Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Para obtener una introducción a WebNN, incluida la información sobre la compatibilidad del sistema operativo, el soporte técnico del modelo y mucho más, visite La información general de WebNN.
En este tutorial se muestra cómo usar WebNN con ONNX Runtime Web para crear un sistema de clasificación de imágenes en la web que se acelera por hardware mediante GPU en el dispositivo. Aprovecharemos el modelo MobileNetV2 , que es un modelo de código abierto en Hugging Face que se usa para clasificar imágenes.
Si desea ver y ejecutar el código final de este tutorial, puede encontrarlo en nuestra versión preliminar para desarrolladores de WebNN En GitHub.
Nota:
La API de WebNN es una Recomendación de Candidato de W3C y se encuentra en las primeras fases de una versión preliminar para desarrolladores. Algunas funcionalidades están limitadas. Tenemos una lista del estado actual de soporte técnico e implementación.
Requisitos y configuración:
Configuración de Windows
Asegúrese de que tiene las versiones correctas de edge, Windows y controladores de hardware, tal y como se detalla en la sección Requisitos de WebNN.
Configuración de Edge
Descargue e instale Microsoft Edge Dev.
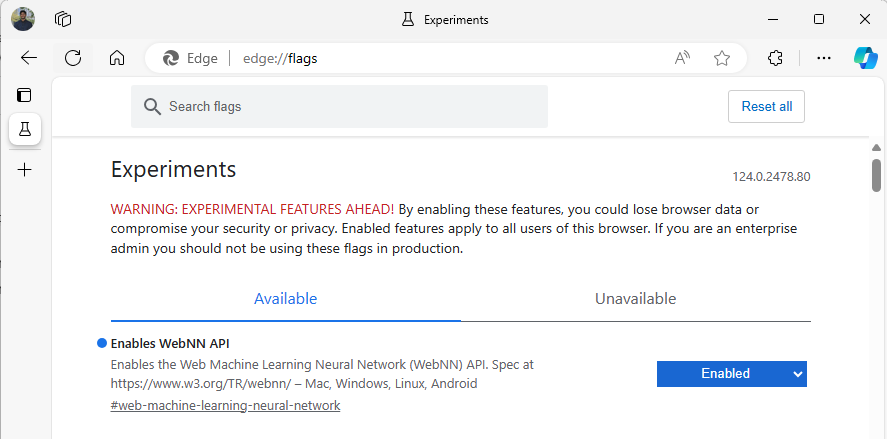
Inicie Edge Beta y vaya a
about:flagsen la barra de direcciones.Busque "API de WebNN", haga clic en la lista desplegable y establezca en "Habilitado".
Reinicie Edge, como se le solicite.
Configuración del entorno para desarrolladores
Descargue e instale Visual Studio Code (VSCode).
Inicie VSCode.
Descargue e instale la extensión live Server para VSCode en VSCode.
Seleccione
File --> Open Foldery cree una carpeta en blanco en la ubicación deseada.
Paso 1: Inicializar la aplicación web
- Para empezar, cree una nueva
index.htmlpágina. Agregue el siguiente código reutilizable a la nueva página:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
</head>
<body>
<main>
<h1>Welcome to My Website</h1>
</main>
</body>
</html>
- Compruebe que el código plantilla y la configuración del desarrollador funcionaron seleccionando el botón Iniciar transmisión en vivo en la esquina inferior derecha de VSCode. Esto debería iniciar un servidor local en Edge Beta ejecutando el código base.
- Ahora, cree un nuevo archivo denominado
main.js. Esto contendrá el código javascript de la aplicación. - A continuación, cree una subcarpeta fuera del directorio raíz denominado
images. Descargue y guarde cualquier imagen dentro de la carpeta. Para esta demostración, usaremos el nombre predeterminado deimage.jpg. - Descargue el modelo de mobilenet desde onnx Model Zoo. En este tutorial, usará el archivo mobilenet2-10.onnx . Guarde este modelo en la carpeta raíz de la aplicación web.
