Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los conjuntos de recursos de Databricks se pueden crear y modificar directamente en el área de trabajo.
Para conocer los requisitos para utilizar paquetes en el área de trabajo, consulte Paquetes de Recursos de Databricks en los requisitos del área de trabajo.
Para obtener más información sobre las agrupaciones, consulte ¿Qué son los conjuntos de recursos de Databricks?.
Crear un paquete
Para crear un paquete en el espacio de trabajo de Databricks:
Diríjase a la carpeta git donde desea crear su paquete.
Haga clic en el botón Crear y, a continuación, haga clic en Agrupación de recursos. Como alternativa, haga clic con el botón derecho en la carpeta Git o en su kebab asociado en el árbol del área de trabajo y haga clic en Crear>agrupación de recursos:
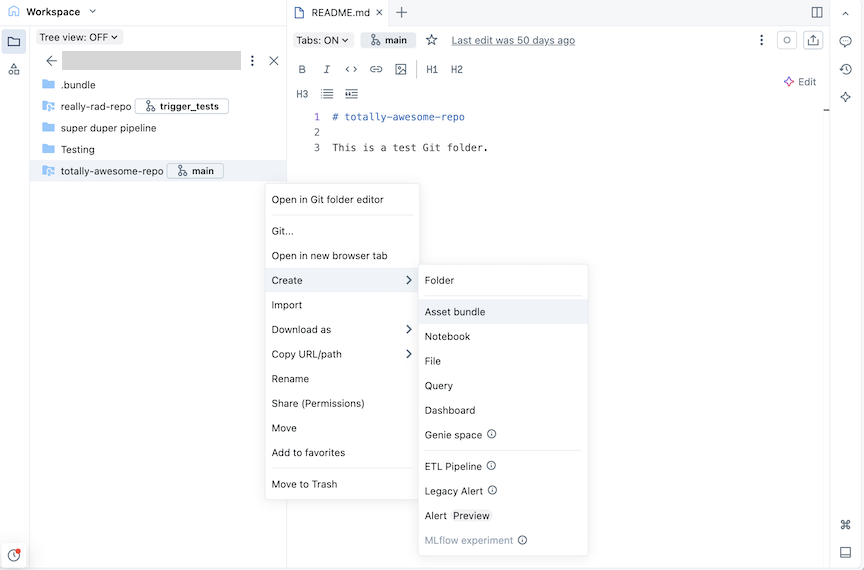
En el cuadro de diálogo Crear un lote de recursos , asigne un nombre al conjunto de recursos, como un paquete totalmente impresionante. El nombre del lote solo puede contener letras, números, guiones y caracteres de subrayado.
En Plantilla, elija si desea crear un paquete vacío, un lote que ejecuta un cuaderno de Python de ejemplo o un lote que ejecuta SQL. Si tiene habilitado el Editor de canalizaciones de Lakeflow , también verá una opción para crear un proyecto de canalización ETL.
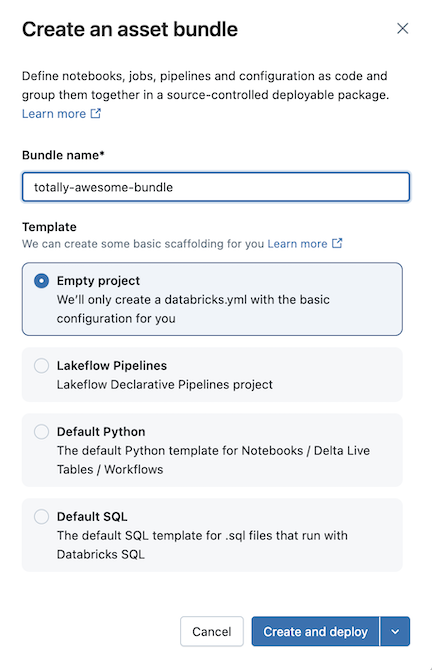
Algunas plantillas requieren configuración adicional. Haga clic en Siguiente para terminar de configurar el proyecto.
