Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se proporcionan instrucciones sobre cómo planear volúmenes de clúster para satisfacer las necesidades de rendimiento y capacidad de las cargas de trabajo, incluida la elección de su sistema de archivos, el tipo de resistencia y el tamaño.
Nota:
Espacios de almacenamiento directo no admite un servidor de archivos para uso general. Si necesita ejecutar el servidor de archivos u otros servicios genéricos en Espacio de almacenamiento directo, configúrelo en las máquinas virtuales.
Reseña: ¿Qué son los volúmenes?
Los volúmenes son donde se colocan los archivos que necesitan las cargas de trabajo, como los archivos VHD o VHDX para Hyper-V máquinas virtuales. Los volúmenes combinan las unidades del bloque de almacenamiento para introducir las ventajas de tolerancia a errores, escalabilidad y rendimiento de Espacios de almacenamiento directo, la tecnología de almacenamiento definida por software detrás de Azure Local y Windows Server.
Nota:
Usamos el término "volumen" para hacer referencia conjuntamente al volumen y al disco virtual en él, incluida la funcionalidad proporcionada por otras características de Windows integradas, como volúmenes compartidos de clúster (CSV) y ReFS. No es necesario comprender estas distinciones de nivel de implementación para planear e implementar Espacios de almacenamiento directo correctamente.
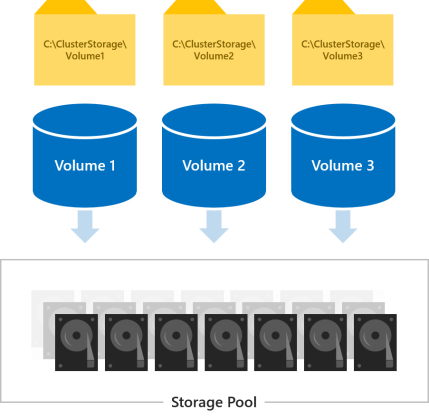
Todos los volúmenes son accesibles por todos los servidores del clúster al mismo tiempo. Una vez creados, se muestran en C:\ClusterStorage\ en todos los servidores.

Elección del número de volúmenes que se van a crear
El número de volúmenes que cree depende del tamaño del grupo y del tamaño máximo de volumen admitido, con un mínimo de un volumen por nodo. Esta configuración permite que el clúster distribuya el volumen "propiedad" (un servidor controla la orquestación de metadatos para cada volumen) uniformemente entre los servidores.
Se recomienda limitar el número total de volúmenes a 64 volúmenes por clúster.
Elección del sistema de archivos
Se recomienda usar el nuevo sistema de archivos Resilient (ReFS) para Espacios de almacenamiento directo. ReFS es el sistema de archivos premier diseñado para la virtualización y ofrece muchas ventajas, incluidas las aceleraciones de rendimiento dramáticas y la protección integrada contra daños en los datos. Admite casi todas las características ntfs clave, incluida la desduplicación de datos en Windows Server versión 1709 y posteriores. Consulte la tabla de comparación de características de ReFS para obtener más información.
Si la carga de trabajo requiere una característica que ReFS aún no admite, puede usar NTFS en su lugar.
Sugerencia
Los volúmenes con diferentes sistemas de archivos pueden coexistir en el mismo clúster.
Elección del tipo de resistencia
Los volúmenes de Espacios de almacenamiento directo proporcionan resistencia para protegerse frente a problemas de hardware, como errores de unidad o de servidor, y para habilitar la disponibilidad continua en todo el mantenimiento del servidor, como las actualizaciones de software.
Nota:
Los tipos de resistencia que puede elegir son independientes de los tipos de unidades que tenga.
Con dos servidores
Con dos servidores en el clúster, puede utilizar la duplicación bidireccional o puede utilizar la resistencia anidada.
El reflejo bidireccional mantiene dos copias de todos los datos, una copia en los discos de cada servidor. Su eficiencia de almacenamiento es del 50 por ciento; para escribir 1 TB de datos, necesita al menos 2 TB de capacidad de almacenamiento físico en el bloque de almacenamiento. La creación de reflejo bidireccional puede tolerar de forma segura un error de hardware a la vez (un servidor o una unidad).
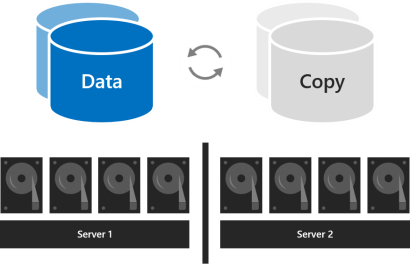
La resiliencia anidada proporciona resiliencia de datos entre servidores con reflejo bidireccional y, a continuación, agrega resiliencia dentro de un servidor con reflejo bidireccional o paridad acelerada por reflejo. El anidamiento proporciona resiliencia de datos incluso cuando un servidor se reinicia o no está disponible. Su eficacia de almacenamiento es del 25 por ciento con creación de reflejo bidireccional anidada y de alrededor del 35-40 por ciento para paridad acelerada con reflejo anidado. La resistencia anidada puede tolerar de forma segura dos errores de hardware a la vez (dos unidades, o un servidor y una unidad en el servidor restante). Debido a esta resistencia de datos agregada, se recomienda usar resistencia anidada en implementaciones de producción de clústeres de dos servidores. Para obtener más información, consulte Resistencia anidada.

