Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El panel de WinML es una herramienta para ver, editar, convertir y validar modelos de aprendizaje automático para el motor de inferencia de Windows ML. El motor está integrado en Windows 10 y evalúa los modelos entrenados localmente en dispositivos Windows mediante optimizaciones de hardware para CPU y GPU para habilitar inferencias de alto rendimiento.
Obtención de la herramienta
Puede descargar el panel de WinML aquí o puede compilar la aplicación desde el origen siguiendo las instrucciones que se indican a continuación.
Compilar desde el código fuente
Al compilar la aplicación desde el origen, necesitará hacer lo siguiente:
| Requisitos | Versión | Descargar | Comando para comprobar |
|---|---|---|---|
| Python3 | 3.4 o superior | aquí | python --version |
| Hilo | más reciente | aquí | yarn --version |
| Node.js. | más reciente | aquí | node --version |
| Git | más reciente | aquí | git --version |
| MSBuild | más reciente | aquí | msbuild -version |
| Nuget | más reciente | aquí | nuget help |
Los seis requisitos previos Deben agregarse a la ruta de acceso del entorno. Tenga en cuenta que MSBuild y Nuget se incluirán en una instalación de Visual Studio 2017.
Pasos para compilar y ejecutar
Para ejecutar el panel de WinML, siga estos pasos:
- En la línea de comandos, clone el repositorio:
git clone https://github.com/Microsoft/Windows-Machine-Learning - En el repositorio, escriba lo siguiente para acceder a la carpeta correcta:
cd Tools/WinMLDashboard - Ejecute
git submodule update --init --recursivepara actualizar Netron. - Ejecute Yarn para descargar las dependencias.
- A continuación, ejecute
yarn electron-prodpara compilar e iniciar la aplicación de escritorio, que iniciará el panel.
Todos los comandos del panel disponibles se pueden ver en package.json.
Visualización y edición de modelos
El panel usa Netron para ver modelos de aprendizaje automático. Aunque WinML usa el formato ONNX, el visor de Netron admite la visualización de varios formatos de marcos diferentes.
Muchas veces un desarrollador puede necesitar actualizar determinados metadatos del modelo o modificar los nodos de entrada y salida del modelo. Esta herramienta admite la modificación de las propiedades del modelo, los metadatos y los nodos de entrada y salida de un modelo ONNX.
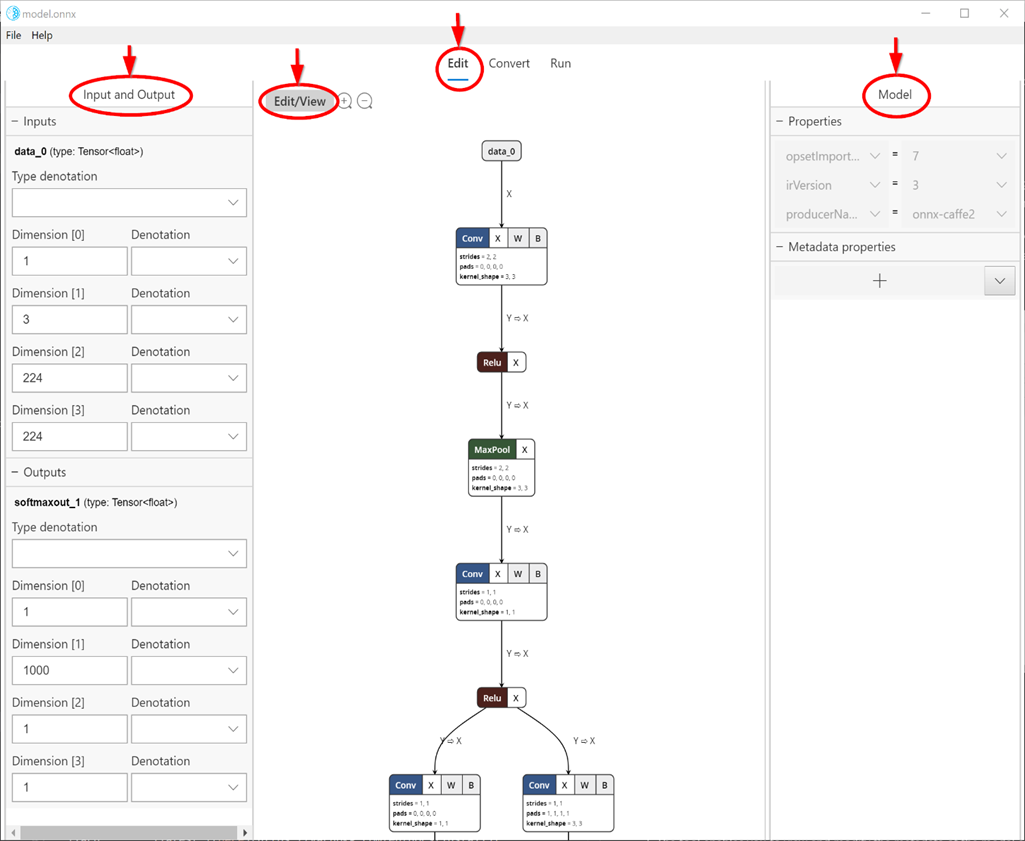
Al seleccionar la Edit pestaña (parte superior central, como se muestra en el recorte a continuación), se abrirá el panel de visualización y edición. El panel izquierdo del panel permite editar los nodos de entrada y salida del modelo, y el panel derecho permite editar propiedades del modelo. La parte central muestra el gráfico. En este momento, la compatibilidad de edición está limitada a los nodos de entrada y salida del modelo (y no a los nodos internos), las propiedades del modelo y los metadatos del modelo.
