Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Puedes habilitar la recuperación ante desastres para tu implementación de Servicios de Escritorio remoto que aproveche varios centros de datos en Azure. A diferencia de una implementación de RDS de alta disponibilidad estándar (como se describe en Arquitectura de Servicios de Escritorio remoto), que usa centros de datos de una única región de Azure (por ejemplo, Oeste de Europa), una implementación de varios centros de datos usa los centros de datos de varias ubicaciones geográficas, lo que aumenta la disponibilidad de la implementación: es posible que un centro de datos no esté disponible, pero es improbable que varias regiones dejan de funcionar al mismo tiempo. Al implementar una arquitectura de RDS con redundancia geográfica, puedes habilitar la conmutación por error en caso de falla grave de toda una región.
Puedes seguir las instrucciones a continuación para aprovechar los servicios de infraestructura de Microsoft Azure y RDS para prestar servicios de hospedaje de escritorio con redundancia geográfica y licencias de acceso de suscriptor (SAL) a varios inquilinos a través del programa del Contrato de licencias del proveedor de servicios (SPLA) de Microsoft. También puedes seguir los pasos a continuación para crear un servicio de hospedaje con redundancia geográfica para tus propios empleados mediante las licencias CAL de usuario de RDS con derechos extendidos a través de Software Assurance.
Arquitectura lógica para alta disponibilidad: una y varias regiones
En la siguiente imagen se muestra la arquitectura de una implementación de alta disponibilidad en una única región de Azure:
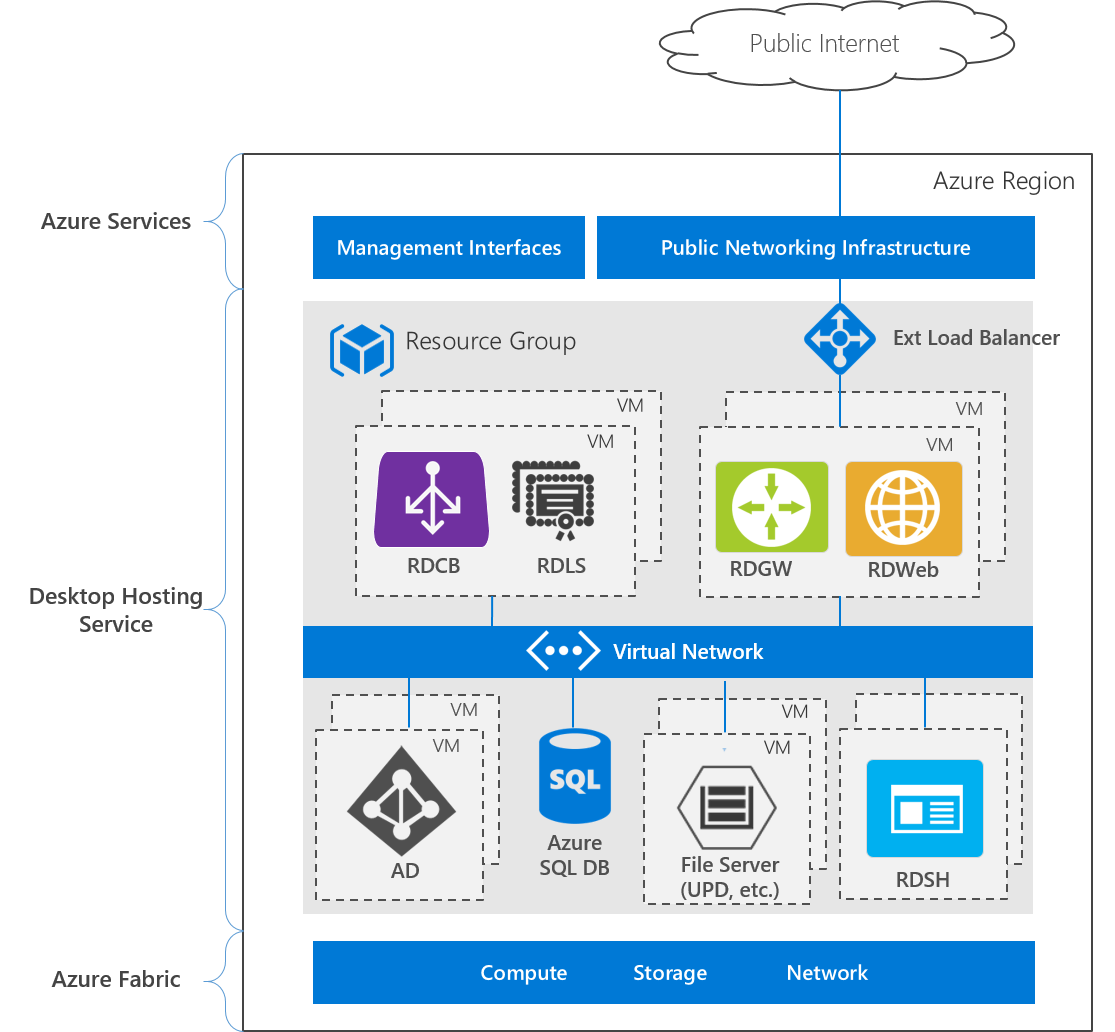
La implementación consta de tres niveles:
- Servicios de Azure: Las interfaces de Administración de Azure, incluidos Azure Portal y las API, y los servicios de red pública, como DNS y direcciones IP públicas.
