Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La clonación de bloques da la orden al sistema de archivos para que copie un intervalo de bytes del archivo en nombre de una aplicación, en el que el archivo de destino puede que sea el mismo o diferente del archivo de origen. Desafortunadamente, las operaciones de copia tradicionales son costosas, ya que desencadenan lecturas y escrituras costosas en los datos físicos subyacentes.
La clonación de bloques en ReFS, sin embargo, realiza copias de metadatos con una operación de bajo coste en lugar de leer y escribir los datos de los archivos. Ya que ReFS permite que varios archivos compartan los mismos clústeres lógicos (ubicaciones físicas en un volumen), las operaciones de copia solo necesitan volver a asignar una región de un archivo a una ubicación física independiente, convirtiendo así una costosa operación física en una operación rápida y lógica. Esto permite que las copias se realicen más rápido y se generen menos E/S en el almacenamiento subyacente. Esta mejora también beneficia a las cargas de trabajo de virtualización, ya que las operaciones de combinación de puntos de control .vhdx se aceleran drásticamente cuando se utilizan operaciones de clonación de bloques. Además, ya que varios archivos pueden compartir los mismos clústeres lógicos, los datos idénticos no se almacenarán físicamente varias veces y se mejorará la capacidad de almacenamiento.
Cómo funciona
La clonación de bloques en ReFS convierte una operación de archivo de datos en una operación de metadatos. Para llevar a cabo esta optimización, ReFS presenta recuentos de referencia en los metadatos para las regiones que se han copiado. Este recuento de referencias registra el número de las distintas regiones de archivo que hacen referencia a las mismas regiones físicas. Esto permite a varios archivos compartir los mismos datos físicos:
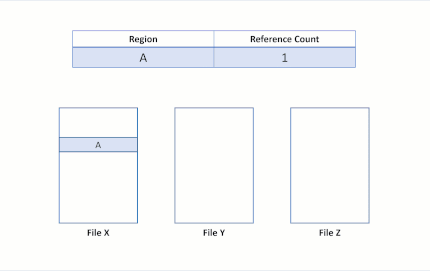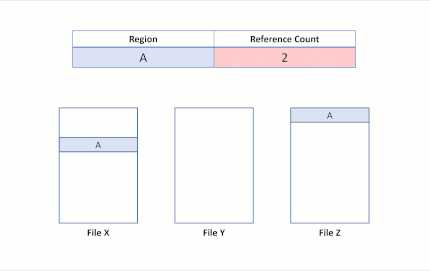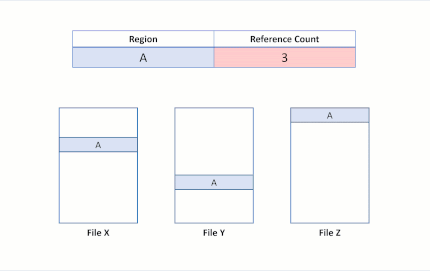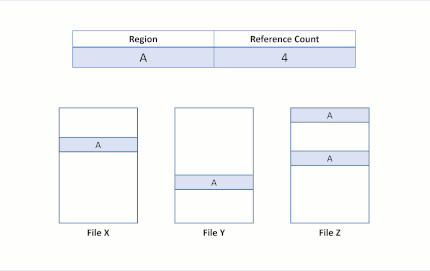
Al mantener un recuento de referencias para cada clúster lógico, ReFS no interrumpe el aislamiento entre archivos: escrituras en regiones compartidas desencadenan un mecanismo de asignación de escritura, donde ReFS asigna una nueva región para la escritura entrante. Este mecanismo conserva la integridad de los clústeres lógicos compartidos.
Example
Supongamos que hay dos archivos, X e Y, que cada archivo se compone de tres regiones y cada región se asigna para separar los clústeres lógicos.
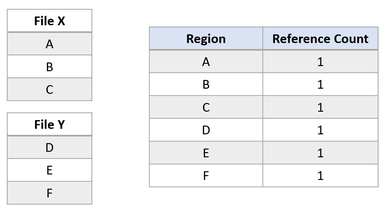
Ahora supongamos que una aplicación realiza una operación de clonación de bloques del archivo X al archivo Y para que las regiones A y B se copien en el desplazamiento de la región E. A continuación, se produciría el siguiente estado en el sistema de archivos:
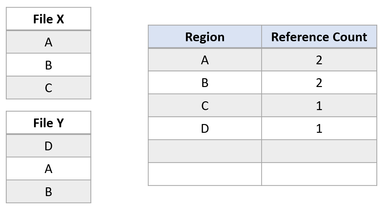
Este estado en el sistema de archivos revela una duplicación con éxito de la región de bloques clonados. Dado que ReFS realiza esta operación de copia mediante la actualización de asignaciones VCN a LCN, no se podían leer datos físicos ni se sobrescribieron datos físicos en el archivo Y. Los archivos X e Y ahora comparten clústeres lógicos, reflejados en los recuentos de referencia en la tabla. Ya que no hay datos copiados físiciamente, ReFS reduce el consumo de capacidad en el volumen.
Ahora supongamos que la aplicación intenta sobrescribir la región A en el archivo X. ReFS duplica la región compartida, actualiza los recuentos de referencias de forma adecuada y realiza la escritura entrante en la región recién duplicada. Esto asegura que el aislamiento entre los archivos se conserve.
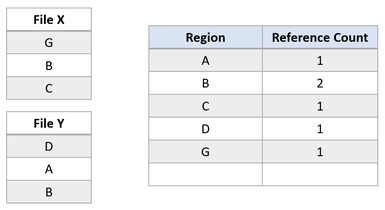
Tras de la escritura de modificación, la región B aún se comparte en ambos archivos. Si la región A fuera mayor que un clúster, solo el clúster modificado se habría duplicado y el resto seguiría siendo compartido.
Comentarios y restricciones de funcionalidad
- La región de origen y de destino deben comenzar y terminar en los límites de un clúster.
- La región clonada debe ser inferior a 4 GB de longitud.
- El número máximo de regiones de archivos que pueden asignarse a la misma región física es 8175.
- La región de destino no debe extenderse más allá del final del archivo. Si la aplicación desea extender el destino con datos clonados, primero debe llamar a SetEndOfFile.
- Si las regiones de origen y destino están en el mismo archivo, no deben superponerse. (La aplicación puede continuar dividiendo la operación de clonación de bloques en varios bloques de clones que ya no se superpongan).
- Los archivos de origen y de destino deben tener el mismo volumen ReFS.
- Los archivos de origen y destino deben tener la misma configuración De secuencias de integridad .
- Si el archivo de origen es disperso, el archivo de destino también debe serlo.
- La operación de clonación de bloques rompe los bloqueos oportunistas compartidos (también conocidos como bloqueos oportunistas de nivel 2).
- El volumen ReFS debe haberse formateado con Windows Server 2016 y, si se usa la agrupación en clústeres de conmutación por error, el nivel funcional de agrupación en clústeres debe ser Windows Server 2016 o posterior en el momento del formateo.
- A partir de las compilaciones de Windows 11 24H2 y Windows Server 2025, la clonación de bloques se produce de forma nativa en las operaciones de copia de Windows admitidas.