Template Opciones de configuración Canalizaciones declarativas de Spark de Lakeflow - Catálogo predeterminado que se va a usar para los datos de canalización
- Usar el esquema personal (recomendado) para cada usuario que colabore en este paquete.
- Lenguaje inicial para los archivos de código del pipeline
Python predeterminado - Incluir un cuaderno de ejemplo
- Incluir una canalización de ejemplo
- Incluir un paquete de Python de ejemplo
- Uso del proceso sin servidor
SQL predeterminado - Ruta de acceso de SQL Warehouse
- Catálogo inicial
- Uso del esquema personal
- Esquema inicial durante el desarrollo
Haga clic en Crear e implementar.
Esto crea una agrupación inicial en la carpeta Git, que incluye los archivos de la plantilla de proyecto que seleccionó, un .gitignore archivo de configuración de Git y el archivo de conjuntos de recursos de Databricks databricks.yml necesarios. El databricks.yml archivo contiene la configuración principal de la agrupación. Para obtener más información, consulte Configuración del conjunto de recursos de Databricks.
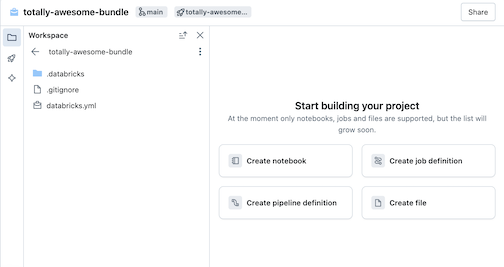
Los cambios realizados en los archivos de la agrupación se pueden sincronizar con el repositorio remoto asociado a la carpeta Git. Una carpeta de Git puede contener muchos paquetes.
Agregar nuevos archivos a una agrupación
Un paquete contiene el databricks.yml archivo que define configuraciones de implementación y área de trabajo, archivos de origen, como cuadernos, archivos de Python y archivos de prueba, y definiciones y opciones de configuración para recursos de Databricks, como trabajos de Lakeflow y canalizaciones declarativas de Spark de Lakeflow. De forma similar a cualquier carpeta del área de trabajo, puede agregar nuevos archivos a la agrupación.
Sugerencia
Para abrir una nueva pestaña en la vista de agrupación que le permite modificar los archivos de agrupación, vaya a la carpeta bundle del área de trabajo y, a continuación, haga clic en Abrir en el editor a la derecha del nombre del lote.
Adición de archivos de código fuente
Para agregar nuevos cuadernos u otros archivos a una agrupación en la interfaz de usuario del área de trabajo, vaya a la carpeta bundle y, a continuación, haga lo siguiente:
- Haga clic en Crear en la esquina superior derecha y elija uno de los siguientes tipos de archivo para agregar a la agrupación: Cuaderno, Archivo, Consulta, Panel.
- Como alternativa, haga clic en el kebab a la izquierda de Compartir e importe un archivo.
Nota:
Para que el archivo forme parte de la implementación del lote, después de agregar un archivo a la carpeta bundle, debe agregarlo a la databricks.yml configuración del lote o crear un archivo de definición de canalización o trabajo que lo incluya. Consulte Agregar un recurso existente a una agrupación.
Creación de una definición de recursos
Los paquetes contienen definiciones de recursos como trabajos y canalizaciones para incluir en una implementación. Cuando se implementa la agrupación, los recursos definidos en la agrupación se crean en el área de trabajo (o se actualizan si ya se han implementado). Estas definiciones se especifican en YAML o Python, y puede crear y editar estas configuraciones directamente en la interfaz de usuario.
Vaya a la carpeta bundle en el área de trabajo donde desea definir un nuevo recurso.
Sugerencia
Si ha abierto previamente la agrupación en el editor del área de trabajo, puede usar la lista de contextos de creación del explorador del área de trabajo para navegar a la carpeta bundle. Consulte Contextos de creación.
A la derecha del nombre del lote, haga clic en Abrir en el editor para ir a la vista del editor del lote.
Haga clic en el icono de implementación del paquete para cambiar al panel Implementaciones .
