Traductor personalizado para principiantes
Traductor personalizado le permite crear un sistema de traducción que refleje la terminología y el estilo específicos del negocio, el sector y el dominio. Entrenar e implementar un sistema personalizado es fácil y no requiere aptitudes de programación. El sistema de traducción personalizada se integra perfectamente en las aplicaciones, flujos de trabajo y sitios web existentes y está disponible en Azure mediante el mismo servicio de Microsoft Text Translation API basado en la nube que atiende miles de millones de traducciones cada día.
La plataforma permite a los usuarios compilar y publicar sistemas de traducción personalizados desde y al inglés. El Traductor personalizado admite más de 60 idiomas que asigna directamente a los idiomas disponibles para la traducción automática neuronal (NMT). Para obtener una lista completa, consulte Soporte con idiomas de Traductor.
¿Un modelo de traducción personalizado es la opción adecuada para mí?
Un modelo de traducción personalizada bien entrenado proporciona traducciones específicas de un dominio más precisas porque se basa en documentos traducidos previamente en el dominio para aprender las traducciones que se prefieren. Translator usa estos términos y frases en contexto para generar traducciones fluidas en el idioma de destino, al tiempo que se respeta la gramática dependiente del contexto.
El entrenamiento de un modelo de traducción personalizado completo requiere una cantidad considerable de datos. Si no tiene al menos 10 000 frases de documentos entrenados previamente, no puede entrenar un modelo de traducción de idioma completo. Sin embargo, puede entrenar un modelo de solo diccionario o usar las traducciones de alta calidad y listas para usar disponibles con Text Translation API.
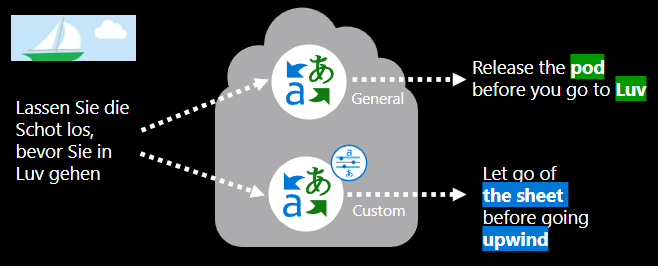
¿Qué implica entrenar un modelo de traducción personalizado?
La creación de un modelo de traducción personalizado requiere:
Descripción del caso de uso.
Obtener datos traducidos en el dominio (preferiblemente traducción humana).
Evaluar la calidad de la traducción o las traducciones de idiomas de destino.
¿Cómo puedo evaluar mi caso de uso?
Tener claridad sobre el caso de uso y lo que se espera como éxito es el primer paso para obtener datos de entrenamiento competentes. Sí, pero debe tener en cuenta algunas consideraciones:
¿Se especifica el resultado deseado y cómo se mide?
¿Está identificado el dominio de su empresa?
¿Tiene frases del dominio de terminología y estilo similares?
¿El caso de uso implica varios dominios? En caso afirmativo, ¿debe crear un sistema de traducción o varios sistemas?
¿Tiene requisitos que afectan a la residencia de datos regionales en reposo y en tránsito?
¿Los usuarios de destino están en una o varias regiones?
¿Cómo debo crear el origen de mis datos?
La búsqueda de datos de calidad en el dominio suele ser una tarea complicada que varía en función de la clasificación del usuario. Estas son algunas preguntas que puede hacerse a medida que evalúa los datos que puede tener a su disposición:
¿Su empresa tiene datos de traducción anteriores disponibles que puede usar? Las empresas suelen tener una gran cantidad de datos de traducción acumulados durante muchos años de uso de la traducción humana.
¿Tiene una gran cantidad de datos monolingües? Los datos monolingües son datos en un solo idioma. Si es así, ¿puede obtener traducciones de estos datos?
¿Puede rastrear portales en línea para recopilar frases de origen y sintetizar frases de destino?
¿Qué debo usar para el material de entrenamiento?
| Source | Qué hace | Reglas que se deben seguir |
|---|---|---|
| Documentos de entrenamiento bilingües | Enseñan al sistema la terminología y el estilo. | Ser liberal. Cualquier traducción humana en el dominio es mejor que la traducción automática. Agregue y quite documentos a medida que avance e intente mejorar la puntuación BLEU. |
| Optimización de documentos | Entrena los parámetros de traducción automática neuronal. | Ser estricto. Redáctelos para que sean una representación óptima de lo que va a traducir en el futuro. |
| Documentos de prueba | Calcule la puntuación BLEU. | Ser estricto. Redacte documentos de prueba para que sean una representación óptima de lo que planea traducir en el futuro. |
| Diccionario de frases | Fuerza la traducción proporcionada el 100 % de las veces. | Ser restrictivo. Un diccionario de frases distingue mayúsculas de minúsculas, y cualquier palabra o frase enumerada se traduce de la manera que especifique. En muchos casos, es mejor no usar un diccionario de frases y dejar que el sistema aprenda. |
| Diccionario de oraciones | Fuerza la traducción proporcionada el 100 % de las veces. | Ser estricto. Un diccionario de oraciones no distingue mayúsculas de minúsculas y es bueno para las oraciones cortas comunes en el dominio. Para que exista una coincidencia con el diccionario de oraciones, la oración completa que se envíe debe coincidir con la entrada de origen del diccionario. Si solo coincide una parte de la oración, la entrada no coincide. |
¿Qué es una puntuación BLEU?
BLEU (Suplente de evaluación bilingüe) es un algoritmo para evaluar la precisión o exactitud del texto que se traduce automáticamente de un idioma a otro. Traductor personalizado usa la métrica BLEU como una manera de transmitir la precisión de la traducción.
