Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Integre el reconocimiento de voz y el texto a voz (también conocido como TTS o síntesis de voz) directamente en la experiencia del usuario de la aplicación.
Reconocimiento de voz El reconocimiento de voz convierte las palabras habladas por el usuario en texto para la entrada del formulario, para el dictado de texto, para especificar una acción o un comando y para realizar tareas. Admite gramáticas predefinidas para dictado de texto libre y búsqueda web, y gramáticas personalizadas creadas mediante la especificación de gramática de reconocimiento de voz (SRGS) versión 1.0.
Speech synthesis/Text to Speech (TTS) TTS usa un motor de síntesis de voz (voz) para convertir una cadena de texto en palabras habladas. La cadena de entrada puede ser texto básico, sin adornado o más complejo lenguaje de marcado de síntesis de voz (SSML). SSML proporciona una manera estándar de controlar las características de la salida de voz, como la pronunciación, el volumen, el tono, la velocidad y el énfasis.
Diseño de interacción de voz
Al diseñar e implementar la voz cuidadosamente, puede ser una forma eficaz, accesible y natural para que las personas interactúen con sus aplicaciones de Windows, complementando o incluso reemplazando las experiencias de interacción tradicionales en función de un mouse, teclado, controlador o toque.
Estas directrices y recomendaciones describen cómo integrar mejor el reconocimiento de voz y TTS en la experiencia de interacción de la aplicación.
Si estás considerando admitir interacciones de voz en tu aplicación, hazte las siguientes preguntas:
- ¿Qué acciones pueden realizar los usuarios a través de voz? ¿Pueden navegar entre páginas, invocar comandos o escribir datos como campos de texto, notas breves o mensajes largos?
- ¿La entrada de voz es una buena opción para completar una tarea?
- ¿Cómo sabe un usuario cuándo está disponible la entrada de voz?
- ¿La aplicación siempre escucha o el usuario necesita realizar una acción para que la aplicación entre en modo de escucha?
- ¿Qué frases inician una acción o comportamiento? ¿Deben enumerarse las frases y acciones en pantalla?
- ¿Se requieren pantallas de aviso, confirmación y desambiguación o TTS?
- ¿Cuál es el cuadro de diálogo de interacción entre la aplicación y el usuario?
- ¿Se requiere un vocabulario personalizado o restringido (como medicina, ciencia o configuración regional) para el contexto de la aplicación?
- ¿Se requiere conectividad de red?
Entrada de texto
La entrada de texto puede variar desde la entrada de formulario corto, como una sola palabra o frase, hasta la entrada de forma larga, como varias frases, párrafos o dictado continuo. La entrada de formulario corto suele ser inferior a 10 segundos de longitud, mientras que las sesiones de entrada de formulario largas pueden tener hasta dos minutos de longitud. La entrada de formulario largo puede reiniciarse sin intervención del usuario para dar la impresión de dictado continuo.
Proporcione una indicación visual para indicar que el reconocimiento de voz se admite y está disponible para el usuario y si el usuario necesita activarlo. Por ejemplo, use un botón de barra de comandos con un glifo de micrófono (consulte Barras de comandos) para mostrar tanto la disponibilidad como el estado.
Proporcione comentarios de reconocimiento continuos para minimizar cualquier falta aparente de respuesta mientras se realiza el reconocimiento.
Permitir que los usuarios revisen el texto de reconocimiento mediante la entrada del teclado, mensajes de desambiguación, sugerencias o reconocimiento de voz adicional.
Detenga el reconocimiento si se detecta la entrada desde un dispositivo distinto del reconocimiento de voz, como la entrada táctil o el teclado. Esta entrada probablemente indica que el usuario se ha movido a otra tarea, como corregir el texto de reconocimiento o interactuar con otros campos de formulario.
Especifique el período de tiempo durante el que ninguna entrada de voz indica que se ha terminado el reconocimiento. No reinicie automáticamente el reconocimiento después de este período de tiempo, ya que normalmente indica que el usuario ha dejado de interactuar con la aplicación.
En algunos casos, es posible que se requiera una conexión de red para admitir el reconocimiento de voz. Si no está disponible, deshabilite toda la interfaz de usuario de reconocimiento continuo y finalice la sesión de reconocimiento.