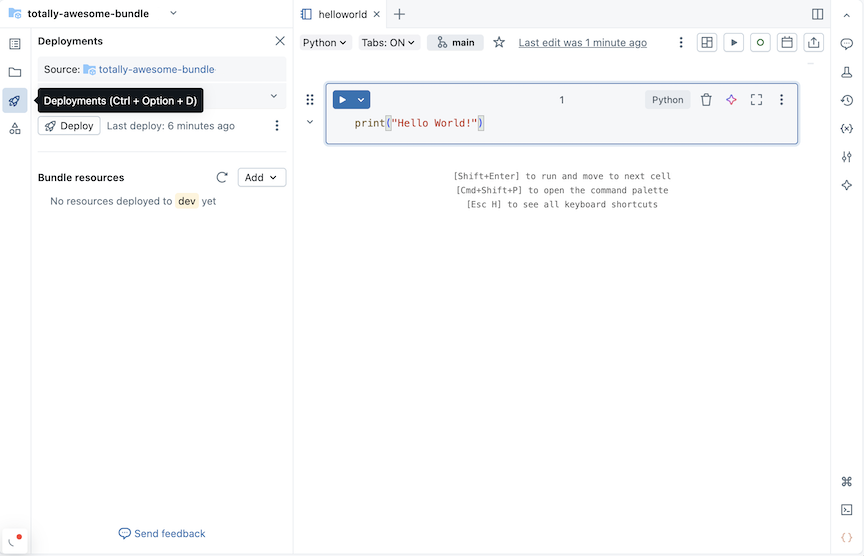
En la sección Agrupación de recursos , haga clic en Agregar y, a continuación, elija una definición de recurso para crear.
Nueva definición de trabajo
Para crear un archivo de configuración de agrupación que defina un trabajo:
En la sección Agrupación de recursos del panel Implementaciones , haga clic en Agregar y, a continuación, en Nueva definición de trabajo.
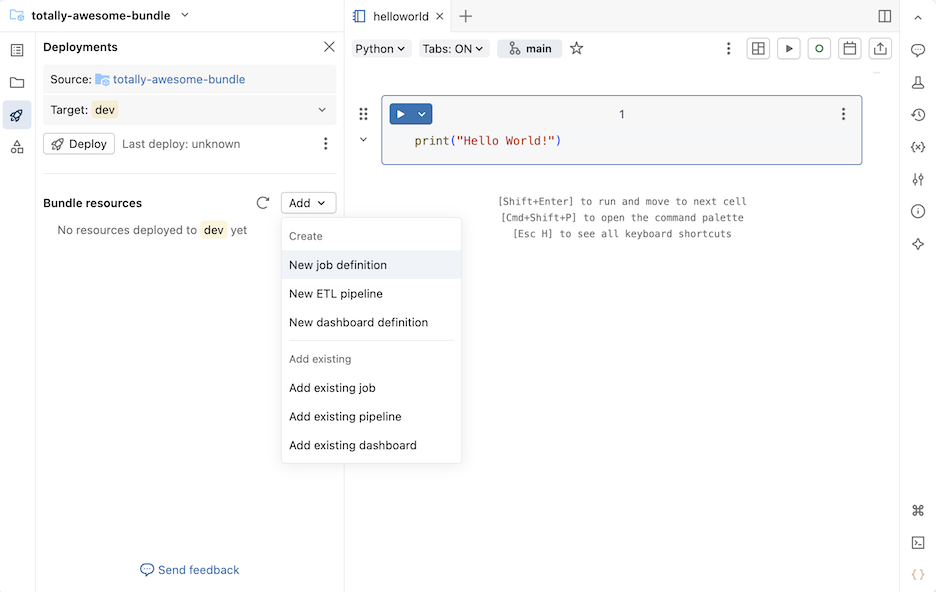
Escriba un nombre para el trabajo en el campo Nombre del trabajo del cuadro de diálogo Crear definición de trabajo . Haga clic en Crear.
