Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Tradicionalmente, tener un sistema monolítico que se ejecuta en varios equipos significaba dividir el sistema en componentes de cliente y servidor independientes. En estos sistemas, el componente cliente controló la interfaz de usuario y el servidor proporcionó procesamiento back-end, como el acceso a la base de datos, la impresión, etc. A medida que los ordenadores proliferaban, bajaban en costo y se conectaban por redes de ancho de banda cada vez más altas, resultaba más conveniente dividir los sistemas de software en varios componentes, cada uno ejecutándose en un ordenador diferente y realizando una función especializada. Este enfoque ha simplificado el desarrollo, la administración, la administración y a menudo ha mejorado el rendimiento y la solidez, ya que los errores de un equipo no necesariamente deshabilitan todo el sistema.
En muchos casos, el sistema parece al cliente como una nube opaca que realiza las operaciones necesarias, aunque el sistema distribuido se compone de nodos individuales, como se muestra en la ilustración siguiente.
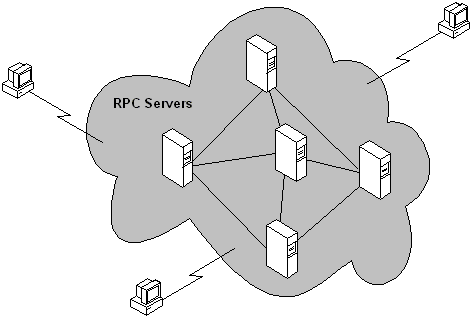
La opacidad de la nube se mantiene porque las operaciones informáticas se invocan en nombre del cliente. Por lo tanto, los clientes pueden localizar un equipo (un nodo de ) dentro de la nube y solicitar una operación determinada; para realizar la operación, ese equipo puede invocar la funcionalidad en otros equipos de la nube sin exponer los pasos adicionales, o el equipo en el que se llevaron a cabo, al cliente.
Con este paradigma, la mecánica de un sistema distribuido, similar a la nube se puede dividir en muchos intercambios de paquetes individuales o conversaciones entre nodos individuales.
Los sistemas tradicionales de servidor cliente tienen dos nodos con roles fijos y responsabilidades. Los sistemas distribuidos modernos pueden tener más de dos nodos y sus roles suelen ser dinámicos. En una conversación, un nodo puede ser un cliente, mientras que en otra conversación el nodo puede ser el servidor. En muchos casos, el consumidor final de la funcionalidad expuesta es un cliente con un usuario sentado en un teclado, viendo la salida. En otros casos, el sistema distribuido funciona desatendido y realiza operaciones en segundo plano.
Es posible que el sistema distribuido no tenga clientes y servidores dedicados para cada intercambio de paquetes concreto, pero es importante recordar que hay un autor de llamada (o iniciador, cualquiera de los cuales se conoce a menudo como cliente). También hay el destinatario de la llamada (a menudo denominado servidor). No es necesario tener intercambios de paquetes bidireccionales en el formato de solicitud-respuesta de un sistema distribuido; a menudo, los mensajes solo se envían de una manera.