Comando
La entrada de voz puede iniciar acciones, invocar comandos y realizar tareas.
Si el espacio permite, considere la posibilidad de mostrar las respuestas admitidas para el contexto de la aplicación actual, con ejemplos de entrada válida. Este enfoque reduce las posibles respuestas que la aplicación necesita procesar y también elimina la confusión para el usuario.
Intente formular sus preguntas para obtener una respuesta lo más específica posible. Por ejemplo, "¿Qué quieres hacer hoy?" está muy abierto y requiere una definición gramatical muy grande debido a la variación de las respuestas. Como alternativa, "¿Desea reproducir un juego o escuchar música?" restringe la respuesta a una de las dos respuestas válidas con una definición gramatical correspondientemente pequeña. Una gramática pequeña es mucho más fácil de crear y da como resultado resultados de reconocimiento mucho más precisos.
Solicite confirmación del usuario cuando la confianza del reconocimiento de voz sea baja. Si la intención del usuario no está clara, es mejor obtener aclaración que iniciar una acción no deseada.
Proporcione una indicación visual para indicar que el reconocimiento de voz se admite y está disponible para el usuario y si el usuario necesita activarlo. Por ejemplo, use un botón de barra de comandos con un glifo de micrófono (consulte Directrices para barras de comandos) para mostrar tanto la disponibilidad como el estado.
Si el conmutador de reconocimiento de voz suele estar fuera de la vista, considere la posibilidad de mostrar un indicador de estado en el área de contenido de la aplicación.
Si el usuario inicia el reconocimiento, considere la posibilidad de usar la experiencia de reconocimiento integrada para la coherencia. La experiencia integrada incluye pantallas personalizables con mensajes, ejemplos, desambiguaciones, confirmaciones y errores.
Las pantallas varían en función de las restricciones especificadas:
Gramática predefinida (dictado o búsqueda web)
- Pantalla de escucha .
- La pantalla pensando .
- La pantalla Te escuchamos decir o la pantalla de error.
Lista de palabras o frases, o un archivo de gramática SRGS
- Pantalla de escucha .
- La pantalla ¿Dijiste si lo que dice el usuario puede interpretarse como más de un resultado potencial.
- La pantalla Te escuchamos decir o la pantalla de error.
En la pantalla Escucha , puede hacer lo siguiente:
- Personalice el texto del encabezado.
- Proporcione texto de ejemplo de lo que el usuario puede decir.
- Especifique si se muestra la pantalla Oyó que dice .
- Vuelva a leer la cadena reconocida al usuario en la pantalla Escuché que dijiste.
Las imágenes siguientes muestran un ejemplo del flujo de reconocimiento integrado para un reconocedor de voz que usa una restricción definida por SRGS. En este ejemplo, el reconocimiento de voz se realiza correctamente.
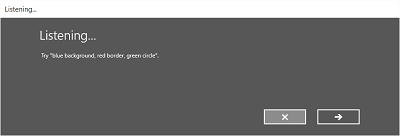
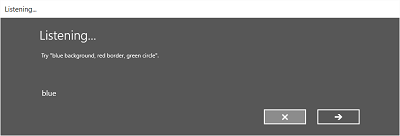
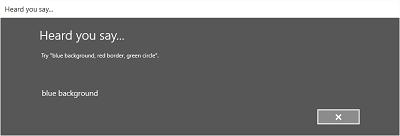
Siempre escuchando
La aplicación puede escuchar y reconocer la entrada de voz tan pronto como se inicie la aplicación, sin intervención del usuario.
Personalice las restricciones gramaticales en función del contexto de la aplicación. Este enfoque mantiene la experiencia de reconocimiento de voz muy dirigida y relevante para la tarea actual y minimiza los errores.
"¿Qué puedo decir?"
Al habilitar la entrada de voz, ayude a los usuarios a descubrir lo que la aplicación puede comprender y qué acciones puede realizar.
Si los usuarios habilitan el reconocimiento de voz, considere la posibilidad de usar la barra de comandos o un comando de menú para mostrar todas las palabras y frases admitidas en el contexto actual.
