Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En la fase anterior de este tutorial, adquirimos el conjunto de datos que usaremos para entrenar nuestro modelo de análisis de datos con PyTorch. Ahora es el momento de usar esos datos.
Para entrenar el modelo de análisis de datos con PyTorch, debe completar los pasos siguientes:
- Cargue los datos. Si ya ha realizado el paso anterior de este tutorial, ya tiene completado este paso.
- Defina una red neuronal.
- Defina una función de pérdida.
- Entrene el modelo en los datos de entrenamiento.
- Pruebe la red en los datos de prueba.
Definición de una red neuronal
En este tutorial, creará un modelo de red neuronal básico con tres capas lineales. La estructura del modelo es la siguiente:
Linear -> ReLU -> Linear -> ReLU -> Linear
Una capa lineal aplica una transformación lineal a los datos entrantes. Debe especificar el número de características de entrada y el número de características de salida que deben corresponder al número de clases.
Una capa ReLU es una función de activación que define que todas las características entrantes sean 0 o mayores. Por lo tanto, cuando se aplica una capa ReLU, cualquier número menor que 0 se cambia a cero, mientras que otros se mantienen iguales. Aplicaremos la capa de activación en las dos capas ocultas y no se activará en la última capa lineal.
Parámetros del modelo
Los parámetros del modelo dependen de nuestro objetivo y de los datos de entrenamiento. El tamaño de entrada depende del número de características que alimentamos el modelo: cuatro en nuestro caso. El tamaño de los resultados es tres, ya que hay tres tipos posibles de Iris.
Con tres capas lineales, (4,24) -> (24,24) -> (24,3), la red tendrá 744 pesos (96+576+72).
La tasa de aprendizaje (lr) establece el control de cuánto se ajustan los pesos de la red con respecto al gradiente de pérdida. Cuanto menor sea, más lento será el entrenamiento. En este tutorial, establecerá lr en 0.01.
¿Cómo funciona la red?
En este caso, crearemos una red de alimentación directa. Durante el proceso de entrenamiento, la red procesará la entrada a través de todas las capas, calculará las pérdidas para comprender cuánto se aleja la etiqueta predicha de la imagen de la etiqueta correcta y propagará los degradados de nuevo a la red para actualizar los pesos de las capas. Al realizar una iteración sobre un enorme conjunto de datos de entrada, la red "aprenderá" a establecer lo que pesa para lograr los mejores resultados.
Una función forward calcula el valor de la función de pérdida y una función hacia atrás calcula los degradados de los parámetros que se pueden aprender. Al crear nuestra red neuronal con PyTorch, solo tiene que definir la función de reenvío. La función de retroceso se definirá automáticamente.
- Copie el código siguiente en el
DataClassifier.pyarchivo de Visual Studio para definir los parámetros del modelo y la red neuronal.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
También deberá definir el dispositivo de ejecución en función del disponible en el equipo. PyTorch no tiene una biblioteca dedicada para GPU, pero puede definir manualmente el dispositivo de ejecución. El dispositivo será una GPU de Nvidia si existe en tu máquina, o tu CPU si no es así.
- Copie el código siguiente para definir el dispositivo de ejecución:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- Como último paso, defina una función para guardar el modelo:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Nota:
¿Le interesa obtener más información sobre la red neuronal con PyTorch? Consulte la documentación de PyTorch.
Defina una función de pérdida.
Una función de pérdida calcula un valor que calcula cuánto lejos está la salida del destino. El objetivo principal es reducir el valor de la función de pérdida cambiando los valores vectoriales de peso a través de la propiedad inversa en redes neuronales.
Tenga en cuenta que el valor de pérdida es diferente de la precisión del modelo. La función de pérdida representa cómo se comporta nuestro modelo después de cada iteración de optimización en el conjunto de entrenamiento. La precisión del modelo se calcula en los datos de prueba y muestra el porcentaje de predicciones correctas.
En PyTorch, el paquete de redes neuronales incluye varias funciones de pérdida que son bloques fundamentales para las redes neuronales profundas. Si desea obtener más información sobre estos detalles, comience con la nota anterior. En este caso, usaremos las funciones existentes como esta, que están optimizadas para la clasificación, y usaremos una función de pérdida de entropía cruzada de clasificación y un optimizador Adam. En el optimizador, la velocidad de aprendizaje (lr) establece el control de la cantidad en que ajustamos los pesos de nuestra red con respecto al gradiente de pérdida. Lo establecerá como 0,001 aquí, cuanto menor sea, más lento será el entrenamiento.
- Copie el código siguiente en el archivo
DataClassifier.pyde Visual Studio para definir la función de pérdida y un optimizador.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Entrene el modelo en los datos de entrenamiento.
Para entrenar el modelo, debe recorrer en bucle nuestro iterador de datos, alimentar las entradas a la red y optimizarla. Para validar los resultados, basta con comparar las etiquetas predichas con las etiquetas reales del conjunto de datos de validación después de cada época de entrenamiento.
