Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta característica está en versión preliminar pública.
En esta página se describe cómo usar la clasificación de datos de Databricks en el catálogo de Unity para clasificar y etiquetar automáticamente datos confidenciales en el catálogo.
Los catálogos de datos pueden tener una gran cantidad de datos, a menudo que contienen datos confidenciales conocidos y desconocidos. Es fundamental que los equipos de datos comprendan qué tipo de datos confidenciales existe en cada tabla para que puedan gobernar y democratizar el acceso a estos datos.
Para solucionar este problema, La clasificación de datos de Databricks usa un agente de INTELIGENCIA ARTIFICIAL para clasificar y etiquetar automáticamente tablas en el catálogo. Esto le permite detectar datos confidenciales y aplicar controles de gobernanza sobre los resultados, mediante herramientas como el control de acceso basado en atributos (ABAC) de Unity Catalog. Para obtener una lista de las etiquetas admitidas, consulte Etiquetas de clasificación admitidas.
Con esta característica, puede:
- Clasificar datos: el motor usa un sistema de IA agente para clasificar y etiquetar automáticamente las tablas en el catálogo de Unity.
- Optimización del costo a través del análisis inteligente: el sistema determina de forma inteligente cuándo examinar los datos mediante el catálogo de Unity y el motor de inteligencia de datos. Esto significa que el examen es incremental y optimizado para asegurarse de que todos los datos nuevos se clasifican sin configuración manual.
- Revisar y proteger datos confidenciales: la visualización de los resultados le ayuda a ver los resultados de clasificación y a proteger los datos confidenciales mediante el etiquetado y la creación de directivas de control de acceso para cada clase.
Importante
La clasificación de datos de Databricks usa el almacenamiento predeterminado para almacenar los resultados de clasificación. No se le factura el almacenamiento.
La clasificación de datos de Databricks usa un modelo de lenguaje grande (LLM) para ayudar con la clasificación.
Requisitos
Nota:
La clasificación de datos es una característica de versión preliminar de nivel de área de trabajo y solo puede administrarla un administrador de área de trabajo o cuenta. Para obtener instrucciones, consulte Administración de versiones preliminares de Azure Databricks.
- El entorno de trabajo debe tener disponible la computación sin servidor (habilitada de forma predeterminada en entornos de trabajo con el catálogo de Unity).
- Para habilitar la clasificación de datos, debe poseer el catálogo o tener privilegios de
USE CATALOGyMANAGEsobre él. - Para habilitar el etiquetado automático para un catálogo, debe tener
USE CATALOGen el catálogo,APPLY TAGen el catálogo yASSIGNen la etiqueta que se está aplicando. - Para ver los resultados de clasificación en la interfaz de usuario, debe tener
USE CATALOGyMANAGEo (SELECT+USE SCHEMA) en el catálogo. Para ver los valores de ejemplo asociados a las detecciones, debe tenerSELECTen la tabla del sistema de resultados.
Nota:
De forma predeterminada, solo los administradores de cuentas tienen permisos MANAGE y ASSIGN sobre etiquetas controladas por el sistema de clasificación de datos. Los administradores de cuentas pueden conceder MANAGE y ASSIGN para etiquetas controladas individuales a otros usuarios, entidades de servicio o grupos. Consulte Administración de permisos en etiquetas reguladas.
Uso de la clasificación de datos
Puede habilitar la clasificación de datos para varios catálogos a la vez desde la página de resultados o configurar catálogos individuales con un control de nivel de esquema más granular.
Habilitación de varios catálogos
- En la página Resultados de clasificación de datos, haga clic en Configurar.
- Seleccione los catálogos que desea habilitar o seleccione todos los catálogos disponibles en el área de trabajo.
- Haga clic en Habilitar.
La habilitación de todos los catálogos disponibles no habilita automáticamente los catálogos futuros. Para clasificar un nuevo catálogo, vuelva al cuadro de diálogo Configurar y habilitelo.
Habilitación de un único catálogo con selección de esquema
Para elegir esquemas específicos dentro de un catálogo:
Vaya al catálogo y haga clic en la pestaña Detalles .