- Servicio de hospedaje de escritorio: Máquinas virtuales, redes, almacenamiento, servicios de Azure y servicios de rol de Windows Server.
- Azure Fabric: Sistemas operativos de Windows Server que ejecutan el rol Hyper-V, usados para virtualizar servidores físicos, unidades de almacenamiento, conmutadores de red y enrutadores. Usar Azure Fabric te permite crear VM, redes, almacenamiento y aplicaciones independientes del hardware subyacente.
Para comparar, esta es la arquitectura para una implementación que usa varios centros de datos de Azure:
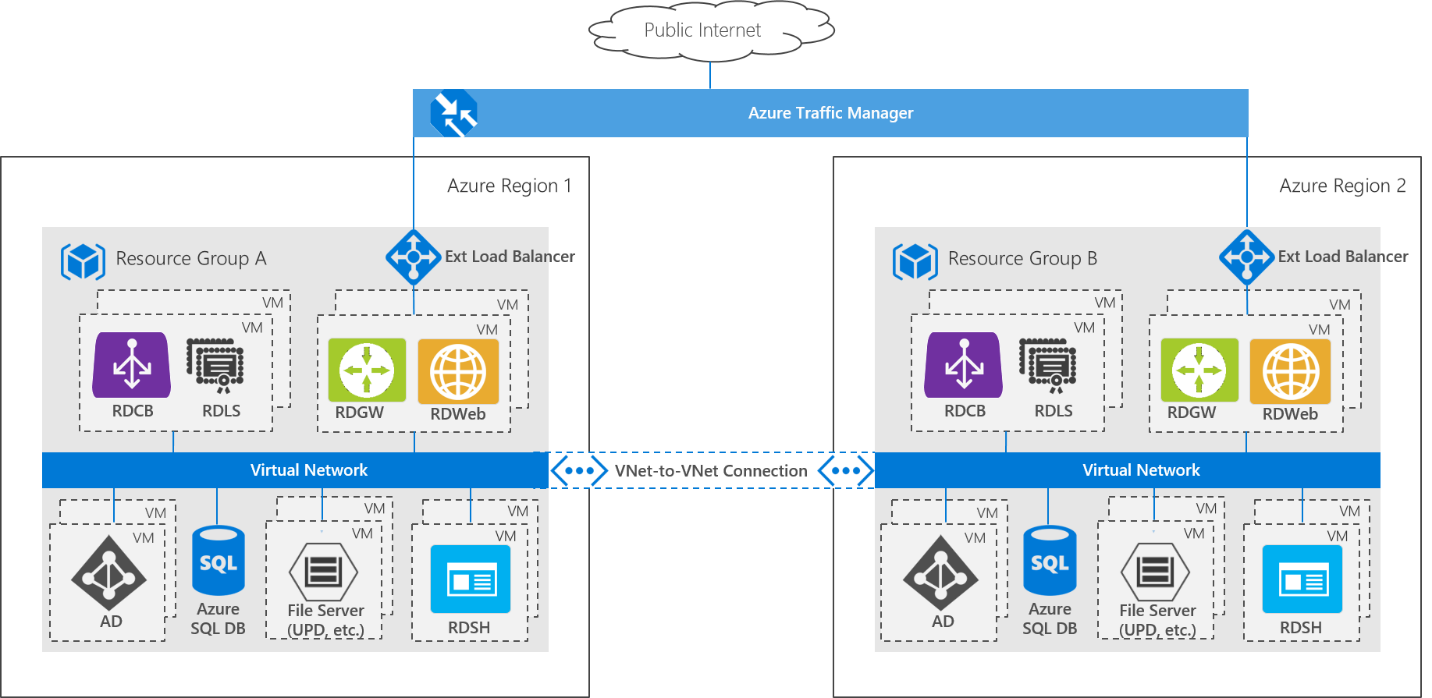
Toda la implementación de RDS se replica en una segunda región de Azure para crear una implementación con redundancia geográfica. Esta arquitectura emplea un modelo activo-pasivo, donde se ejecuta solo una implementación de RDS a la vez. Una conexión de red virtual a red virtual permite que los dos entornos se comuniquen entre sí. Las implementaciones de RDS se basan en un único bosque/dominio de Active Directory, y los servidores de AD se replican a través de las dos implementaciones, por lo que los usuarios pueden iniciar sesión en cualquiera de las implementaciones con las mismas credenciales. La configuración del usuario y los datos almacenados en discos de perfil de usuario (UPD) se almacenan en un Servidor de archivos de escalabilidad horizontal (SOFS) de Espacios de almacenamiento directo con un clúster de dos nodos. Un segundo clúster idéntico de Storage Spaces Direct se implementa en la segunda región (pasiva), y Storage Replica se utiliza para replicar los perfiles de usuario de la implementación activa a la pasiva. Azure Traffic Manager se usa para dirigir automáticamente a los usuarios finales a cualquier implementación que esté activa actualmente (desde la perspectiva del usuario final, este accede a la implementación mediante una dirección URL única y no es consciente de qué región termina usando).
Podría crear una implementación de RDS sin alta disponibilidad en cada región, pero si incluso se reinicia una sola máquina virtual en una región, se produciría una conmutación por error, lo que aumentaría la probabilidad de que se produzcan conmutaciones por error adicionales con impactos de rendimiento asociados.
