Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Microsoft Foundry on Windows es la solución principal para los desarrolladores que buscan integrar las funcionalidades de inteligencia artificial local en sus aplicaciones de Windows.
Microsoft Foundry on Windows proporciona a los desarrolladores...
- Modelos y APIs listos para usar a través de Windows AI APIs y Foundry Local
- Marco de inferencia de IA para ejecutar cualquier modelo localmente a través de Windows ML
Independientemente de si no está familiarizado con la inteligencia artificial o un experto en Machine Learning (ML), Microsoft Foundry on Windows tiene algo para usted.
diagrama 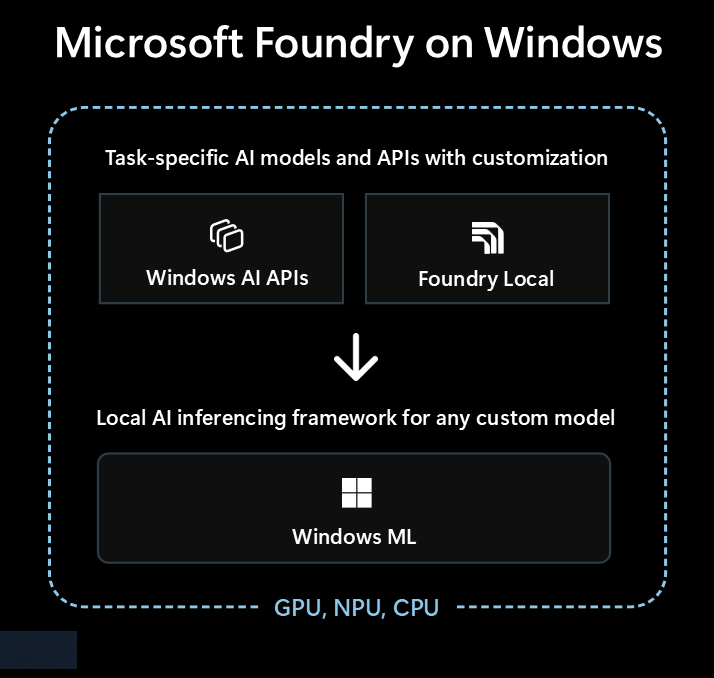
Modelos y API de inteligencia artificial listos para usar
La aplicación puede usar sin esfuerzo los siguientes modelos y API de inteligencia artificial local en menos de una hora. La distribución y el tiempo de ejecución de los archivos de modelo se controlan mediante Microsoft y los modelos se comparten entre aplicaciones. El uso de estos modelos y API solo toma una serie de líneas de código, sin necesidad de experiencia en ML.
| Tipo de modelo o API | Qué es | Opciones y dispositivos compatibles |
|---|---|---|
| Modelos de lenguaje grande (LLM) | Modelos de texto generativo | Phi Silica a través de AI APIs (que admite ajuste fino) o más de 20 modelos LLM de OSS a través de Foundry Local Consulte Vm locales para obtener más información. |
| Descripción de la imagen | Obtener una descripción de texto en lenguaje natural de una imagen | Image Description via AI APIs (Copilot+ PC) |
| Extractor de primer plano de imagen | Segmentar el primer plano de una imagen | Extractor de primer plano de imagen con AI APIs (Copilot+ PCs) |
| Generación de imágenes | Generación de imágenes a partir de texto | Image Generation via AI APIs (Copilot+ PC) |
| Borrado de objetos de imagen | Borrar objetos de imágenes | Eliminación de objetos de imagen mediante AI APIs (PCs con Copilot+) |
| Extractor de objetos de imagen | Segmentar objetos específicos en una imagen | Image Object Extractor a través de AI APIs (Copilot+ PC) |
| Super resolución de imágenes | Aumento de la resolución de imágenes | Resolución Super de Imágenes a través de AI APIs (PC de Copilot+) |
| Búsqueda semántica | Buscar texto e imágenes semánticamente | Búsqueda de contenido de la aplicación a través de AI APIs (Copilot+ PCs) |
| Reconocimiento de voz | Conversión de voz en texto | Susurrar a través de Foundry Local o reconocimiento de voz a través del SDK de Windows Consulte Reconocimiento de voz para obtener más información. |
| Reconocimiento de texto (OCR) | Reconocimiento de texto de imágenes | OCR a través de AI APIs (Copilot+ PCs) |
| Super resolución de vídeo (VSR) | Aumento de la resolución de vídeos | Video Super Resolution a través de AI APIs (Copilot+ PC) |
Uso de otros modelos con Windows ML
Puede usar una amplia variedad de modelos de Hugging Face u otros orígenes, o incluso entrenar sus propios modelos, y ejecutarlos localmente en Windows 10 y equipos posteriores mediante Windows ML(la compatibilidad y el rendimiento del modelo variarán en función del hardware del dispositivo).
Consulte buscar o entrenar modelos para usar con Windows ML para obtener más información.
¿Con qué opción empezar?
Siga este árbol de decisión para seleccionar el mejor enfoque para la aplicación y el escenario:
Compruebe si el Windows integrado cubre su escenario y está apuntando a equipos Copilot+. Esta es la ruta de acceso más rápida al mercado con un esfuerzo de desarrollo mínimo.
Si Windows AI APIs no tiene lo que necesita o necesita admitir Windows 10 y versiones posteriores, considere la posibilidad de Foundry Local para escenarios de LLM o de conversión de voz a texto.
