¿Qué es Habla personalizada?
Con Habla personalizada puede evaluar y mejorar la precisión del reconocimiento de voz de sus aplicaciones y productos. Se puede usar un modelo de voz personalizado para la conversión de voz en texto en tiempo real, la traducción de voz y la transcripción por lotes.
De forma predeterminada, el reconocimiento de voz utiliza un modelo de lenguaje universal como modelo base que se entrena con datos que son propiedad de Microsoft y refleja el idioma hablado que se usa habitualmente. El modelo base está entrenado prviamente con dialectos y fonética representando varios dominios comunes. Al hacer una solicitud de reconocimiento de voz, el modelo base más reciente para cada idioma admitido se usa de manera predeterminada. El modelo base funciona bien en la mayoría de los escenarios de reconocimiento de voz.
Se puede usar un modelo personalizado para aumentar el modelo base para mejorar el reconocimiento del vocabulario concreto del dominio específico de la aplicación proporcionando datos de texto para entrenar el modelo. También se puede usar para mejorar el reconocimiento basado en las condiciones de audio específicas de la aplicación proporcionando datos de audio con transcripciones de referencia.
También puede entrenar un modelo con texto estructurado cuando los datos siguen un patrón, especificar pronunciaciones personalizadas y personalizar el formato de texto para mostrar con normalización de texto inversa personalizada, reescritura personalizada y filtrado de palabras soeces personalizado.
¿Cómo funciona?
Gracias a Voz personalizada, puede cargar sus propios datos, probar y entrenar un modelo personalizado, comparar la precisión entre modelos e implementar un modelo en un punto de conexión personalizado.
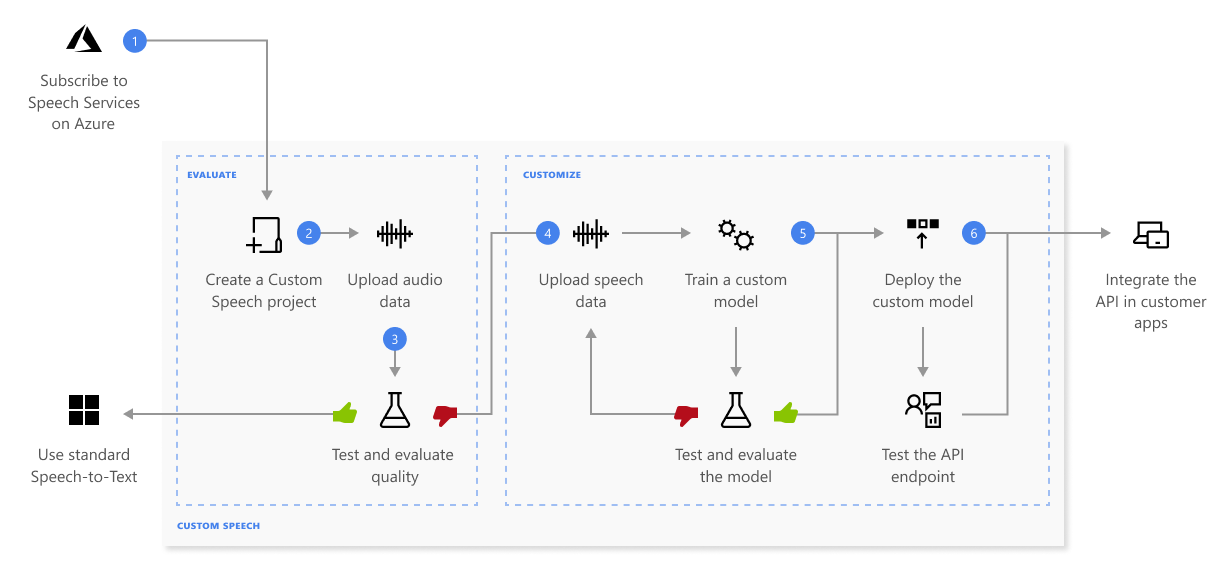
A continuación encontrará más información sobre la secuencia de pasos mostrada en el diagrama anterior:
- Cree un proyecto y elija un modelo. Use un recurso de Voz que cree en Azure Portal. Si entrena un modelo personalizado con datos de audio, elija una región de recursos de Voz con hardware dedicado para entrenar datos de audio. Para obtener más información consulte las notas al pie en la tabla de regiones.
- Carga de datos de prueba. Cargue datos de prueba para evaluar la oferta de conversión de voz en texto para las aplicaciones, herramientas y productos.
- Prueba de la calidad del reconocimiento. Use Speech Studio para reproducir el audio cargado e inspeccionar la calidad del reconocimiento de voz de los datos de prueba.
- Prueba del modelo de forma cuantitativa. Evalúe y mejore la precisión del modelo de conversión de voz a texto. El servicio Voz proporciona una tasa de errores por palabra (WER) cuantitativa que puede usar para determinar si se necesita más entrenamiento.
- Entrenamiento de un modelo. Proporcione transcripciones escritas y texto relacionado, junto con los datos de audio correspondientes. Probar un modelo antes y después del entrenamiento es opcional, pero se recomienda.
Nota:
Se paga por el uso del modelo de habla personalizada y el hospedaje del punto de conexión. También se le cobrará por el entrenamiento del modelo de voz personalizado si el modelo base se creó el 1 de octubre de 2023 y versiones posteriores. No se le cobrará por el entrenamiento si el modelo base se creó antes de octubre de 2023. Para obtener más información, consulte precios de Voz de Azure AI y la sección Cargo por adaptación de la guía de migración de conversión de voz en texto 3.2.
- Implementación de un modelo. Una vez que esté satisfecho con los resultados de la prueba, implemente el modelo en un punto de conexión personalizado. Excepto con la transcripción por lotes, tiene que implementar un punto de conexión personalizado para usar un modelo de voz personalizada.
Sugerencia
No se requiere un punto de conexión de implementación hospedado para usar la voz personalizada con la API de transcripción de Batch. Es posible conservar los recursos si el modelo de voz personalizado solo se usa para la transcripción por lotes. Para más información, consulte Precios del servicio de voz.
Inteligencia artificial responsable
Los sistemas de inteligencia artificial no solo incluyen la tecnología, sino también las personas que la usan, las que se ven afectadas por ella y el entorno en el que se implementan. Lea las notas sobre transparencia para obtener información sobre el uso y la implementación de la IA responsable en los sistemas.
- Nota de transparencia y casos de uso
- Características y limitaciones
- Integración y uso responsable
- Datos, privacidad y seguridad
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de