- Por último, descargue y guarde este archivo de clases de imagen, .
imagenetClasses.jsEsto proporciona 1000 clasificaciones comunes de imágenes para que el modelo lo use.
Paso 2: Agregar elementos de interfaz de usuario y función primaria
- Dentro del cuerpo de las
<main>etiquetas html que agregó en el paso anterior, reemplace el código existente por los siguientes elementos. Estos crearán un botón y mostrarán una imagen predeterminada.
<h1>Image Classification Demo!</h1>
<div><img src="./images/image.jpg"></div>
<button onclick="classifyImage('./images/image.jpg')" type="button">Click Me to Classify Image!</button>
<h1 id="outputText"> This image displayed is ... </h1>
- Ahora, agregará ONNX Runtime Web a la página, que es una biblioteca de JavaScript que usará para acceder a la API de WebNN. En el cuerpo de las
<head>etiquetas html, agregue los siguientes vínculos de código fuente de Javascript.
<script src="./main.js"></script>
<script src="imagenetClasses.js"></script>
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.18.0-dev.20240311-5479124834/dist/ort.webgpu.min.js"></script>
- Abra el
main.jsarchivo y agregue el siguiente fragmento de código.
async function classifyImage(pathToImage){
var imageTensor = await getImageTensorFromPath(pathToImage); // Convert image to a tensor
var predictions = await runModel(imageTensor); // Run inference on the tensor
console.log(predictions); // Print predictions to console
document.getElementById("outputText").innerHTML += predictions[0].name; // Display prediction in HTML
}
Paso 3: Preproceso de datos
- La función que acaba de agregar llama a
getImageTensorFromPath, otra función que tiene que implementar. Lo añadirás a continuación, junto con otra función asincrónica a la que llama para recuperar la imagen.
async function getImageTensorFromPath(path, width = 224, height = 224) {
var image = await loadImagefromPath(path, width, height); // 1. load the image
var imageTensor = imageDataToTensor(image); // 2. convert to tensor
return imageTensor; // 3. return the tensor
}
async function loadImagefromPath(path, resizedWidth, resizedHeight) {
var imageData = await Jimp.read(path).then(imageBuffer => { // Use Jimp to load the image and resize it.
return imageBuffer.resize(resizedWidth, resizedHeight);
});
return imageData.bitmap;
}
- También debe agregar la función
imageDataToTensorreferenciada anteriormente, la cual representará la imagen cargada en un formato tensor que funcionará con nuestro modelo ONNX. Esta es una función más implicada, aunque puede parecer familiar si ha trabajado con aplicaciones de clasificación de imágenes similares antes. Para obtener una explicación extendida, puede ver este tutorial de ONNX.
function imageDataToTensor(image) {
var imageBufferData = image.data;
let pixelCount = image.width * image.height;
const float32Data = new Float32Array(3 * pixelCount); // Allocate enough space for red/green/blue channels.
// Loop through the image buffer, extracting the (R, G, B) channels, rearranging from
// packed channels to planar channels, and converting to floating point.
for (let i = 0; i < pixelCount; i++) {
float32Data[pixelCount * 0 + i] = imageBufferData[i * 4 + 0] / 255.0; // Red
float32Data[pixelCount * 1 + i] = imageBufferData[i * 4 + 1] / 255.0; // Green
float32Data[pixelCount * 2 + i] = imageBufferData[i * 4 + 2] / 255.0; // Blue
// Skip the unused alpha channel: imageBufferData[i * 4 + 3].
