Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Este artículo provee recomendaciones sobre el planeamiento de capacidad para Active Directory Domain Services (AD DS)
Objetivos del planeamiento de capacidad
El planeamiento de capacidad no es lo mismo que la solución de problemas de incidentes de rendimiento. Los objetivos del planeamiento de capacidad son:
- Implementar y operar un entorno de forma apropiada.
- Minimizar el tiempo usado en la solución de problemas de problemas de rendimiento.
En el planeamiento de capacidad, una organización podría tener un objetivo base de 40 % para el uso de procesadores durante periodos pico, con la finalidad de lograr los requerimientos de rendimiento del cliente y dar tiempo suficiente para actualizar el hardware en el centro de datos. Mientras tanto, configuran su umbral de alerta de monitoreo para problemas de rendimiento al 90 % en un intervalo de cinco minutos.
Cuando excedes continuamente el umbral de administración de capacidad, entonces tanto añadir más procesadores o procesadores más rápidos para aumentar la capacidad, como escalar el servicio a lo largo de múltiples servidores podría ser una solución. Los umbrales de alerta de rendimiento te dejan saber cuándo necesitas tomar acción inmediata cuando los problemas de rendimiento afectan negativamente la experiencia del cliente. En contraste, una alternativa de solución de problemas estaría más centrada en abordar eventos únicos.
La administración de capacidad es como tomar medidas preventivas para evitar un accidente automovilístico, como conducción defensiva, asegurarse de que los frenos funcionen correctamente y cosas por el estilo. La solución de problemas de rendimiento es como llamar a la policía, bomberos y a profesionales de emergencias médicas en respuesta a un accidente.
En los últimos años, la guía de planeamiento de capacidad para el escalado vertical de los sistemas ha cambiado drásticamente. Los siguientes cambios en las arquitecturas de sistemas desafían las presunciones básicas sobre diseño y escalamiento de un servicio:
- Plataformas de servidor de 64 bits
- Virtualización
- Mayor atención al consumo de energía
- Almacenamiento en SSD
- Escenarios de nube
Este punto de vista a la planificación de capacidad también está moviéndose desde ejercicios de planificación basados en servidores a otros basados en servicios. Active Directory Domain Services (AD DS), un servicio distribuido maduro que muchos productos de Microsoft y de terceros usan como backend, es ahora uno de los productos más importantes al asegurar que tus otras aplicaciones tengan la capacidad necesaria para ejecutarse.
Información importante a considerar antes de empezar a planear
Para obtener el mayor provecho de este artículo, deberías seguir los pasos a continuación:
- Asegúrate de leer y entender las Guías de ajuste de rendimiento para Windows Server 2012 R2.
- Comprende que la plataforma de Windows Server una arquitectura basada en x64. Asimismo, debes entender que las guías de este artículo también aplican incluso si tu entorno de Active Directory está instalado en Windows Server 2003 x86 (ahora más allá del fin del ciclo de soporte) y tiene un árbol de información de directorio (DIT) menor a 1,5 GB y puede ser almacenado en la memoria fácilmente.
- Comprende que el planeamiento de capacidad es un proceso continuo, así que debes revisar regularmente qué tanto el entorno en que construyes cumple con tus expectativas.
- Comprende que la optimización ocurre a lo largo de múltiples ciclos de vida del hardware mientras los costos del hardware cambian. Por ejemplo, si la memoria se vuelve más barata, el costo por núcleo baja o el precio de diferentes opciones de almacenamiento cambia.
- Planea para el periodo de actividad pico de cada día. Te recomendamos que hagas tus planes sobre la base de intervalos de 30 minutos o de una hora. Los intervalos mayores a una hora podrían ocultar cuándo tu servicio llega en realidad a la capacidad pico, y los intervalos de menos de 30 minutos pueden darte información inexacta que hace que los incrementos transitorios parezcan más importantes de lo que en realidad son.
- Planee teniendo en cuenta el crecimiento durante el ciclo de vida del hardware para la empresa. Este planeamiento puede incluir estrategias para actualizar o añadir hardware de forma intercalada, o un reemplazo completo cada tres a cinco años. Cada plan de crecimiento requiere que estimes cuánto crece la carga en el Active Directory. Los datos históricos pueden ayudarte a hacer un asesoramiento más exacto.
- Planee teniendo en cuenta la tolerancia a errores. (Una vez que hayas derivado el plan N de estimaciones para escenarios que incluyan N - 1, N - 2, and N - x.
Sobre la base de tu plan de crecimiento, añade servidores extra según la necesidad organizacional de asegurar que la pérdida de uno o más servidores no causa que el sistema exceda las estimaciones de la capacidad pico máxima.
También recuerda que debes integrar tu crecimiento y planes de tolerancia a fallas. Por ejemplo, si sabes que tu departamento requiere actualmente un controlador de dominio (DC) para soportar la carga pero tu estimado dice que la carga se duplicará en el próximo año y requiere de dos controladores de dominio para soportarla, entonces tu sistema no tiene la capacidad suficiente para soportar la tolerancia a fallas. Para prevenir esta falta de capacidad, deberías planear empezar con tres controladores de dominio en su lugar. Si tu presupuesto no alcanza para tres controladores de dominio, puedes empezar con dos y luego planear añadir un tercero después de tres o seis meses.
Nota:
Agregar aplicaciones compatibles con Active Directory podría tener un impacto notable en la carga del controlador de dominio, tanto si la carga procede de los servidores de aplicaciones como de los clientes.
El ciclo de planeamiento de capacidad de tres partes
Antes de empezar tu ciclo de planeamiento, necesitas decidir qué calidad de servicio requiere tu organización. Todas las recomendaciones y guías en este artículo son opcionales para entornos de rendimiento óptimo. Sin embargo, puedes dejarlas de lado selectivamente en casos en los que no necesites optimización. Por ejemplo, si tu organización necesita un nivel de concurrencia más alto y una experiencia de usuario más consistente, deberías considerar establecer un centro de datos. Los centros de datos te permiten prestar más atención a la redundancia y minimizar los cuellos de botella de sistema e infraestructura. En contraste, si estás planeando una expansión para una sucursal con unos cuantos usuarios, no necesitas preocuparte tanto por la optimización de hardware e infraestructura, lo que te permite elegir opciones más económicas.
Luego, deberías decidir entre máquinas físicas y virtuales. Desde un punto de vista del planeamiento de capacidad, no hay una respuesta correcta o incorrecta. Sin embargo, necesitas tener en cuenta que cada escenario te da un conjunto de variables diferente con el que puedes trabajar.
Los escenarios de virtualización te ofrecen dos opciones:
- Asignación directa, donde solo tienes un invitado por host.
- Escenarios de host compartido, donde tienes múltiples invitados por host.
Puedes tratar escenarios de asignación directa de la misma manera que hosts físicos. Si eliges una situación de host compartido, introduce otras variables que podrías tomar en consideración en secciones subsiguientes. Los hosts compartidos compiten por recursos con Active Directory Domain Services (AD DS), lo que puede afectar el rendimiento del sistema y la experiencia de usuario.
Ahora que hemos respondido esas dudas, echémosle un vistazo al ciclo del planeamiento de capacidad en sí. Cada ciclo de planeamiento de capacidad incluye un proceso de tres pasos:
- Medir el entorno existente, determinar dónde se encuentran los cuellos de botella del sistema actualmente y obtener los elementos básicos del entorno necesarios para planear la cantidad de capacidad de tus necesidades de despliegue.
- Determinar qué hardware necesitas sobre la base de tus requerimientos de capacidad.
- Monitorear y validar que la infraestructura que configuras está operando según especificaciones específicas. Los datos que obtienes en este paso se vuelven el punto base para el próximo ciclo de planeamiento de capacidad.
Aplicación del proceso
Para optimizar el rendimiento, asegúrate de que los siguientes componentes principales están correctamente seleccionados y ajustados a las cargas de la aplicación:
- Memoria
- Red
- Almacenamiento
- Procesador
- Netlogon
Los requerimientos de almacenamiento básicos para AD DS y el comportamiento general del software de cliente compatible le permite a los entornos con hasta 10.000 a 20.000 usuarios ignorar el planeamiento de capacidad para hardware físico, ya que la mayoría de los sistemas modernos basados en servidores son capaces de manejar una carga de ese tamaño. Sin embargo, las tablas en Tablas sumarias de recolección de datos explican cómo evaluar tu entorno existente para seleccionar el hardware correcto. Las secciones después de esa entran en más detalles sobre las recomendaciones de punto base y principios específicos al entorno para hardware, para ayudar a los administradores AD DS a evaluar su infraestructura.
Otra información que deberías tener en cuenta al planear:
- Cualquier dimensionamiento basado en los datos actuales solo es exacto para el entorno actual.
- Al hacer estimaciones, espera que la demanda crezca a lo largo del ciclo de vida del hardware.
- Acomoda el crecimiento futuro determinando si debes sobredimensionar tu entorno hoy o añadir capacidad gradualmente a lo largo del ciclo de vida.
- Todos los principios y metodologías del planeamiento de la capacidad que aplicarías a un despliegue físico también se aplican a un despliegue virtual. Sin embargo, al planificar un entorno virtualizado, es necesario recordar añadir los gastos generales de virtualización a cualquier planeamiento o estimación relacionada con el dominio.
- El planeamiento de capacidad es una predicción, no un valor perfectamente correcto, así que no esperes que sea perfectamente exacto. Recuerda siempre ajustar la capacidad según sea necesario y validar constantemente que tu entorno funciona como debería.
Tablas de resumen de recopilación de datos
Las siguiente tablas enumeran y explican los criterios para determinar tus estimaciones de hardware.
Entorno de trabajo
| Componente | Estimaciones |
|---|---|
| Tamaño de almacenamiento y base de datos | De 40 KB a 60 KB por cada usuario |
| CARNERO | Tamaño de base de datos Recomendaciones de sistema operativo base Aplicaciones de terceros |
| Red | 1 GB |
| Unidad Central de Procesamiento (CPU) | 1000 usuarios simultáneos por cada núcleo |
Criterios generales de evaluación
| Componente | Criterios de evaluación | Consideraciones de planeamiento |
|---|---|---|
| Tamaño de almacenamiento y base de datos | Desfragmentación sin conexión | |
| Rendimiento del almacenamiento/base de datos |
|
|
| CARNERO |
|
|
| Red |
|
|
| Unidad Central de Procesamiento (CPU) |
|
|
| NetLogon (en inglés) |
|
|
Planificación
Durante mucho tiempo, la recomendación habitual para el dimensionamiento de AD DS era poner tanta RAM como el tamaño de la base de datos. Ahora que los entornos AD DS y el ecosistema que los consume han crecido mucho, las cosas han cambiado. Aunque el aumento de la potencia de proceso y el cambio de la arquitectura x86 a x64 hicieron que los aspectos más sutiles del dimensionamiento para el rendimiento fueran irrelevantes para los clientes que ejecutan AD DS en máquinas físicas, la virtualización ha convertido el ajuste en una preocupación mucho mayor.
Para abordar estas preocupaciones, las siguientes secciones describen cómo determinar y planificar las demandas de Active Directory como un servicio. Puedes aplicar estas directrices a cualquier entorno, independientemente de si es físico, virtualizado o mixto. Para maximizar tu rendimiento, tu objetivo debe ser conseguir que tu entorno AD DS esté lo más cerca posible del límite del procesador.
CARNERO
Cuanto más almacenamiento pueda almacenar en caché la RAM, menos necesitará ir al disco. Para maximizar la escalabilidad del servidor, la cantidad mínima de RAM que utilices debe ser igual a la suma del tamaño actual de la base de datos, el tamaño total del valor del sistema, la cantidad recomendada para su sistema operativo y las recomendaciones del proveedor para los agentes (programas antivirus, monitorización, copias de seguridad, etc.). También deberías incluir RAM adicional para acomodar el crecimiento futuro durante la vida útil del servidor. Esta estimación cambiará en función del crecimiento de la base de datos y de los cambios del entorno.
Para entornos en los que maximizar la RAM no es rentable o viable, como ubicaciones por satélite o cuando el Árbol de Información de Directorio (DIT) es demasiado grande, pasa a Almacenamiento para asegurarte de que tu almacenamiento está configurado apropiadamente.
Otra cosa importante a tener en cuenta para el dimensionamiento de la memoria es el dimensionamiento del archivo de página. En el dimensionamiento del disco, como en todo lo relacionado con la memoria, el objetivo es minimizar el uso del disco. En particular, ¿cuánta RAM necesitas para minimizar la paginación? En las siguientes secciones encontrarás la información que necesitas para responder a esta pregunta. Otras consideraciones para el tamaño de página que no afectan necesariamente al rendimiento de AD DS son las recomendaciones del sistema operativo (OS) y la configuración de tu sistema para volcados de memoria.
Determinar cuánta RAM necesita un controlador de dominio (DC) puede ser difícil debido a muchos factores complejos:
- Los sistemas existentes no siempre son indicadores confiables de los requisitos de RAM porque el Servicio del Subsistema de Autoridad de Seguridad Local (LSSAS) recorta la RAM en condiciones de presión de memoria, desinflando artificialmente los requisitos.
- Los controladores de dominio individuales solo necesitan almacenar en caché los datos que les interesan a sus clientes. Esto significa que los datos almacenados en caché en distintos entornos cambiarán en función del tipo de clientes que contengan. Por ejemplo, un controlador de dominio en un entorno con Exchange Server recopilará datos diferentes con respecto a un controlador de dominio que solo autentique usuarios.
- El esfuerzo necesario para evaluar la RAM de cada controlador de dominio caso por caso suele ser excesivo y cambia a medida que cambia el entorno.
Los criterios en los que se basan las recomendaciones pueden ayudarte a tomar decisiones más informadas:
- Cuanto más caché tengas en la RAM, menos necesita ir al disco.
- El almacenamiento es el componente más lento de una computadora. El acceso a los datos en medios de almacenamiento basados en discos duros y de estado sólido es un millón de veces más lento que el acceso a los datos en RAM.
Consideraciones de virtualización para la memoria RAM
Tu objetivo para optimizar la RAM es minimizar el tiempo que pasa en disco. También debes evitar el exceso de memoria en el host. En escenarios de virtualización, el exceso de memoria es cuando el sistema asigna más RAM a los invitados de la que existe en la propia máquina física. Aunque el exceso de memoria no es un problema en sí mismo, cuando la memoria total utilizada por todos los invitados excede la capacidad de la RAM del host, provoca que el host pagine. La paginación hace que el rendimiento se ligue al disco en los casos en los que el controlador de dominio acude al NTDS.nit o al archivo de paginación para obtener datos o el host acude al disco para intentar acceder a los datos de la RAM. Como resultado, este proceso disminuye enormemente el rendimiento y la experiencia general del usuario.
Ejemplo de resumen de cálculo
| Componente | Memoria estimada (ejemplo) |
|---|---|
| RAM recomendada para el sistema operativo base (Windows Server 2008) | 2 GB |
| Tareas internas de LSASS | 200 MB |
| Agente de supervisión | 100 MB |
| Antivirus | 100 MB |
| Base de datos (catálogo global) | 8,5 GB |
| Espacio de amortiguación para que se ejecute la copia de seguridad y los administradores inicien sesión sin impacto | 1 GB |
| Total | 12 GB |
Recomendado: 16 GB
Con el tiempo, se añaden más datos a la base de datos, y el ciclo de vida promedio del servidor es de tres a cinco años. Basándonos en una estimación de crecimiento del 333 %, 16 GB es una cantidad razonable de RAM para colocar en un servidor físico.
Red
Esta sección trata sobre la evaluación del ancho de banda total y la capacidad de red que necesita tu despliegue, incluidas las consultas de clientes, la configuración de las Políticas del Grupo, etc. Puedes recolectar datos para realizar tu estimación utilizando el Network Interface(*)\Bytes Received/sec y Network Interface(*)\Bytes Sent/sec contadores de rendimiento. Los intervalos de muestra para los contadores de la interfaz de red deben ser de 15, 30 o 60 minutos. Cualquier intervalo menor a eso será demasiado volátil para obtener buenas mediciones, y todo lo que sea superior suavizará excesivamente los picos diarios.
