Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
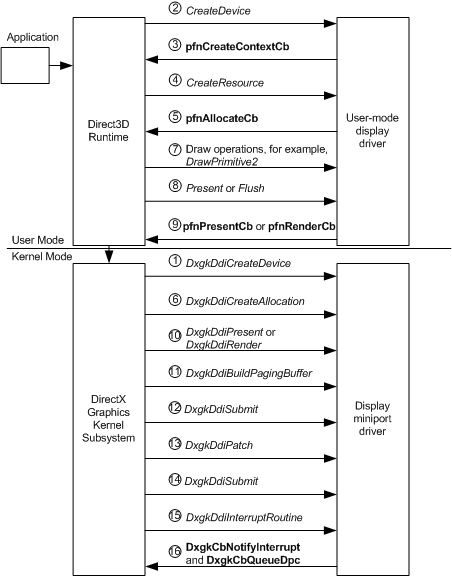
En el diagrama siguiente se muestra el flujo de operaciones WDDM que se producen desde cuando se crea un dispositivo de representación a cuando se presenta el contenido a la pantalla. La información que sigue al diagrama describe la secuencia ordenada del flujo de operación con más detalle.
Creación de un dispositivo de representación
Después de que una aplicación solicite crear un dispositivo de representación:
1: El Subsistema de Kernel de Gráficos de DirectX (Dxgkrnl) llama a la función DxgkDdiCreateDevice del controlador de miniporte (KMD) del modo kernel.
KMD inicializa el acceso directo a la memoria (DMA) devolviendo un puntero a una estructura de DXGK_DEVICEINFO rellenada en el miembro pInfo de la estructura DXGKARG_CREATEDEVICE .
2: Si la llamada a DxgkDdiCreateDevice se realiza correctamente, el tiempo de ejecución de Direct3D llama a la función CreateDevice del controlador de pantalla en modo de usuario (UMD).
3: En la llamada CreateDevice , UMD debe llamar explícitamente a la función pfnCreateContextCb del runtime para crear uno o varios contextos de GPU, que son subprocesos de GPU de ejecución en el dispositivo recién creado. El tiempo de ejecución devuelve información a UMD a través de los miembros pCommandBuffer y CommandBufferSize de la estructura D3DDDICB_CREATECONTEXT con el fin de inicializar el búfer de comandos.
Crear superficies para un dispositivo
Después de que una aplicación solicite crear superficies para el dispositivo de representación:
4: El entorno de ejecución de Direct3D llama a la función CreateResource de UMD.
5: CreateResource llama a la función pfnAllocateCb proporcionada por el entorno de ejecución.
6: El tiempo de ejecución llama a la función DxgkDdiCreateAllocation de KMD, especificando el número y los tipos de asignaciones que se van a crear. DxgkDdiCreateAllocation devuelve información sobre las asignaciones de una matriz de estructuras de DXGK_ALLOCATIONINFO en el miembro pAllocationInfo de la estructura DXGKARG_CREATEALLOCATION .
Envío del búfer de comandos al modo kernel
Después de que una aplicación solicite dibujar en una superficie:
7: El tiempo de ejecución de Direct3D llama a la función UMD relacionada con la operación de dibujo, por ejemplo , DrawPrimitive2.
8: El tiempo de ejecución de Direct3D llama a la función Present o Flush del UMD para que el búfer de comandos se envíe al modo kernel. Nota: UMD también envía el búfer de comandos cuando el búfer de comandos está lleno.
9: En respuesta al paso 8, UMD llama a una de las siguientes funciones proporcionadas por el entorno de ejecución:
- La función pfnPresentCb del entorno de ejecución si Present fue llamado.
- La función pfnRenderCb del tiempo de ejecución si se invocó Flush o el búfer de comandos está lleno.
10: se llama a la función DxgkDdiPresent de KMD si se llamó a pfnPresentCb, o a la función DxgkDdiRender o DxgkDdiRenderKm si se llamó a pfnRenderCb. KMD valida el búfer de comandos, escribe en el búfer de DMA en el formato del hardware y genera una lista de asignación que describe las superficies utilizadas.
Envío del búfer DMA al hardware
11: Dxgkrnl llama a la función DxgkDdiBuildPagingBuffer de KMD para crear búferes DMA de propósito especial que mueven las asignaciones especificadas en la lista de asignaciones hacia y desde la memoria accesible para GPU. Estos búferes DMA especiales se conocen como búferes de paginación. No se llama a DxgkDdiBuildPagingBuffer en cada fotograma.
12: Dxgkrnl llama a la función DxgkDdiSubmitCommand de KMD para poner en cola los búferes de paginación en la unidad de ejecución de GPU.
13: Dxgkrnl llama a la función DxgkDdiPatch de KMD para asignar direcciones físicas a los recursos del búfer DMA.
14: Dxgkrnl llama a la función DxgkDdiSubmitCommand de KMD para poner en cola el búfer DMA a la unidad de ejecución de GPU. Cada búfer DMA enviado a la GPU contiene un identificador de barrera, que es un número. Una vez que la GPU termina de procesar el búfer DMA, la GPU genera una interrupción.
15: KMD recibe una notificación de la interrupción en su función DxgkDdiInterruptRoutine . KMD debe leer el identificador de barrera del búfer DMA completado de la GPU.
16: KMD debe llamar a DxgkCbNotifyInterrupt para notificar a Dxgkrnl que el búfer DMA se completó. KMD también debe llamar a DxgkCbQueueDpc para poner en cola una llamada a procedimiento diferido (DPC).