Con tres servidores
Con tres servidores, debe usar la creación de reflejo triple para mejorar la tolerancia a errores y el rendimiento. La creación de reflejo triple mantiene tres copias de todos los datos, una copia en las unidades de cada servidor. Su eficacia de almacenamiento es del 33,3 por ciento: para escribir 1 TB de datos, necesita al menos 3 TB de capacidad de almacenamiento físico en el bloque de almacenamiento. La creación de reflejo triple puede tolerar de forma segura al menos dos problemas de hardware (unidad o servidor) a la vez. Si 2 nodos no están disponibles, el bloque de almacenamiento pierde el cuórum, ya que el 2/3 de los discos no está disponible y los discos virtuales no son accesibles. Sin embargo, un nodo puede estar inactivo y uno o varios discos de otro nodo pueden producir un error y los discos virtuales permanecen en línea. Por ejemplo, si reinicia un servidor cuando se produce un error de repente en otra unidad o servidor, todos los datos permanecen seguros y accesibles continuamente.
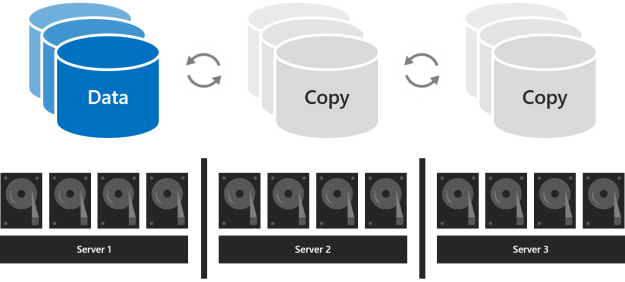
Con cuatro o más servidores
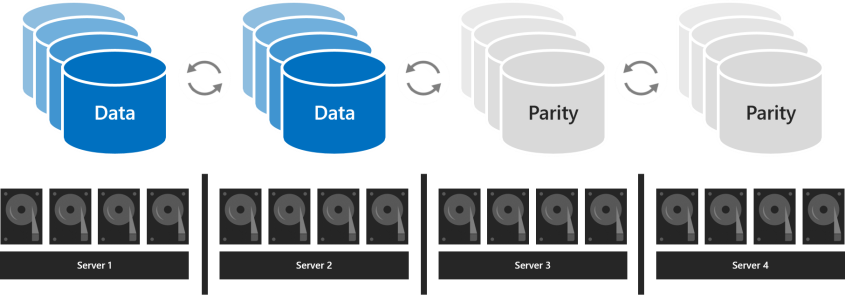
Con cuatro o más servidores, puede elegir para cada volumen si desea usar la creación de reflejo triple, paridad doble (a menudo denominada "codificación de borrado") o mezclar las dos con paridad acelerada por reflejo.
La paridad dual proporciona la misma tolerancia a errores que el triple reflejo, pero con una mejor eficiencia de almacenamiento. Con cuatro servidores, su eficiencia de almacenamiento es del 50,0 por ciento; para almacenar 2 TB de datos, necesita 4 TB de capacidad de almacenamiento físico en el bloque de almacenamiento. Esto aumenta a un 66,7 % de eficiencia de almacenamiento con siete servidores y continúa hasta un 80,0 % de eficiencia de almacenamiento. El inconveniente es que la codificación de paridad es más intensiva en proceso, lo que puede limitar su rendimiento.
El tipo de resistencia que se va a usar depende de los requisitos de rendimiento y capacidad para su entorno. Esta es una tabla que resume el rendimiento y la eficacia del almacenamiento de cada tipo de resistencia.
| Tipo de resistencia | Eficiencia de la capacidad | Velocidad |
|---|---|---|
| Reflejo |

Reflejo triple: 33 % Reflejo bidireccional: 50 % |

Rendimiento más alto |
| Paridad acelerada por reflejo |

Depende de la proporción de reflejo y paridad |
El rendimiento muestra aproximadamente 20% Mucho más lento que el reflejo, pero hasta dos veces más rápido que la paridad doble Ideal para escrituras y lecturas secuenciales grandes |
| Paridad dual |