Nota:
Por lo general, la mayoría del tráfico de red en un controlador de dominio es saliente, ya que el controlador de dominio responde a las consultas de cliente. Como resultado, esta sección se centra principalmente en el tráfico saliente. Sin embargo, también te recomendamos que evalúes cada uno de tus entornos para el tráfico entrante. Puedes utilizar las directrices de este artículo para evaluar también los requisitos del tráfico de red entrante. Para más información, consulta 929851: El rango de puertos dinámicos predeterminado para TCP/IP ha cambiado en Windows Vista y en Windows Server 2008.
Necesidades de ancho de banda
El planeamiento de la escalabilidad de red abarca dos categorías distintas: la cantidad de tráfico y la carga de CPU debida al tráfico de red.
Hay dos cosas que debes tener en cuenta en el planeamiento de capacidad para soporte de tráfico. En primer lugar, necesitas saber cuánto Tráfico de replicación de Active Directory ocurre entre tus controladores de dominio. En segundo lugar, debes evaluar el tráfico interno del cliente al servidor. El tráfico dentro del sitio recibe principalmente pequeñas peticiones de los clientes en relación con las grandes cantidades de datos que envía de vuelta a los clientes. 100 MB suelen ser suficientes para entornos con hasta 5.000 usuarios por servidor. Para entornos de más de 5.000 usuarios, te recomendamos que utilices un adaptador de red de 1 GB y soporte de escalado lateral de recepción (RSS).
Para evaluar la capacidad de tráfico dentro del sitio, especialmente en entornos de consolidación de servidores, debes mirar el Network Interface(*)\Bytes/sec contador de rendimiento en todos los controladores de dominio en un sitio, sumarlos y dividir la suma por el número deseado de controladores de dominio. Una forma fácil de calcular este número es abrir el Monitor de rendimiento y confiabilidad de Windows y revisa la vista de Área apilada. Asegúrate de que todos los contadores tengan la misma escala.
Veamos un ejemplo de una forma más compleja de validar que esta regla general se aplica a un entorno específico. En este ejemplo, partimos de los siguientes supuestos:
- El objetivo es reducir la superficie al menor número de servidores posible. Idealmente, un servidor soporta la carga y, a continuación, despliegues un servidor adicional para redundancia (n + 1 situación).
- En esta situación, el adaptador de red actual solo admite 100 MB y se encuentra en un entorno de switch.
- El objetivo máximo de utilización del ancho de banda de la red es del 60 % en una n situación (pérdida de un controlador de dominio).
- Cada servidor tiene unos 10 000 clientes conectados a él.
Ahora, echemos un vistazo a lo que el gráfico del contador Network Interface(*)\Bytes Sent/sec dice sobre esta situación de ejemplo:
- La jornada laboral comienza alrededor de las 5:30 a. m. y termina a las 7:00 p. m.
- El periodo de mayor actividad es desde las 8:00 y hasta las 8:15 a. m., con más de 25 bytes enviados por segundo en el controlador de dominio de mayor actividad.
Nota:
Todos los datos de rendimiento son históricos, por lo que el punto de datos máximo a las 8:15 a. m. indica la carga desde las 8:00 hasta las 8:15 a. m.
- Hay picos antes de las 4:00 a. m., con más de 20 bytes enviados por segundo en el controlador de dominio más activo, lo que podría indicar una carga procedente de distintas zonas horarias o una actividad de fondo de la infraestructura, como las copias de seguridad. Dado que el pico a las 8:00 a. m. supera esta actividad, no es relevante.
- Hay cinco controladores de dominio en el sitio.
- La carga máxima es de unos 5,5 MBps por controlador de dominio, lo que representa el 44 % de la conexión de 100 MB. Con estos datos, podemos estimar que el ancho de banda total necesario entre las 8:00 a. m. y las 8:15 a. m. es de 28 MBps.
Nota:
Los contadores de envío/recepción de la interfaz de red están en bytes, pero el ancho de banda de la red se mide en bits. Por tanto, para calcular el ancho de banda total, tendrías que hacer la operación 100 MB ÷ 8 = 12,5 MB y 1 GB ÷ 8 = 128 MB.
Ahora que hemos revisado los datos, ¿qué conclusiones podemos sacar de ello?
- El entorno actual cumple el n + 1 nivel de tolerancia a fallas con una utilización deseada del 60 %. Si se desconecta un sistema, el ancho de banda por servidor pasará de unos 5,5 MBps (44 %) a unos 7 MBps (56 %).
- Sobre la base del objetivo previamente establecido de consolidar a un solo servidor, este cambio supera la utilización máxima prevista y posible de una conexión de 100 MB.
- Con una conexión de 1 GB, este valor representa el 22 % de la capacidad total.
- Bajo condiciones normales de funcionamiento en la n + 1 situación, la carga del cliente se distribuye de forma relativamente uniforme en alrededor de 14 MBps por servidor o el 11 % de la capacidad total.
- Para asegurarte de que tienes capacidad suficiente mientras un controlador de dominio no está disponible, los objetivos operativos normales por servidor serían aproximadamente un 30 % de utilización de la red o 38 MBps por servidor. Los objetivos de conmutación por error serían una utilización de la red del 60 % o 72 MBps por servidor.
El despliegue final del sistema debe contar con un adaptador de red de 1 GB y una conexión a una infraestructura de red que soporte dicha carga. Debido a la cantidad de tráfico de red, la carga de CPU de las comunicaciones de red puede limitar potencialmente la escalabilidad máxima de AD DS. Puedes utilizar este mismo proceso para estimar la comunicación entrante al controlador de dominio. Sin embargo, en la mayoría de los casos, no será necesario calcular el tráfico entrante porque es menor que el saliente.
Es importante asegurarse de que el hardware soporta RSS en entornos con más de 5.000 usuarios por servidor. Para escenarios de alto tráfico de red, equilibrar la carga de interrupciones puede suponer un cuello de botella. Puedes detectar posibles cuellos de botella comprobando el Processor(*)\% Interrupt Time contador para ver si el tiempo de interrupción se distribuye de forma desigual entre las CPU. Los controladores de interfaz de red (NIC) con RSS pueden mitigar estas limitaciones y aumentar la escalabilidad.
Nota:
Puedes adoptar un enfoque similar para estimar si necesitas más capacidad al consolidar centros de datos o retirar un controlador de dominio en una sucursal. Para estimar la capacidad requerida, basta con mirar los datos de tráfico de salida y de entrada a los clientes. El resultado es la cantidad de tráfico presente en los enlaces de la red de área extensa (WAN).
En algunos casos, es posible que experimente más tráfico de lo esperado porque el tráfico es más lento, como cuando la comprobación de certificados no cumple los tiempos de espera agresivos de la WAN. Por este motivo, el dimensionamiento y el uso de WAN deben ser un proceso iterativo y continuo.
Consideraciones de virtualización para el ancho de banda de red
Las recomendaciones típicas para un servidor físico son de 1 GB para servidores que soporten más de 5.000 usuarios. Una vez que varios invitados comienzan a compartir una infraestructura de conmutación virtual subyacente, debes prestar especial atención a si el host tiene un ancho de banda de red adecuado para soportar todos los invitados en el sistema. Debes tener en cuenta el ancho de banda independientemente de si la red incluye el controlador de dominio que se ejecuta como una máquina virtual en un host con tráfico de red que va a través de un switch virtual o directamente conectado a un switch físico. Los switches virtuales son componentes en los que el enlace ascendente debe soportar la cantidad de datos que transmite la conexión, lo que significa que el adaptador de red host físico vinculado al switch debe ser capaz de soportar la carga del controlador de dominio más todos los demás invitados que compartan el switch virtual conectado al adaptador de red físico.
Ejemplo de resumen de cálculo de red
La siguiente tabla contiene valores de una situación de ejemplo que podemos utilizar para calcular la capacidad de la red:
| Sistema | Ancho de banda máximo |
|---|---|
| DC 1 | 6,5 MBps |
| DC 2 | 6,25 MBps |
| DC 3 | 6,25 MBps |
| DC 4 | 5,75 MBps |
| DC 5 | 4,75 MBps |
| Total | 28,5 MBps |
Según esta tabla, el ancho de banda recomendado sería de 72 MBps (28,5 MBps ÷ 40 %).
| Conteo del sistema deseado | Ancho de banda total (según aparece anteriormente) |
|---|---|
| 2 | 28,5 MBps |
| Comportamiento normal resultante | 28,5 ÷ 2 = 14,25 MBps |
Como siempre, debes asumir que la carga de clientes aumentará con el tiempo, por lo que debes planificar este crecimiento lo antes posible. Te recomendamos que planifiques un crecimiento estimado del tráfico de red de al menos un 50 %.
Almacenamiento
Hay dos cosas que debes tener en cuenta a la hora de planificar la capacidad de almacenamiento:
- Capacidad o tamaño de almacenamiento
- Rendimiento
Aunque la capacidad es importante, no hay que descuidar el rendimiento. Con los costes de hardware actuales, la mayoría de los entornos no son lo suficientemente grandes como para que ninguno de los dos factores sea una preocupación importante. Por lo tanto, la recomendación habitual es poner tanta RAM como el tamaño de la base de datos. Sin embargo, esta recomendación podría ser excesiva para sucursales en entornos de mayor tamaño.
Ajuste de tamaño
Evaluación del almacenamiento
En comparación con los primeros tiempos de Active Directory, cuando las unidades de 4 GB y 9 GB eran los tamaños más comunes, ahora el dimensionamiento de Active Directory ni siquiera se tiene en cuenta, salvo en los entornos más grandes. Con los tamaños de disco duro más pequeños disponibles de aproximadamente 180 GB, todo el sistema operativo, SYSVOL y NTDS.dit pueden caber fácilmente en una unidad. Como resultado, te recomendamos que evites invertir demasiado en esta área.
Nuestra única recomendación es que te asegures de que el 110 % del tamaño de NTS.dit esté disponible para que puedas desfragmentar tu almacenamiento. Más allá de eso, debes tener en cuenta las consideraciones habituales para acomodar el crecimiento futuro.
Si vas a evaluar tu almacenamiento, primero debes evaluar el tamaño que deben tener NTDS.dit y SYSVOL. Estas mediciones te ayudarán a dimensionar tanto el disco fijo como las asignaciones de RAM. Debido a que los componentes son relativamente baratos, no hace falta ser muy preciso al hacer los cálculos. Para obtener más información sobre la evaluación del almacenamiento, consulta Límites de almacenamiento y Estimaciones de crecimiento para usuarios y unidades organizativas de Active Directory.
Nota:
Los artículos enlazados en el párrafo anterior se basan en estimaciones del tamaño de los datos realizadas durante el lanzamiento de Active Directory en Windows 2000. Al hacer tu propia estimación, utiliza tamaños de objetos que reflejen el tamaño real de los objetos de tu entorno.
Al revisar los entornos existentes con varios dominios, es posible que observes variaciones en el tamaño de las bases de datos. Cuando detectes estas variaciones, utiliza los tamaños más pequeños de catálogo global (GC) y de los que no pertenecen al GC.
El tamaño de las bases de datos puede variar según la versión del sistema operativo. Los controladores de dominio que ejecutan versiones anteriores del sistema operativo, como Windows Server 2003, tienen bases de datos de menor tamaño que los que ejecutan versiones posteriores, como Windows Server 2008 R2. El controlador de dominio que tenga habilitadas funciones como Active Directory REcycle Bin o Credential Roaming también puede afectar al tamaño de la base de datos.
Nota:
- Para entornos nuevos, recuerda que 100.000 usuarios en un mismo dominio consumen unos 450 MB de espacio. Los atributos que rellenes pueden tener un gran impacto en la cantidad total de espacio consumido. Los atributos se rellenan con muchos objetos de productos tanto de terceros como de Microsoft, incluidos Microsoft Exchange Server y Lync. Como resultado, te recomendamos que evalúes en función de la cartera de productos del entorno. Sin embargo, también hay que tener en cuenta que hacer los cálculos y las pruebas para obtener estimaciones precisas para todos los entornos, salvo los más grandes, puede no merecer mucho tiempo o esfuerzo.
- Asegúrate de que el espacio libre disponible es de un 110 % del tamaño de NTDS.dit para activar la desfragmentación sin conexión. Este espacio libre también te permite planificar el crecimiento durante los tres a cinco años del ciclo de vida del hardware del servidor. Si dispones de espacio para ello, asignar suficiente espacio libre para igualar el 300 % del DIT para almacenamiento es una forma segura de acomodar el crecimiento y la desfragmentación.
Consideraciones de virtualización para el almacenamiento
En escenarios en los que asignes varios archivos de disco duro virtual (VHD) a un único volumen, debes utilizar un disco de estado fijo de al menos el 210 % del tamaño del DIT (100 % del DIT + 110% de espacio libre) para asegurarte de que tienes suficiente espacio reservado para tus necesidades.
Ejemplo de resumen de cálculo de almacenamiento
La siguiente tabla enumera los valores que utilizarías para estimar los requisitos de espacio para una situación de almacenamiento hipotética.
| Datos recopilados en la fase de evaluación | Tamaño |
|---|---|
| Tamaño del archivo NTDS.dit | 35 GB |
| Modificador para permitir la desfragmentación sin conexión | 2,1 GB |
| Almacenamiento total necesario | 73,5 GB |
Nota:
La estimación de almacenamiento también debe incluir cuánto almacenamiento necesitas para SYSVOL, el sistema operativo, el archivo de páginas, los archivos temporales, los datos locales almacenados en caché, como los archivos de instalación, y las aplicaciones.
Rendimiento del almacenamiento
Como el componente más lento de cualquier equipo, el almacenamiento puede tener el mayor impacto adverso en la experiencia del cliente. Para entornos lo suficientemente grandes como para que las recomendaciones de dimensionamiento de RAM de este artículo no sean factibles, las consecuencias de pasar por alto la planificación de la capacidad de almacenamiento pueden ser devastadoras para el rendimiento del sistema. Las complejidades y variedades de la tecnología de almacenamiento disponible aumentan aún más el riesgo, ya que la recomendación típica de poner el sistema operativo, los registros y la base de datos en discos físicos separados no se aplica universalmente a todos los escenarios.
Las antiguas recomendaciones sobre discos daban por sentado que un disco era un disco duro dedicado que permitía una E/S aislada. Esta suposición ya no es cierta debido a la introducción de los siguientes tipos de almacenamiento:
- INCURSIÓN
- Nuevos tipos de almacenamiento y escenarios de almacenamiento virtualizado y compartido
- Ejes compartidos en una red de área de almacenamiento (SAN)
- Archivo VHD en una SAN o un almacenamiento conectado a la red
- Unidades de estado sólido (SSDs)
- Arquitecturas de almacenamiento por niveles, como almacenamiento en caché de estado sólido para almacenamiento más grande basado en discos duros.
El almacenamiento compartido, como RAID, SAN, NAS, JBOD, Storage Spaces y VHD, es capaz de sobrecargarse por otras cargas de trabajo que coloques en el almacenamiento backend. Estos tipos de almacenamiento también suponen un reto adicional: los problemas de SAN, red o controladores entre el disco físico y la aplicación AD pueden provocar ralentizaciones y retrasos. Aclaremos que no son malas configuraciones, pero son más complejas, lo que significa que hay que prestar más atención para asegurarse de que todos los componentes funcionan como es debido. Para explicaciones más detalladas, consulta Apéndice C y Apéndice D más adelante en este artículo. Además, aunque los discos de estado sólido no están limitados por los discos duros que solo pueden procesar una E/S a la vez, siguen teniendo limitaciones de E/S que pueden sobrecargarse.
En resumen, el objetivo de toda planificación del rendimiento del almacenamiento, independientemente de la arquitectura de almacenamiento, es garantizar que el número necesario de E/S esté siempre disponible y que se produzcan en un plazo aceptable. Para escenarios con un almacenamiento enlazado localmente, consulta Apéndice C para más información sobre diseño y planeamiento. Puedes aplicar los principios del apéndice a escenarios de almacenamiento más complejos, así como a las conversaciones con los proveedores que respaldan tus soluciones de almacenamiento back-end.