El Edit/View botón cambia del modo Editar al modo de solo vista y viceversa.
Modo de solo vista no permite la edición y activa las características nativas del visor de Netron, como la capacidad de ver información detallada para cada nodo.
Conversión de modelos
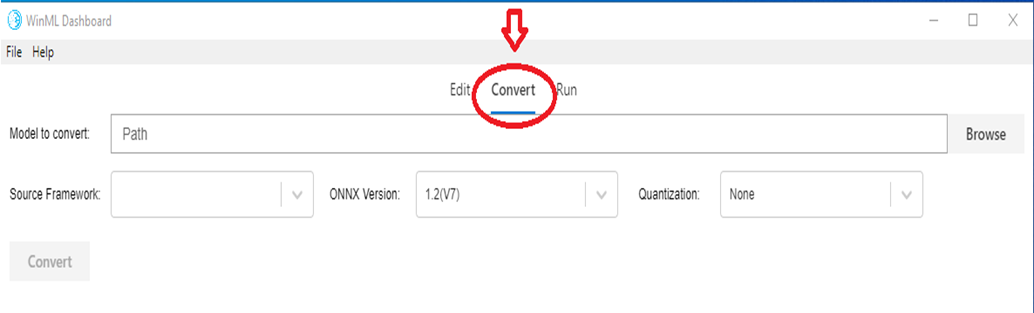
En la actualidad hay varios marcos diferentes disponibles para el entrenamiento y la evaluación de modelos de aprendizaje automático, lo que dificulta que los desarrolladores de aplicaciones integaten modelos en su producto. Windows ML usa el formato de modelo de aprendizaje automático ONNX que permite la conversión de un formato de marco a otro, y este panel facilita la conversión de modelos de diferentes marcos a ONNX.
La pestaña Convertir admite la conversión a ONNX desde los marcos de origen siguientes:
- Núcleo de Apple ML
- TensorFlow (subconjunto de modelos convertibles a ONNX)
- Keras
- Scikit-learn (subconjunto de modelos convertibles a ONNX)
- Xgboost
- LibSVM
La herramienta también permite la validación del modelo convertido mediante la evaluación del modelo con un motor de inferencia de Windows ML integrado mediante datos sintéticos (valor predeterminado) o datos de entrada reales en cpu o GPU.