Si necesita modelos personalizados, quiere aprovechar los modelos existentes de Hugging Face u otros orígenes, o tener requisitos de modelo específicos que no estén cubiertos por las opciones anteriores, Windows ML le ofrece la flexibilidad de encontrar o entrenar sus propios modelos (y admite Windows 10 y versiones posteriores).
La aplicación también puede usar una combinación de las tres tecnologías.
Tecnologías disponibles para la inteligencia artificial local
Las siguientes tecnologías están disponibles en Microsoft Foundry on Windows:
| Windows AI APIs | Foundry Local | Windows ML | |
|---|---|---|---|
| Qué es | Modelos y API de inteligencia artificial listos para usar en una variedad de tipos de tareas, optimizados para equipos de Copilot+ | Modelos de LLM listos para usar y de voz a texto | ONNX Runtime framework para ejecutar modelos que encuentres o entrenes |
| Dispositivos compatibles | equipos de Copilot+ | Windows 10 y equipos posteriores y multiplataforma (El rendimiento varía en función del hardware disponible, no de todos los modelos disponibles) |
Windows 10 y PCs posteriores, y multiplataforma a través de código abierto ONNX Runtime (El rendimiento varía en función del hardware disponible) |
| Tipos de modelo y API disponibles |
LLM Descripción de la imagen Extractor de primer plano de imagen Generación de imágenes Borrado de objetos de imagen Extractor de objetos de imagen Super resolución de imágenes Búsqueda semántica Reconocimiento de texto (OCR) Super resolución de vídeo |
LLMs (múltiples) voz a texto Examinar más de 20 modelos disponibles |
Buscar o entrenar sus propios modelos |
| Distribución de modelos | Hospedado por Microsoft, adquirido en tiempo de ejecución y compartido entre aplicaciones | Hospedado por Microsoft, adquirido en tiempo de ejecución y compartido entre aplicaciones | Distribución controlada por la aplicación (las bibliotecas de aplicaciones pueden compartir modelos entre aplicaciones) |
| Aprende más | Leer los AI APIs documentos | Leer los Foundry Local documentos | Leer los Windows ML documentos |
Microsoft Foundry on Windows también incluye herramientas para desarrolladores, como Foundry Toolkit para Visual Studio Code y AI Dev Gallery que le ayudarán a crear correctamente funcionalidades de inteligencia artificial.
Foundry Toolkit para Visual Studio Code es una extensión de VS Code que permite descargar y ejecutar modelos de IA localmente, incluido el acceso a la aceleración de hardware para mejorar el rendimiento y escalar a través de DirectML. Foundry Toolkit También puede ayudarle con:
- Probar modelos en un área de juegos intuitiva o en la aplicación con una API REST.
- Ajuste del modelo de inteligencia artificial, tanto localmente como en la nube (en una máquina virtual) para crear nuevas aptitudes, mejorar la confiabilidad de las respuestas, establecer el tono y el formato de la respuesta.
- Ajuste de modelos populares de lenguaje pequeño (SLAM), como Phi-3 y Mistral.
- Implemente la característica de inteligencia artificial en la nube o con una aplicación que se ejecute en un dispositivo.
- Aproveche la aceleración de hardware para mejorar el rendimiento con las características de inteligencia artificial mediante DirectML. DirectML es una API de bajo nivel que permite que el hardware del dispositivo Windows acelere el rendimiento de los modelos de ML utilizando la GPU o NPU del dispositivo. El emparejamiento de DirectML con el ONNX Runtime suele ser la manera más sencilla para que los desarrolladores incorporen la inteligencia artificial acelerada por hardware a sus usuarios a escala. Más información: Introducción a DirectML.
- Cuantizar y validar un modelo para su uso en NPU mediante las funcionalidades de conversión de modelos
Ideas para aprovechar la inteligencia artificial local
Algunas maneras de Windows aplicaciones pueden aprovechar la inteligencia artificial local para mejorar su funcionalidad y la experiencia del usuario incluyen:
- Las aplicaciones pueden usar modelos LLM de IA generativa para comprender temas complejos para resumir, reescribir, informar o expandir.
- Las aplicaciones pueden usar modelos LLM para transformar el contenido de forma libre en un formato estructurado que la aplicación pueda comprender.
- Las aplicaciones pueden usar modelos de búsqueda semántica que permiten a los usuarios buscar contenido por significado y encontrar rápidamente contenido relacionado.
- Las aplicaciones pueden usar modelos de procesamiento de lenguaje natural para razonar sobre requisitos complejos de lenguaje natural y planear y ejecutar acciones para realizar la pregunta del usuario.
- Las aplicaciones pueden usar modelos de manipulación de imágenes para modificar de forma inteligente imágenes, borrar o agregar temas, escalar verticalmente o generar contenido nuevo.
- Las aplicaciones pueden usar modelos de diagnóstico predictivo para ayudar a identificar y predecir problemas y ayudar a guiar al usuario o hacerlo para ellos.
Uso de modelos de IA en la nube
Si el uso de características de inteligencia artificial local no es la ruta de acceso adecuada, el uso de modelos y recursos de inteligencia artificial en la nube puede ser una solución.
Uso de prácticas de inteligencia artificial responsable
Siempre que esté incorporando características de IA en sus aplicaciones de Windows, le recomendamos altamente seguir las directrices de Desarrollo de Aplicaciones y Características de IA Generativa Responsable en Windows.