Debido a la gran cantidad de opciones de almacenamiento disponibles en la actualidad, te recomendamos que consultes a tus equipos de soporte o proveedores de hardware durante la planificación para asegurarte de que la solución satisface las necesidades de tu despliegue de AD DS. Durante estas conversaciones, puede que los siguientes contadores de rendimiento te resulten útiles, especialmente cuando tu base de datos es demasiado grande para tu memoria RAM:
-
LogicalDisk(*)\Avg Disk sec/Read(por ejemplo, si NTDS.dit está almacenado en la unidad D, la ruta completa seríaLogicalDisk(D:)\Avg Disk sec/Read) LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
Al proporcionar los datos, debes asegurarte de que se muestrean en intervalos de 15, 30 o 60 minutos para ofrecer la imagen más precisa posible de tu entorno actual.
Evaluación de los resultados
Esta sección se centra en las lecturas de la base de datos, ya que esta suele ser el componente más exigente. Puedes aplicar la misma lógica a las escrituras en el archivo de registro sustituyendo <NTDS Log>)\Avg Disk sec/Write y LogicalDisk(<NTDS Log>)\Writes/sec).
El LogicalDisk(<NTDS>)\Avg Disk sec/Read contador muestra si el almacenamiento actual tiene el tamaño adecuado. Si el valor es aproximadamente igual al tiempo de acceso al disco esperado para el tipo de disco, el LogicalDisk(<NTDS>)\Reads/sec contador es una medida válida. Si los resultados son aproximadamente iguales al tiempo de acceso al disco para el tipo de disco, el LogicalDisk(<NTDS>)\Reads/sec contador es una medida válida. Aunque esto puede cambiar dependiendo de las especificaciones del fabricante que tenga tu almacenamiento back-end, pero buenos rangos para LogicalDisk(<NTDS>)\Avg Disk sec/Read serían aproximadamente:
- 7200 rpm: de 9 a 12,5 milisegundos (ms)
- 10.000 rpm: 6 a 10 ms
- 15.000 rpm: 4 a 6 ms
- SSD: de 1 a 3 ms
Puede que oigas de otras fuentes que el rendimiento del almacenamiento se degrada a los 15 ms o 20 ms. La diferencia entre esos valores y los de la lista anterior es que los valores de la lista muestran el rango de funcionamiento normal. Los otros valores son para fines de solución de problemas, que le ayudan a identificar cuando la experiencia del cliente se ha degradado lo suficiente como para que sea perceptible. Para más información, consulta Apéndice C.
-
LogicalDisk(<NTDS>)\Reads/seces la cantidad de E/S que el sistema está rindiendo actualmente.- Si
LogicalDisk(<NTDS>)\Avg Disk sec/Readestá dentro del rango óptimo para el almacenamiento back-end, puedes utilizar directamenteLogicalDisk(<NTDS>)\Reads/secpara dimensionar el almacenamiento. - Si
LogicalDisk(<NTDS>)\Avg Disk sec/Readno está dentro del rango óptimo para el almacenamiento back-end, se necesita E/S adicional de acuerdo con la siguiente fórmula:LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ Tiempo de Acceso al Disco del Medio Físico ×LogicalDisk(<NTDS>)\Avg Disk sec/Read
- Si
Al hacer estos cálculos, debes tener en cuenta lo siguiente:
- Si el servidor tiene una cantidad de RAM inferior a la óptima, los valores resultantes serán demasiado altos y no serán lo suficientemente precisos como para ser útiles para el planeamiento. Sin embargo, aún puedes utilizarlos para predecir los peores escenarios.
- Si añades u optimizas RAM, también disminuye la cantidad de E/S de lectura
LogicalDisk(<NTDS>)\Reads/Sec. Esta disminución puede hacer que la solución de almacenamiento no sea tan robusta como se pensaba en los cálculos originales. Desafortunadamente, no podemos dar más detalles sobre lo que significa esta afirmación, ya que los cálculos varían mucho en función de cada entorno, sobre todo de la carga de clientes. Sin embargo, te recomendamos que ajustes el dimensionamiento del almacenamiento después de optimizar la RAM.
Consideraciones de virtualización para el rendimiento
Al igual que en las secciones anteriores, nuestro objetivo aquí es asegurarnos de que la infraestructura compartida puede soportar la carga total de todos los consumidores. Debes tener presente este objetivo cuando planees los siguientes escenarios:
- Un CD físico que comparte el mismo soporte en una infraestructura SAN, NAS o iSCSI que otros servidores o aplicaciones.
- Un usuario que utiliza el acceso de tránsito a una infraestructura SAN, NAS o iSCSI que comparte el medio.
- Un usuario que utiliza un archivo VHD en un medio compartido localmente o en una infraestructura SAN, NAS o iSCSI.
Desde la perspectiva de un usuario invitado, tener que pasar por un host para acceder a cualquier almacenamiento afecta al rendimiento, ya que el usuario debe recorrer rutas de código adicionales para obtener acceso. Las pruebas de rendimiento indican que la virtualización afecta al rendimiento en función de la parte del procesador que utiliza el sistema host. La utilización de los procesadores también se ve influida por la cantidad de recursos que el usuario invitado exige al host. Esta demanda contribuye a las Consideraciones de virtualización para procesamiento que debes tomar para las necesidades de procesamiento en escenarios virtualizados. Para más información, consulta Apéndice A.
Para complicar aún más las cosas, hay muchas opciones de almacenamiento disponibles en la actualidad, cada una de ellas con efectos muy diferentes en el rendimiento. Estas opciones incluyen almacenamiento de tránsito, adaptadores SCSI e IDE. Al cambiar de un entorno físico a uno virtual, debes ajustar las diferentes opciones de almacenamiento para los usuarios invitados virtualizados utilizando un multiplicador de 1,10. Sin embargo, no es necesario tener en cuenta los ajustes al transferir entre distintos escenarios de almacenamiento, ya que importa más si el almacenamiento es local, SAN, NAS o iSCSI.
Ejemplo de cálculo de virtualización
Determinar la cantidad de E/S necesaria para un sistema en estado correcto en condiciones de funcionamiento normales:
- LogicalDisk(
<NTDS Database Drive>) ÷ Transferencias por segundo durante el periodo pico de 15 minutos - Para determinar la cantidad de E/S necesaria para el almacenamiento cuando se supera la capacidad del almacenamiento subyacente:
IOPS necesaria = (LogicalDisk(
<NTDS Database Drive>)) ÷ Lecturas promedio de disco/seg ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\Lecturas/seg
| Contador | Valor |
|---|---|
LogicalDisk Real(<NTDS Database Drive>)\Transferencia promedio de disco/seg |
0,02 segundos (20 milisegundos) |
LogicalDisk objetivo(<NTDS Database Drive>)Transferencia promedio de disco/seg |
0,01 segundos |
| Multiplicador del cambio de E/S disponibles | 0,02 ÷ 0,01 = 2 |
| Nombre del valor | Valor |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Transferencias/seg. |
400 |
| Multiplicador del cambio de E/S disponibles | 2 |
| IOPS totales necesarias durante el período máximo | 800 |
Para determinar la velocidad a la que debes calentar la caché:
- Determina el tiempo máximo que consideras aceptable dedicar al calentamiento del caché. En escenarios típicos, una cantidad de tiempo aceptable sería lo que debería tardar en cargarse toda la base de datos desde un disco. En escenarios en los que la RAM no pueda cargar toda la base de datos, utiliza el tiempo que tardaría en llenarse toda la RAM.
- Determina el tamaño de la base de datos, excluyendo el espacio que no tengas previsto utilizar. Para más información, consulte Evaluación del almacenamiento.
- Divide el tamaño de la base de datos por 8 KB para obtener el número total de E/S que necesita para cargar la base de datos.
- Divide el total de E/S por el número de segundos en el intervalo de tiempo definido.
El número que calculas es en su mayor parte exacto, pero puede no serlo porque no has configurado (Extensible Storage Engine) ESE para que tenga un tamaño de caché fijo, entonces AD DS desalojará las páginas cargadas previamente porque utiliza un tamaño de caché variable por defecto.
| Puntos de datos que se van a recopilar | Valores |
|---|---|
| Tiempo máximo aceptable para la activación | 10 minutos (600 segundos) |
| Tamaño de base de datos | 2 GB |
| Paso de cálculo | Fórmula | Resultado |
|---|---|---|
| Cálculo del tamaño de la base de datos en páginas | (2 GB × 1024 × 1024) = Tamaño de la base de datos en KB | 2 097 152 KB |
| Cálculo del número de páginas de la base de datos | 2 097 152 KB ÷ 8 KB = Número de páginas | 262 144 páginas |
| Cálculo de las IOPS necesarias para activar completamente la memoria caché | 262 144 páginas ÷ 600 segundos = IOPS necesarias | 437 IOPS |
Procesamiento
Evaluación del uso de procesador de Active Directory
En la mayoría de los entornos, la administración de la capacidad de procesamiento es el componente que merece más atención. Al evaluar cuánta capacidad de CPU necesita tu despliegue, debes tener en cuenta los dos aspectos siguientes:
- ¿Se comportan las aplicaciones de tu entorno según lo previsto dentro de una infraestructura de servicios compartidos basándose en los criterios expuestos en Seguimiento de búsquedas costosas e ineficientes? En entornos más grandes, las aplicaciones mal programadas pueden hacer que la carga de la CPU se vuelva volátil, ocupar una cantidad desmesurada de tiempo de la CPU a expensas de otras aplicaciones, aumentar las necesidades de capacidad y distribuir de forma desigual la carga entre los controladores de dominio.
- AD DS es un entorno distribuido con muchos clientes potenciales cuyas necesidades de procesamiento varían ampliamente. Los costes estimados para cada cliente pueden variar debido a los patrones de uso y a cuántas aplicaciones utilizan AD DS. De la misma manera que en Red, debes enfocar la estimación como una evaluación de la capacidad total necesaria en el entorno, en lugar de mirar a cada cliente de uno en uno.
Solo debes hacer esta estimación después de haber completado tu estimación de almacenamiento, ya que no podrás hacer una estimación precisa sin datos válidos sobre la carga de tu procesador. También es importante asegurarse de que los cuellos de botella no están causados por el almacenamiento antes de solucionar el problema del procesador. A medida que se eliminan los estados de espera del procesador, la utilización de la CPU aumenta porque ya no necesita esperar los datos. Por lo tanto, los contadores de rendimiento a los que debes prestar más atención son Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read y Process(lsass)\ Processor Time. Si el Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read contador es superior a 10 o 15 milisegundos, entonces los datos en Process(lsass)\ Processor Time son artificialmente bajos y el problema está relacionado con el rendimiento del almacenamiento. Te recomendamos que fijes los intervalos de muestra en 15, 30 o 60 minutos para obtener los datos más precisos posibles.
Visión general del procesamiento
Para planear la capacidad de los controladores de dominio, la potencia de procesamiento requiere la mayor atención y comprensión. Al hacer el dimensionamiento de los sistemas para garantizar el máximo rendimiento, siempre hay un componente que es el cuello de botella, y en un controlador de dominio de tamaño adecuado este componente es el procesador.
De forma similar a la sección de redes, en la que se revisa la demanda del entorno sitio a sitio, se debe hacer lo mismo para la capacidad de proceso demandada. A diferencia de la sección de redes, donde las tecnologías de redes disponibles superan con creces la demanda normal, preste más atención al dimensionamiento de la capacidad de CPU. Como cualquier entorno de tamaño incluso moderado, cualquier cosa que supere unos miles de usuarios simultáneos puede poner una carga significativa en la CPU.
Desafortunadamente, debido a la enorme variabilidad de las aplicaciones cliente que aprovechan AD, una estimación general de usuarios por CPU es inaplicable a todos los entornos. Específicamente, las demandas de proceso están sujetas al comportamiento del usuario y al perfil de aplicación. Por lo tanto, se debe dimensionar de forma individual cada entorno.
Perfil de comportamiento objetivo del sitio
Cuando planifiques la capacidad de todo un sitio, tu objetivo debe ser un N + 1 diseño de capacidad. En este diseño, incluso si un sistema falla durante el periodo pico, el servicio puede continuar con niveles aceptables de calidad. En una situación N, la carga en todas las cajas debe ser inferior al 80 %-100 % durante los periodos pico.
Además, las aplicaciones y los clientes del sitio utilizan el DsGetDcName function método recomendado para localizar los controladores de dominio, ya deberían estar distribuidos uniformemente con solo pequeños picos transitorios.
Ahora vamos a ver dos ejemplos de entornos que están dentro y fuera del objetivo. En primer lugar, vamos a ver un ejemplo de un entorno que funciona según lo previsto y no supera el objetivo del planeamiento de capacidad.
Para el primer ejemplo, partimos de los siguientes supuestos:
- Cada uno de los cinco controladores de dominio del sitio tiene cuatro CPU.
- El uso total de CPU deseado durante el horario laboral es del 40 % en condiciones normales de funcionamiento (N + 1) y 60 % en caso contrario (N). Durante las horas no laborales, el objetivo de uso de la CPU es del 80 % porque esperamos que el software de copia de seguridad y otros procesos de mantenimiento consuman todos los recursos disponibles.
Ahora, echemos un vistazo al (Processor Information(_Total)\% Processor Utility) gráfico, para cada uno de los controladores de dominio, como se muestra en la siguiente imagen.
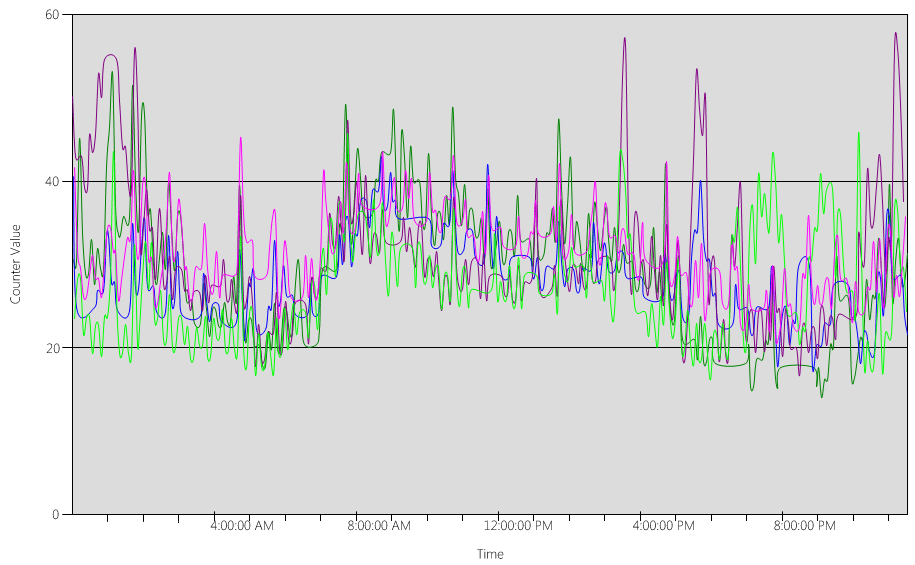
La carga está distribuida de forma relativamente uniforme, que es lo que cabría esperar cuando los clientes hacen uso del localizador de controladores de dominio y de búsquedas bien escritas.
En varios intervalos de cinco minutos, hay picos del 10 %, a veces incluso del 20 %. Sin embargo, a menos que estos picos hagan que el uso de la CPU supere el objetivo del plan de capacidad, no es necesario investigarlos.
El periodo pico para todos los sistemas es entre las 8:00 a. m. y las 9:15 a. m. La jornada laboral media dura desde las 5:00 a. m. hasta las 5:00 p. m.. Por lo tanto, cualquier pico aleatorio de uso de la CPU que se produzca entre las 5:00 p. m. y las 4:00 a. m. está fuera del horario laboral y, por lo tanto, no es necesario incluirlo en tus preocupaciones del planeamiento de capacidad.
Nota:
En un sistema bien gestionado, los picos que se producen durante el periodo valle suelen estar causados por el software de copia de seguridad, los análisis antivirus completos del sistema, el inventario de hardware o software, la implantación de software o parches, etc. Como estos picos se producen fuera del horario laboral, no cuentan para superar los objetivos del planeamiento de capacidad.
Como cada sistema funciona al 40 % y todos tienen el mismo número de CPU, si uno de ellos se desconecta, los restantes funcionan a un 53 % estimado. El sistema D tiene una carga del 40 % que se divide a partes iguales y se añade a la carga existente del 40 % de los sistemas A y C. Esta suposición lineal no es perfectamente exacta, pero proporciona suficiente precisión para hacer suposiciones.
