determinada. Con las barreras nativas, se podría suprimir una interrupción señalizada de barrera supervisada para una barrera determinada.
:
Se necesita una manera de volver a crear las operaciones de barrera, tal como se muestra en esta imagen de GPUView. Los recuadros de rosa oscuro son señales y los recuadros de rosa claro son tareas de espera. Cada recuadro comienza cuando la operación se envía en la CPU a Dxgkrnl y finaliza cuando Dxgkrnl completa la operación en la CPU. De este modo, podemos estudiar toda la duración de un comando.
Por tanto, en un nivel alto, las condiciones por HWQueue que se deben registrar son:
| Condición | Significado |
|---|---|
| FENCE_WAIT_QUEUED | Marca de tiempo de CPU del momento en que el UMD inserta una instrucción de espera de GPU en la cola de comandos |
| FENCE_SIGNAL_QUEUED | Marca de tiempo de CPU del momento en que el UMD inserta una instrucción de señal de GPU en la cola de comandos |
| FENCE_SIGNAL_EXECUTED | Marca de tiempo de GPU del momento en que se ejecuta un comando de señal en la GPU para un HWQueue |
| FENCE_WAIT_UNBLOCKED | Marca de tiempo de GPU del momento en que se cumple una condición de espera en la GPU y la HWQueue está desbloqueada |
DDI con búferes de registros de barreras nativas
Se incorporan las siguientes DDI, estructuras y enumeraciones para trabajar con búferes de registros de barreras nativas:
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- Un búfer de registros que incluye un encabezado y una matriz de entradas de registro. El encabezado identifica si las entradas son para una espera o señal y cada entrada identifica el tipo de operación (ejecutada o desbloqueada):
El diseño del búfer de registro está diseñado para colas de envío nativas y en modo de usuario donde la carga del búfer de registro está escrita por el motor o CMP de GPU, sin intervención de Dxgkrnl o KMD. Por lo tanto, UMD insertará una instrucción al generar el búfer de comandos wait/signal, programando la GPU para escribir la carga del búfer de registro en la entrada del búfer de registro en la ejecución. Para el envío en modo no usuario (es decir, colas en modo kernel), las señales y espera son comandos de software dentro de Dxgkrnl, por lo que ya conocemos las marcas de tiempo y otros detalles de estas operaciones y no necesitamos hardware/KMD para actualizar el búfer de registro. Para estas colas de modo kernel, Dxgkrnl no creará un búfer de registro.
Mecanismo de búfer de registros
Dxgkrnl asigna dos búferes de registros de 4 KB dedicados por HWQueue.
- Uno para las esperas de registro.
- Uno para las señales de registro.
Estos búferes de registros tienen asignaciones para la VA de CPU en modo kernel (LogBufferCpuVa), una VA de GPU en el espacio de direcciones de proceso (LogBufferGpuVa) y la VA de CMP (LogBufferSystemProcessGpuVa), para que se puedan leer y escribir en el KMD, el motor de GPU y el CMP. Dxgkrnl llama a DxgkDdiSetNativeFenceLogBuffer dos veces: una vez para crear el búfer de registros para las esperas de registro y una vez para crear el búfer de registros para las señales de registro.
Inmediatamente después de que el UMD inserte una instrucción de espera o señal de barrera nativa en la lista de comandos, también insertará un comando que indicará a la GPU que escriba una carga en una entrada determinada en el búfer de registros.
Una vez que el motor de GPU ejecuta la operación de barrera, ve la instrucción de UMD para escribir una carga en una entrada determinada en el búfer de registros. Además, la GPU también escribe la FenceEndGpuTimestamp actual en esta entrada del búfer de registros.
Aunque el UMD no puede acceder al búfer de registros al que puede acceder la GPU, controla la progresión del búfer de registros. Es decir, el UMD determina la siguiente entrada gratuita en la que escribir, si existe, y programa la GPU con esta información. Cuando la GPU escribe en el búfer de registros, incrementa el valor FirstFreeEntryIndex en el encabezado de registro. UMD debe asegurarse de que las escrituras en las entradas de registro aumentan de forma uniforme.
Considere el caso siguiente:
- Hay dos HWQueues, HWQueueA y HWQueueB, con los búferes de registros de barrera correspondientes con direcciones VA de GPU de FenceLogA y FenceLogB. HWQueueA está asociada al búfer de registros con las esperas de registro y HWQueueB está asociada al búfer de registros con las señales de registro.