Validación de modelos
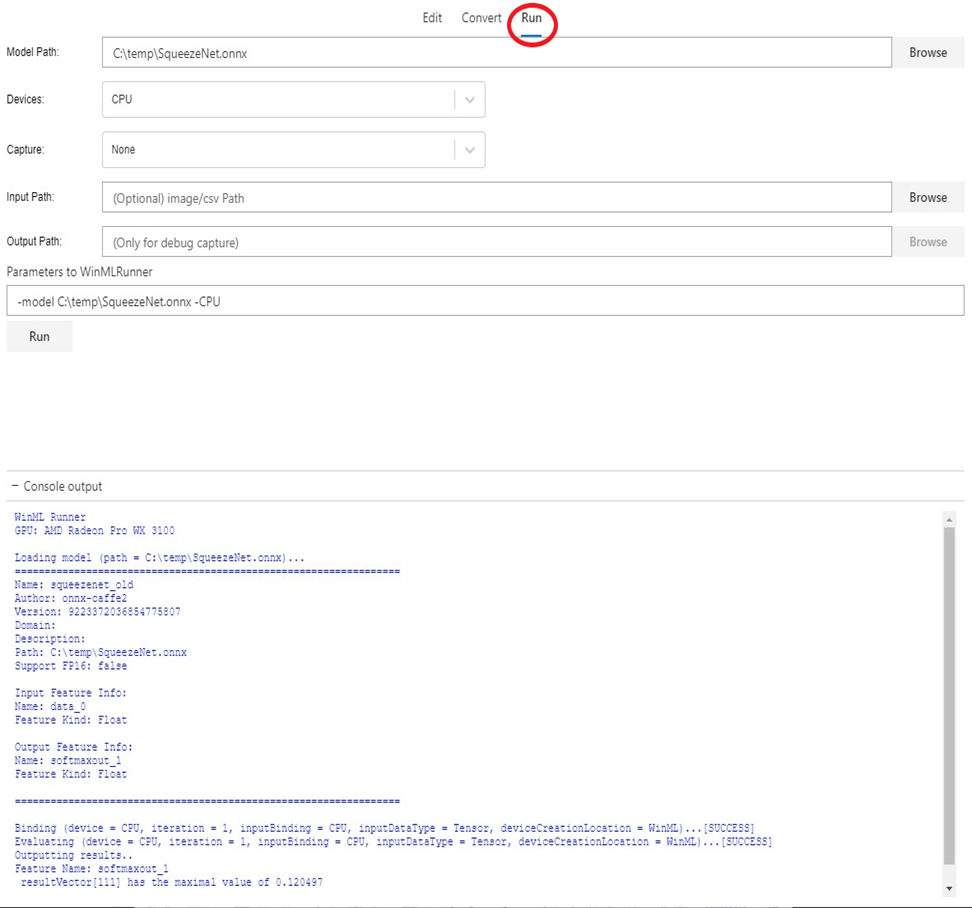
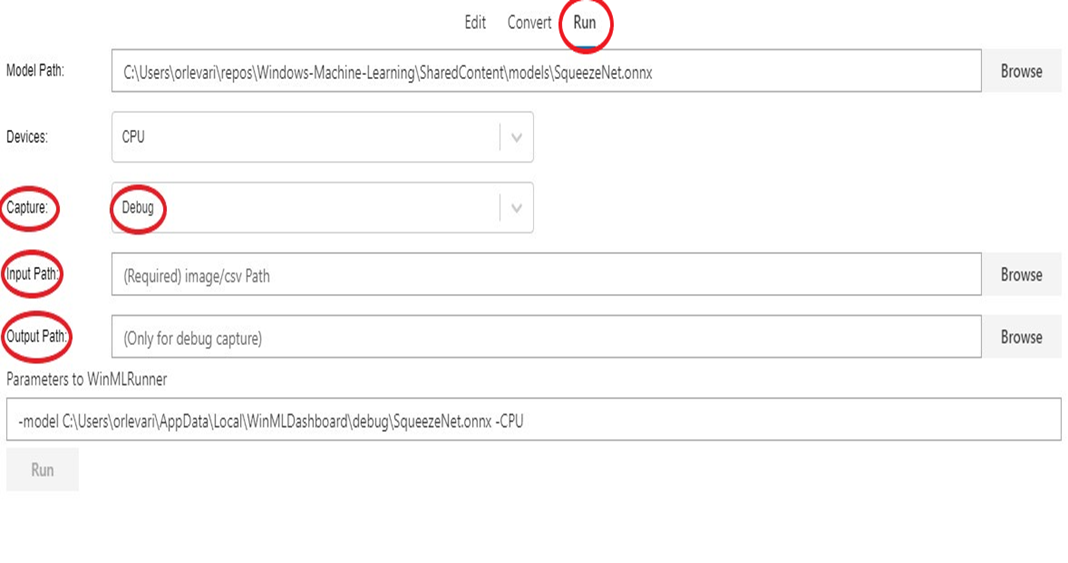
Una vez que tenga un modelo ONNX, puede validar si la conversión se ha producido correctamente y que el modelo se puede evaluar en el motor de inferencia de Windows ML. Esto se hace con la pestaña Run (consulte el recorte a continuación).
Puede elegir varias opciones, como CPU (valor predeterminado) frente a GPU, entrada real frente a entrada sintética (valor predeterminado), etc. El resultado de la evaluación del modelo aparece en la ventana de la consola de la parte inferior.
Tenga en cuenta que la característica de validación de modelos solo está disponible en la actualización de octubre de 2018 de Windows 10 o en una versión más reciente de Windows 10, ya que la herramienta se basa en el motor de inferencia de Windows ML integrado.