Agregue YAML al archivo de definición de trabajo que se creó. En el ejemplo siguiente YAML se define un trabajo que ejecuta un cuaderno:
resources: jobs: run_notebook: name: run-notebook queue: enabled: true tasks: - task_key: my-notebook-task notebook_task: notebook_path: ../helloworld.ipynb
Para más información sobre cómo definir un trabajo en YAML, consulte trabajo. Para ver la sintaxis de YAML para otros tipos de tareas de trabajo admitidos, consulte Incorporación de tareas a trabajos en Conjuntos de recursos de Databricks.
Nueva definición de canalización
Nota:
Si ha habilitado el Editor de canalizaciones de Lakeflow en el área de trabajo, consulte Nueva canalización de ETL.
Para agregar una definición de canalización a su paquete:
En la sección Agrupación de recursos del panel Implementaciones , haga clic en Agregar y, a continuación, en Nueva definición de canalización.
Escriba un nombre para la canalización en el campo Nombre de canalización del cuadro de diálogo Agregar canalización a la agrupación existente .
Haga clic en Agregar e implementar.
Para una canalización con el nombre test_pipeline que ejecuta un cuaderno, se crea el siguiente código YAML en un archivo test_pipeline.pipeline.yml:
resources:
pipelines:
test_pipeline:
name: test_pipeline
libraries:
- notebook:
path: ../test_pipeline.ipynb
serverless: true
catalog: main
target: test_pipeline_${bundle.environment}
Puede modificar la configuración para ejecutar un cuaderno existente. Para más información sobre cómo definir una canalización en YAML, consulte canalización.
Nueva canalización de ETL
Para agregar una nueva definición de canalización ETL:
En la sección Agrupación de recursos del panel Implementaciones , haga clic en Agregar y, a continuación, en Nueva canalización de ETL.
Escriba un nombre para la canalización en el campo Nombre del cuadro de diálogo Agregar canalización a la agrupación existente . El nombre debe ser único dentro del área de trabajo.
En el campo Usar esquema personal , seleccione Sí para escenarios de desarrollo y No para escenarios de producción.
Seleccione un catálogo predeterminado y un esquema predeterminado para la canalización.
Elija un lenguaje para el código fuente de la canalización.
Haga clic en Agregar e implementar.
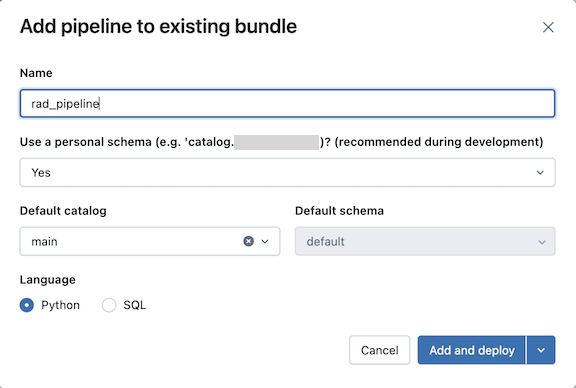
Revise los detalles del cuadro de diálogo de confirmación Desplegar en desarrollo y, a continuación, haga clic en Desplegar.
Se crea una canalización ETL con tablas de exploración y transformación de ejemplo.