- Hay un objeto de barrera nativa con un D3DKMT_HANDLE en modo de usuario de FenceF.
- Una espera de GPU en FenceF para el valor V1 se pone en cola en HWQueueA a la vez que CPUT1. Cuando el UMD compila el búfer de comandos, inserta un comando que indica a la GPU que registre la carga: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED).
- Una señal de la GPU a FenceF con valor V1 se pone en cola en HWQueueB a la vez que CPUT2. Cuando el UMD compila el búfer de comandos, inserta un comando que indica a la GPU que registre la carga: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED).
Una vez que el programador de GPU ejecuta la señal de la GPU en HWQueueB en la hora de GPU GPUT1, lee la carga del UMD y registra el evento en el registro de barrera facilitado por el sistema operativo en HWQueueB:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
Una vez que el programador de GPU observa que HWQueueA se desbloquea en la hora de GPU GPUT2, lee la carga del UMD y registra el evento en el registro de barrera facilitado por el sistema operativo en HWQueueA:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl puede destruir y volver a crear un búfer de registros. Cada vez que lo hace, llama a DxgkDdiSetNativeFenceLogBuffer para informar al KMD de la nueva ubicación.
Marcas de tiempo de CPU de operaciones de barrera en cola
No vale mucha la pena hacer que el UMD registre estas marcas de tiempo de CPU por estas razones:
- Se puede grabar una lista de comandos durante varios minutos antes de la ejecución por GPU de un búfer de comandos que incluya la lista de comandos.
- Estos minutos pueden estar fuera de lugar con respecto a otros objetos de sincronización que se encuentran en el mismo búfer de comandos.
Hay un coste derivado de incluir las marcas de tiempo de CPU en las instrucciones del UMD en el búfer de registros escrito por la GPU, por lo que las marcas de tiempo de CPU no se incluyen en la carga de entradas de registro.
En su lugar, el entorno de ejecución o el UMD pueden emitir un evento ETW en cola de barrera nativa con la marca de tiempo de CPU en el momento en que se registra una lista de comandos. Así, las herramientas pueden crear una escala de tiempo de eventos de barrera en cola y completados combinando la marca de tiempo de CPU de este nuevo evento y la marca de tiempo de GPU a través de la entrada del búfer de registros.
Orden de las operaciones en la GPU al señalar o desbloquear una barrera
El UMD debe garantizar que mantiene el orden siguiente cuando compila una lista de comandos con la que indica a la GPU que señale o desbloquee una barrera:
- Escribir el nuevo valor de barrera en la VA de GPU o CMP de barrera.
- Escribir la carga del registro en la VA de GPU o CMP del búfer de registros correspondiente.
- Generar una interrupción señalizada de barrera nativa si es necesario.
Este orden de operaciones garantiza que Dxgkrnl consulte las entradas de registro más recientes cuando se genera la interrupción en el sistema operativo.
Se permite que se sature el búfer de registros
La GPU puede sobrecargar el búfer de registros sobrescribiendo las entradas que aún no ha visto el sistema operativo. Para ello, incrementa el WraparoundCount.
Cuando el sistema operativo finalmente lee el registro, puede detectar que se ha producido una saturación comparando el nuevo valor de WraparoundCount en el encabezado de registro con el valor almacenado en caché. Si se ha producido una saturación, el sistema operativo puede realizar las siguientes acciones alternativas:
- Para desbloquear las barreras cuando se produce una saturación, el sistema operativo examina todas las barreras y determina qué tareas de espera se han desbloqueado.
- Si se ha habilitado el seguimiento, el sistema operativo puede emitir un indicador en el proceso de seguimiento para notificar a un usuario que se han perdido eventos. Además, cuando se habilita el seguimiento, el sistema operativo aumenta primero el tamaño del búfer de registros para evitar saturaciones desde el comienzo.
No es necesario que el UMD implemente la función presión retroactiva mientras progresan las entradas del búfer de registros.
Marcas de tiempo vacías o repetidas del búfer de registros
Por lo general, Dxgkrnl espera que las marcas de tiempo de las entradas de registro aumenten de forma uniforme. Sin embargo, hay casos en los que las marcas de tiempo de las entradas de registro posteriores dan cero o tienen un valor igual a las entradas de registro anteriores.