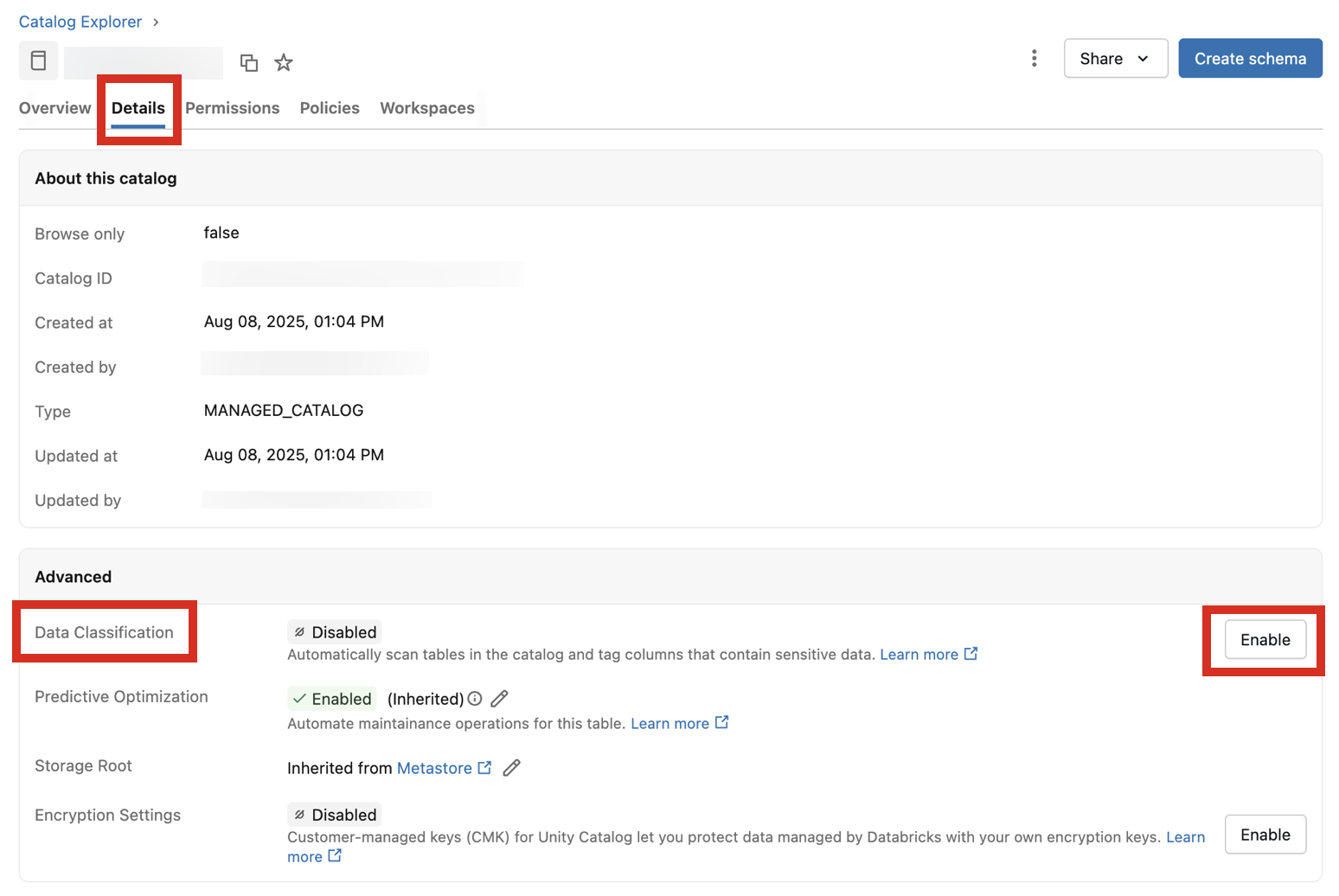
Junto a Clasificación de datos, haga clic en el botón Habilitar .
Aparece el diálogo de Clasificación de datos. De forma predeterminada, se incluyen todos los esquemas. Para incluir solo algunos esquemas, selecciónelos en el menú desplegable Esquemas para incluir . También puede seleccionar una directiva de uso.