A continuación, veamos un ejemplo de un entorno que no tiene un buen uso de la CPU y supera el objetivo del planeamiento de capacidad.
En este ejemplo, tenemos dos controladores de dominio funcionando al 40 %. Un controlador de dominio se desconecta, lo que provoca que el uso estimado de CPU en el controlador de dominio restante alcance el 80 %. Este nivel de uso de la CPU supera con creces el umbral del plan de capacidad y empieza a limitar el margen de maniobra del 10 % al 20 % del perfil de carga. Como resultado, cada pico podría potencialmente llevar el controlador de dominio al 90 % o incluso al 100 % durante la N situación, reduciendo su capacidad de respuesta.
Cálculo de las demandas de CPU
El Process\% Processor Time contador de rendimiento rastrea la cantidad total de tiempo que todos los hilos de la aplicación pasan en la CPU, y luego divide esa suma por la cantidad total de tiempo del sistema que ha pasado. Una aplicación de hilos múltiples en un sistema de CPU múltiples puede superar el 100 % de tiempo de CPU, e interpretarías sus datos de manera muy diferente a la del Processor Information\% Processor Utility contador. En la práctica, el contador Process(lsass)\% Processor Time registra cuántas CPU funcionando al 100 % necesita el sistema para soportar las demandas de un proceso. Por ejemplo, si el contador tiene un valor del 200 %, significa que el sistema necesita dos CPU funcionando al 100 % para soportar toda la carga de AD DS. Aunque una CPU que funcione al 100 % de su capacidad es la más rentable en términos de potencia y consumo de energía, por las razones expuestas en el Apéndice A, un sistema de hilos múltiples responde mejor cuando su sistema no funciona al 100 %.
Para hacer frente a los picos transitorios de carga de los clientes, te recomendamos que te fijes como objetivo un pico de CPU entre el 40 % y el 60 % de la capacidad del sistema. Por ejemplo, en el primer ejemplo en el Perfil de comportamiento del sitio objetivo, necesitarías entre 3,33 CPU (60 % del objetivo) y 5 CPU (40 % del objetivo) para soportar la carga de AD DS. Deberás añadir capacidad adicional en función de las exigencias del sistema operativo y de cualquier otro agente necesario, como antivirus, copias de seguridad, supervisión, etc. Aunque deberías evaluar el impacto de los agentes en la CPU en función de cada entorno, por lo general puedes asignar entre un 5 % y un 10 % para procesos de agentes en una única CPU. Volviendo a nuestro ejemplo, necesitaríamos entre 3,43 (60 % del objetivo) y 5,1 (40 % del objetivo) CPU para soportar la carga durante los periodos pico.
Veamos ahora un ejemplo de cálculo para un proceso concreto. En este caso, se trata del proceso LSASS.
Cálculo del uso de CPU para el proceso LSASS
En este ejemplo, el sistema es una N + 1 situación donde un servidor lleva la carga de AD DS mientras que un servidor extra está ahí por redundancia.
El siguiente gráfico muestra el tiempo de procesamiento del proceso LSASS en todos los procesadores para esta situación de ejemplo. Estos datos se obtuvieron del Process(lsass)\% Processor Time contador de rendimiento.
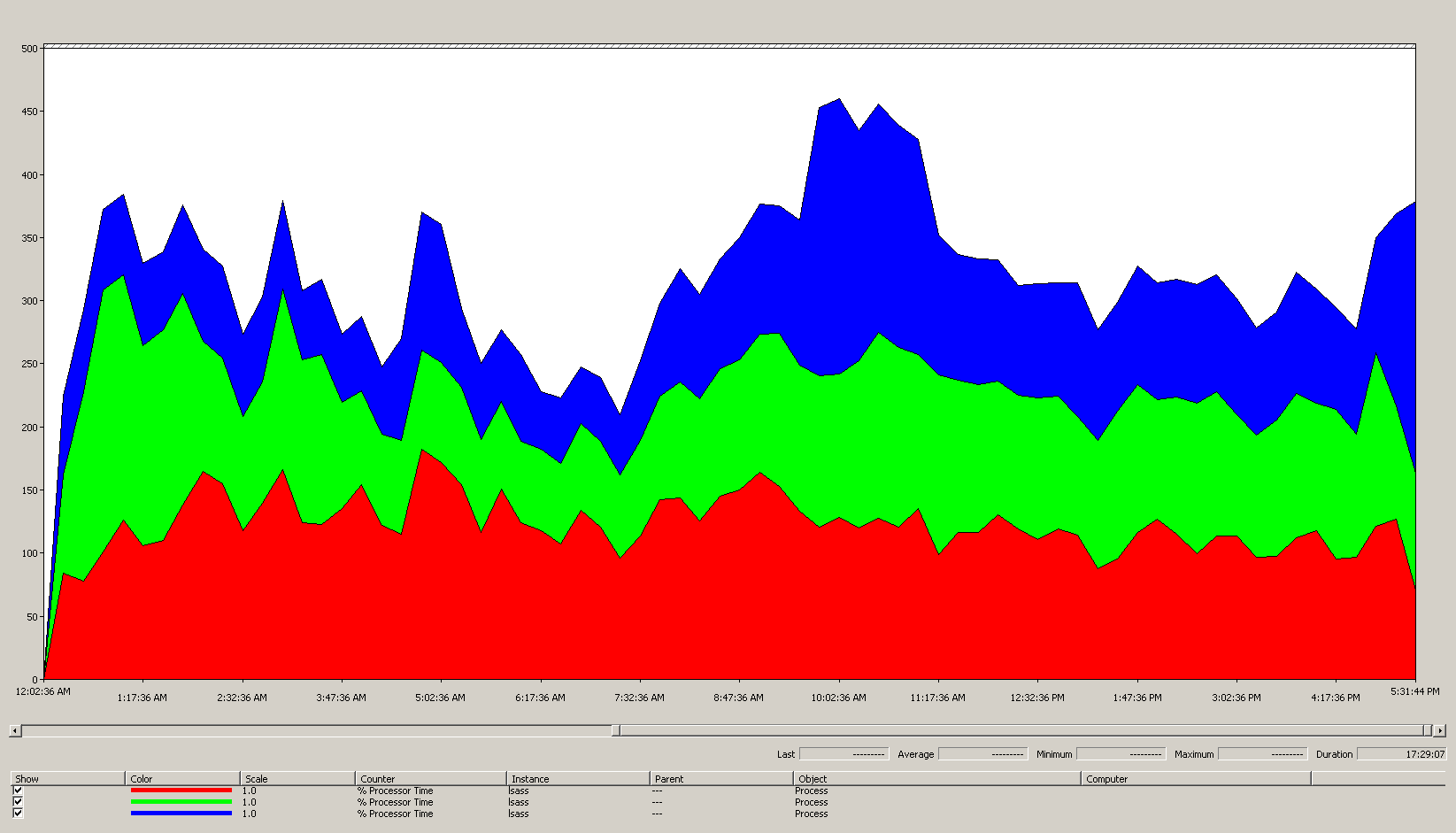
Esto es lo que nos dice este gráfico sobre el entorno de la situación:
- Hay tres controladores de dominio en el sitio.
- La jornada laboral comienza alrededor de las 7 a. m. y termina a las 5 p. m.
- El periodo con mayor actividad es entre las 9:30 a. m y las 11.00 a. m.
Nota:
Todos los datos de rendimiento son históricos. El punto de datos pico a las 9:15 a. m. indica la carga desde las 9:00 a. m. hasta las 9:15 a. m.
- Los picos antes de las 7:00 a. m. podrían indicar una carga extra procedente de diferentes zonas horarias o de una actividad de infraestructura de fondo, como las copias de seguridad. Sin embargo, como este pico es inferior a la actividad máxima de las 9:30 a. m., no es motivo de preocupación.
A carga máxima, el proceso lsass consume alrededor de 4,85 CPU funcionando al 100 %, lo que supondría un 485 % en una sola CPU. Estos resultados sugieren que el sitio de la situación necesita alrededor de 12/25 CPU para manejar AD DS. Si se tiene en cuenta la capacidad adicional recomendada del 5 % al 10 % para procesos en segundo plano, el servidor necesita entre 12,30 y 12,25 CPU para soportar su carga actual. Las estimaciones que prevén un crecimiento futuro hacen que esta cifra sea aún mayor.
Cuándo ajustar las ponderaciones de LDAP
Hay ciertos escenarios en las que deberías considerar hacer un ajuste de LdapSrvWeight. En el contexto del planeamiento de capacidad, se ajustaría cuando las aplicaciones, las cargas de usuarios o las capacidades del sistema subyacente no estuvieran equilibradas.
Las siguientes secciones describen dos escenarios de ejemplo en los que deberías ajustar los pesos del Protocolo ligero de acceso a directorios (LDAP).
Ejemplo 1: Entorno emulador de PDC
Si utilizas un emulador de Controlador de dominio primario (PDC), el comportamiento desigual de los usuarios o las aplicaciones puede afectar a varios entornos a la vez. Los recursos de la CPU en el emulador PDC suelen estar más solicitados que en cualquier otra parte de la implementación porque varias herramientas y acciones se dirigen a él, como las herramientas de gestión de directivas de grupo, los segundos intentos de autenticación, el establecimiento de confianza, etc.
- Deberías ajustar tu emulador PDC solo si hay una diferencia notable en la utilización de la CPU. El ajuste debería reducir la carga en el emulador PDC y aumentar la carga en otros controladores de dominio, permitiendo una distribución más uniforme de la carga.
- En estos casos, configura el valor de
LDAPSrvWeightentre 50 y 75 para el emulador PDC.
| Sistema | Utilización de la CPU con valores predeterminados | Nuevo LdapSrvWeight | Nueva utilización estimada de la CPU |
|---|---|---|---|
| DC 1 (emulador de PDC) | 53 % | 57 | 40 % |
| DC 2 | 33 % | 100 | 40 % |
| DC 3 | 33 % | 100 | 40 % |
El problema es que si el rol de emulador PDC se transfiere o se toma, particularmente a otro controlador de dominio en el sitio, entonces la utilización de CPU aumenta dramáticamente en el nuevo emulador PDC.
En esta situación de ejemplo, asumimos basándonos en Perfil de comportamiento del sitio objetivo que los tres controladores de dominio de este sitio tienen cuatro CPU. En condiciones normales, ¿qué pasaría si uno de estos controladores de dominio tuviera ocho CPU? Habría dos controladores de dominio al 40 % de utilización y uno al 20 %. Aunque esta configuración no es necesariamente mala, existe la oportunidad de utilizar el ajuste de peso LDAP para equilibrar mejor la carga.
Ejemplo 2: entorno con diferentes recuentos de CPU
Cuando tienes servidores con diferentes CPU y velocidades en el mismo sitio, necesitas asegurarte de que están distribuidos uniformemente. Por ejemplo, si tu sitio tiene dos servidores de ocho núcleos y uno de cuatro, el de cuatro solo tiene la mitad de potencia de procesamiento que los otros dos. Si la carga de clientes se distribuye uniformemente, esto significa que el servidor de cuatro núcleos necesita trabajar el doble que los dos servidores de ocho núcleos para gestionar su carga de CPU. Además, si uno de los servidores de ocho núcleos se desconecta, el servidor de cuatro núcleos se sobrecarga.
| Sistema | Información del Procesador\ Utilidad del Procesador %(_Total) Utilización de la CPU con valores predeterminados |
Nuevo LdapSrvWeight | Nueva utilización estimada de la CPU |
|---|---|---|---|
| DC 1 de 4-CPU | 40 | 100 | 30 % |
| DC 2 de 4-CPU | 40 | 100 | 30 % |
| DC 3 de 8-CPU | 20 | 200 | 30 % |
Planear para una “N + 1” situación es de suma importancia. Se debe calcular para cada escenario el impacto de un controlador de dominio que se queda sin conexión. En la situación inmediatamente anterior, en el que la distribución de la carga es uniforme, para garantizar una carga del 60 % durante una “N” situación, con la carga equilibrada uniformemente en todos los servidores, la distribución está bien ya que los ratios se mantienen consistentes. Si nos fijamos en el escenario de ajuste del emulador PDC, o en cualquier escenario general en el que la carga de usuarios o aplicaciones esté desequilibrada, el efecto es muy diferente:
| Sistema | Uso optimizado | Nuevo LdapSrvWeight | Nuevo uso estimado |
|---|---|---|---|
| DC 1 (emulador de PDC) | 40 % | 85 | 47 % |
| DC 2 | 40 % | 100 | 53 % |
| DC 3 | 40 % | 100 | 53 % |
Consideraciones de virtualización para el procesamiento
A la hora de planificar la capacidad de un entorno virtualizado, hay que tener en cuenta dos niveles: el de host y el de invitado. A nivel de host, debes identificar los periodos pico de tu ciclo comercial. Dado que programar hilos de invitado en la CPU para una máquina virtual es similar a conseguir hilos AD DS en la CPU para una máquina física, seguimos recomendándote que utilices entre el 40 % y el 60 % del host subyacente. A nivel de invitado, dado que los principios subyacentes de programación de subprocesos no han cambiado, también recomendamos mantener el uso de la CPU entre el 40 % y el 60 %.
En un escenario de asignación directa con un invitado por anfitrión, deberás aportar todas las estimaciones de planeamiento de capacidad que hayas realizado en los apartados anteriores para realizar tu estimación. Para un escenario de host compartido, hay alrededor de un 10 % de impacto en la eficiencia de los procesadores subyacentes, lo que significa que si un sitio necesita 10 CPU a un objetivo del 40 %, el número recomendado de CPU virtuales que debes asignar a través de todos N invitados serían 11. En sitios con distribuciones mixtas de servidores físicos y virtuales, este modificador solo se aplica a las máquinas virtuales (VM). Por ejemplo, en un N + 1 escenario, un servidor físico o de asignación directa con 10 CPU es casi igual a un invitado con 11 CPU en un host con 11 CPU más reservadas para el controlador de dominio.
Mientras analizas y calculas cuántas CPU necesitas para soportar la carga de AD DS, ten en cuenta que si tienes previsto comprar hardware físico, es posible que los tipos de hardware disponibles en el mercado no se ajusten exactamente a tus estimaciones. Sin embargo, no tienes ese problema cuando utilizas virtualización. El uso de máquinas virtuales reduce el esfuerzo necesario para añadir capacidad de proceso a un sitio, ya que puedes añadir tantas CPU con las especificaciones exactas que desees a una máquina virtual. Sin embargo, la virtualización no elimina tu responsabilidad de evaluar con precisión cuánta potencia de proceso necesitas para garantizar que tu hardware subyacente esté disponible cuando los invitados necesiten más CPU. Como siempre, recuerda planear el crecimiento con antelación.
Ejemplo de resumen de cálculo de virtualización
| Sistema | CPU máxima |
|---|---|
| DC 1 | 120 % |
| DC 2 | 147 % |
| DC 3 | 218 % |
| Uso total de CPU | 485 % |
| Número de sistemas objetivo | Ancho de banda total (según aparece anteriormente) |
|---|---|
| CPU necesarias en el objetivo del 40 % | 4,85 ÷ 4 = 12,25 |
Al planear con antelación el crecimiento en este escenario, si supones que la demanda crecerá un 50 % en los próximos tres años, debes asegurarte de que dispones de 18,375 CPU (12,25 × 1,5) para ese momento. Otra posibilidad es revisar la demanda después del primer año y añadir capacidad adicional en función de los resultados.
Carga de la autenticación de cliente de confianza cruzada para NTLM
Evaluación de la carga de la autenticación de cliente de confianza cruzada
Muchos entornos pueden tener uno o varios dominios conectados por una confianza. Las solicitudes de autenticación de identidades en otros dominios que no utilizan Kerberos deben atravesar una confianza utilizando un canal seguro entre dos controladores de dominio. El controlador de dominio al que el usuario intenta acceder en el sitio se conecta a otro controlador de dominio que se encuentra en el dominio de destino o en algún lugar más arriba en la ruta hacia el dominio de destino. El número de llamadas que el controlador de dominio puede realizar a los demás controladores de domino en el dominio de confianza está controlado por el *MaxConcurrentAPI ajuste. Para garantizar que el canal seguro puede gestionar la cantidad de carga necesaria para que los controladores de dominio se comuniquen entre sí, puedes ajustar MaxConcurrentAPI o, si te encuentras en un bosque, crear relaciones de confianza de acceso directo. Más información sobre cómo determinar el volumen de tráfico a través de las relaciones de confianza en Cómo realizar ajustes de rendimiento para la autenticación NTLM utilizando el ajuste MaxConcurrentApi.