Pasos de implementación
Crea los siguientes recursos en Azure para crear una implementación de RDS de varios centros de datos con redundancia geográfica:
Dos grupos de recursos en dos regiones de Azure independientes. Por ejemplo GR A (la implementación activa, GR significa "grupo de recursos") y GR B (la implementación pasiva).
Una implementación de Active Directory de alta disponibilidad en GR A. Puedes usar la plantilla Create an new AD Domain with 2 Domain Controllers (Crear un nuevo dominio de AD con 2 controladores de dominio) para crear la implementación.
Una implementación de RDS de alta disponibilidad en GR A. Usa la plantilla RDS farm deployment using existing active directory (Implementación de granja de RDS mediante una instancia existente de Active Directory) para crear la implementación básica de RDS y, luego, sigue la información de Servicios de Escritorio remoto: alta disponibilidad para configurar los demás componentes de RDS para alta disponibilidad.
Una red virtual en GR B; asegúrate de usar un espacio de direcciones que no se superponga con la implementación en GR A.
Una conexión VNet a VNet entre los dos grupos de recursos.
Dos máquinas virtuales de AD en un conjunto de disponibilidad en GR B; asegúrate de que los nombres de las VM sean diferentes de las VM de AD en GR A. Implementa dos VM de Windows Server 2016 en un único conjunto de disponibilidad, instala el rol Servicios de dominio de Active Directory y, luego, promuévelas al controlador de dominio en el dominio que creaste en el paso 1.
Una segunda implementación de RDS de alta disponibilidad en GR B.
- Usa de nuevo la plantilla RDS Farm Deployment using existing Active Directory (despliegue de granja RDS usando el directorio activo existente), pero esta vez realizando los siguientes cambios. (Para personalizar la plantilla, selecciónala en la galería, haz clic en Implementar en Azure y, luego, Editar plantilla).
Ajuste el espacio de direcciones de la IP privada del servidor DNS para que corresponda con la 'VNet' en RG B.