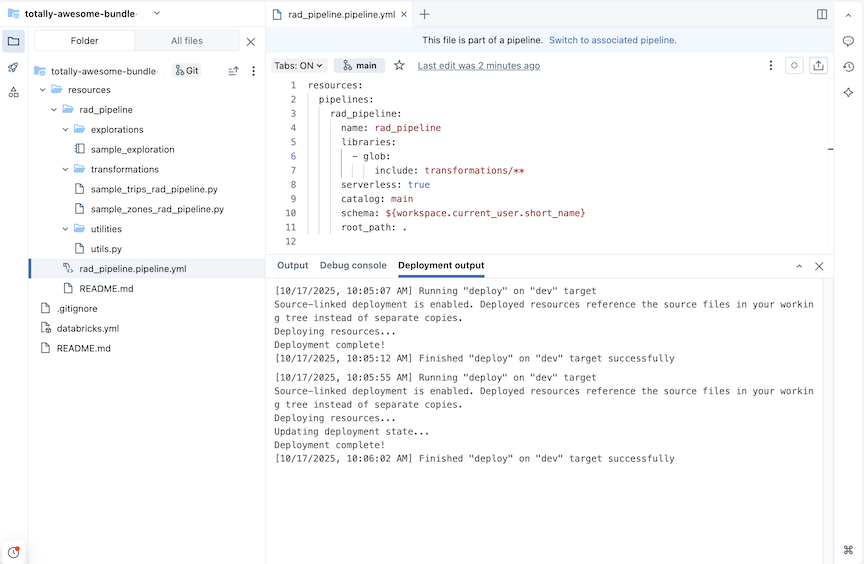
Para una canalización con el nombre rad_pipeline, se crea el siguiente CÓDIGO YAML en un archivo rad_pipeline.pipeline.yml. Esta canalización está configurada para ejecutarse en un proceso sin servidor. Para ver la referencia de configuración de canalización, consulte canalización.
resources:
pipelines:
rad_pipeline:
name: rad_pipeline
libraries:
- glob:
include: transformations/**
serverless: true
catalog: main
schema: ${workspace.current_user.short_name}
root_path: .
Nueva definición del tablero de control
Para crear un archivo de configuración de agrupación que defina un panel:
En la sección Agrupación de recursos del panel Implementaciones , haga clic en Agregar y, a continuación, en Nueva definición del panel.
Escriba un nombre para el panel en el campo Nombre del panel del cuadro de diálogo Agregar panel a lote existente .
Seleccione un almacén para el panel. Haga clic en Agregar e implementar.
Se crea un nuevo panel vacío y un archivo de configuración *.dashboard.yml en la agrupación. El panel se almacena en el almacén especificado en el archivo de configuración.
Para obtener más información sobre los paneles, consulte Paneles. Para ver la sintaxis de YAML para la configuración del panel, consulte panel.
Agregar un recurso existente a una agrupación
Puede agregar recursos existentes a su paquete mediante la interfaz de usuario del área de trabajo o agregando la configuración de recursos a su paquete.
Uso de la interfaz de usuario del área de trabajo de agrupación
Para agregar un trabajo existente, una canalización existente o un panel existente a un conjunto:
Vaya a la carpeta bundle en el área de trabajo donde desea agregar un recurso.
Sugerencia
Si ha abierto previamente la agrupación en el editor del área de trabajo, puede usar la lista de contextos de creación del explorador del área de trabajo para navegar a la carpeta bundle. Consulte Contextos de creación.
A la derecha del nombre del lote, haga clic en Abrir en el editor para ir a la vista del editor del lote.
Haga clic en el icono de implementación del paquete para cambiar al panel Implementaciones .
En la sección Agrupación de recursos , haga clic en Agregar y, a continuación, haga clic en Agregar trabajo existente, Agregar canalización existente o Agregar panel existente.
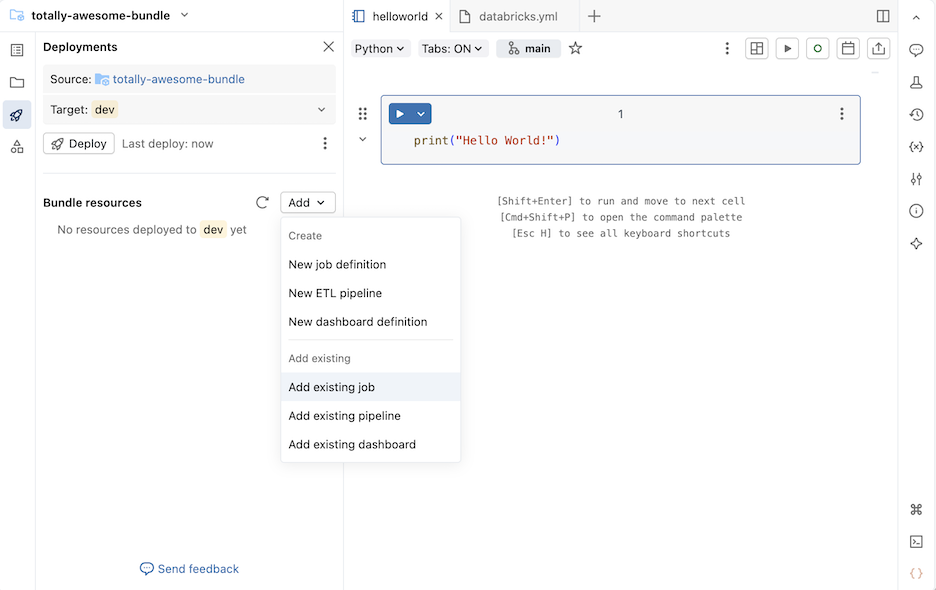
En el cuadro de diálogo Agregar existente... , seleccione el recurso existente en la lista desplegable.