Al igual que en los escenarios anteriores, para que los datos sean útiles deben recopilarse durante los periodos de mayor actividad del día.
Nota:
Los escenarios intraforestales e interforestales pueden hacer que la autenticación atraviese múltiples relaciones de confianza, lo que significa que es necesario realizar ajustes durante cada etapa del proceso.
Planeación de virtualización
Hay algunas cosas que debes tener en cuenta al planear la capacidad de virtualización:
- Muchas aplicaciones utilizan la autenticación Network Level Trust Manager (NTLM) por defecto o en determinadas configuraciones.
- A medida que aumenta el número de clientes activos, también lo hace la necesidad de que los servidores de aplicaciones tengan más capacidad.
- A veces, los clientes mantienen las sesiones abiertas durante un tiempo limitado y, en cambio, vuelven a conectarse periódicamente para servicios como la sincronización pull de correo electrónico.
- Los servidores proxy web que requieren autenticación para acceder a Internet pueden provocar una carga elevada de NTLM.
Estas aplicaciones pueden crear una gran carga para la autenticación NTLM, lo que supone un estrés significativo para los controladores de dominio, especialmente cuando los usuarios y los recursos se encuentran en diferentes dominios.
Hay muchos enfoques que puede adoptar para gestionar la carga de relaciones de confianza cruzada, que a menudo puede y debe utilizar juntos al mismo tiempo:
- Reducir la autenticación de relaciones de confianza cruzada localizando los servicios que un usuario consume en el dominio en el que se encuentra.
- Aumentar el número de canales seguros disponibles. Estos canales se denominan relaciones de confianza de acceso directo y son relevantes para el tráfico intraforestal y transforestal.
- Optimice la configuración predeterminada de MaxConcurrentAPI.
Para ajustar MaxConcurrentAPI en un servidor existente, utiliza la siguiente ecuación:
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + semaphore_time outs) × average_semaphore_hold_time ÷ time_collection_length
Para obtener más información, consulte el artículo de KB 2688798: Cómo realizar el ajuste del rendimiento para la autenticación NTLM mediante la configuración MaxConcurrentApi.
Consideraciones de virtualización
No hay consideraciones especiales que debas tener en cuenta, ya que la virtualización es una configuración de ajuste del sistema operativo.
Ejemplo de cálculo de ajuste de virtualización
| Tipo de datos | Valor |
|---|---|
| Adquisiciones de semáforo (mínimo) | 6161 |
| Adquisiciones de semáforo (máximo) | 6762 |
| Tiempos de espera del semáforo | 0 |
| Promedio de tiempo de retención del semáforo | 0,012 |
| Duración de la recopilación (segundos) | 1:11 minutos (71 segundos) |
| Fórmula (según KB 2688798) | ((6762 - 6161) + 0) × 0,012 / |
| Valor mínimo de MaxConcurrentAPI | ((6762 - 6161) + 0) × 0,012 ÷ 71 = ,101 |
Para este sistema durante este período de tiempo, los valores predeterminados son aceptables.
Supervisión del cumplimiento de los objetivos de planeamiento de capacidad
A lo largo de este artículo, hemos hablado de cómo el planeamiento y el escalado contribuyen a los objetivos de utilización. La siguiente tabla resume los umbrales recomendados que debe supervisar para garantizar que los sistemas funcionan según lo previsto. Ten en cuenta que no se trata de umbrales de rendimiento, sino de umbrales de planeamiento de capacidad. Un servidor que funcione por encima de estos umbrales seguirá funcionando, pero es necesario validar que las aplicaciones funcionan según lo previsto antes de empezar a ver problemas de rendimiento a medida que aumenta la demanda de los usuarios. Si las aplicaciones están bien, entonces deberías empezar a evaluar actualizaciones de hardware u otros cambios de configuración.
| Categoría | Contador de rendimiento | Intervalo/muestreo | Destino | Advertencia |
|---|---|---|---|---|
| Procesador | Processor Information(_Total)\% Processor Utility |
60 minutos | 40 % | 60 % |
| RAM (Windows Server 2008 R2 o versiones anteriores) | Memoria\MB disponible | < 100 MB | N/D | < 100 MB |
| RAM (Windows Server 2012) | Memoria\Vida útil promedio de la caché en espera a largo plazo | 30 minutos | Se debe probar | Se debe probar |
| Red | Interfaz de red(*)\Bytes enviados por segundo Interfaz de red(*)\Bytes recibidos por segundo |
30 minutos | 40 % | 60 % |
| Almacenamiento | LogicalDisk((<NTDS Database Drive>))\Lecturas promedio de disco/segLogicalDisk(( |
60 minutos | 10 ms | 15 ms |
| Servicios de AD | Netlogon(*)\Promedio de tiempo de suspensión del semáforo | 60 minutos | 0 | 1 segundo |
Apéndice A: Criterios de dimensionamiento de CPU
Este apéndice analiza términos y conceptos útiles que pueden ayudarte a estimar las necesidades de dimensionamiento de CPU de tu entorno.
Definiciones: Dimensionamiento de CPU
Un procesador (microprocesador) es un componente que lee y ejecuta instrucciones de programas.
Un procesador multinúcleo tiene varias CPU en el mismo circuito integrado.
Un CPU múltiple es un sistema que tiene múltiples CPU que no están en el mismo circuito integrado.
Un procesador lógico es un procesador que solo tiene un motor lógico de computación desde la perspectiva del sistema operativo.
Estas definiciones incluyen hyper-threaded, un núcleo en procesador multinúcleo, o un procesador de un solo núcleo.
Dado que los sistemas de servidor actuales tienen múltiples procesadores, múltiples procesadores multinúcleo e hyper-threading, estas definiciones son generalizadas para cubrir ambos escenarios. Utilizamos el término procesador lógico porque representa la perspectiva del sistema operativo y la aplicación de los motores informáticos disponibles.
Paralelismo de nivel de subproceso
Cada subproceso es una tarea independiente, ya que cada subproceso tiene su propia pila e instrucciones. AD DS es multi-threaded y puede ajustar el número de hilos disponibles siguiendo las instrucciones de Cómo ver y establecer la política LDAP en Active Directory utilizando Ntdsutil. exe, se escala bien a través de múltiples procesadores lógicos.
Paralelismo de nivel de datos
El paralelismo a nivel de datos se produce cuando un servicio comparte datos entre muchos subprocesos para el mismo proceso y comparte muchos subprocesos entre varios procesos. El proceso AD DS por sí solo contaría como un servicio que comparte datos a través de varios hilos para un único proceso. Cualquier cambio en los datos se refleja en todos los subprocesos en ejecución en todos los niveles de la caché, en cada núcleo y en cualquier actualización de la memoria compartida. El rendimiento puede disminuir durante las operaciones de escritura porque todas las posiciones de memoria se ajustan a los cambios antes de que pueda continuar el procesamiento de instrucciones.
Velocidad de la CPU frente a consideraciones sobre múltiples núcleos
En general, los procesadores lógicos más rápidos reducen el tiempo necesario para procesar una serie de instrucciones. Más procesadores lógicos significa que puedes ejecutar más tareas al mismo tiempo. Sin embargo, estas reglas no se aplican a los escenarios más complejos, como la obtención de datos de la memoria compartida, esperando en el paralelismo a nivel de datos, y la sobrecarga de la gestión múltiples hilos a la vez. En consecuencia, la escalabilidad de los sistemas multinúcleo no es lineal.
Para entender por qué se produce este cambio, es útil pensar estos escenarios como una autopista. Cada hilo es un coche individual, cada carril es un núcleo y el límite de velocidad es la velocidad del reloj.
Si solo hay un coche en la autopista, da igual que haya dos o 12 carriles. Ese coche solo va tan rápido como lo permite el límite de velocidad.
Si los datos que necesita el hilo no están disponibles inmediatamente, el hilo no puede procesar instrucciones hasta que obtenga los datos relevantes de la memoria. Es como si se cerrara un tramo de la autopista. Aunque solo haya un coche en la autopista, el límite de velocidad no afectará a su capacidad de viajar, porque no puede ir a ninguna parte hasta que la carretera vuelva a funcionar.
A medida que aumenta el número de coches, también aumenta la sobrecarga que necesita la autopista para administrar el número de coches. Los conductores deben concentrarse más cuando circulan por la autopista en hora punta que cuando lo hacen a última hora de la tarde, cuando la carretera está casi vacía. Además, conducir por una autopista de dos carriles en la que solo tienes que preocuparte de otro carril requiere menos concentración que conducir por una autopista de seis carriles en la que tienes que prestar atención a otros cinco carriles de tráfico.
En resumen, las cuestiones sobre si debe añadir más procesadores o más rápidos son muy subjetivas y deben considerarse caso por caso. En el caso concreto de AD DS, sus necesidades de procesamiento dependen de factores ambientales y pueden variar de un servidor a otro dentro de un mismo entorno. Como resultado, en las secciones anteriores de este artículo no se ha insistido mucho en hacer cálculos demasiado precisos. Cuando tomes decisiones de compra basadas en tu presupuesto, te recomendamos que primero optimices el uso del procesador al 40 % o a la cifra que requiera tu entorno específico. Si tu sistema no está optimizado, no te beneficiarás tanto de la compra de procesadores adicionales.
Nota:
La ley de Amdahl y la ley de Gustafson son conceptos relevantes en este caso.
Tiempo de respuesta y cómo influyen los niveles de actividad del sistema en el rendimiento
La teoría de colas es el estudio matemático de las líneas de espera, o colas. En la teoría de colas dentro de la informática, la ley de utilización se representa mediante la ecuación t:
U k = B ÷ T
Donde U k es el porcentaje de utilización, B es la cantidad de tiempo en que hay actividad, y T es el tiempo total usado en observar el sistema. En el contexto de Microsoft, esto significa el número de subprocesos de intervalos de 100 nanosegundos (ns) que se encuentran en estado de Ejecución dividido por cuántos intervalos de 100 ns estaban disponibles en el intervalo de tiempo dado. Esta es la misma fórmula que calcula el porcentaje de utilización del procesador que se muestra en Objeto de procesador y PERF_100NSEC_TIMER_INV.
La teoría de colas también proporciona la fórmula: N = U k ÷ (1 - U k) para estimar el número de ítems en espera basándose en la utilización, donde N es la longitud de la cola. Si se representa gráficamente esta ecuación en todos los intervalos de utilización, se obtienen las siguientes estimaciones de la longitud de la cola para acceder al procesador en cualquier carga dada de la CPU.
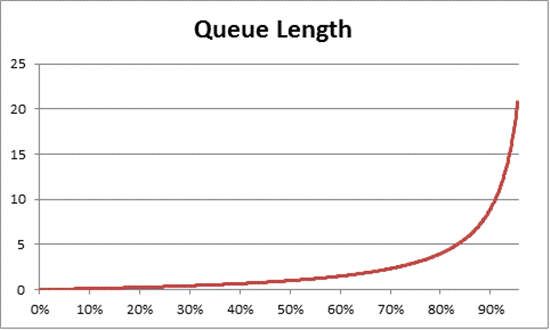
Basándonos en esta estimación, podemos observar que después de un 50 % de carga de la CPU, la espera media suele incluir otro elemento en la cola, y aumenta rápidamente hasta un 70 % de utilización de la CPU.
Para entender cómo se aplica la teoría de las colas a su despliegue de AD DS, volvamos a la metáfora de la autopista que utilizamos en Velocidad de la CPU frente a las consideraciones sobre múltiples núcleos.
Las horas de mayor afluencia, a media tarde, se situarían entre el 40 % y el 70 % de la capacidad. Hay suficiente tráfico como para que tu capacidad de elegir un carril por el que circular no esté gravemente restringida. Aunque la posibilidad de que otro conductor se interponga en tu camino es alta, no requiere el mismo nivel de esfuerzo que necesitarías para encontrar un hueco seguro entre otros coches en el carril que durante la hora pico.
A medida que se acerca la hora pico, la red viaria se aproxima al 100 % de su capacidad. Cambiar de carril en hora punta se convierte en todo un reto porque los coches están tan juntos que no hay tanto espacio para maniobrar al cambiar de carril.
Por eso, estimar las medias de capacidad a largo plazo en un 40 % deja más margen para picos de carga anormales, ya sean transitorios, como las consultas mal programadas que tardan en ejecutarse, o ráfagas anormales de carga general, como el pico de actividad a la mañana siguiente de un fin de semana festivo.
La afirmación anterior considera que el cálculo del porcentaje de tiempo de procesador es el mismo que la ecuación de la ley de utilización. Esta versión simplificada pretende introducir el concepto a los nuevos usuarios. Sin embargo, para cálculos más avanzados, puedes utilizar las siguientes referencias como guía:
- Traducción de PERF_100NSEC_TIMER_INV
- B = El número de intervalos de 100 ns que el hilo inactivo pasa en el procesador lógico.. El cambio en la variable X en el PERF_100NSEC_TIMER_INV cálculo
- T = número total de intervalos de 100 ns en un intervalo de tiempo determinado. El cambio en la variable Y en el PERF_100NSEC_TIMER_INV cálculo.
- U k = Porcentaje de utilización del procesador lógico por el subproceso inactivo o % de tiempo inactivo.
- Trabajando con las matemáticas:
- U k = 1 – porcentaje de tiempo de procesador
- Porcentaje de tiempo de procesador = 1 – U k
- Porcentaje de tiempo de procesador = 1 – B / T
- Porcentaje de tiempo de procesador = 1 – X1 – X0 / Y1 – Y0
Aplicación de estos conceptos al planeamiento de capacidad
Los cálculos de la sección anterior probablemente hacen que determinar cuántos procesadores lógicos necesitas en un sistema parezca muy complejo. Como resultado, tu enfoque para hacer el dimensionamiento del sistema debe centrarse en determinar la utilización máxima objetivo basada en la carga actual y, a continuación, calcular el número de procesadores lógicos que necesitas para alcanzar ese objetivo. Además, tu estimación no tiene por qué ser perfectamente exacta. Aunque la velocidad de los procesadores lógicos tiene un impacto significativo en la sincronización, el rendimiento también puede verse afectado por otras áreas:
- Eficiencia de la caché
- Requisitos de coherencia de la memoria
- Programación y sincronización de subprocesos
- Cargas de clientes imperfectamente equilibradas
Como la potencia de proceso es relativamente barata, no vale la pena invertir demasiado tiempo en calcular el número exacto de CPU que necesitas.
También es importante recordar que la recomendación del 40 %, en este caso, no es un requisito obligatorio. Lo utilizamos como punto de partida razonable para hacer cálculos. Los distintos tipos de usuarios de AD necesitan diferentes niveles de capacidad de respuesta. Incluso puede haber escenarios en los que los entornos pueden funcionar al 80 % o incluso al 90 % de utilización en una media sostenida sin que el aumento de los tiempos de espera para acceder al procesador afecte notablemente al rendimiento del cliente.
También hay otras áreas en el sistema que son mucho más lentas que el procesador lógico y que también deberías ajustar, incluyendo el acceso a la RAM, el acceso al disco y la transmisión de respuestas a través de la red. Por ejemplo:
Si añades procesadores a un sistema que funciona al 90 % de utilización y que está ligado al disco, probablemente el rendimiento no mejorará significativamente. Si observas el sistema con más detenimiento, verás que hay muchos hilos que ni siquiera llegan al procesador porque están esperando a que se completen las operaciones de E/S.
Resolver los problemas de ligación de disco puede significar que los hilos que antes estaban atascados en estado de espera dejen de estarlo, creando más competencia por el tiempo de CPU. Como resultado, la utilización del 90 % pasará al 100 %. Es necesario ajustar ambos componentes para que la utilización vuelva a niveles manejables.
Nota:
El contador
Processor Information(*)\% Processor Utilitypuede superar el 100 % con sistemas que tengan un modo Turbo. El modo Turbo le permite a la CPU superar la velocidad nominal del procesador durante periodos breves. Si necesitas más información, consulta la documentación y las descripciones de los contadores de los fabricantes de CPU.