Si el reconocimiento de voz siempre está activado, considere la posibilidad de agregar la frase "¿Qué puedo decir?" a cada página. Cuando el usuario diga esta frase, muestre todas las palabras y frases admitidas en el contexto actual. El uso de esta frase proporciona una manera coherente de que los usuarios detecten funcionalidades de voz en todo el sistema.
Errores de reconocimiento
El reconocimiento de voz puede producir un error. Los errores se producen cuando la calidad del audio es deficiente, cuando el reconocedor detecta solo parte de una frase o cuando el reconocedor no detecta ninguna entrada.
Controle los errores correctamente, ayude al usuario a comprender por qué se produjo un error en el reconocimiento y recuperarse.
La aplicación debe informar al usuario de que el reconocedor no los entendió y que necesitan volver a intentarlo.
Considere la posibilidad de proporcionar ejemplos de una o varias frases admitidas. Es probable que el usuario repita una frase sugerida, lo que aumenta el éxito del reconocimiento.
Muestra una lista de posibles coincidencias entre las que el usuario debe seleccionar. Este enfoque puede ser mucho más eficaz que volver a pasar por el proceso de reconocimiento.
Siempre admite tipos de entrada alternativos, lo que resulta especialmente útil para controlar errores de reconocimiento repetidos. Por ejemplo, podría sugerir que el usuario intente usar un teclado, o usar la función táctil o un mouse para seleccionar una lista de posibles coincidencias.
Use la experiencia integrada de reconocimiento de voz, ya que incluye pantallas que informan al usuario de que el reconocimiento no se realizó correctamente y permite al usuario realizar otro intento de reconocimiento.
Escuche e intente corregir problemas en la entrada de audio. El reconocedor de voz puede detectar problemas con la calidad de audio que podría afectar negativamente a la precisión del reconocimiento de voz. Puede usar la información proporcionada por el reconocedor de voz para informar al usuario del problema y permitirle tomar medidas correctivas, si es posible. Por ejemplo, si la configuración del volumen en el micrófono es demasiado baja, puede pedir al usuario que hable más fuerte o activar el volumen.
Limitaciones
Las restricciones o gramáticas definen las palabras y las frases pronunciadas que el reconocedor de voz puede reconocer. Puede especificar una de las gramáticas de servicio web predefinidas o puede crear una gramática personalizada que instale con la aplicación.
Gramáticas predefinidas
Las gramáticas predefinidas de dictado y búsqueda web proporcionan reconocimiento de voz para la aplicación sin necesidad de crear una gramática. Cuando se usan estas gramáticas, un servicio web remoto realiza el reconocimiento de voz y devuelve los resultados al dispositivo.
- La gramática de dictado de texto libre predeterminada reconoce la mayoría de las palabras y frases que un usuario puede decir en un idioma determinado. Está optimizado para reconocer frases cortas. Use dictado de texto libre cuando no quiera limitar los tipos de cosas que un usuario puede decir. Los usos típicos incluyen la creación de notas o el dictado del contenido de un mensaje.
- La gramática de búsqueda web, como una gramática de dictado, contiene un gran número de palabras y frases que un usuario podría decir. Sin embargo, está optimizado para reconocer términos que las personas suelen usar al buscar en la web.
Nota:
Dado que los dictados predefinidos y las gramáticas de búsqueda web pueden ser grandes y, dado que están en línea (no en el dispositivo), es posible que el rendimiento no sea tan rápido como con una gramática personalizada instalada en el dispositivo.
Estas gramáticas predefinidas pueden reconocer hasta 10 segundos de entrada de voz y no requieren ningún esfuerzo de creación. Sin embargo, requieren conexión a una red.
Gramáticas personalizadas
Diseñe y cree una gramática personalizada e instálela con la aplicación. El dispositivo realiza el reconocimiento de voz mediante una restricción personalizada.
Las restricciones de lista mediante programación proporcionan un enfoque ligero para crear gramáticas simples mediante una lista de palabras o frases. Una restricción de lista funciona bien para reconocer frases cortas y distintas. Especificar explícitamente todas las palabras de una gramática también mejora la precisión del reconocimiento, ya que el motor de reconocimiento de voz solo debe procesar la voz para confirmar una coincidencia. También puede actualizar la lista mediante programación.