Busca "dnsServerPrivateIp" en las variables. Edita la dirección IP predeterminada (10.0.0.4) para que corresponda al espacio de direcciones definido en la red virtual en GR B.
Edita los nombres de equipo para que no entren en conflicto con los de la implementación en GR A.
Busque las máquinas virtuales en la sección Recursos de la plantilla. Cambie el campo computerName en osProfile. Por ejemplo, "gateway-b" puede convertirse en "[concat('rdsh-b-', copyIndex())]", y "broker" puede convertirse en "broker-b".
(También puedes cambiar los nombres de las VM manualmente después de ejecutar la plantilla).
- Como en el paso 3 anterior, usa la información de Servicios de Escritorio remoto: alta disponibilidad para configurar los demás componentes de RDS para alta disponibilidad.
- Usa de nuevo la plantilla RDS Farm Deployment using existing Active Directory (despliegue de granja RDS usando el directorio activo existente), pero esta vez realizando los siguientes cambios. (Para personalizar la plantilla, selecciónala en la galería, haz clic en Implementar en Azure y, luego, Editar plantilla).
Un Servidor de archivos de escalabilidad horizontal de Espacios de almacenamiento directo con réplica de almacenamiento en las dos implementaciones. Use el script de PowerShell para implementar la plantilla en los grupos de recursos.
Note
Puedes aprovisionar el almacenamiento manualmente (en lugar de usar el script de PowerShell y la plantilla):
- Implementa un SOFS de Espacios de almacenamiento directo de dos nodos en GR A para almacenar los discos de perfil de usuario (UPD).
- Despliega un segundo SOFS idéntico, Storage Spaces Direct en RG B; asegúrate de usar la misma cantidad de almacenamiento en cada clúster.
- Configura Réplica de almacenamiento con replicación asincrónica entre los dos.
Habilitación de UPD
Réplica de almacenamiento replica los datos de un volumen de origen (asociado a la implementación principal/activa) en un volumen de destino (asociado a la implementación secundaria/pasiva). Por diseño, el clúster de destino aparece como Online (No Access) (En línea [sin acceso]); Réplica de almacenamiento desmonta los volúmenes de destino y sus letras de unidad o puntos de montaje. Esto significa que no podrás habilitar las UPD para la implementación secundaria proporcionando la ruta de acceso del recurso compartido de archivos, porque el volumen no está montado.
¿Quieres más información sobre cómo administrar la replicación? Echa un vistazo a Replicación de almacenamiento de clúster a clúster.
Para habilitar las UPD en ambas implementaciones, haz lo siguiente:
Ejecute el cmdletSet-RDSessionCollectionConfiguration para habilitar los discos de perfil de usuario para la implementación principal (activa): proporcione una ruta de acceso al recurso compartido de archivos en el volumen de origen (que creó en el paso 7 de los pasos de implementación).
Invierte la dirección de la Réplica de almacenamiento para que el volumen de destino se convierta en el volumen de origen (con esto, se monta el volumen y hace que la implementación secundaria pueda acceder a él). Puede ejecutar el cmdlet Set-SRPartnership para hacerlo. Por ejemplo:
Set-SRPartnership -NewSourceComputerName "cluster-b-s2d-c" -SourceRGName "cluster-b-s2d-c" -DestinationComputerName "cluster-a-s2d-c" -DestinationRGName "cluster-a-s2d-c"Habilita los discos de perfil de usuario en la implementación secundaria (pasiva). Sigue los mismos pasos que completaste para la implementación principal, en el paso 1.
Invierte la dirección de la Réplica de almacenamiento de nuevo, para que el volumen de origen original vuelva a ser el volumen de origen en la asociación de Réplica de almacenamiento, y la implementación principal pueda acceder al recurso compartido de archivos. Por ejemplo:
Set-SRPartnership -NewSourceComputerName "cluster-a-s2d-c" -SourceRGName "cluster-a-s2d-c" -DestinationComputerName "cluster-b-s2d-c" -DestinationRGName "cluster-b-s2d-c"
Administrador de tráfico de Azure
Crea un perfil de Azure Traffic Manager y asegúrate de seleccionar el método de enrutamiento Prioridad. Establece los dos puntos de conexión en las direcciones IP públicas de cada implementación. En Configuración, cambie el protocolo a HTTPS (en lugar de HTTP) y el puerto a 443 (en lugar de 80). Tome nota del tiempo de vida de DNS y configúrelo adecuadamente para sus necesidades de failover.