Las consideraciones sobre la utilización de todo el sistema también afectan a los controladores de dominio como invitados virtualizados. Tiempo de respuesta y cómo los niveles de actividad del sistema impactan en el rendimiento se aplica tanto al host como al invitado en un escenario virtualizado. En un host con un solo invitado, un controlador de dominio o sistema tiene casi el mismo rendimiento que tendría en hardware físico. Añadir más invitados a los hosts aumenta la utilización del host subyacente, incrementando también los tiempos de espera para acceder a los procesadores. Por lo tanto, debes gestionar la utilización del procesador lógico tanto a nivel de host como de invitado.
Volvamos a la metáfora de la autopista de las secciones anteriores, solo que esta vez imaginaremos la máquina virtual invitada como un autobús expreso. Los autobuses expresos, a diferencia del transporte público o los autobuses escolares, van directamente al destino del viajero sin hacer paradas.
Ahora imaginemos cuatro escenarios:
- Las horas valle de un sistema son como viajar en un autobús expreso a altas horas de la noche. Cuando el viajero sube, casi no hay otros pasajeros y la carretera está casi vacía. Como el autobús no tiene tráfico, el trayecto es fácil y tan rápido como si el viajero hubiera llegado en su propio coche. Sin embargo, el tiempo de viaje del viajero también está limitado por el límite de velocidad local.
- Las horas valle, cuando la utilización de la CPU de un sistema es demasiado alta, son como un viaje nocturno en el que la mayoría de los carriles de la autopista están cerrados. Aunque el autobús está casi vacío, la carretera sigue congestionada por el tráfico sobrante que circula por los carriles restringidos. Mientras el viajero es libre de sentarse donde quiera, la duración real del viaje viene determinada por el tráfico fuera del autobús.
- Un sistema con una elevada utilización de la CPU durante las horas pico es como un autobús lleno en hora pico. No solo el viaje dura más, sino que subir y bajar del autobús es más difícil porque el autobús está lleno de otros pasajeros. Añadir más procesadores lógicos al sistema de invitados para intentar acelerar los tiempos de espera sería como intentar resolver el problema del tráfico añadiendo más autobuses. El problema no es el número de autobuses, sino la duración del trayecto.
- Un sistema con una elevada utilización de la CPU fuera de las horas pico es como ese mismo autobús abarrotado en una carretera casi vacía por la noche. Aunque los viajeros pueden tener problemas para encontrar asiento o subir y bajar del autobús, el viaje es bastante tranquilo una vez que el autobús recoge a todos sus pasajeros. Este escenario es el único en el que el rendimiento mejoraría añadiendo más autobuses.
Basándose en los ejemplos anteriores, puedes ver que hay muchos escenarios entre el 0 % y el 100 % de utilización que tienen diferentes grados de impacto en el rendimiento. Además, añadir más procesadores lógicos no mejora necesariamente el rendimiento fuera de escenarios muy específicos. Debería ser bastante sencillo aplicar estos principios al objetivo recomendado del 40 % de utilización de la CPU para hosts e invitados.
Apéndice B: Consideraciones relativas a las distintas velocidades del procesador
En Procesamiento, asumimos que el procesador está funcionando al 100 % de la velocidad del reloj mientras recopila datos, y que cualquier sistema de sustitución tiene la misma velocidad de procesamiento. A pesar de que estas suposiciones no son exactas, especialmente para Windows Server 2008 R2 y posteriores, donde el plan de energía predeterminado es Equilibrado, estas suposiciones aún funcionan para estimaciones conservadoras. Aunque los errores potenciales pueden aumentar, solo aumenta el margen de seguridad a medida que aumenta la velocidad de los procesadores.
- Por ejemplo, en un escenario que demanda 11,25 CPU, si los procesadores funcionaban a media velocidad cuando recogiste los datos, la estimación más precisa de su demanda sería 5,125 ÷ 2.
- Es imposible garantizar que al duplicar la velocidad de reloj se duplique la cantidad de procesamiento que tiene lugar en el periodo de tiempo registrado. La cantidad de tiempo que los procesadores pasan esperando la RAM u otros componentes se mantiene más o menos igual. Por lo tanto, los procesadores más rápidos pueden pasar un mayor porcentaje de tiempo inactivos mientras esperan a que el sistema recupere los datos. Te recomendamos que te quedes con el mínimo común denominador, mantengas tus estimaciones conservadoras y evites asumir una comparación lineal entre las velocidades de los procesadores que podría hacer que tus resultados fueran inexactos.
Si la velocidad de los procesadores del hardware de sustitución es inferior a la del hardware actual, deberás aumentar proporcionalmente la estimación del número de procesadores que necesitas. Por ejemplo, veamos un escenario en el que calculas que necesitas 10 procesadores para sostener la carga de tu sitio. Los procesadores actuales funcionan a 3,3 GHz, y los procesadores por los que piensas sustituirlos funcionan a 2,6 GHz. Sustituir solo los 10 procesadores originales supondría una disminución de la velocidad del 21 %. Para aumentar la velocidad, necesitas conseguir al menos 12 procesadores en lugar de 10.
Sin embargo, esta variabilidad no cambia los objetivos de utilización del procesador de administración de capacidad. Las velocidades de reloj de los procesadores se ajustan dinámicamente en función de la demanda de carga, por lo que el funcionamiento del sistema bajo cargas más altas hace que la CPU pase más tiempo en un estado de velocidad de reloj más alta. El objetivo final es que la CPU esté al 40 % de utilización en un estado de velocidad de reloj del 100 % durante las horas pico. Todo lo que no sea esto generará un ahorro de energía al reducir la velocidad de la CPU durante las horas valle.
Nota:
Puedes desactivar la gestión de energía en los procesadores durante la recopilación de datos estableciendo el plan de energía en Alto Rendimiento. Si desactivas la administración de energía, obtendrás lecturas más precisas del consumo de CPU en el servidor de destino.
Para ajustar las estimaciones a los distintos procesadores, te recomendamos que utilices el índice de referencia SPECint_rate2006 de Standard Performance Evaluation Corporation. Para utilizar este punto de referencia:
Ve al Sitio web de la Standard Performance Evaluation Corporation (SPEC).
Seleccione Resultados.
Entra a CPU2006 y selecciona Buscar.
En el menú desplegable de Configuraciones disponibles, selecciona Todos los SPEC CPU2006.
En el campo Solicitud de formulario de búsqueda, selecciona Simple, luego selecciona ¡Ir!.
Bajo Solicitud simple, introduce los criterios de búsqueda para tu procesador de destino. Por ejemplo, si buscas un procesador ES-2630, en el menú desplegable, selecciona Procesador, luego introduce el nombre del procesador en el campo de búsqueda. Cuando termines, selecciona Ejecutar búsqueda simple.
Busca la configuración de tu servidor y procesador en los resultados de la búsqueda. Si el motor de búsqueda no devuelve una coincidencia exacta, busca la más parecida posible.
Registra los valores en las columnas Resultado y N.° de Núcleos.
Determina el modificador utilizando esta ecuación:
((Valor de la puntuación por cada núcleo de la plataforma objetivo) × (MHz por núcleo de la plataforma de línea base)) ÷ ((valor de la puntuación por cada núcleo de la línea base) × (MHz por núcleo de la plataforma objetivo))
Por ejemplo, así es como encontrarías el modificador para un procesador ES-2630:
(35,83 × 2000) ÷ (33,75 × 2300) = 0,92
Multiplica el número de procesadores que calculas que necesitas en este modificador.
Para el ejemplo del procesador ES-2630, 0,92 × 10,3 = 10,35 procesadores.
Apéndice C: Cómo interactúa el sistema operativo con el almacenamiento
Los conceptos de la teoría de colas que discutimos en Tiempo de respuesta y cómo los niveles de actividad del sistema impactan en el rendimiento también se aplican al almacenamiento. Para poder aplicar estos conceptos de forma eficaz, es necesario estar familiarizado con la forma en que tu sistema operativo maneja la E/S. En los sistemas operativos Windows, el sistema operativo crea una cola que contiene las solicitudes de E/S para cada disco físico. Sin embargo, un disco físico no es necesariamente un disco único. El sistema operativo también puede registrar una agregación de cabezales en un controlador de matrices o SAN como un disco físico. Los controladores de matrices y los SAN también pueden agregar varios discos en un único conjunto de matrices, dividirlo en varias particiones y, a continuación, utilizar cada partición como un disco físico, como se muestra en la siguiente imagen
En esta ilustración, los dos cabezales se reflejan y se dividen en áreas lógicas para el almacenamiento de datos, etiquetadas como Datos 1 y Datos 2. El sistema operativo registra cada una de estas áreas lógicas como discos físicos independientes.
Ahora que hemos aclarado lo que define un disco físico, también deberías familiarizarte con los siguientes términos para ayudarte a entender mejor la información de este Apéndice.
- Un cabezal es el dispositivo instalado físicamente en el servidor.
- Una matriz es una colección de cabezales agregados por el controlador.
- Una partición de matriz es una partición de la matriz agregada.
- Una Logical Unit Number (LUN) es una matriz de dispositivos SCSI conectados a una computadora. En este artículo se utilizan estos términos cuando se habla de SAN.
- Un disco incluye cualquier cabezal o partición que el sistema operativo registre como un único disco físico.
- Una partición es una partición lógica de lo que el sistema operativo registra como disco físico.
Consideraciones sobre la arquitectura del sistema operativo
El sistema operativo crea una cola de E/S FIFO (First In, First Out) para cada disco que registra. Estos discos pueden ser cabezales, matrices o particiones de matrices. Cuando se trata de cómo el sistema operativo gestiona la E/S, cuantas más colas activas, mejor. Cuando el sistema operativo serializa la cola FIFO, debe procesar todas las peticiones de E/S FIFO emitidas al subsistema de almacenamiento por orden de llegada. Cuando el sistema operativo correlaciona cada disco con un cabezal o matriz, mantiene una cola de E/S para cada conjunto único de discos, eliminando la competencia por los escasos recursos de E/S entre discos y aislando la demanda de E/S a un único disco. Sin embargo, Windows Server 2008 introdujo una excepción en forma de Priorización de E/S. Las aplicaciones diseñadas para utilizar E/S de prioridad baja se mueven al final de la cola sin importar cuándo las haya recibido el sistema operativo. Las aplicaciones no programadas específicamente para utilizar el ajuste de prioridad baja tienen por defecto la prioridad normal.
Introducción a los subsistemas de almacenamiento simples
En esta sección hablaremos de subsistemas de almacenamiento sencillos. Empecemos con un ejemplo: un único disco duro dentro de una computadora. Si desglosamos este sistema en sus principales componentes del subsistema de almacenamiento, esto es lo que obtenemos:
- Un disco duro Ultra Fast SCSI de 10.000 RPM (Ultra Fast SCSI tiene una velocidad de transferencia de 20 MBps)
- Un bus SCSI (el cable)
- Un adaptador Ultra Fast SCSI
- Un bus PCI de 32 bits y 33 MHz
Nota:
Este ejemplo no refleja la caché de disco, donde el sistema suele guardar los datos de un cilindro. En este caso, la primera E/S necesita 10 ms y el disco lee todo el cilindro. Todas las demás E/S secuenciales son satisfechas por la caché. Como resultado, las memorias caché en disco pueden mejorar el rendimiento de la E/S secuencial.
Una vez identificados los componentes, puedes empezar a hacerte una idea de cuántos datos puede transmitir el sistema y cuántas E/S puede manejar. La cantidad de E/S y la cantidad de datos que pueden transitar por el sistema están relacionadas entre sí, pero no tienen el mismo valor. Esta correlación depende del tamaño del bloque y de si la E/S del disco es aleatoria o secuencial. El sistema escribe todos los datos en el disco como un bloque, pero las distintas aplicaciones pueden utilizar tamaños de bloque diferentes.
A continuación, analicemos estos elementos componente por componente.
Tiempos de acceso al disco duro
El disco duro medio de 10.000 rpm tiene un tiempo de búsqueda de 7 ms y un tiempo de acceso de 3 ms. El tiempo de búsqueda es el tiempo medio que tarda el cabezal de lectura o escritura en desplazarse a una posición del plato. El tiempo de acceso es el tiempo medio que tarda el cabezal en leer o escribir los datos en el disco una vez que están en la ubicación correcta. Por lo tanto, el tiempo medio de lectura de un único bloque de datos en un disco duro de 10.000 rpm incluye tanto el tiempo de búsqueda como el de acceso para un total de aproximadamente 10 ms, o 0,010 segundos, por bloque de datos.
Cuando cada acceso al disco requiere que el cabezal se mueva a una nueva ubicación en el disco, el comportamiento de lectura o escritura se denomina aleatorio. Cuando toda la E/S es aleatoria, un disco duro de 10.000 rpm puede manejar aproximadamente 100 E/S por segundo (IOPS).
Cuando toda la E/S se produce desde sectores adyacentes en el disco duro, lo llamamos E/S secuencial. La E/S secuencial no tiene tiempo de búsqueda porque, una vez finalizada la primera E/S, el cabezal de lectura o escritura se encuentra al principio de donde el disco duro almacena el siguiente bloque de datos. Por ejemplo, un disco duro de 10.000 rpm es capaz de gestionar aproximadamente 333 E/S por segundo, según la siguiente ecuación:
1000 ms por segundo ÷ 3 ms por E/S
Hasta ahora, la velocidad de transferencia del disco duro no ha sido relevante para nuestro ejemplo. Independientemente del tamaño del disco duro, la cantidad real de IOPS que puede manejar un disco duro de 10.000 rpm es siempre de unas 100 E/S aleatorias o 300 secuenciales. Como el tamaño de los bloques cambia en función de la aplicación que escribe en la unidad, la cantidad de datos extraídos por E/S también cambia. Por ejemplo, si el tamaño del bloque es de 8 KB, 100 operaciones de E/S leerán o escribirán en el disco duro un total de 800 KB. Sin embargo, si el tamaño del bloque es de 32 KB, 100 E/S leerán o escribirán 3.200 KB (3,2 MB) en el disco duro. Si la velocidad de transferencia SCSI supera la cantidad total de datos transferidos, conseguir una velocidad de transferencia más rápida no cambia nada. Para más información, consulta las tablas siguientes:
| Descripción | 7200 rpm 9 ms de búsqueda, 4 ms de acceso | 10.000 rpm 7 ms de búsqueda, 3 ms de acceso | 15.000 rpm 4 ms de búsqueda, 2 ms de acceso |
|---|---|---|---|
| E/S aleatoria | 80 | 100 | 150 |
| E/S secuencial | 250 | 300 | 500 |
| Unidad de 10 000 RPM | Tamaño de bloque de 8 KB (Jet de Active Directory) |
|---|---|
| E/S aleatoria | 800 KB/s |
| E/S secuencial | 2400 KB/s |
La placa base SCSI
El impacto de la placa base SCSI, que en este ejemplo es el cable plano, en el rendimiento del subsistema de almacenamiento depende del tamaño de los bloques. ¿Cuánta E/S puede manejar el bus si la E/S está en bloques de 8 KB? En este escenario, el bus SCSI es de 20 MBps, o 20480 KB/s. 20480 KB/s divididos por bloques de 8 KB produce un máximo de aproximadamente 2500 IOPS admitidas por el bus SCSI.
Nota:
Las cifras del cuadro siguiente representan un escenario de ejemplo. La mayoría de los dispositivos de almacenamiento conectados actualmente usan PCI Express, que proporciona un rendimiento mucho mayor.
| Operaciones de E/S admitidas por el bus SCSI por tamaño de bloque | Tamaño de bloque de 2 KB | Tamaño de bloque de 8 KB (Jet de AD) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20 MBps | 10 000 | 2,500 |
| 40 MBps | 20.000 | 5\.000 |
| 128 MBps | 65 536 | 16 384 |
| 320 MBps | 160 000 | 40 000 |
Como muestra la tabla anterior, en nuestro escenario de ejemplo, el bus nunca es un cuello de botella porque el máximo del cabezal es de 100 E/S, muy por debajo de cualquiera de los umbrales enumerados.
Nota:
En este escenario, estamos asumiendo que el bus SCSI es 100 % eficiente.