Por ejemplo, en una situación con adaptadores de pantalla vinculados, uno de los adaptadores encadenados de la LDA puede saltarse la operación de escritura de barrera. En este caso, la entrada del búfer de registros tendrá una marca de tiempo con valor cero. Dxgkrnl controla dichos casos. Sabiendo esto, Dxgkrnl nunca espera que la marca de tiempo de una entrada de registro determinada sea menor que la de la entrada de registro anterior; es decir, las marcas de tiempo nunca pueden ir hacia atrás.
Actualización sincrónica del registro de barrera nativa
Las operaciones de escritura de GPU para actualizar el valor de barrera y el búfer de registros correspondiente deben asegurarse de que las operaciones de escritura se propagan por completo antes de que las lecturas de la CPU. Este requisito requiere el uso de barreras de memoria. Por ejemplo:
- Signal Fence(N): escribir N como nuevo valor actual
- Escribir entrada LOG, incluida la marca de tiempo de GPU
- MemoryBarrier
- Incrementar FirstFreeEntryIndex
- MemoryBarrier
- Interrupción de barrera supervisada (N): leer Dirección "M" y comparar el valor con N para decidir cómo activar la interrupción de la CPU
Cuesta demasiado insertar dos barreras en cada señal de GPU, especialmente cuando es probable que la comprobación de interrupción condicional no se realice y que no sea necesaria ninguna interrupción de CPU. Por ello, el diseño traslada el coste de insertar una de las barreras de memoria de la GPU (productor) a la CPU (consumidor). Dxgkrnl llama a la función DxgkDdiUpdateNativeFenceLogs introducida para hacer que el KMD vacíe sincrónicamente las operaciones de escritura pendientes del registro de barrera nativa a petición (igual a cuando se incluye DxgkddiUpdateflipqueuelog para el vaciado de registro de la cola de prerenderización de HW).
Para las operaciones de GPU:
- Signal Fence(N): escribir N como nuevo valor actual
- Escribir entrada LOG, incluida la marca de tiempo de GPU
- Incrementar FirstFreeEntryIndex
- MemoryBarrier => garantiza que FirstFreeEntryIndex esté totalmente propagado
- Interrupción de barrera supervisada (N): leer Dirección "M" y comparar el valor con N para decidir cómo activar la interrupción de la CPU
Para las operaciones de CPU:
En el controlador de interrupción señalizada de barrera nativa de Dxgkrnl (DISPATCH_IRQL):
- En cada registro de HWQueue: se lee FirstFreeEntryIndex y se determina si se escriben nuevas entradas.
- En cada registro de HWQueue con nuevas entradas: se llama a DxgkDdiUpdateNativeFenceLogs y se facilitan los identificadores de kernel para esos HWQueues. En esta DDI, KMD inserta una barrera de memoria en cada HWQueue concreta, lo que garantiza que se confirmen todas las operaciones de escritura de entradas de registro.
- Dxgkrnl lee las entradas de registro para extraer la carga de marca de tiempo.
Por tanto, siempre que el hardware inserte una barrera de memoria después de escribir en FirstFreeEntryIndex, Dxgkrnl siempre llama a la DDI de KMD, lo que permite que KMD inserte una barrera de memoria antes de que Dxgkrnl lea cualquier entrada de registro.
Próximos requisitos de hardware
La mayoría del hardware de última generación puede admitir solamente la escritura del identificador del kernel del objeto de barrera en la interrupción señalizada de barrera nativa. Este diseño se describe anteriormente en Interrupción señalizada de barrera nativa. En este caso, Dxgkrnl controla la carga de interrupción, tal como se indica a continuación:
- El sistema operativo realiza una lectura (potencialmente a través del PCI) del valor de barrera.
- Al saber qué barrera se ha señalizado y el valor de la barrera, el sistema operativo activa las tareas de espera de CPU que están esperando en esa barrera o valor.
- Por separado, para el dispositivo principal de esta barrera, el sistema operativo examina los búferes de registros de todas las HWQueues. Luego, el sistema operativo lee las últimas entradas del búfer de registros escritas para determinar qué HWQueue ha emitido la señal y extrae la carga de marca de tiempo correspondiente. Este método podría leer redundantemente algunos valores de barrera en el PCI.
