Obtención de la posición facial con visema
Nota
Para explorar las configuraciones regionales admitidas para el id. de visema y combinar formas, consulte la lista de todas las configuraciones regionales admitidas. Los gráficos vectoriales escalables (SVG) solo se admiten para la configuración regional en-US.
Un visema es la descripción visual de un fonema en lenguaje hablado. Define la posición de la cara y la boca cuando habla una persona. Cada visema describe las principales supuestos faciales para un conjunto específico de fonemas.
Puede usar visemas para controlar el movimiento de los modelos de avatar 2D y 3D, de modo que las posiciones faciales coincidan mejor con la voz sintética. Por ejemplo, puede:
- Crear un asistente para voz virtual animado para quioscos inteligentes y servicios integrados multi-modo para los clientes.
- Crear informativos inmersivos y mejorar las experiencias del público con movimientos naturales de la cara y la boca.
- Generar avatares de juegos y personajes animados más interactivos que puedan hablar con contenido dinámico.
- Crear vídeos de enseñanza de idiomas más eficaces que ayuden a los aprendices a comprender el comportamiento de la boca de cada palabra y fonema.
- Las personas con deficiencias auditivas también pueden captar los sonidos de forma visual y "leer los labios" del contenido de voz que muestra los visemas en una cara animada.
Para más información sobre los visemas, vea este vídeo introductorio.
Flujo de trabajo general de producción de visemas con voz
Texto a voz neuronal (TTS neuronal) convierte el texto de entrada o SSML (lenguaje de marcado de síntesis de voz) en voz sintetizada realista. La salida de audio de voz puede ir acompañada de id. de visema, Scalable Vector Graphics (SVG) o formas de mezcla. Con un motor de representación 2D o 3D, puede usar estos eventos de visema para animar el avatar.
El flujo de trabajo general de visemas se muestra en el diagrama de flujo siguiente:
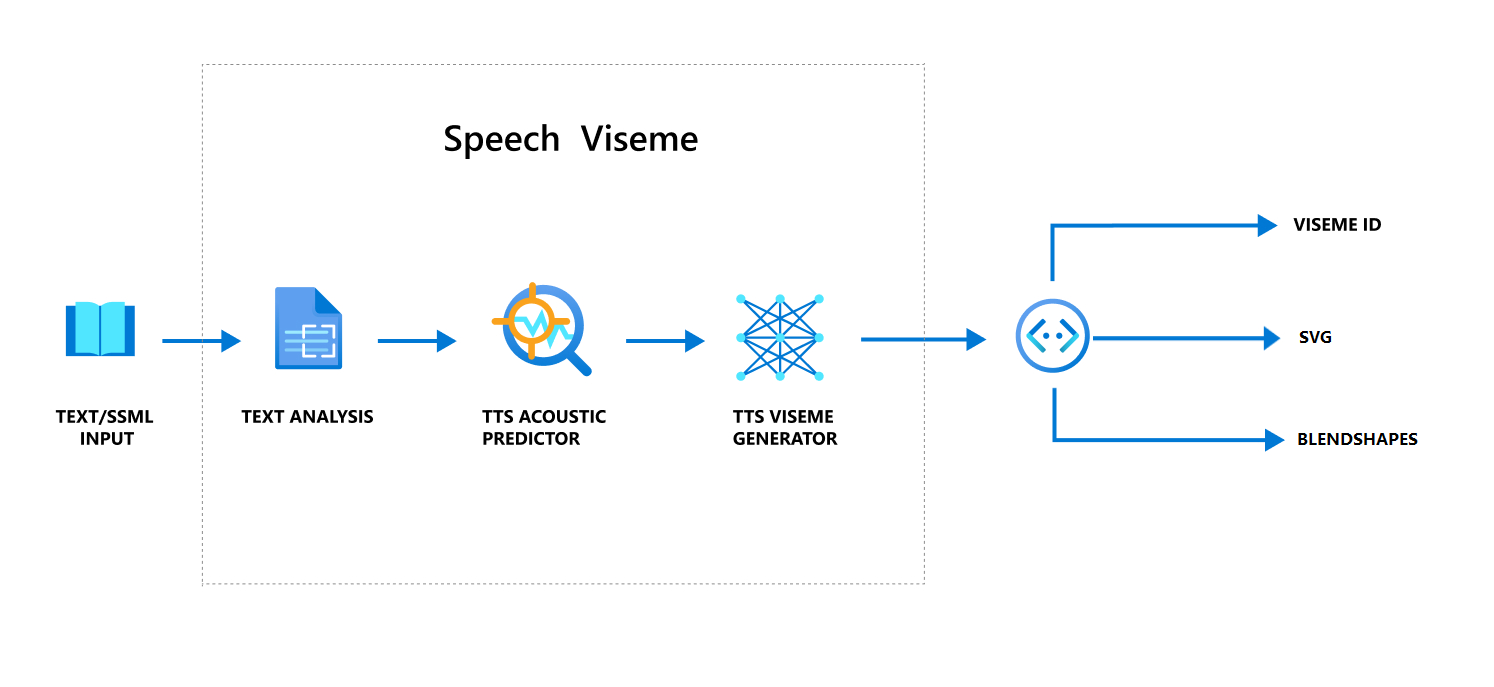
Id. de visema
Id. de visema hace referencia a un número entero que especifica un visema. Incluimos 22 visemas diferentes y cada uno representa la posición de la boca para un conjunto específico de fonemas. No hay una correspondencia uno a uno entre visemas y fonemas. A menudo, varios fonemas se corresponden con un único visema, ya que se ven igual en la cara del hablante cuando se producen, como s y z. Para obtener información más específica, consulte la tabla para asignar fonemas a los identificadores de visema.
La salida de audio de voz puede ir acompañada de id. de visema y Audio offset. Audio offset indica la marca de tiempo de desfase que representa la hora de inicio de cada visema, en tics (100 nanosegundos).