Tenga en cuenta que Traffic Manager requiere que los extremos devuelvan 200 OK en respuesta a una solicitud GET para que se marque como "saludable". El objeto publicIP creado a partir de las plantillas de RDS funcionará, pero no agregue un complemento de ruta. En su lugar, puedes dar a los usuarios finales la dirección URL de Traffic Manager con "/RDWeb" anexado, por ejemplo: http://deployment.trafficmanager.net/RDWeb
Al implementar Azure Traffic Manager con el método de enrutamiento Prioridad, evitas que los usuarios finales accedan a la implementación pasiva, mientras que la implementación activa es funcional. Si los usuarios finales acceden a la implementación pasiva y no se ha cambiado la dirección de la Réplica de almacenamiento para la conmutación por error, el inicio de sesión del usuario se bloquea, ya que la implementación intenta y no puede acceder al recurso compartido de archivos en el clúster pasivo de Espacios de almacenamiento directo, por lo que, finalmente, la implementación renunciará y proporcionará al usuario un perfil temporal.
Desasignar máquinas virtuales para ahorrar recursos
Después de configurar ambas implementaciones, tienes la opción de apagar y desasignar la infraestructura de RDS secundaria y las VM de RDSH para ahorrar costos en estas VM. Las máquinas virtuales de SOFS de Espacios de Almacenamiento Directo y de AD deben permanecer siempre en ejecución en la implementación secundaria/pasiva para permitir la sincronización de las cuentas y perfiles de usuario.
Cuando se produce una conmutación por error, deberás iniciar las VM desasignadas. Esta configuración de implementación tiene la ventaja de tener un menor costo, pero a costa del tiempo de conmutación por error. Si se produce un error grave en la implementación activa, tendrás que iniciar manualmente la implementación pasiva o necesitarás un script de automatización para detectar el error e iniciar la implementación pasiva automáticamente. En cualquier caso, puedes tardar varios minutos en hacer que la implementación pasiva se ponga en funcionamiento y esté disponible para que los usuarios inicien sesión, lo que produce un tiempo de inactividad en el servicio. Este tiempo de inactividad depende de la cantidad de tiempo se tarda en iniciar la infraestructura RDS y las VM de RDSH (normalmente de 2 a 4 minutos, si las VM se inician en paralelo en lugar de en serie) y del tiempo para conectar el clúster pasivo (lo que depende del tamaño del clúster, normalmente de 2 a 4 minutos para un clúster de 2 nodos con 2 discos por nodo).
Active Directory
Los servidores de Active Directory en cada implementación son réplicas dentro del mismo bosque/dominio. Active Directory tiene un protocolo de sincronización integrado para mantener sincronizados los cuatro controladores de dominio. Sin embargo, puede haber algún retraso, por lo que, si se agrega un nuevo usuario a un servidor de AD, puede tardar algún tiempo en replicarse en todos los servidores de AD en las dos implementaciones. En consecuencia, asegúrate de advertir a los usuarios que no intenten iniciar sesión inmediatamente después de que se han agregado al dominio.
Servidor de licencias de Escritorio remoto
Proporciona una CAL de Escritorio remoto por usuario para cada usuario con nombre que esté autorizado a acceder a la implementación con redundancia geográfica. Distribuye las CAL por usuario de manera uniforme entre los dos Servidores de Licencias de RD en la implementación activa. A continuación, duplica estas CAL en los dos servidores de licencias de Escritorio remoto en la implementación pasiva. Dado que las CAL se duplican entre la implementación activa y pasiva, en un momento dado solo una implementación puede estar activa con usuarios que se conectan; en caso contrario, infringirás el contrato de licencia.
Administración de imágenes
Al actualizar las imágenes de RDSH para proporcionar nuevas aplicaciones o actualizaciones de software, tendrás que actualizar por separado las colecciones de RDSH en cada implementación para mantener una experiencia de usuario común entre ambas implementaciones. Puedes usar la plantilla Update RDSH collection (Actualizar colección de RDSH), pero ten en cuenta que la infraestructura de RDS y las VM de RDSH de la implementación pasiva deben estar en ejecución para poder ejecutar la plantilla.