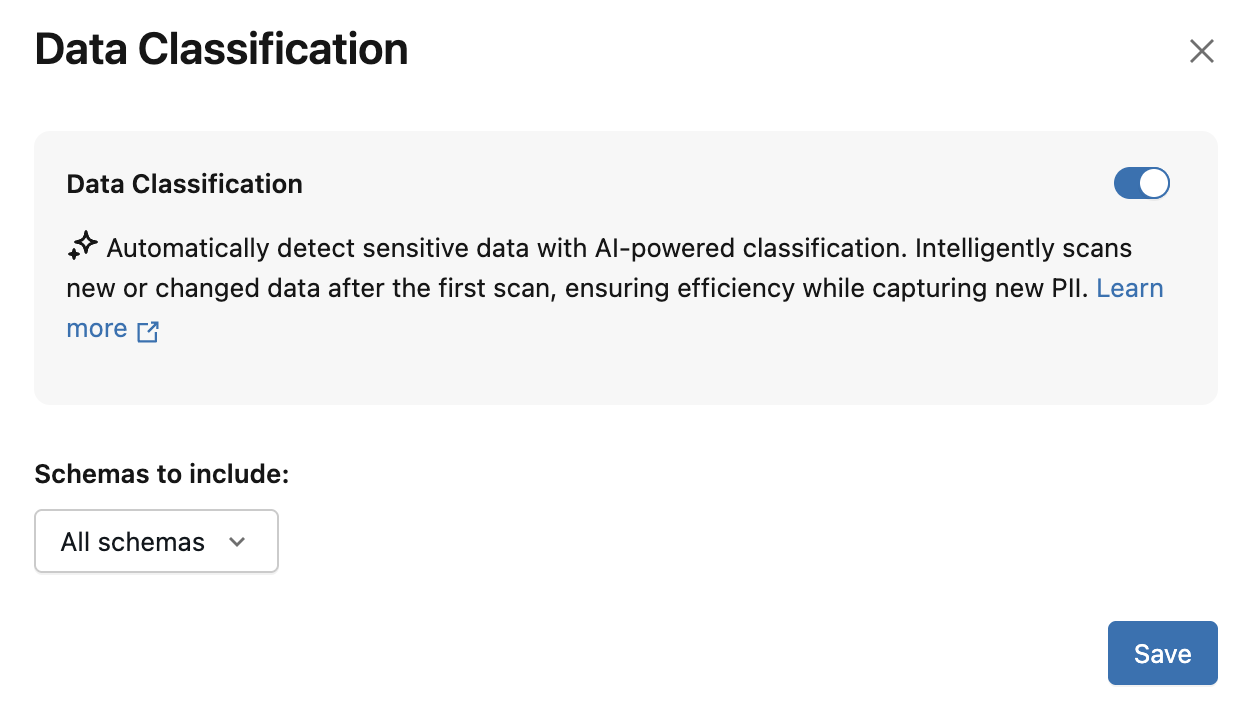
Haz clic en Guardar.
Esto crea un trabajo en segundo plano que examina incrementalmente todas las tablas del catálogo o esquemas seleccionados.
El motor de clasificación se basa en el examen inteligente para determinar cuándo examinar una tabla. Las nuevas tablas y columnas de un catálogo normalmente se examinan en un plazo de 24 horas a partir de la creación.
Visualización de los resultados de la clasificación
Para ver los resultados de la clasificación, haga clic en Ver resultados junto a la configuración Clasificación de datos .
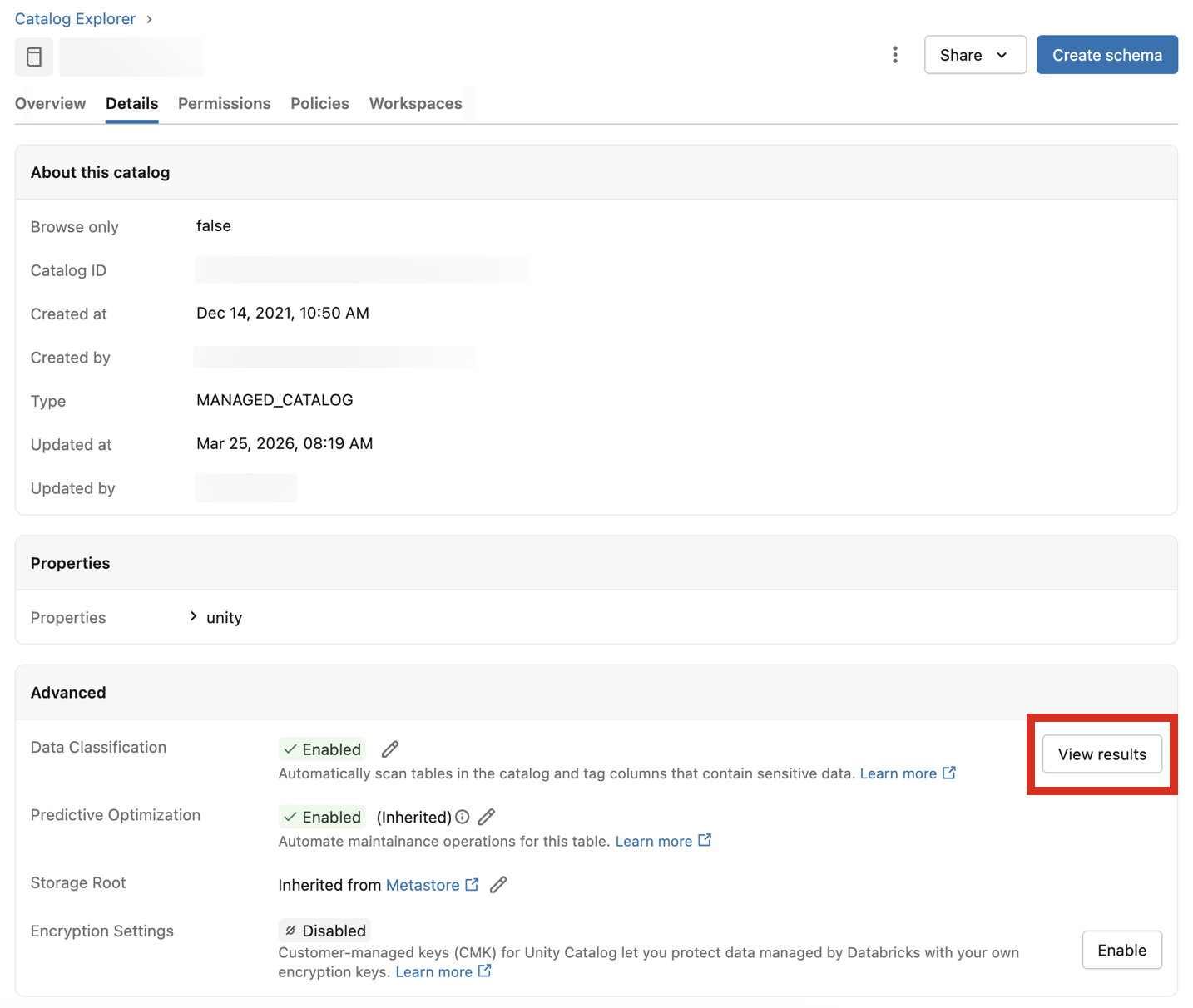
Se abrirá la interfaz de usuario de clasificación de datos del catálogo. Para ver los resultados de la clasificación, se requiere un almacenamiento de SQL sin servidor.
También puede ver los resultados agregados en todos los catálogos clasificados de la metastore mediante el selector de catálogos situado en la esquina superior izquierda. Elija Todos los catálogos en el menú desplegable.
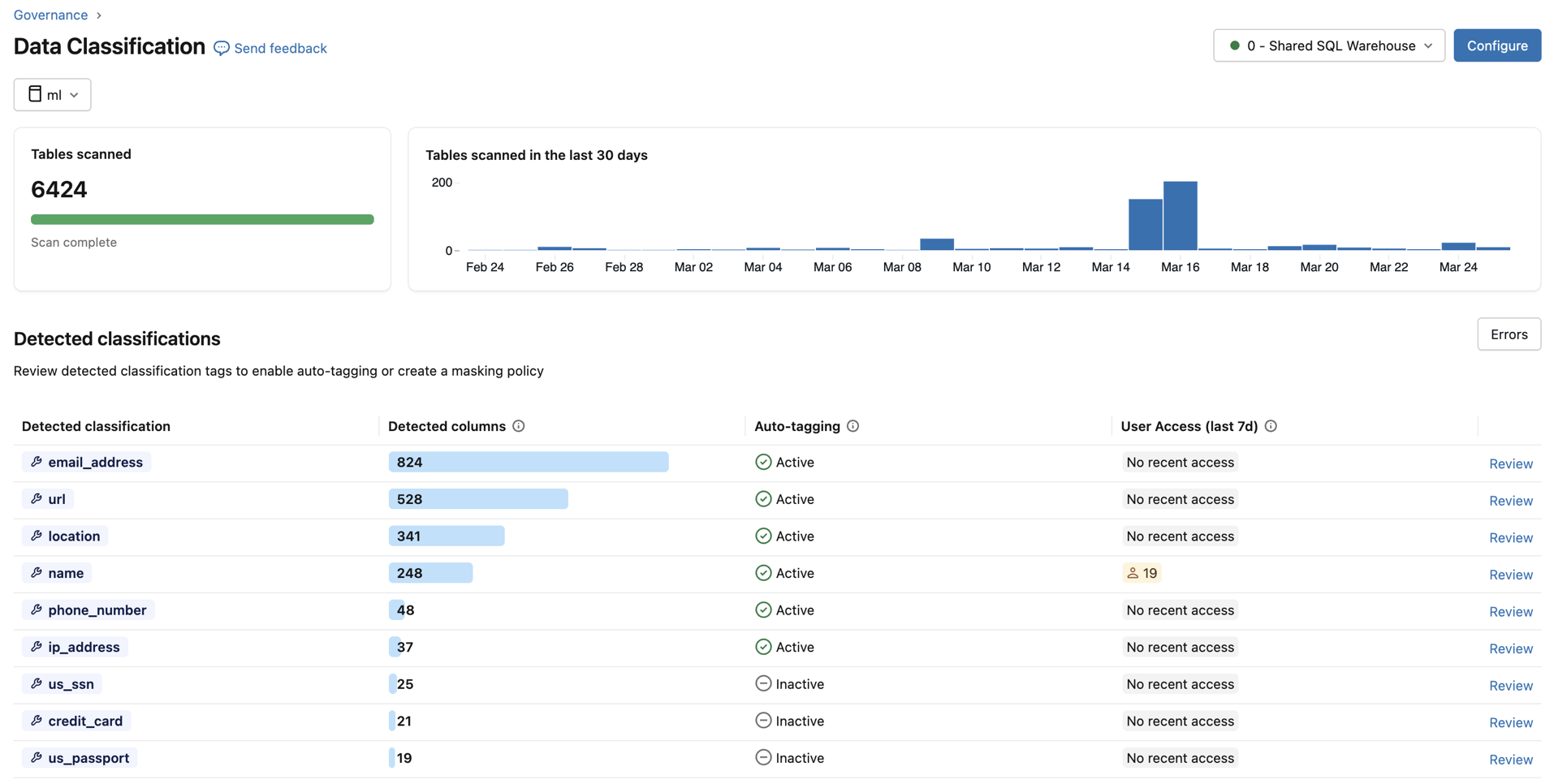
Para cada tipo de clasificación, la tabla muestra:
- Columnas detectadas: número de columnas donde se detectó la clasificación.
- Etiquetado automático: el estado de etiquetado de esa clasificación: activo o inactivo. En la vista de metastore, un estado de Parcialmente activo indica que el etiquetado está habilitado en algunos, pero no en todos los catálogos.
- Acceso de usuarios (últimos 7d): El número de usuarios distintos que accedieron a datos sin enmascarar en comparación con datos enmascarados de esa clasificación en los últimos 7 días. Úselo para evaluar la exposición de datos confidenciales en toda la organización.
Revisión de detecciones
Para revisar los resultados de un tipo de clasificación específico, haga clic en Revisar en la columna situada más a la derecha. Aparece un panel con dos pestañas:
- Columnas detectadas: muestra las columnas en las que se detectó la etiqueta de clasificación con alta confianza, ordenadas por la detección más reciente primero. También incluye un gráfico Detecciones a lo largo del tiempo y una lista de columnas detectadas con valores de ejemplo. Haga clic en cualquier barra del gráfico para ver las detecciones específicas de esa fecha. Los valores de ejemplo solo aparecen si tiene los permisos necesarios para ver los resultados de clasificación.
- Acceso de usuarios: enumera a todos los usuarios que accedieron a columnas con esta etiqueta de clasificación, mostrando su correo electrónico y su nombre de usuario junto con si tienen acceso enmascarado o desmascarado. También se muestran las directivas de control de acceso (ABAC) basadas en atributos asignadas a esta etiqueta de clasificación. Al ver los resultados de un único catálogo, puede crear una nueva directiva de ABAC directamente desde el panel.
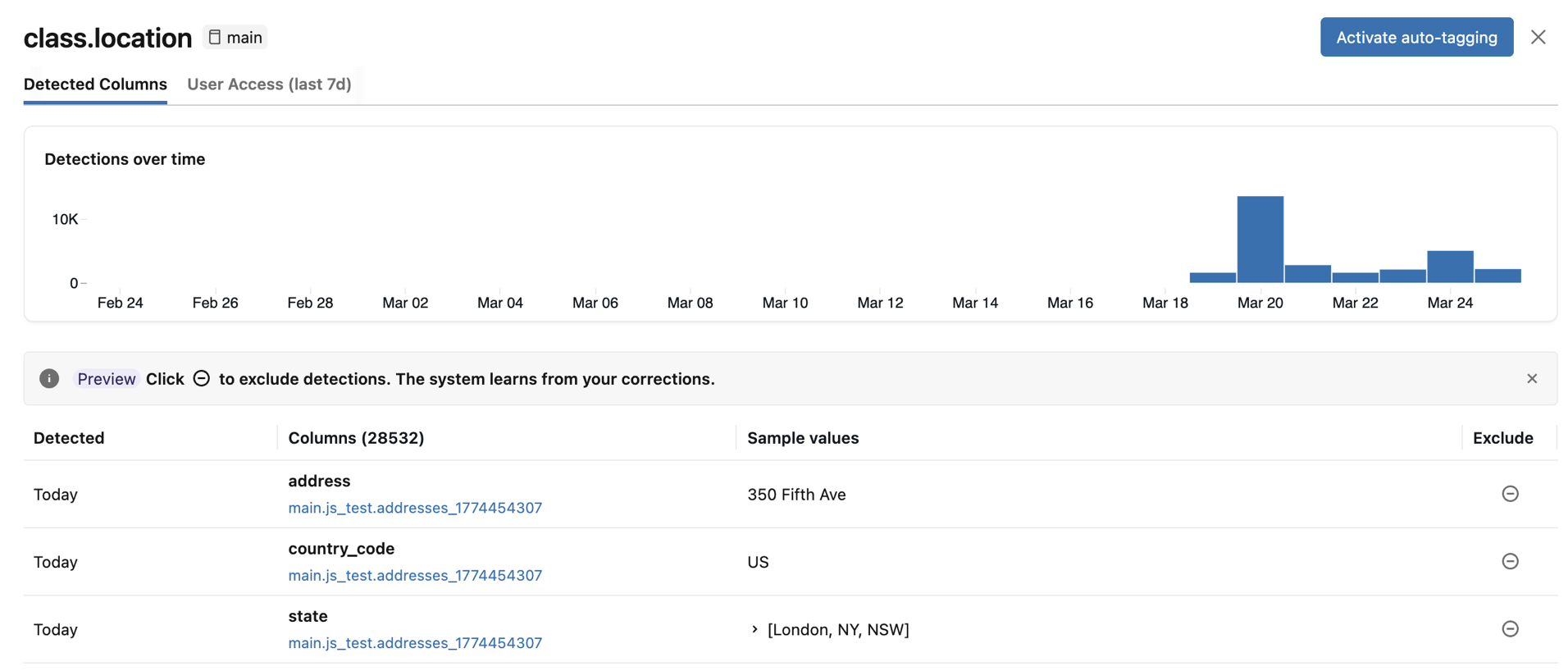
Si alguna columna detectada es incorrecta, puede hacer clic en el icono Excluir situado a la derecha de la entrada. Ver Excluir detecciones.
Habilitación del etiquetado automático
Si las columnas identificadas coinciden con sus expectativas, puede habilitar el etiquetado automático para la etiqueta de clasificación. Cuando se habilita el etiquetado automático, se etiquetan todas las detecciones existentes y futuras de esta clasificación.
Puede configurar el etiquetado automático en dos niveles:
-
Nivel de metastore: Activación o desactivación en todos los catálogos a la vez. Debe ser un administrador del metastore y tener
ASSIGNen la etiqueta que se aplica. -
Nivel del catálogo: habilite o deshabilite para el catálogo actual solamente. La configuración a nivel de catálogo tiene prioridad sobre la configuración a nivel de metastore. Debe tener
USE CATALOGyAPPLY TAGen el catálogo, yASSIGNen la etiqueta que se va a aplicar.
En el nivel de catálogo, el etiquetado automático tiene tres estados:
- Valor predeterminado (heredado): el catálogo hereda la configuración de etiquetado del nivel de metastore.
- Activo: el etiquetado está habilitado explícitamente para este catálogo, independientemente de la configuración de nivel de metastore.
- Inactivo: el etiquetado está deshabilitado explícitamente para este catálogo, independientemente de la configuración de nivel de metastore.
Al deshabilitar el etiquetado, no se aplica ninguna etiqueta futura, pero no se quitan las etiquetas existentes.
Nota:
Al habilitar el etiquetado automático, las etiquetas no se rellenan inmediatamente. Se rellenarán en el siguiente escaneo, que debe entrar en vigor en un plazo de 24 horas. Las clasificaciones posteriores se etiquetarán inmediatamente.
Exclusión de detecciones
Importante
Las exclusiones de detección y su uso para mejorar la precisión futura de la clasificación se encuentran en Beta.
En el panel de revisión, puede excluir detecciones de columnas individuales. Exclusión de una detección:
- Quita cualquier etiqueta de clasificación existente de esa columna.
- Impide que los escaneos futuros vuelvan a aplicar la etiqueta a esa columna.
- Proporciona comentarios que mejoran la precisión de los resultados de clasificación futuros.
Para excluir una detección, haga clic en el icono Excluir de la columna correspondiente en el panel de revisión. Para volver a incluir la detección, haga clic de nuevo en el icono.
La tabla del sistema de resultados
La clasificación de datos crea una tabla del sistema denominada system.data_classification.results para almacenar los resultados que, de forma predeterminada, solo son accesibles para el administrador de la cuenta. El administrador de la cuenta puede compartir esta tabla. La tabla solo es accesible cuando se utiliza computación sin servidor. Para obtener más información sobre esta tabla, consulte Referencia de tabla del sistema de clasificación de datos.
Importante
La tabla system.data_classification.results de resultados contiene todos los resultados de clasificación en todo el metastore e incluye valores de ejemplo de tablas de cada catálogo. Debe compartir esta tabla únicamente con usuarios que tengan privilegios para ver los resultados de clasificación de todo el metastore, incluidos los valores de muestra.
Los usuarios con SELECT acceso a esta tabla también pueden ver valores de ejemplo asociados a detecciones en la página resultados de clasificación de datos.
Configuración de controles de gobernanza basados en los resultados de clasificación de datos
Enmascarar datos confidenciales mediante una directiva de ABAC
Databricks recomienda usar el control de acceso basado en atributos (ABAC) de Unity Catalog para crear controles de gobernanza basados en los resultados de la clasificación de datos.
Para crear una directiva desde la página resultados de clasificación de datos, haga clic en Revisar para obtener una etiqueta de clasificación, abra la pestaña Acceso de usuario y haga clic en Nueva directiva. El formulario de directiva se rellena previamente para enmascarar columnas con la etiqueta de clasificación que se está revisando. Para enmascarar los datos, especifique cualquier función de enmascaramiento registrada en el catálogo de Unity y haga clic en Guardar.
También puede crear una directiva que abarque varias etiquetas de clasificación al cambiar Cuando la columna a cumpla la condición y proporcionando varias etiquetas.
Por ejemplo, para crear una directiva denominada "Confidencial", que enmascara cualquier nombre, correo electrónico o número de teléfono, establezca la condición has_tag("class.name") OR has_tag("class.email_address") OR has_tag("class.phone_number") en .
Detección y eliminación del RGPD
En este cuaderno de ejemplo se muestra cómo puede usar la clasificación de datos para ayudar con la detección y eliminación de datos para el cumplimiento del RGPD.
Detección y eliminación del RGPD mediante el cuaderno de clasificación de datos
Cómo controlar etiquetas incorrectas
Si una clasificación es incorrecta, excluya la detección del panel de revisión. Al excluir una detección, se quita la etiqueta , se evita que se vuelva a aplicar y se mejora la precisión de los exámenes futuros. Consulte Excluir detecciones.
Errores de escaneo
Si se producen errores durante el examen, aparece un botón Errores en la esquina superior derecha de la tabla de resultados.
