Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se explica cómo usar la computación sin servidor para notebooks. Para obtener información sobre el uso del proceso sin servidor para trabajos, consulte Ejecución de trabajos de Lakeflow con proceso sin servidor para flujos de trabajo.
Para obtener información sobre cómo usar cómputo sin servidor en cuadernos, consulte Precios de Databricks.
Requisitos
- Su área de trabajo debe estar habilitada para Unity Catalog.
- El área de trabajo debe estar en una región admitida para la computación sin servidor.
Adjuntar un notebook a recursos de computación sin servidor
Si el área de trabajo está habilitada para la computación interactiva sin servidor, todos los usuarios del área de trabajo tienen acceso a la computación sin servidor para cuadernos. No se requieren permisos adicionales.
Para adjuntar al cómputo sin servidor, haga clic en el menú desplegable de cómputo en el cuaderno y seleccione Sin Servidor. En el caso de los cuadernos nuevos, el proceso adjunto pasa automáticamente al modo sin servidor cuando se ejecuta el código si no se ha seleccionado ningún otro recurso.
Visualización de información de consulta
El cómputo sin servidor para cuadernos y trabajos usa insights de consulta para evaluar el rendimiento de la ejecución de Spark. Después de ejecutar una celda en un cuaderno, puede ver las conclusiones relacionadas con las consultas SQL y Python haciendo clic en el vínculo Ver rendimiento.
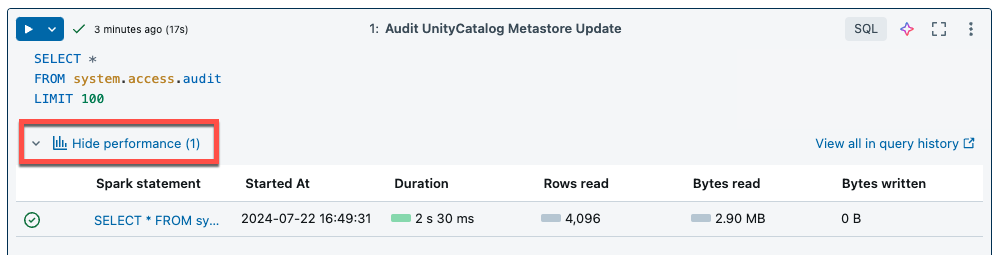
Puede hacer clic en cualquiera de las instrucciones de Spark para ver las métricas de consulta. Desde allí puede hacer clic en Ver perfil de consulta para ver una visualización de la ejecución de la consulta. Para más información sobre los perfiles de consulta, consulte Perfil de consulta.
Nota:
Para ver conclusiones de rendimiento de las ejecuciones de trabajos, vea Visualización de conclusiones de consulta de ejecución de trabajos.
Historial de consultas
Todas las consultas que se realicen en el cómputo sin servidor serán registradas también en la página del historial de consultas del área de trabajo. Para obtener información sobre el historial de consultas, consulte Historial de consultas.
Limitaciones de información de consultas
- El perfil de consulta solo está disponible una vez finalizada la ejecución de la consulta.
- Las métricas se actualizan en directo aunque el perfil de consulta no se muestra durante la ejecución.
- Solo se cubren los siguientes estados de consulta: EN EJECUCIÓN, CANCELADO, FALLIDO, FINALIZADO.
- No se pueden cancelar las consultas en ejecución desde la página del historial de consultas. Se pueden cancelar en cuadernos o trabajos.
- Las métricas detalladas no están disponibles.
- La descarga del perfil de consulta no está disponible.
- El acceso a la interfaz de usuario de Spark no está disponible.
- El texto de la instrucción solo contiene la última línea que se ejecutó. Sin embargo, puede haber varias líneas anteriores a esta línea que se ejecutaron como parte de la misma instrucción.
Protección contra exceso de gasto en arquitectura sin servidor
Para controlar las consultas de ejecución prolongada, los cuadernos sin servidor tienen un tiempo de espera de ejecución predeterminado de 2,5 horas. Puede establecer manualmente la duración del tiempo de espera mediante la configuración spark.databricks.execution.timeout en el cuaderno. Consulte Configuración de las propiedades de Spark para cuadernos y trabajos sin servidor.