4 servidores: 50 % 16 servidores: hasta 80% |

Latencia de E/S más alta y uso de CPU en escrituras Ideal para escrituras y lecturas secuenciales grandes |
Cuando más importa el rendimiento
Las cargas de trabajo que tienen requisitos de latencia estrictos o que necesitan una gran cantidad de IOPS aleatorias mixtas, como bases de datos de SQL Server o máquinas virtuales Hyper-V sensibles al rendimiento, deben ejecutarse en volúmenes que usan espejado para maximizar el rendimiento.
Sugerencia
El reflejo es más rápido que cualquier otro tipo de resiliencia. Usamos el reflejo para casi todos nuestros ejemplos de rendimiento.
Cuando la capacidad importa más
Las cargas de trabajo que escriben con poca frecuencia, como almacenes de datos o almacenamiento "en frío", deben ejecutarse en volúmenes que usan paridad dual para maximizar la eficacia del almacenamiento. Algunas otras cargas de trabajo, como servidor de archivos Scale-Out (SoFS), infraestructura de escritorio virtual (VDI) u otras que no crean gran cantidad de tráfico aleatorio de E/S que cambia rápidamente y/o que no requieren el mejor rendimiento también pueden usar la paridad dual, a su discreción. La paridad aumenta inevitablemente el uso de la CPU y la latencia de E/S, especialmente en las escrituras, en comparación con la creación de reflejo.
Cuando los datos se escriben de forma masiva
Las cargas de trabajo que escriben en grandes pasadas secuenciales, como los objetivos de archivado o copia de seguridad, tienen otra opción: un volumen puede mezclar la creación de reflejo y doble paridad. Las escrituras se encuentran primero en la porción reflejada y se mueven gradualmente a la porción de paridad más tarde. Esto acelera la ingesta y reduce el uso de recursos cuando llegan escrituras grandes al permitir que la codificación de paridad, que requiere un procesamiento intensivo, se lleve a cabo durante más tiempo. A la hora de dimensionar las partes, tenga en cuenta que la cantidad de escrituras que se producen a la vez (como una copia de seguridad diaria) debe caber cómodamente en la porción de reflejo. Por ejemplo, si ingiere 100 GB una vez al día, considere la posibilidad de usar la creación de reflejo de 150 GB a 200 GB y la paridad dual para el resto.
La eficiencia de almacenamiento resultante depende de las proporciones que elija.
Sugerencia
Si observa una disminución abrupta del rendimiento de escritura durante la ingesta de datos, puede indicar que la parte del reflejo no es lo suficientemente grande o que la paridad acelerada por espejo no es adecuada para su caso de uso. Por ejemplo, si el rendimiento de escritura disminuye de 400 MB/s a 40 MB/s, considere ampliar la parte de reflejo o cambiar a reflejo triple.
Acerca de las implementaciones con NVMe, SSD y HDD
En las implementaciones con dos tipos de unidades, las unidades más rápidas proporcionan almacenamiento en caché, mientras que las unidades más lentas proporcionan capacidad. Esto sucede automáticamente: para obtener más información, consulte Introducción de la memoria caché en Espacios de almacenamiento directo. En estas implementaciones, todos los volúmenes residen en última instancia en el mismo tipo de unidades: las unidades de capacidad.
En las implementaciones con los tres tipos de unidades, solo las unidades más rápidas (NVMe) proporcionan almacenamiento en caché, dejando dos tipos de unidades (SSD y HDD) para proporcionar capacidad. Para cada volumen, puede elegir si reside completamente en el nivel DE SSD, completamente en el nivel de HDD o si abarca los dos.
Importante
Se recomienda usar el nivel SSD para colocar las cargas de trabajo más sensibles al rendimiento completamente en almacenamiento flash.
Elección del tamaño de los volúmenes
Se recomienda limitar el tamaño de cada volumen a 64 TB en Azure Local.
Sugerencia
Si usa una solución de copia de seguridad que se basa en el servicio de instantáneas de volumen (VSS) y el proveedor de software Volsnap, como sucede con las cargas de trabajo del servidor de archivos, limitar el tamaño del volumen a 10 TB mejorará el rendimiento y la confiabilidad. Las soluciones de copia de seguridad que usan la API RCT de Hyper-V más reciente y/o la clonación de bloques ReFS y/o las API nativas de copia de seguridad de SQL funcionan bien hasta 32 TB y más allá.
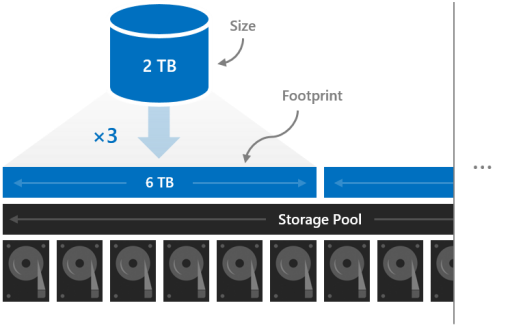
Huella
El tamaño de un volumen hace referencia a su capacidad utilizable, la cantidad de datos que puede almacenar. Esto lo proporciona el parámetro -Size del cmdlet New-Volume y, a continuación, aparece en la propiedad Size cuando se ejecuta el cmdlet Get-Volume .
El tamaño es distinto de la superficie del volumen, la capacidad total de almacenamiento físico que ocupa en el grupo de almacenamiento. La superficie depende de su tipo de resistencia. Por ejemplo, los volúmenes que usan la creación de reflejo triple tienen una superficie tres veces su tamaño.
Las superficies de sus volúmenes deben caber en el bloque de almacenamiento.
Reserva de capacidad
Al dejar parte de la capacidad del grupo de almacenamiento sin asignar, los volúmenes disponen de espacio para repararse localmente cuando se produce un error en las unidades, lo que mejora la seguridad de los datos y el rendimiento. Si hay capacidad suficiente, una reparación paralela inmediata local puede restaurar los volúmenes a su plena capacidad de recuperación incluso antes de sustituir las unidades con errores. Esto ocurre automáticamente.
Se recomienda reservar el equivalente de una unidad de capacidad por servidor, hasta 4 unidades. Puede reservar más a su discreción, pero esta recomendación mínima garantiza que una reparación paralela inmediata y local se realice correctamente después del error de cualquier unidad.