}
let dimensions = [1, 3, image.height, image.width];
const inputTensor = new ort.Tensor("float32", float32Data, dimensions);
return inputTensor;
}
Paso 4: Llamar a ONNX Runtime Web
- Ahora ha agregado todas las funciones necesarias para recuperar la imagen y representarla como tensor. Ahora, con la biblioteca de ejecución en la web de ONNX que cargó anteriormente, ejecutará este modelo. Tenga en cuenta que para usar WebNN aquí, basta con especificar
executionProvider = "webnn": la compatibilidad de ONNX Runtime facilita la habilitación de WebNN.
async function runModel(preprocessedData) {
// Set up environment.
ort.env.wasm.numThreads = 1;
ort.env.wasm.simd = true;
// Uncomment for additional information in debug builds:
// ort.env.wasm.proxy = true;
// ort.env.logLevel = "verbose";
// ort.env.debug = true;
// Configure WebNN.
const modelPath = "./mobilenetv2-10.onnx";
const devicePreference = "gpu"; // Other options include "npu" and "cpu".
const options = {
executionProviders: [{ name: "webnn", deviceType: devicePreference, powerPreference: "default" }],
freeDimensionOverrides: {"batch": 1, "channels": 3, "height": 224, "width": 224}
// The key names in freeDimensionOverrides should map to the real input dim names in the model.
// For example, if a model's only key is batch_size, you only need to set
// freeDimensionOverrides: {"batch_size": 1}
};
modelSession = await ort.InferenceSession.create(modelPath, options);
// Create feeds with the input name from model export and the preprocessed data.
const feeds = {};
feeds[modelSession.inputNames[0]] = preprocessedData;
// Run the session inference.
const outputData = await modelSession.run(feeds);
// Get output results with the output name from the model export.
const output = outputData[modelSession.outputNames[0]];
// Get the softmax of the output data. The softmax transforms values to be between 0 and 1.
var outputSoftmax = softmax(Array.prototype.slice.call(output.data));
// Get the top 5 results.
var results = imagenetClassesTopK(outputSoftmax, 5);
return results;
}
Paso 5: Datos posteriores al proceso
- Por último, agregará una
softmaxfunción y luego añadirá su función final para retornar la clasificación de imágenes más probable.softmaxtransforma tus valores para que estén entre 0 y 1, que es la forma de probabilidad necesaria para esta clasificación final.
En primer lugar, agregue los siguientes archivos de código fuente para bibliotecas auxiliares Jimp y Lodash en la etiqueta principal de main.js.
<script src="https://cdnjs.cloudflare.com/ajax/libs/jimp/0.22.12/jimp.min.js" integrity="sha512-8xrUum7qKj8xbiUrOzDEJL5uLjpSIMxVevAM5pvBroaxJnxJGFsKaohQPmlzQP8rEoAxrAujWttTnx3AMgGIww==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
Ahora, agregue estas funciones siguientes a main.js.
// The softmax transforms values to be between 0 and 1.
function softmax(resultArray) {
// Get the largest value in the array.
const largestNumber = Math.max(...resultArray);
// Apply the exponential function to each result item subtracted by the largest number, using reduction to get the
// previous result number and the current number to sum all the exponentials results.
const sumOfExp = resultArray
.map(resultItem => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
// Normalize the resultArray by dividing by the sum of all exponentials.
// This normalization ensures that the sum of the components of the output vector is 1.
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp
});
}
function imagenetClassesTopK(classProbabilities, k = 5) {
const probs = _.isTypedArray(classProbabilities)
? Array.prototype.slice.call(classProbabilities)
: classProbabilities;
const sorted = _.reverse(
_.sortBy(
probs.map((prob, index) => [prob, index]),
probIndex => probIndex[0]
)
);
const topK = _.take(sorted, k).map(probIndex => {
const iClass = imagenetClasses[probIndex[1]]
return {
id: iClass[0],
index: parseInt(probIndex[1].toString(), 10),
name: iClass[1].replace(/_/g, " "),
probability: probIndex[0]
}
});
return topK;
}
- Ahora ha agregado todo el scripting necesario para ejecutar la clasificación de imágenes con WebNN en la aplicación web básica. Con la extensión Live Server para VS Code, ahora puede iniciar tu página web básica en la aplicación para ver los resultados de la clasificación por sí mismo/a.