El programa mostrará la pérdida de entrenamiento, la pérdida de validación y la precisión del modelo para cada época o para cada iteración completa sobre el conjunto de entrenamiento. Guardará el modelo con la mayor precisión y, después de 10 épocas, el programa mostrará la precisión final.
- Agregue el siguiente código al archivo
DataClassifier.py.
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Pruebe el modelo con los datos de prueba.
Ahora que hemos entrenado el modelo, podemos probarlo con el conjunto de datos de prueba.
Agregaremos dos funciones de prueba. La primera prueba el modelo que guardó en la parte anterior. Probará el modelo con el conjunto de datos de prueba de 45 elementos e imprimirá la precisión del modelo. La segunda es una función opcional para probar la confianza del modelo en la predicción de cada una de las tres especies de iris, representada por la probabilidad de una clasificación correcta de cada especie.
- Agregue el siguiente código al archivo
DataClassifier.py.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Por último, agregue el código principal. Esto iniciará el entrenamiento del modelo, guardará el modelo y mostrará los resultados en la pantalla. Ejecutaremos solo dos iteraciones [num_epochs = 25] en el conjunto de entrenamiento, por lo que el proceso de entrenamiento no tomará mucho tiempo.
- Agregue el siguiente código al archivo
DataClassifier.py.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
Ejecute la prueba. Asegúrese de que los menús desplegables de la barra de herramientas superior estén configurados a Debug. Cambie Solution Platform a x64 para ejecutar el proyecto en su equipo local si el dispositivo es de 64 bits o x86 si es de 32 bits.
- Para ejecutar el proyecto, haga clic en el
Start Debuggingbotón de la barra de herramientas o presioneF5.
Aparecerá la ventana de la consola y se mostrará el proceso de entrenamiento. Como lo definió, el valor de pérdida se imprimirá para cada época. La expectativa es que el valor de pérdida disminuya con cada bucle.
Una vez completado el entrenamiento, verá un resultado similar al siguiente. Los números no serán exactamente iguales: el entrenamiento depende de muchos factores y no siempre devolverá resultados identificales, pero deben tener un aspecto similar.
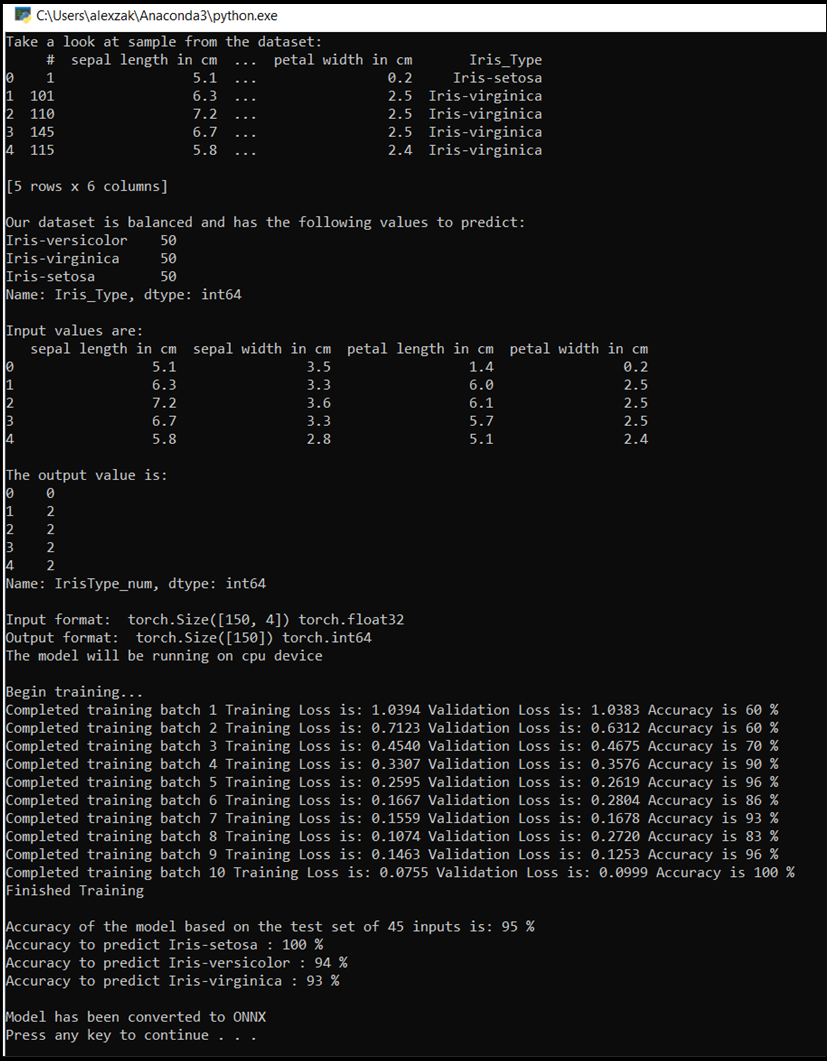
Pasos siguientes
Ahora que tenemos un modelo de clasificación, el siguiente paso es convertir el modelo al formato ONNX.