En plataformas futuras, Dxgkrnl prefiere obtener una matriz de identificadores HwQueue basados en kernel en la interrupción señalizada de barrera nativa. Este modelo permite al sistema operativo lo siguiente:
- Leer las entradas del búfer de registros más recientes para esa HwQueue. El dispositivo de usuario no lo conoce el controlador de interrupción y, por eso este identificador de HwQueue debe ser un identificador de kernel.
- Examinar el búfer de registros en las entradas de registro que indican qué barreras se han señalizado y con qué valores. Al leer solo el búfer de registros, se garantiza una sola lectura por el PCI en lugar de tener que leer de forma redundante los valores de barrera y el búfer de registros. Esta optimización se realiza correctamente siempre que el búfer de registros no se haya saturado (quitando entradas que Dxgkrnl nunca vaya a leer).
- Si el sistema operativo detecta que se ha superado el búfer de registros, vuelve a la ruta no optimizada que lee el valor dinámico de cada barrera que pertenece al mismo dispositivo. El rendimiento es proporcional al número de barreras que pertenecen al dispositivo. Si el valor de barrera está en la memoria de vídeo, estas lecturas son coherentes con la memoria caché en la PCI.
- Al conocer las barreras que se han señalizado y los valores de barrera, el sistema operativo activar las tareas de espera de CPU que están esperando en esas barreras o valores.
Interrupción optimizada señalizada de barrera nativa
Además de los cambios descritos en Interrupción señalizada de barrera nativa, también se realiza el siguiente cambio para incluir el método optimizado:
- El límite OptimizedNativeFenceSignaledInterrupt se agrega a DXGK_VIDSCHCAPS.
Si es compatible con el hardware, en lugar de rellenar una matriz de identificadores de barrera que se han señalizado, la GPU solo debe mencionar el identificador de KMD de la HWQueue que se estaba ejecutando cuando se generó la interrupción. Dxgkrnl examina el búfer de registros de barrera en esta HWQueue y lee todas las operaciones de barreras completadas por la GPU desde la última actualización y desbloquea las tareas de espera de CPU correspondientes. Si la GPU no pudo determinar qué subconjunto de barreras se han señalizado, debe indicar un identificador de HWQueue con valor NULL. Cuando Dxgkrnl ve un identificador HWQueue con valor NULL, vuelve a examinar el búfer de registros de todas las HWQueues de este motor para determinar qué barreras se han señalizado.
La compatibilidad con esta optimización es opcional; el KMD debe crear el límite DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt si es compatible con el hardware. Si no se crea el límite OptimizedNativeFenceSignaledInterrupt, la GPU o el KMD deben seguir el procedimiento descrito en Interrupción señalizada de barrera nativa.
Ejemplo de interrupción señalizada optimizada de barrera nativa
HWQueueA: señal de GPU a barrera F1, valor V1 -> Escribir en entra de búfer de registros E1 -> no se necesita interrupción
HWQueueA: señal de GPU a barrera F1, valor V2 -> Escribir en entra de búfer de registros E2 -> no se necesita interrupción
HWQueueA: señal de GPU a barrera F2, valor V3 -> Escribir en entra de búfer de registros E3 -> no se necesita interrupción
HWQueueA: señal de GPU a barrera F2, valor V3 -> Escribir en entra de búfer de registros E4 -> se genera interrupción
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl lee el búfer de registros de HWQueueA. Lee las entradas del búfer de registros E1, E2, E3 y E4 para observar las barreras señalizadas F1 con valor V1, F1 con valor V2, F2 con valor V3 y F2 con valor V3, y desbloquea las tareas de espera que esperan en esas barreras y valores.
Registro opcional y obligatorio
La compatibilidad con el registro de barreras nativas de DXGK_NATIVE_FENCE_LOG_TYPE_WAITS y DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS es obligatorio.
En el futuro, se podrán agregar otros tipos de registro solo cuando las herramientas como GPUView habilitan el registro detallado de ETW en el sistema operativo. El sistema operativo debe informar tanto al UMD como al KMD cuando el registro detallado estçé habilitado y deshabilitado para que el registro de esos eventos detallados esté habilitado de forma selectiva.