Failover
En el caso de la implementación activa/pasiva, la conmutación por error requiere que inicies las VM de la implementación secundaria. Puedes hacerlo manualmente o con un script de automatización. En el caso de una conmutación por error grave del SOFS de Espacios de almacenamiento directo, cambia la dirección de asociación de Réplica de almacenamiento para que el volumen de destino se convierta en el volumen de origen. Por ejemplo:
Set-SRPartnership -NewSourceComputerName "cluster-b-s2d-c" -SourceRGName "cluster-b-s2d-c" -DestinationComputerName "cluster-a-s2d-c" -DestinationRGName "cluster-a-s2d-c"
Puedes obtener más información en Replicación de almacenamiento de clúster a clúster.
Azure Traffic Manager reconoce automáticamente que la implementación principal falló y que la implementación secundaria es correcta (en Puerta de enlace de Escritorio remoto, las VM se iniciaron en GR B) y dirige el tráfico de usuarios a la implementación secundaria. Los usuarios pueden usar la misma dirección URL de Traffic Manager para seguir trabajando con sus recursos remotos, por lo que disfrutan de una experiencia coherente. Ten en cuenta que la caché de DNS del cliente no actualizará el registro durante el TTL establecido en la configuración de Azure Traffic Manager.
Prueba de conmutación por error
En una asociación de Réplica de almacenamiento, solo se puede activar un volumen (el origen) a la vez. Esto significa que, al cambiar la dirección de la asociación de Réplica de almacenamiento, el volumen en la implementación principal (GR A) se convierte en el destino de replicación y, por tanto, se oculta. Por lo tanto, los usuarios que se conecten a GR A dejarán de tener acceso a sus UPD almacenadas en el SOFS en GR A.
Para probar la conmutación por error al tiempo que permites a los usuarios seguir iniciando sesión:
Inicia las VM de la infraestructura y las VM de RDSH en GR B.
Cambia la dirección de la asociación de Replicación de almacenamiento (cluster-b-s2d-c se convierte en el volumen de origen).
Deshabilita el punto de conexión de GR A en el perfil de Azure Traffic Manager para forzar a ATM a dirigir el tráfico a GR B. Como alternativa, usa un script de PowerShell:
Disable-AzureRmTrafficManagerEndpoint -Name publicIpA -Type AzureEndpoints -ProfileName MyTrafficManagerProfile -ResourceGroupName RGA -Force
GR B ahora es la implementación principal activa. Para volver de nuevo a GR A como implementación principal:
Cambia la dirección de la asociación de Réplica de almacenamiento (cluster-a-s2d-c se convierte en el volumen de origen):
Set-SRPartnership -NewSourceComputerName "cluster-a-s2d-c" -SourceRGName "cluster-a-s2d-c" -DestinationComputerName "cluster-b-s2d-c" -DestinationRGName "cluster-b-s2d-c"Vuelve a habilitar el punto de conexión de GR A en el perfil de Azure Traffic Manager:
Enable-AzureRmTrafficManagerEndpoint -Name publicIpA -Type AzureEndpoints -ProfileName MyTrafficManagerProfile -ResourceGroupName RGA
Consideraciones para las implementaciones locales
Si bien una implementación local no pude usar las plantillas de inicio rápido de Azure a las que se hace referencia en este artículo, puedes implementar manualmente todos los roles de infraestructura. En una implementación local donde el costo no depende del consumo de Azure, ten en cuenta usar un modelo activo-activo para una conmutación por error más rápida.
Puedes usar Azure Traffic Manager con puntos de conexión locales, pero se requiere una suscripción a Azure. Como alternativa, para el DNS proporcionado a los usuarios finales, asígnales un registro CNAME que simplemente dirija a los usuarios a la implementación principal. En caso de conmutación por error, modifica el registro CNAME de DNS para redirigir a la implementación secundaria. De este modo, el usuario final usa una sola dirección URL, al igual que con Azure Traffic Manager, que dirige al usuario a la implementación apropiada.
Si estás interesado en crear un modelo que vaya del entorno local a un sitio de Azure, ten en cuenta el uso de Azure Site Recovery.