Depuración de una inferencia
Puedes utilizar la función de depuración del WinML Dashboard para obtener información sobre cómo los datos en bruto fluyen a través de los operadores de tu modelo. También puede elegir visualizar estos datos para la inferencia en visión por computadora.
Para depurar el modelo, siga estos pasos:
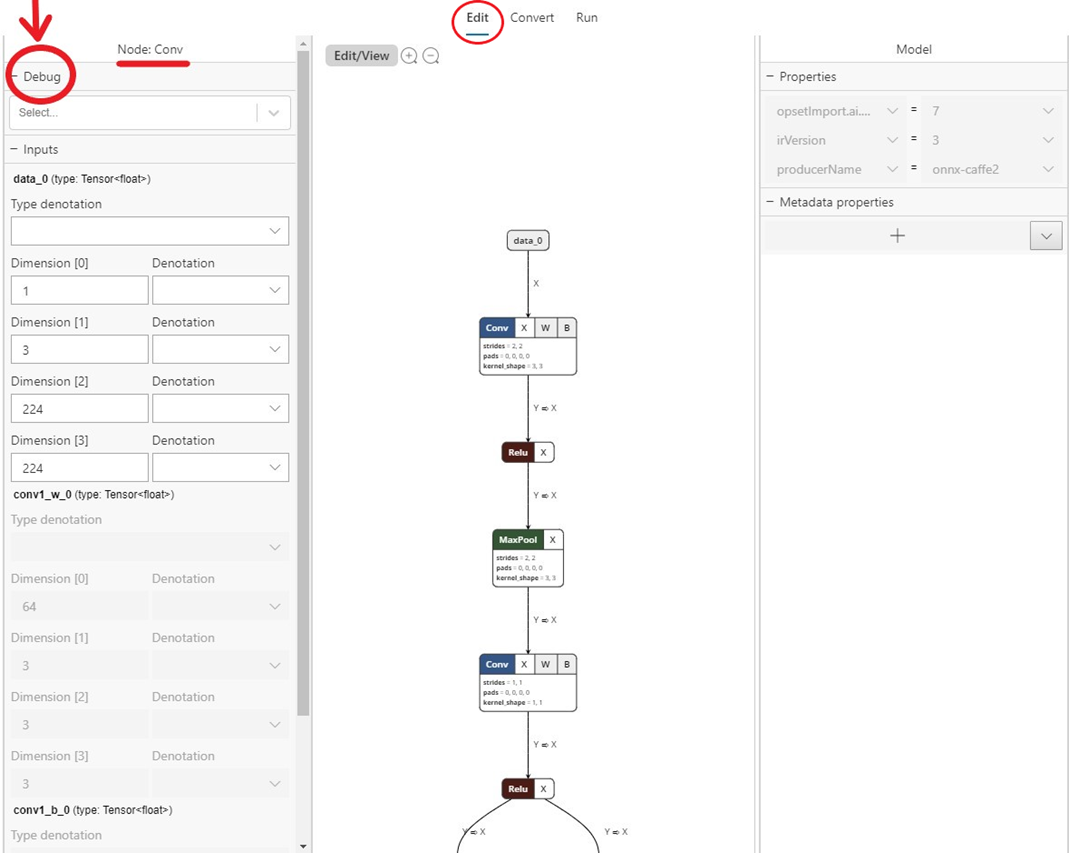
- Vaya a la
Editpestaña y seleccione el operador para el que desea capturar datos intermedios. En el panel izquierdo, habrá unDebugmenú donde puede seleccionar los formatos de los datos intermedios que desea capturar. Las opciones son actualmente texto y PNG. Text generará un archivo de texto que contiene las dimensiones, el tipo de datos y los datos de tensor sin procesar generados por este operador. PNG dará formato a estos datos en un archivo de imagen que puede ser útil para las aplicaciones de Computer Vision.
- Vaya a la
Runpestaña y seleccione el modelo que desea depurar. - Para el
Capturecampo, seleccioneDebugen la lista desplegable. - Seleccione una imagen o un archivo CSV de entrada para proporcionar a su modelo durante la ejecución. Tenga en cuenta que esto es necesario al capturar datos de Debug.
- Seleccione una carpeta de salida para exportar datos de depuración.
- Seleccione
Run. Una vez completada la ejecución, puede ir a esta carpeta seleccionada para ver la captura de depuración.
También puede abrir la vista de depuración en la aplicación Electron con una de las siguientes opciones:
- Ejecútela con
flag --dev-tools - O bien, seleccione
View -> Toggle Dev Toolsen el menú de la aplicación. - O presione
Ctrl + Shift + I.