Una gramática SRGS es un documento estático que, a diferencia de una restricción de lista mediante programación, usa el formato XML definido por la versión 1.0 de SRGS. Una gramática SRGS proporciona el mayor control sobre la experiencia de reconocimiento de voz al permitirle capturar varios significados semánticos en un solo reconocimiento.
Estas son algunas sugerencias para crear gramáticas SRGS:
- Mantenga cada gramática pequeña. Las gramáticas que contienen menos frases tienden a proporcionar un reconocimiento más preciso que las gramáticas más grandes que contienen muchas frases. Es mejor tener varias gramáticas más pequeñas para escenarios específicos que tener una única gramática para toda la aplicación.
- Indique a los usuarios qué decir para cada contexto de aplicación y habilite y deshabilite las gramáticas según sea necesario.
- Diseñe cada gramática para que los usuarios puedan hablar un comando de varias maneras. Por ejemplo, use la regla GARBAGE para hacer coincidir la entrada de voz que su gramática no define. Esta regla permite a los usuarios hablar palabras adicionales que no tienen ningún significado para la aplicación. Por ejemplo, "dame", "y", "uh", "tal vez", etc.
- Use el elemento sapi:subconjunto para ayudar a buscar coincidencias con la entrada de voz. Este elemento es una extensión de Microsoft a la especificación SRGS para ayudar a hacer coincidir frases parciales.
- Intente evitar definir frases en la gramática que contengan solo una sílaba. El reconocimiento tiende a ser más preciso para las frases que contienen dos o más sílabas.
- Evite usar frases que suenan similares. Por ejemplo, las frases como "hello", "bellow" y "fellow" pueden confundir el motor de reconocimiento y dar lugar a una precisión de reconocimiento deficiente.
Nota:
El tipo de restricción que use depende de la complejidad de la experiencia de reconocimiento que desea crear. Cualquier tipo podría ser la mejor opción para una tarea de reconocimiento específica y podrías encontrar usos para todos los tipos de restricciones de la aplicación.
Pronunciaciones personalizadas
Si la aplicación contiene vocabulario especializado con palabras inusuales o ficticias, o palabras con pronunciaciones poco frecuentes, es posible que puedas mejorar el rendimiento del reconocimiento de esas palabras definiendo pronunciaciones personalizadas.
Para obtener una pequeña lista de palabras y frases, o una lista de palabras y frases usadas con poca frecuencia, cree pronunciaciones personalizadas en una gramática SRGS. Consulta token Element para obtener más información.
Para obtener listas más grandes de palabras y frases, o palabras y frases usadas con frecuencia, cree documentos de léxico de pronunciación independientes. Para obtener más información, consulta Acerca de los lexicons y los alfabetos fonéticos .
Testing
Pruebe la precisión del reconocimiento de voz y cualquier interfaz de usuario compatible con la audiencia de destino de la aplicación. Este enfoque le ayuda a determinar la eficacia de la experiencia de interacción de voz en la aplicación. Por ejemplo, ¿los usuarios obtienen resultados de reconocimiento deficientes porque la aplicación no escucha una frase común?
Modifique la gramática para admitir esta frase o proporcione a los usuarios una lista de frases admitidas. Si ya proporciona la lista de frases admitidas, asegúrese de que los usuarios puedan encontrarlo fácilmente.
Texto a voz (TTS)
TTS genera la salida de voz a partir de texto plano o SSML.
Intenta diseñar mensajes que son amables y animados.
Tenga en cuenta si debe leer cadenas largas de texto. Es una cosa escuchar un mensaje de texto, pero otro para escuchar una larga lista de resultados de búsqueda que son difíciles de recordar.
Proporcione controles multimedia para permitir a los usuarios pausar o detener TTS.
Escuche todas las cadenas de TTS para asegurarse de que sean inteligibles y suenen naturales.
- Al encadenar una secuencia inusual de palabras, números de parte o signos de puntuación, podría provocar que una frase se vuelva ininteligible.
- La voz puede sonar no natural cuando la prosodia o cadencia es diferente de la forma en que un hablante nativo diría una frase.
Puede solucionar ambos problemas mediante SSML en lugar de texto sin formato como entrada en el sintetizador de voz. Para obtener más información sobre SSML, consulte Usar SSML para controlar el habla sintetizada y Referencia del Lenguaje de Marcado de Síntesis de Voz.