Al agregar un recurso existente a una agrupación, Databricks crea una definición en un archivo de configuración de agrupación para este recurso. Dado que puede modificar esta definición en la agrupación, el recurso definido en la agrupación puede diverge del recurso usado para crearla.
Elija una opción para controlar las actualizaciones de la configuración de recursos de agrupación:
-
Actualización sobre despliegues de producción: el recurso existente se vincula al recurso en el paquete y los cambios que realice en el recurso del paquete se aplican al recurso existente cuando se despliega al
proddestino. -
Actualización de las implementaciones de desarrollo: el recurso existente se vincula al recurso del paquete y los cambios realizados en el recurso del paquete se aplican al recurso existente al implementar en el
devdestino. - (Avanzado) No actualice: el recurso existente no está vinculado a la agrupación. Los cambios realizados en el recurso de la agrupación nunca se aplican al recurso existente. En su lugar, se crea una copia. Para más información sobre cómo vincular los recursos del paquete a su recurso de área de trabajo correspondiente, consulte databricks bundle deployment bind.
-
Actualización sobre despliegues de producción: el recurso existente se vincula al recurso en el paquete y los cambios que realice en el recurso del paquete se aplican al recurso existente cuando se despliega al
Haga clic en Agregar ... para agregar el recurso existente a la agrupación.
Agregar configuración de paquete
También se puede agregar un recurso existente a la agrupación definiendo la configuración de la agrupación para incluirlo en el despliegue de la agrupación. En el siguiente ejemplo, se agrega una canalización existente a un paquete.
Suponiendo que tiene una canalización denominada taxifilter que ejecuta el taxifilter.ipynb notebook en tu área de trabajo compartida:
En la barra lateral del área de trabajo de Azure Databricks, haga clic en Trabajos y canalizaciones.
Opcionalmente, seleccione los filtros Canalizaciones y Propiedad de mí .
Seleccione la canalización existente
taxifilter.En la página de canalización, haga clic en el kebab situado a la izquierda del botón Modo de implementación de desarrollo . A continuación, haga clic en Ver configuración YAML.
Haga clic en el icono de copia para copiar la configuración de agrupación de la canalización.
Navega a tu paquete en Área de trabajo.
Haga clic en el icono de implementación del paquete para cambiar al panel Implementaciones .
En la sección Agrupación de recursos , haga clic en Agregar y, a continuación, en Nueva definición de canalización.
Nota:
Si en su lugar ve un elemento de menú Nueva canalización de ETL , tendrá habilitado el Editor de canalizaciones de Lakeflow . Para agregar una canalización ETL a una agrupación, consulte Creación de una canalización controlada por código fuente.
Escriba
taxifilteren el campo Nombre de canalización del cuadro de diálogo Agregar canalización a la agrupación existente . Haga clic en Crear.Pegue la configuración de la canalización existente en el archivo. Esta canalización de ejemplo se define para ejecutar el
taxifiltercuaderno:resources: pipelines: taxifilter: name: taxifilter catalog: main libraries: - notebook: path: /Workspace/Shared/taxifilter.ipynb target: taxifilter_${bundle.environment}
Ahora puede implementar la agrupación y, a continuación, ejecutar el recurso de canalización a través de la interfaz de usuario.