Por ejemplo, si tiene 2 servidores y usa unidades de 1 TB, destine 2 x 1 = 2 TB del grupo como reserva. Si tiene 3 servidores y unidades de capacidad de 1 TB, reserve 3 x 1 = 3 TB como reserva. Si tiene 4 o más servidores y unidades de capacidad de 1 TB, reserve 4 x 1 = 4 TB como reserva.
Nota:
En clústeres con unidades de los tres tipos (NVMe + SSD + HDD), se recomienda reservar el equivalente de un SSD más un HDD por servidor, hasta 4 unidades de cada uno.
Ejemplo: Planeamiento de capacidad
Considere un clúster de cuatro servidores. Cada servidor tiene algunas unidades de caché más dieciséis unidades de 2 TB para la capacidad.
4 servers x 16 drives each x 2 TB each = 128 TB
A partir de estos 128 TB en el bloque de almacenamiento, se han reservado cuatro unidades u 8 TB, de modo que las reparaciones en contexto puedan producirse sin necesidad de reemplazar las unidades después de que produzcan un error. Esto deja 120 TB de capacidad de almacenamiento físico en el grupo con el que podemos crear volúmenes.
128 TB – (4 x 2 TB) = 120 TB
Supongamos que necesitamos nuestra implementación para hospedar algunas máquinas virtuales de Hyper-V altamente activas, pero también tenemos un gran almacenamiento en frío: archivos antiguos y copias de seguridad que necesitamos conservar. Dado que tenemos cuatro servidores, vamos a crear cuatro volúmenes.
Vamos a colocar las máquinas virtuales en los dos primeros volúmenes, Volume1 y Volume2. Elegimos ReFS como sistema de archivos (para una creación y puntos de control más rápidos) y el reflejo triple para mejorar la resiliencia y maximizar el rendimiento. Vamos a colocar el almacenamiento en frío en los otros dos volúmenes, Volumen 3 y Volumen 4. Elegimos NTFS como sistema de archivos (para Desduplicación de datos) y paridad dual para lograr resistencia para maximizar la capacidad.
No es necesario que todos los volúmenes sean del mismo tamaño, pero por motivos de simplicidad, por ejemplo, podemos convertirlos en todos los 12 TB.
Volume1 y Volume2 ocupan una eficiencia de 12 TB x 33,3 % = 36 TB de capacidad de almacenamiento físico.
Volume3 y Volume4 ocupan una eficiencia de 12 TB x 50,0 % = 24 TB de capacidad de almacenamiento físico.
36 TB + 36 TB + 24 TB + 24 TB = 120 TB
Los cuatro volúmenes encajan exactamente en la capacidad de almacenamiento física disponible en nuestro grupo. lo que resulta ideal.

Sugerencia
No es necesario crear todos los volúmenes inmediatamente. Siempre puede extender volúmenes o crear nuevos volúmenes más adelante.
Por motivos de simplicidad, en este ejemplo se usan unidades decimales (base-10), lo que significa que 1 TB = 1000 000 000 000 bytes. Sin embargo, las cantidades de almacenamiento de Windows aparecen en unidades binarias (base-2). Por ejemplo, cada unidad de 2 TB aparecería como 1,82 TiB en Windows. Del mismo modo, el grupo de almacenamiento de 128 TB aparecería como 116.41 TiB. Esto es lo esperado.
Uso
Consulte Creación de volúmenes.
Pasos siguientes
Para obtener más información, consulte también: