Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
.NET para Apache Spark proporciona compatibilidad gratuita, de código abierto y multiplataforma con .NET para Spark.
Proporciona enlaces de .NET para Spark, lo que permite acceder a las API de Spark a través de C# y F#. Con .NET para Apache Spark, también puede escribir y ejecutar funciones definidas por el usuario para Spark escritas en .NET. Las API de .NET para Spark permiten acceder a todos los aspectos de los dataframes de Spark que le ayudan a analizar los datos, incluidos Spark SQL, Delta Lake y Structured Streaming.
Puede analizar datos con .NET para Apache Spark mediante definiciones de trabajos por lotes de Spark o con cuadernos interactivos de Azure Synapse Analytics. En este artículo, aprenderá a usar .NET para Apache Spark con Azure Synapse mediante ambas técnicas.
Importante
.NET para Apache Spark es un proyecto de código abierto en .NET Foundation que actualmente requiere la biblioteca de .NET 3.1, que ha alcanzado el estado fuera de soporte técnico. Nos gustaría informar a los usuarios de Azure Synapse Spark de la eliminación de la biblioteca .NET para Apache Spark en Azure Synapse Runtime para Apache Spark versión 3.3. Los usuarios pueden consultar la directiva de soporte técnico de .NET para obtener más detalles sobre este asunto.
Como resultado, ya no será posible que los usuarios usen las API de Apache Spark a través de C# y F#, o bien ejecuten código de C# en cuadernos dentro de Synapse o a través de definiciones de trabajos de Apache Spark en Synapse. Es importante tener en cuenta que este cambio afecta solo a Azure Synapse Runtime para Apache Spark 3.3 y versiones posteriores.
Seguiremos admitiendo .NET para Apache Spark en todas las versiones anteriores de Azure Synapse Runtime según sus fases de ciclo de vida. Sin embargo, no tenemos planes para admitir .NET para Apache Spark en Azure Synapse Runtime para Apache Spark 3.3 y versiones futuras. Se recomienda que los usuarios con cargas de trabajo existentes escritas en C# o F# migren a Python o Scala. Se recomienda a los usuarios tomar nota de esta información y planear en consecuencia.
Envío de trabajos por lotes mediante la definición de trabajo de Spark
Visite el tutorial para aprender a usar Azure Synapse Analytics para crear definiciones de trabajos de Apache Spark para grupos de Synapse Spark. Si no ha empaquetado la aplicación para enviar a Azure Synapse, complete los pasos siguientes.
Configure las
dotnetdependencias de la aplicación para la compatibilidad con Synapse Spark. La versión de .NET Spark necesaria se anotará en la interfaz de Synapse Studio en la configuración del grupo de Apache Spark, en el cuadro de herramientas Administrar.
Cree el proyecto como una aplicación de consola de .NET que genere un ejecutable de Ubuntu x86.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Ejecute los siguientes comandos para publicar la aplicación. Asegúrese de reemplazar mySparkApp por la ruta de acceso a la aplicación.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Comprima el contenido de la carpeta publish,
publish.zippor ejemplo, que se creó como resultado del paso 1. Todos los ensamblados deben estar en la raíz del archivo ZIP y no debe haber ninguna capa de carpeta intermedia. Esto significa que, al descomprimirpublish.zip, todos los elementos ensamblados se extraen en el directorio de trabajo actual.En Windows:
Con Windows PowerShell o PowerShell 7, cree un .zip a partir del contenido del directorio de publicación.
Compress-Archive publish/* publish.zip -UpdateEn Linux:
Abra un shell de bash, cambie al directorio bin con todos los archivos binarios publicados y ejecute el siguiente comando.
zip -r publish.zip
.NET para Apache Spark en los cuadernos de Azure Synapse Analytics
Los cuadernos son una excelente opción para crear prototipos de canalizaciones y escenarios de .NET para Apache Spark. Puede empezar a trabajar con, comprender, filtrar, mostrar y visualizar los datos de forma rápida y eficaz.
Los ingenieros de datos, los científicos de datos, los analistas de negocios y los ingenieros de aprendizaje automático pueden colaborar en un documento compartido e interactivo. Verá resultados inmediatos de la exploración de datos y puede visualizar los datos en el mismo cuaderno.
Cómo utilizar .NET en los cuadernos de Apache Spark
Al crear un cuaderno, elija un kernel de lenguaje que desee expresar la lógica de negocios. La compatibilidad con kernel está disponible para varios lenguajes, incluido C#.
Para usar .NET para Apache Spark en el cuaderno de Azure Synapse Analytics, seleccione .NET Spark (C#) como kernel y asocie el cuaderno a un grupo de Apache Spark sin servidor existente.
El cuaderno de Spark de .NET se basa en las experiencias interactivas de .NET y proporciona experiencias interactivas de C# con la capacidad de usar .NET para Spark de fábrica con la variable spark de sesión de Spark ya predefinida.
Instalación de paquetes NuGet en cuadernos
Puede instalar paquetes NuGet que elija en el cuaderno mediante el comando mágico #r nuget antes del nombre del paquete NuGet. En el diagrama siguiente se muestra un ejemplo:
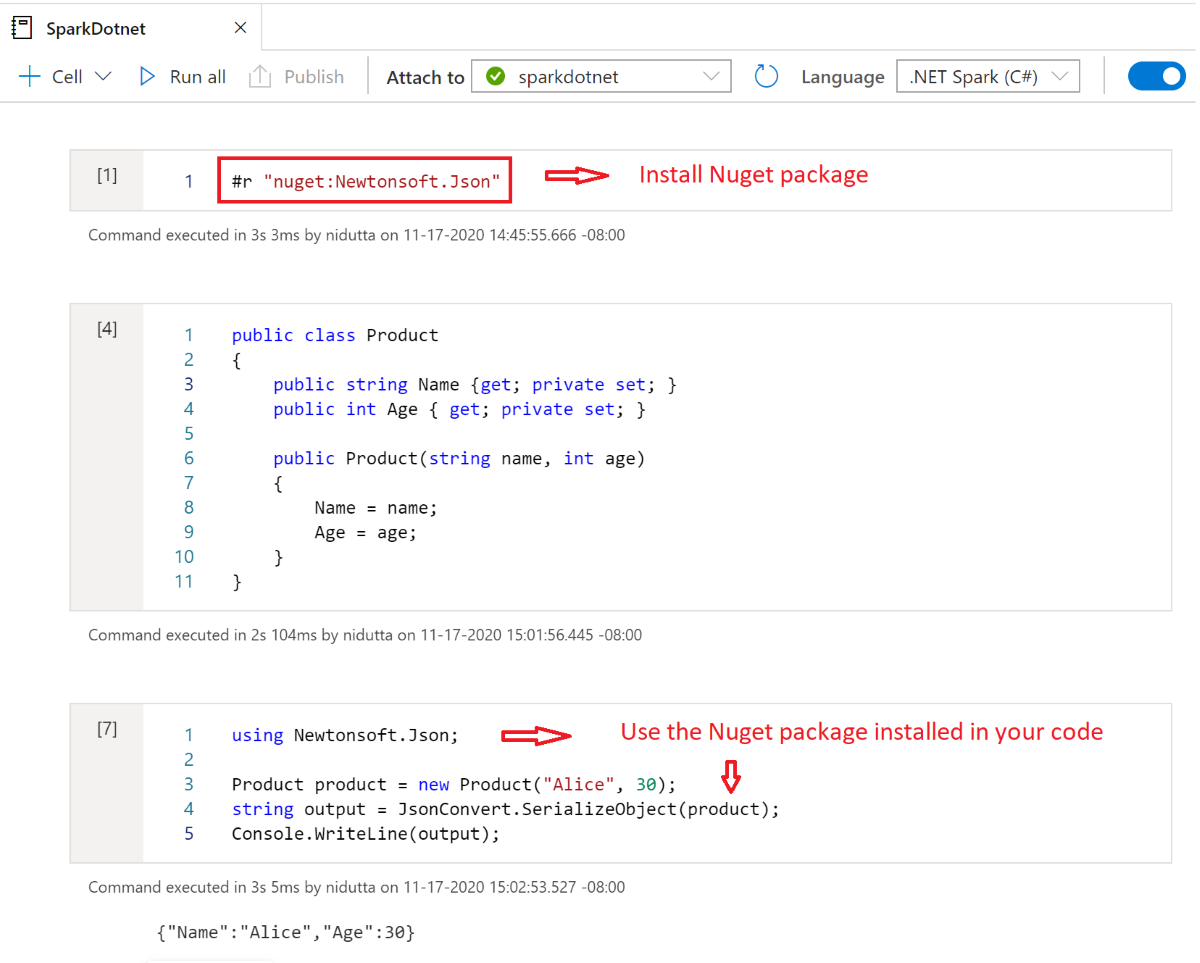
Para obtener más información sobre cómo trabajar con paquetes NuGet en cuadernos, consulte la documentación interactiva de .NET.
Características del kernel de .NET para Apache Spark en C#
Las siguientes características están disponibles cuando se usa .NET para Apache Spark en el cuaderno de Azure Synapse Analytics:
- HTML declarativa: Genere resultados a partir de las celdas con sintaxis HTML, como encabezados, listas con viñetas e, incluso, mostrar imágenes.
- Instrucciones simples de C# (como asignaciones, impresión en la consola, generación de excepciones, etc.).
- Bloques de código de C# de varias líneas (como instrucciones if, bucles foreach, definiciones de clase, etc.).
- Acceso a la biblioteca estándar de C# (como System, LINQ, Enumerables, etc.).
- Compatibilidad con las características del lenguaje C# 8.0.
-
sparkcomo una variable predefinida para proporcionarle acceso a la sesión de Apache Spark. - Compatibilidad con la definición de funciones definidas por el usuario de .NET que se pueden ejecutar en Apache Spark. Le recomendamos leer Escritura y llamada a UDF en entornos interactivos de .NET para Apache Spark para aprender a usar UDF en experiencias interactivas de .NET para Apache Spark.
- Compatibilidad para visualizar la salida de los trabajos de Spark con distintos gráficos (como líneas, barras o histogramas), y diseños (como único, superpuesto, etc.) mediante la biblioteca de
XPlot.Plotly. - Capacidad de incluir paquetes NuGet en el cuaderno de C#.
Solución de problemas
OutOfMemoryError: espacio de montón de Java en org.apache.spark
Dotnet Spark 1.0.0 usa una arquitectura de depuración diferente a la 1.1.1+. Tendrá que usar 1.0.0 para la versión publicada y 1.1.1+ para la depuración local.