El adaptador SCSI
Para determinar cuántas E/S puede manejar el sistema, debes consultar las especificaciones del fabricante. Dirigir las peticiones de E/S al dispositivo apropiado requiere potencia de procesamiento, por lo que la cantidad de E/S que el sistema puede manejar depende del adaptador SCSI o del procesador del controlador de matriz.
En este ejemplo, suponemos que el sistema puede gestionar 1.000 E/S.
Bus PCI
El bus PCI es un componente que a menudo se pasa por alto. En este ejemplo, el bus PCI no es el cuello de botella. Sin embargo, a medida que los sistemas se amplían, puede convertirse en un cuello de botella en el futuro.
Podemos ver cuánto puede transferir datos un bus PCI en nuestro escenario de ejemplo utilizando esta ecuación:
32 bits ÷ 8 bits por byte × 33 MHz = 133 MBps
Por tanto, podemos suponer que un bus PCI de 32 bits que funcione a 33 Mhz puede transferir 133 MBps de datos.
Nota:
El resultado de esta ecuación representa el límite teórico de los datos transferidos. En realidad, la mayoría de los sistemas solo alcanzan alrededor del 50 % del límite máximo. En determinados escenarios de ráfagas, el sistema puede alcanzar el 75 % del límite durante breves periodos.
Según esta ecuación, un bus PCI de 66 MHz y 64 bits puede soportar un máximo teórico de 528 MBps:
64 bits ÷ 8 bits por byte × 66 Mhz = 528 MBps
Cuando se añade cualquier otro dispositivo, como un adaptador de red o una segunda controladora SCSI, se reduce el ancho de banda disponible para el sistema, ya que todos los dispositivos comparten el ancho de banda y pueden competir entre sí por los limitados recursos de procesamiento.
Análisis de subsistemas de almacenamiento para detectar cuellos de botella
En este escenario, el cabezal es el factor que limita la cantidad de E/S que puedes solicitar. Como resultado, este cuello de botella también limita la cantidad de datos que el sistema puede transmitir. Debido a que nuestro ejemplo es un escenario AD DS, la cantidad de datos transmisibles es de 100 E/S aleatorias por segundo en incrementos de 8 KB, para un total de 800 KB por segundo cuando se accede a la base de datos Jet. En contraste, el rendimiento máximo de un cabezal que configures para asignar exclusivamente a archivos de registro se limitaría a 300 E/S secuenciales por segundo en tramos de 8 KB, con un total de 2.400 KB o 2,4 MB por segundo.
Ahora que hemos analizado los componentes de nuestra configuración de ejemplo, veamos una tabla que demuestra dónde pueden producirse cuellos de botella a medida que añadimos y cambiamos componentes en el subsistema de almacenamiento.
| Notas | Análisis de cuellos de botella | Disco | En bus | Adapter (Adaptador) | Bus PCI |
|---|---|---|---|---|---|
| Esta es la configuración del controlador de dominio después de agregar un segundo disco. La configuración del disco representa el cuello de botella a 800 KB/s. | Adición de 1 disco (Total=2) La E/S es aleatoria. Tamaño de bloque de 4 KB HD de 10 000 RPM |
Total de 200 E/S Total de 800 KB/s. |
|||
| Después de agregar 7 discos, la configuración del disco sigue representando el cuello de botella a 3200 KB/s. | Adición de 7 discos (Total=8) La E/S es aleatoria. Tamaño de bloque de 4 KB HD de 10 000 RPM |
Total de 800 E/S. Total de 3200 KB/s |
|||
| Después de cambiar la E/S a secuencial, el adaptador de red se convierte en el cuello de botella porque está limitado a 1000 IOPS. | Adición de 7 discos (Total=8) La E/S es secuencial. Tamaño de bloque de 4 KB HD de 10 000 RPM |
Se pueden leer y escribir en el disco 2400 E/S, el controlador está limitado a 1000 IOPS. | |||
| Después de sustituir el adaptador de red por un adaptador SCSI que admite 10 000 IOPS, el cuello de botella vuelve a ser la configuración del disco. | Adición de 7 discos (Total=8) La E/S es aleatoria. Tamaño de bloque de 4 KB HD de 10 000 RPM Actualización del adaptador SCSI (ahora admite 10 000 E/S) |
Total de 800 E/S. Total de 3200 KB/s |
|||
| Tras aumentar el tamaño de bloque a 32 KB, el bus se convierte en el cuello de botella porque solo soporta 20 MBps. | Adición de 7 discos (Total=8) La E/S es aleatoria. Tamaño de bloque de 32 KB HD de 10 000 RPM |
Total de 800 E/S. Se pueden leer/escribir en disco 25.600 KB/s (25 MBps). El bus solo admite 20 MBps |
|||
| Después de actualizar el bus y agregar más discos, el disco sigue siendo el cuello de botella. | Adición de 13 discos (Total=14) Adición de un segundo adaptador SCSI con 14 discos La E/S es aleatoria. Tamaño de bloque de 4 KB HD de 10 000 RPM Actualizar a un bus SCSI de 320 MBps |
2800 E/S 11.200 KB/s (10,9 MBps) |
|||
| Después de cambiar la E/S a secuencial, el disco sigue siendo el cuello de botella. | Adición de 13 discos (Total=14) Adición de un segundo adaptador SCSI con 14 discos La E/S es secuencial. Tamaño de bloque de 4 KB HD de 10 000 RPM Actualizar a un bus SCSI de 320 MBps |
8400 E/S 33 600 KB/s (32,8 MB/s) |
|||
| Después de agregar unidades de disco duro más rápidas, el disco sigue siendo el cuello de botella. | Adición de 13 discos (Total=14) Adición de un segundo adaptador SCSI con 14 discos La E/S es secuencial. Tamaño de bloque de 4 KB HD de 15 000 RPM Actualizar a un bus SCSI de 320 MBps |
14 000 E/S 56 000 KB/s (54,7 MBps) |
|||
| Después de aumentar el tamaño del bloque a 32 KB, el bus PCI se convierte en el cuello de botella. | Adición de 13 discos (Total=14) Adición de un segundo adaptador SCSI con 14 discos La E/S es secuencial. Tamaño de bloque de 32 KB HD de 15 000 RPM Actualizar a un bus SCSI de 320 MBps |
14 000 E/S 448 000 KB/s (437 MBps) es el límite de lectura/escritura en el cabezal. El bus PCI soporta un máximo teórico de 133 MBps (75 % de eficiencia en el mejor de los casos). |
Introducción a RAID
Cuando introduces un controlador de matriz en su subsistema de almacenamiento, esto no cambia drásticamente su naturaleza. El controlador de matriz solo sustituye al adaptador SCSI en los cálculos. Sin embargo, el coste de lectura y escritura de datos en el disco cuando se utilizan los distintos niveles de matriz sí cambia.
En RAID 0, la escritura de datos se reparte entre todos los discos del conjunto RAID. Durante una operación de lectura o escritura, el sistema extrae o introduce datos en cada disco, lo que aumenta la cantidad de datos que el sistema puede transmitir durante ese periodo de tiempo concreto. Por lo tanto, en este ejemplo en el que estamos utilizando unidades de 10.000 rpm, el uso de RAID 0 te permitiría realizar 100 operaciones de E/S. La cantidad total de E/S que soporta el sistema es N cabezales por 100 E/S por segundo por cabezal, o N cabezales × 100 E/S por segundo por cabezal.

En RAID 1, el sistema refleja, o duplica, los datos en un par de cabezales para redundancia. Cuando el sistema realiza una operación de E/S de lectura, puede leer datos de ambos cabezales del conjunto. Esta duplicación hace que la capacidad de E/S de ambos discos esté disponible durante una operación de lectura. Sin embargo, RAID 1 no ofrece ventajas de rendimiento en las operaciones de escritura, ya que el sistema también necesita reflejar los datos escritos en el par de cabezales. Aunque la duplicación no hace que las operaciones de escritura tarden más, impide que el sistema realice más de una operación de lectura al mismo tiempo. Por lo tanto, cada operación de E/S de escritura cuesta dos operaciones de E/S de lectura.
La siguiente ecuación calcula cuántas operaciones de E/S se producen en este escenario:
E/S de lectura + 2 × E/S de escritura = Total de E/S disponible de disco consumida
Cuando conozcas la relación entre lecturas y escrituras y el número de cabezales de tu despliegue, puedes usar esta ecuación para calcular cuánta E/S puede soportar tu matriz:
IOPS máximo por cabezal × 2 cabezales × [(% Lectura + % Escritura) ÷ (% Lectura + 2 × % Escritura)] = IOPS total
Un escenario que utilice tanto RAID 1 como RAID 0 se comporta exactamente igual que RAID 1 en el coste de las operaciones de lectura y escritura. Sin embargo, ahora la E/S está seccionada en cada conjunto reflejado. Esto significa que la ecuación cambiará a esto:
IOPS máximo por cabezal × 2 cabezales × [(% Lectura + % Escritura) ÷ (% Lectura + 2 × % Escritura)] = E/S total
En un conjunto RAID 1, cuando se hace un stripe de N número de conjuntos RAID 1, la E/S total que puede procesar tu matriz se convierte en N × E/S por conjunto RAID 1:
N × {IOPS máximo por cabezal × 2 cabezales × [(% Lectura + % Escritura) ÷ (% Lectura + 2 × % Escritura)]} = IOPS total
A veces le llamamos a RAID 5 N + 1 RAID porque el sistema separa los datos a lo largo de N cabezales y escribe la información de paridad en el + 1 cabezal. Sin embargo, RAID 5 utiliza más recursos al realizar una E/S de escritura que RAID 1 o RAID 1 + 0. RAID 5 realiza el siguiente proceso cada vez que el sistema operativo envía una E/S de escritura a la matriz:
- Lee los datos antiguos.
- Lee la paridad antigua.
- Escribe los nuevos datos.
- Escribe la nueva paridad.
Cada solicitud de E/S de escritura que el sistema operativo envía al controlador de la matriz requiere cuatro operaciones de E/S para finalizar. Por lo tanto, N + 1 solicitudes de escritura RAID tardan cuatro veces más que las de lectura en finalizar. En otras palabras, para determinar cuántas peticiones de E/S del sistema operativo se traducen en cuántas peticiones reciben los cabezales, se utiliza esta ecuación:
E/S de lectura + 4 × E/S de escritura = E/S total
De manera similar, en un conjunto RAID 1 en el que conoces la relación entre lecturas y escrituras y cuántos cabezales hay, puedes usar esta ecuación para identificar cuánta E/S puede soportar tu matriz:
IOPS por cabezal × (Cabezales – 1) × [(% Lectura + % Escritura) ÷ (% Lectura + 4 × % Escritura)] = IOPS total
Nota:
El resultado de la ecuación anterior no incluye la unidad perdida por paridad.
Introducción a las SAN
La introducción de una red de área de almacenamiento (SAN) en tu entorno no afecta a los principios de planificación que hemos descrito en las secciones anteriores. Sin embargo, debes tener en cuenta que la SAN puede cambiar el comportamiento de E/S de todos los sistemas conectados a ella. Una de las principales ventajas de utilizar una SAN es que ofrece más redundancia que el almacenamiento conectado interna o externamente, pero también implica que la planificación de la capacidad debe tener en cuenta las necesidades de tolerancia a fallas. Además, a medida que introduzcas más componentes en tu sistema, también tendrás que incluirlos en tus cálculos.
Ahora vamos a desglosar una SAN en sus componentes:
- El disco duro SCSI o canal de fibra
- La placa base del canal de la unidad de almacenamiento
- Las unidades de almacenamiento en sí
- El módulo controlador de almacenamiento
- Uno o más switches SAN
- Uno o más adaptadores de bus de host (HBA)
- El bus de interconexión de componentes periféricos (PCI)
Cuando diseñas un sistema para que sea redundante, debes incluir componentes adicionales para garantizar que el sistema siga funcionando en un escenario de crisis en el que uno o varios de los componentes originales dejen de funcionar. Sin embargo, a la hora del planeamiento de capacidad, es necesario excluir los componentes redundantes de los recursos disponibles para obtener una estimación precisa de la capacidad de referencia del sistema, ya que estos componentes no suelen entrar en funcionamiento a menos que se produzca una emergencia. Por ejemplo, si tu SAN tiene dos módulos controladores, solo necesitas utilizar uno cuando calcules el rendimiento total de E/S disponible, ya que el otro no se encenderá a menos que el módulo original deje de funcionar. Tampoco deberías incluir el switch SAN redundante, la unidad de almacenamiento o los cabezales en los cálculos de E/S.
Además, como el planeamiento de capacidad solo tiene en cuenta los periodos de máxima utilización, no hay que tener en cuenta los componentes redundantes en los recursos disponibles. Los picos de utilización no deben superar el 80 % de saturación del sistema para poder dar cabida a ráfagas u otros comportamientos inusuales del sistema.
Al analizar el comportamiento del disco duro SCSI o canal de fibra debes hacerlo de acuerdo con los principios que hemos descrito en las secciones anteriores. A pesar de que cada protocolo tiene sus propias ventajas e inconvenientes, lo que más limita el rendimiento por disco son las limitaciones mecánicas del disco duro.
Cuando analices el canal en la unidad de almacenamiento, debes adoptar el mismo enfoque que adoptaste al calcular cuántos recursos había disponibles en el bus SCSI: divide el ancho de banda por el tamaño del bloque. Por ejemplo, si tu dispositivo de almacenamiento tiene seis canales que admiten cada uno una velocidad de transferencia máxima de 20 MBps, el total disponible de E/S y transferencia de datos es de 100 MBps. La razón por la que el total es de 100 MBps en lugar de 120 MBps es porque el rendimiento total del canal de almacenamiento no debería superar la cantidad de rendimiento que utilizaría si uno de los canales se apagara de repente, dejándolo con solo cinco canales en funcionamiento. Por supuesto, este ejemplo también supone que el sistema distribuye uniformemente la carga y la tolerancia a fallos en todos los canales.
La posibilidad de convertir el ejemplo anterior en un perfil de E/S depende del comportamiento de la aplicación. Para las E/S de Active Directory Jet, el valor máximo sería de aproximadamente 12.500 E/S por segundo, o 100 MBps ÷ 8 KB por E/S.
Para saber cuánto rendimiento admiten tus módulos controladores, también debes conocer las especificaciones del fabricante. En este ejemplo, la SAN tiene dos módulos de controlador que admiten 7500 E/S cada uno. Si no utilizas redundancia, el rendimiento total del sistema sería de 15.000 IOPS. Sin embargo, en un escenario en el que se requiere redundancia, calcularías el rendimiento máximo basándote en los límites de solo uno de los controladores, que es de 7.500 IOPS. Suponiendo que el tamaño del bloque sea de 4 KB, este umbral está muy por debajo de las 12.500 IOPS máximas que pueden soportar los canales de almacenamiento y, por tanto, es el cuello de botella de tu análisis. Sin embargo, a efectos de planificación, el máximo deseado de E/S que debes planificar es de 10.400 E/S.
Cuando los datos salen del módulo controlador, transmiten una conexión canal de fibra de 1 GBps, o 128 MBps. Dado que esta cantidad supera el ancho de banda total de 100 MBps en todos los canales de la unidad de almacenamiento, no supondrá un cuello de botella para el sistema. Además, como esta transmisión se realiza solo en uno de los dos canales de fibra debido a la redundancia, si una conexión de canal de fibra deja de funcionar, la conexión restante sigue teniendo capacidad suficiente para gestionar la demanda de transferencia de datos.
A continuación, los datos transitan por un switch SAN de camino al servidor. El switch limita la cantidad de E/S que puede manejar porque necesita procesar la petición entrante y luego reenviarla al puerto apropiado. Sin embargo, solo puedes saber cuál es el límite del interruptor si consultas las especificaciones del fabricante. Por ejemplo, si tu sistema tiene dos switches y cada uno puede manejar 10.000 IOPS, el rendimiento total será de 20.000 IOPS. Según las reglas de tolerancia a fallas, si un switch deja de funcionar, el rendimiento total del sistema será de 10.000 IOPS. Por lo tanto, en circunstancias normales, no deberías utilizar más del 80%, u 8.000 E/S.
Finalmente, el HBA que instales en el servidor también limita la cantidad de E/S que puede manejar. Normalmente, se instala un segundo HBA para redundancia, pero al igual que con el switch SAN, cuando se calcula cuánta E/S puede manejar el sistema, el rendimiento total será N - 1 HBA.