Asignación de fonemas a visemas
Las visemas varían según el lenguaje y la configuración regional. Cada configuración regional tiene un conjunto de visemas que corresponden a sus fonemas específicos. La documentación de los alfabetos fonéticos de SSML asigna identificadores de visemas a los fonemas del alfabeto fonético internacional (IPA) correspondientes. La tabla de esta sección se muestra una relación de asignación entre identificadores de visema y posiciones de boca, indicando los fonemas del alfabeto fonético internacional (IPA) típicos para cada identificador de visema.
| Id. de visema | IPA | Posición de la boca |
|---|---|---|
| 0 | Silencio |  |
| 1 | æ, ə, ʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, i, ɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, tʃ, dʒ, ʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, t, n, θ |
 |
| 20 | k, g, ŋ |
 |
| 21 | p, b, m |
 |
Animación con SVG 2D
Para los personajes 2D, puede diseñar uno que se adapte al escenario y usar gráficos vectoriales escalables (SVG) para cada identificador de visema a fin de obtener una posición de la cara basada en el tiempo.
Con las etiquetas temporales proporcionadas en el evento de visema, estos gráficos SVG bien diseñados se procesan con modificaciones de suavizado y proporcionan una animación sólida a los usuarios. Por ejemplo, en la ilustración siguiente se muestra un personaje con labios de color rojo diseñado para el aprendizaje de idiomas.

Animación con formas de mezcla 3D
Puede usar formas de mezcla para impulsar los movimientos faciales de un personaje 3D que diseñe.
La cadena JSON de formas de mezcla se representa como una matriz bidimensional. Cada fila representa un fotograma. Cada fotograma (en 60 fps) contiene una matriz de 55 posiciones faciales.
Obtención de eventos de visema con el SDK de voz
Para obtener visemas con la voz sintetizada, suscríbase al evento VisemeReceived en el SDK de Voz.
Nota
Para solicitar la salida de las formas SVG o de mezcla, debe usar el elemento mstts:viseme en SSML. Para obtener más información, consulte cómo usar el elemento visema en SSML.
En el fragmento de código siguiente se muestra cómo suscribirse al evento de visema:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Este es un ejemplo de la salida del visema.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Después de obtener la salida del visema, puede usar estos eventos para controlar la animación de los personajes. Puede crear personajes propios y animarlos de forma automática.