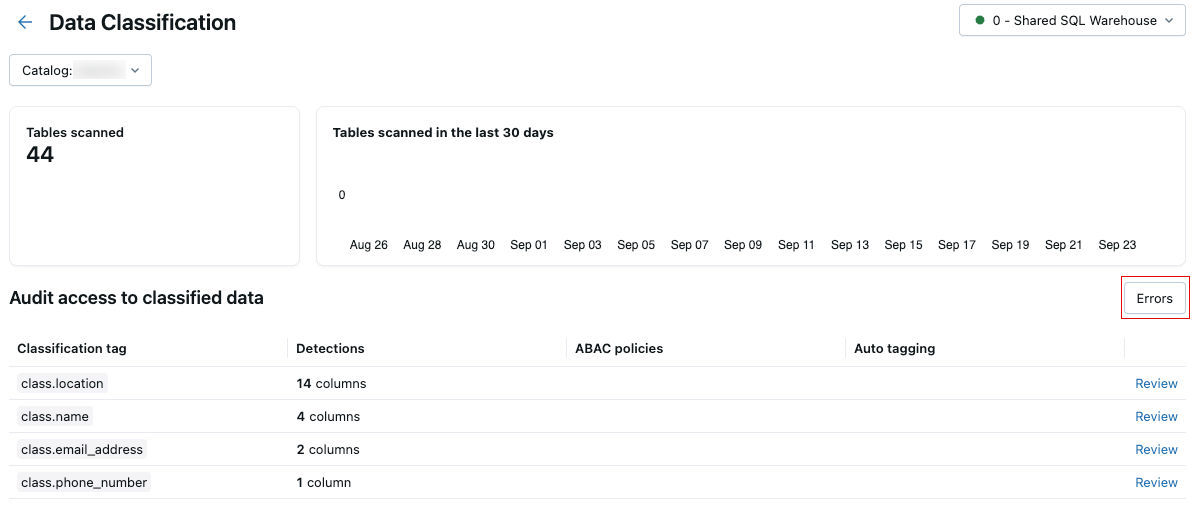
Haga clic en el botón para mostrar las tablas que han producido un error en el examen y los mensajes de error asociados.

De forma predeterminada, los errores que se produjeron para las tablas individuales se omiten y se reintentan el día siguiente.
Ver los gastos de clasificación de datos
Para comprender cómo se factura la clasificación de datos, consulte la página de precios. Puede ver los gastos relacionados con la clasificación de datos ejecutando una consulta o viendo el panel de uso.
Nota:
El examen inicial es más costoso que los exámenes posteriores en el mismo catálogo, ya que esos exámenes son incrementales y normalmente incurren en costos más bajos.
Visualización del uso de la tabla del sistema system.billing.usage
Puede consultar los gastos de clasificación de datos desde system.billing.usage. Los campos created_by y catalog_id se pueden usar opcionalmente para desglosar los costos:
-
created_by: Incluir para ver los costos del usuario que activó el uso. -
catalog_id: Incluya esta opción para ver los costes por catálogo. El identificador de catálogo se muestra en lasystem.data_classification.resultstabla.
Consulta de ejemplo para los últimos 30 días:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
Para calcular el costo total del dólar, únase a system.billing.list_prices. En la consulta de ejemplo siguiente se usa un parámetro :add_on_rate nombrado como multiplicador del precio de lista. Establézcalo en 1 para usar el precio de lista directamente o en un valor menor que 1 para reflejar un descuento negociado (por ejemplo, 0.9 para un descuento de 10%).
Consulta de ejemplo para el costo total de dólar en los últimos 30 días:
SELECT
u.usage_date,
SUM(u.usage_quantity * lp.pricing.effective_list.default) * :add_on_rate
AS `Data Classification Dollar Cost`
FROM system.billing.usage AS u
JOIN system.billing.list_prices AS lp
ON lp.sku_name = u.sku_name
WHERE
u.billing_origin_product = 'DATA_CLASSIFICATION'
AND u.usage_end_time >= lp.price_start_time
AND (lp.price_end_time IS NULL OR u.usage_end_time < lp.price_end_time)
AND u.usage_date >= DATE_ADD(CURRENT_DATE(), -30)
GROUP BY
u.usage_date
ORDER BY
u.usage_date DESC;
Visualización del uso desde el panel de uso
Si ya tiene un panel de uso configurado en el área de trabajo, puede usarlo para filtrar el uso seleccionando el proyecto de origen de facturación con la etiqueta "Clasificación de datos". Si no tiene configurado un panel de uso, puede importar uno y aplicar el mismo filtrado. Para obtener más información, consulte Paneles de uso.
Etiquetas de clasificación admitidas
Para obtener una lista completa de las etiquetas admitidas organizadas por etiquetas globales, etiquetas regionales y marcos de cumplimiento (PII, RGPD, HIPAA, DPDPA), consulte Etiquetas de clasificación admitidas.
Limitaciones
- No se admiten visualizaciones ni vistas de métricas. Si la vista se basa en tablas existentes, Databricks recomienda clasificar las tablas subyacentes para ver si contienen datos confidenciales.