Consideraciones sobre el almacenamiento en caché
Las cachés son uno de los componentes que pueden afectar significativamente al rendimiento global en cualquier parte del sistema de almacenamiento. Sin embargo, un análisis detallado de los algoritmos de almacenamiento en caché queda fuera del alcance de este artículo. En su lugar, le daremos una lista rápida de cosas que debe saber sobre el almacenamiento en caché en subsistemas de disco.
- El almacenamiento en caché mejora la E/S de escritura secuencial sostenida porque almacena en búfer muchas operaciones de escritura más pequeñas en bloques de E/S más grandes. También desaloja las operaciones al almacenamiento en unos pocos bloques grandes en lugar de muchos pequeños. Esta optimización reduce el total de operaciones de E/S aleatorias y secuenciales, dejando más recursos disponibles para otras operaciones de E/S.
- El almacenamiento en caché no mejora el rendimiento de E/S de escritura sostenida en el subsistema de almacenamiento, ya que solo almacena en búfer las escrituras hasta que los cabezales están disponibles para consignar los datos. Cuando todas las E/S disponibles de los cabezales están saturadas de datos durante largos periodos de tiempo, la caché acaba por llenarse. Para vaciar la caché, debes proporcionar suficientes E/S para que la caché se vacíe por sí misma, proporcionando cabezales extra o dando suficiente tiempo entre ráfagas para que el sistema se ponga al día.
- Las cachés más grandes permiten almacenar más datos, lo que significa que la caché puede soportar periodos de saturación más largos.
- En los subsistemas de almacenamiento típicos, el sistema operativo experimenta un rendimiento de escritura mejorado con las cachés, ya que el sistema solo necesita escribir los datos en la caché. Sin embargo, una vez que el soporte subyacente se satura con operaciones de E/S, la caché se llena y el rendimiento de escritura vuelve a la velocidad normal del disco.
- Cuando se almacena en caché la E/S de lectura, la caché es más útil cuando se almacenan los datos secuencialmente en el escritorio y se permite que la caché lea por adelantado. La lectura anticipada se produce cuando la caché puede pasar inmediatamente al siguiente sector como si este contuviera los datos que el sistema va a solicitar a continuación.
- Cuando la E/S de lectura es aleatoria, el almacenamiento en caché en el controlador de la unidad no aumenta la cantidad de datos que el disco puede leer. Si el tamaño de la caché basada en el sistema operativo o en la aplicación es mayor que el tamaño de la caché basada en el hardware, cualquier intento de mejorar la velocidad de lectura del disco no cambiará nada.
- En Active Directory, la caché solo está limitada por la cantidad de RAM que tenga el sistema.
Consideraciones sobre SSD
Las unidades de estado sólido (SSD) son fundamentalmente diferentes de los discos duros basados en cabezales. Las unidades SSD pueden gestionar mayores volúmenes de E/S con menor latencia. Aunque las unidades SSD pueden ser caras en términos de coste por gigabyte, son muy baratas en términos de coste por E/S. Sin embargo, para planificar la capacidad de las unidades SSD hay que plantearse las mismas preguntas que para los cabezales: ¿cuántas IOPS pueden manejar y cuál es la latencia de esas IOPS?
Estos son algunos aspectos que debe tener en cuenta a la hora de planificar las unidades SSD:
- Tanto los IOPS como la latencia están sujetos a los diseños de los fabricantes. En algunos casos, ciertos diseños de unidades SSD pueden ofrecer peores resultados que las tecnologías basadas en cabezales. Cuando intentes decidir si debes utilizar SSD o cabezales, debes revisar y validar las especificaciones del fabricante unidad por unidad en lugar de asumir que todas las tecnologías funcionan de una determinada manera.
- Los tipos de IOPS pueden tener diferentes valores dependiendo de si son de lectura o de escritura. Los servicios de AD DS se basan principalmente en la lectura y, por lo tanto, se ven menos afectados por la tecnología de escritura que se utilice en comparación con otros escenarios de aplicación.
- La resistencia a la escritura es la suposición de que las celdas de las unidades SSD tienen una vida útil limitada y acabarán desgastándose después de usarlas mucho. Para las unidades de bases de datos, un perfil de E/S predominantemente de lectura amplía la resistencia de escritura de las celdas hasta el punto de que no es necesario preocuparse tanto por la resistencia de escritura.
Resumen
Imagina que el almacenamiento es como la plomería interior de una casa. Los IOPS del soporte en el que almacenas tus datos son como el desagüe principal de la casa. Cuando el desagüe principal se atasca o se ve limitado por el tamaño o el colapso de la tubería, los desagües se atascan y no funcionan correctamente cuando el hogar utiliza mucha agua. Este escenario es como cuando un entorno compartido tiene uno o más sistemas que utilizan almacenamiento compartido en la misma SAN, NAS o iSCSI con los mismos medios subyacentes. Como la demanda de los usuarios supera la capacidad del sistema, el rendimiento se resiente.
De la misma manera, en nuestro escenario imaginario de plomaría, puedes adoptar diferentes enfoques para resolver los atascos y otros problemas de rendimiento:
- Para solucionar el problema de una tubería de desagüe colapsada o demasiado pequeña, hay que sustituir las tuberías por otras que funcionen y tengan el tamaño correcto. En términos de almacenamiento compartido, es como añadir nuevo hardware o redistribuir el uso de los sistemas compartidos por toda la infraestructura.
- Para desatascar un desagüe es necesario identificar los problemas subyacentes y su ubicación y, a continuación, eliminarlos con la herramienta adecuada. Por ejemplo, un atasco relativamente sencillo en un desagüe del fregadero de la cocina solo necesita un desatascador o un desatascador para eliminarlo, mientras que los atascos más complejos que implican un objeto atrapado pueden requerir una serpiente de desagüe. Del mismo modo, en un sistema de almacenamiento compartido, identificar la causa de los problemas de rendimiento le ayuda a averiguar si necesita crear una copia de seguridad a nivel del sistema, sincronizar los análisis antivirus en todos los servidores o sincronizar el software de desfragmentación que ejecuta durante los periodos pico.
En la mayoría de los diseños de plomería, varios desagües desembocan en el desagüe principal. Cuando un desagüe se atasca, el agua solo queda atrapada detrás del punto donde está el atasco. Si se obstruye un punto de unión, todos los desagües situados detrás de ese punto dejan de desaguar. En un escenario de almacenamiento, una unión que se atasca es como un switch sobrecargado, un problema de compatibilidad de controladores o tareas de software no sincronizadas. Debes medir los IOPS y el tamaño de E/S para determinar si tu sistema de almacenamiento puede soportar la carga y, a continuación, ajustar el sistema según sea necesario.
Apéndice D: solución de problemas de almacenamiento en entornos en los que más RAM no es una opción
Muchas recomendaciones de almacenamiento antes del almacenamiento virtualizado servían dos propósitos:
- Aislar las E/S para evitar que los problemas de rendimiento en el cabezal del sistema operativo afecten al rendimiento de la base de datos y los perfiles de E/S.
- Aprovechar el aumento de rendimiento que los discos duros y cachés basados en cabezales pueden proporcionar a su sistema cuando se utilizan con la E/S secuencial de los archivos de registro AD DS. Aislar la E/S secuencial en una unidad física independiente también puede aumentar el rendimiento.
Con las nuevas opciones de almacenamiento, muchos supuestos fundamentales en los que se basaban las recomendaciones anteriores ya no son ciertos. Los escenarios de almacenamiento virtualizado, como los archivos de imagen iSCSI, SAN, NAS y Virtual Disk, suelen compartir medios de almacenamiento subyacentes entre varios hosts. Esta diferencia niega las suposiciones de que debe aislar la E/S y optimizar la E/S secuencial. Ahora, otros hosts que accedan a los medios compartidos pueden reducir la capacidad de respuesta del controlador de dominio.
Cuando planifiques la capacidad de rendimiento del almacenamiento, debes tener en cuenta tres aspectos:
- Estado de caché en frío
- Estado de caché caliente
- Copia de seguridad y restauración
El estado de caché en frío es cuando se reinicia inicialmente el controlador de dominio o se reinicia el servicio Active Directory, por lo que no hay datos de Active Directory en la RAM. Un estado caché caliente es cuando el controlador de dominio está operando en un estado estable y ha almacenado en caché la base de datos. En términos de diseño de rendimiento, calentar una caché fría es como hacer una corrida corta, mientras que ejecutar un servidor con una caché totalmente calentada es como hacer una maratón. Definir estos estados y los distintos perfiles de rendimiento que generan es importante, ya que hay que tenerlos en cuenta a la hora de calcular la capacidad. Por ejemplo, el hecho de tener suficiente RAM para almacenar en caché toda la base de datos durante un estado de caché caliente no ayuda a optimizar el rendimiento durante el estado de caché frío.
Para ambos escenarios de caché, lo más importante es la rapidez con la que el almacenamiento puede mover los datos del disco a la memoria. Cuando se calienta la caché, con el tiempo el rendimiento mejora a medida que las consultas reutilizan los datos, aumenta la tasa de aciertos de la caché y disminuye la frecuencia con la que se acude al disco para recuperar datos. Como resultado, también disminuyen los efectos adversos sobre el rendimiento derivados de tener que acudir al disco. Cualquier degradación del rendimiento es temporal y suele desaparecer cuando la caché alcanza su estado caliente y el tamaño máximo que permite el sistema.
Puedes medir la rapidez con la que el sistema puede obtener datos del disco midiendo las IOPS disponibles en Active Directory. El número de IOPS disponibles también depende del número de IOPS disponibles en el almacenamiento subyacente. Desde el punto de vista del planeamiento, dado que el calentamiento de la caché y los estados de copia de seguridad o restauración son eventos excepcionales que suelen ocurrir fuera de las horas pico y están sujetos a la carga de controladores de dominio, no podemos dar recomendaciones generales más allá de solo entrar en estos estados durante las horas valle.
En la mayoría de los escenarios, AD DS es predominantemente E/S de lectura, con una proporción de 90 % de lectura y 10 % de escritura. La E/S de lectura es el cuello de botella típico para la experiencia del usuario, mientras que la E/S de escritura es el cuello de botella que degrada el rendimiento de escritura. Las cachés tienden a proporcionar un beneficio mínimo a la lectura de E/S porque las operaciones de E/S para el archivo NTDS.dit son predominantemente aleatorias. Por lo tanto, su principal prioridad es asegurarse de configurar correctamente el almacenamiento del perfil de E/S de lectura.
En condiciones normales de funcionamiento, su objetivo de la planeación del almacenamiento es minimizar los tiempos de espera para que el sistema devuelva las peticiones de AD DS al disco. El número de operaciones de E/S excepcionales y pendientes debe ser menor o igual que el número de rutas en el disco. Para escenarios de supervisión del rendimiento, generalmente recomendamos que el LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read contador debe ser inferior a 20 ms. Deberías el umbral de funcionamiento mucho más bajo, lo más cerca posible de la velocidad de almacenamiento, en un rango de dos a seis milisegundos según el tipo de almacenamiento.
El siguiente gráfico de líneas muestra la medición de la latencia del disco dentro de un sistema de almacenamiento.
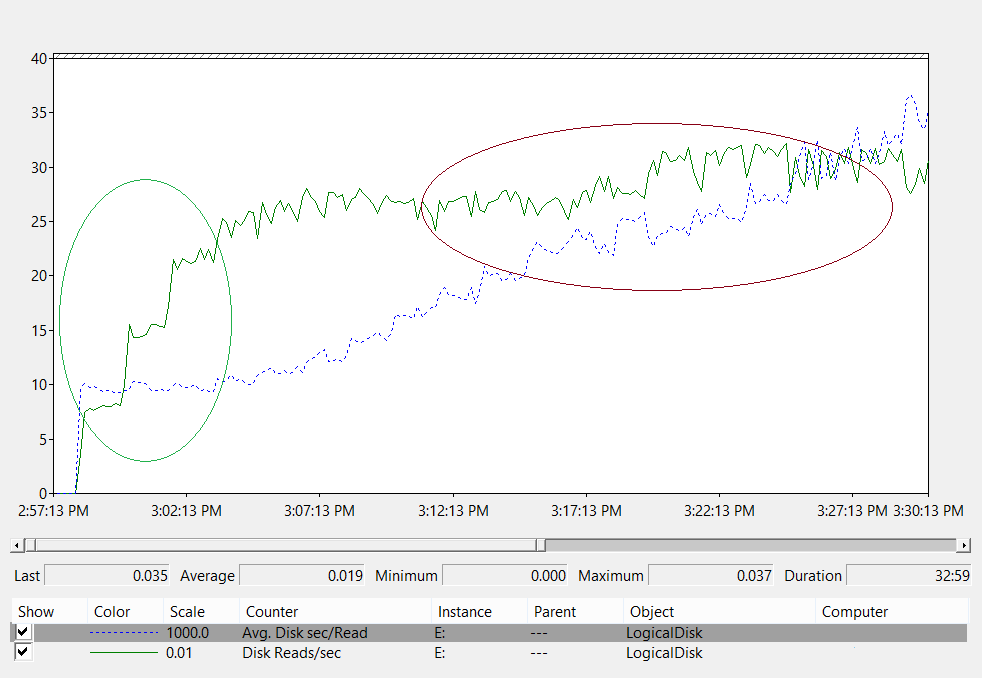
Analicemos este gráfico de líneas:
- El área de la izquierda del gráfico, rodeada por un círculo verde, muestra que la latencia se mantiene en 10 ms a medida que la carga aumenta de 800 IOPS a 2.400 IOPS. Esta área es la línea de base de la rapidez con la que el almacenamiento subyacente puede procesar una solicitud de E/S. Sin embargo, esta línea de base se ve afectada por el tipo de solución de almacenamiento que utilices.
- La zona de la derecha del gráfico marcada con un círculo granate muestra el rendimiento del sistema entre la línea de base y el final de la recogida de datos. El rendimiento en sí no cambia, pero la latencia aumenta. Esta área demuestra cómo las peticiones pasan más tiempo esperando en la cola para ser enviadas al subsistema de almacenamiento cuando los volúmenes de las peticiones superan los límites físicos del almacenamiento subyacente.
Ahora, pensemos en qué nos dicen estos datos.
En primer lugar, supongamos que un usuario que consulta la pertenencia a un grupo grande requiere que el sistema lea 1 MB de datos del disco. Con estos valores se puede evaluar la cantidad de E/S necesaria y el tiempo que tardarán las operaciones:
- El tamaño de cada página de la base de datos de Active Directory es de 8 KB.
- El número mínimo de páginas que el sistema necesita leer es 128.
- Por lo tanto, en la zona de referencia del diagrama, el sistema debería tardar al menos 1,28 segundos en cargar los datos del disco y devolverlos al cliente. En la marca de 20 ms, donde el rendimiento supera ampliamente el máximo recomendado, el proceso tarda 2,5 segundos.
A partir de estas cifras, puedes calcular la velocidad a la que se calentará la caché mediante esta ecuación:
2.400 IOPS × 8 KB por E/S
Después de realizar este cálculo, podemos decir que la tasa de calentamiento de la caché en este escenario es de 20 MBps. En otras palabras, el sistema carga aproximadamente 1 GB de base de datos en la memoria RAM cada 53 segundos.
Nota:
Es normal que la latencia aumente durante breves periodos mientras los componentes leen o escriben agresivamente en el disco. Por ejemplo, la latencia aumenta cuando el sistema está realizando una copia de seguridad o AD DS ejecuta la recolección de basura. Deberías proveer un margen adicional para estos eventos periódicos además de sus estimaciones de uso originales. Tu objetivo es ofrecer un rendimiento suficiente para acomodar estos picos sin afectar al funcionamiento general.
Hay un límite físico a la rapidez con la que se calienta la caché en función de cómo se diseñe el sistema de almacenamiento. La única cosa que puede calentar la caché al ritmo que el almacenamiento subyacente puede acomodar son las peticiones entrantes de los clientes. Ejecutar scripts para intentar precalentar la caché durante las horas punta compite con las peticiones reales de los clientes, aumenta la carga total, carga datos que no son relevantes para las peticiones de los clientes y degrada el rendimiento. Te recomendamos que evites utilizar medidas artificiales para calentar la caché.