Una puntuación BLEU es un número entre cero y 100. Una puntuación de cero indica una traducción de baja calidad donde nada de la traducción coincide con la referencia. Una puntuación de 100 indica una traducción perfecta idéntica a la referencia. No es necesario alcanzar una puntuación de 100: una puntuación BLEU entre 40 y 60 indica una traducción de alta calidad.
¿Qué ocurre si no envío datos de optimización o prueba?
Las frases de optimización y de prueba son una representación óptima de lo que planea traducir en el futuro. Si no envía ningún dato de optimización o de prueba, Traductor personalizado excluye automáticamente frases de los documentos de entrenamiento para usarlas como datos de optimización y prueba.
| Generada por el sistema | Selección manual |
|---|---|
| Conveniente. | Permite ajustar las necesidades futuras. |
| Bueno, si sabe que los datos de entrenamiento son representativos de lo que planea traducir. | Proporciona más libertad para crear los datos de entrenamiento. |
| Fácil de rehacer cuando se aumenta o se reduce el dominio. | Permite más datos y una mejor cobertura del dominio. |
| Cambia cada ejecución de entrenamiento. | Permanece estático en las ejecuciones de entrenamiento repetidas. |
¿Cómo procesa Traductor personalizado el material de entrenamiento?
Para prepararse para el entrenamiento, los documentos se someten a una serie de pasos de procesamiento y filtrado. El conocimiento del proceso de filtrado puede ayudar a comprender el número de frases que se muestra, así como los pasos que puede seguir para preparar los documentos de entrenamiento para el entrenamiento con Traductor personalizado. Los pasos de filtrado son los siguientes:
Alineación de frases
Si el documento no está en formato
XLIFF,XLSX,TMXoALIGN, Traductor personalizado alinea las oraciones de los documentos de origen y de destino entre sí, oración por oración. El Traductor personalizado no realiza la alineación del documento, sigue la convención de nomenclatura de los documentos para buscar el documento coincidente en el otro idioma. Dentro del texto de origen, Traductor personalizado intenta encontrar la frase correspondiente en el idioma de destino. Usa el marcado de documento, como etiquetas HTML incrustadas, para ayudar con la alineación.Si observa una gran discrepancia entre el número de frases en los documentos de origen y de destino, es posible que el documento de origen no sea paralelo o no se pueda alinear. Si el documento se empareja con una gran diferencia (>10 %) de oraciones en cada lado, deberá asegurarse de que están realmente en paralelo.
Extracción de datos de optimización y prueba
Los datos de optimización y prueba son opcionales. Si no los proporciona, el sistema quita un porcentaje adecuado de los documentos de entrenamiento para su uso en la optimización y las pruebas. La eliminación se produce dinámicamente como parte del proceso de entrenamiento. Dado que este paso se produce como parte del entrenamiento, los documentos cargados no se ven afectados. Puede ver los recuentos finales de frases usadas para cada categoría de datos (entrenamiento, optimización, pruebas y diccionario) en la página de detalles del modelo después de que el entrenamiento se realice correctamente.
Filtro de longitud
- Quita las frases con solo una palabra a ambos lados.
- Quita las frases con más de 100 palabras a ambos lados. Las frases en chino, japonés o coreano están exentas.
- Quita las frases con menos de tres caracteres. Las frases en chino, japonés o coreano están exentas.
- Quita las frases con más de 2000 caracteres en chino, japonés o coreano.
- Quita las frases con menos del 1 % de caracteres alfanuméricos.
- Quita las entradas de diccionario que contengan más de 50 palabras.
Espacio en blanco
- Reemplaza cualquier secuencia de caracteres de espacios en blanco, incluyendo las tabulaciones y las secuencias de retorno de carro y avance de línea, por un único carácter de espacio.
- Quita los espacios iniciales o finales de la frase.
Puntuación de final de frase
Reemplaza varios caracteres de puntuación de final de frase por una sola instancia. Normalización de caracteres japoneses.
Convierte las letras y dígitos de ancho completo en caracteres de medio ancho.
Etiquetas XML sin escape
Transforma las etiquetas sin caracteres de escape en etiquetas con caracteres de escape:
Etiqueta Se convierte en < < > > & & Caracteres no válidos
Traductor personalizado quita frases que contengan el carácter Unicode U+FFFD. El carácter U+FFFD indica una conversión de codificación incorrecta.
¿Qué pasos debo realizar antes de cargar los datos?
- Quite las frases con una codificación no válida.
- Quite los caracteres de control Unicode.
- Si es factible, alinee las frases (de origen a destino).
- Quite las frases de origen y destino que no coincidan con los idiomas de origen y destino.
- Cuando las frases de origen y destino tienen idiomas mixtos, asegúrese de que las palabras sin traducir sean intencionadas, por ejemplo, nombres de organizaciones y productos.
- Evite enseñar errores al modelo asegurándose de que la gramática y la tipografía son correctas.
- Asigne una frase de origen a una frase de destino. Aunque nuestro proceso de entrenamiento controla las líneas de origen y de destino que contienen varias oraciones, la asignación uno a uno es la opción recomendable.
¿Cómo puedo evaluar los resultados?
Una vez entrenado correctamente el modelo, puede ver la puntuación BLEU del modelo y la puntuación BLEU del modelo de línea base en la página de detalles del modelo. Usamos el mismo conjunto de datos de prueba para generar la puntuación BLEU del modelo y la puntuación BLEU de base de referencia. Estos datos le ayudan a tomar una decisión informada sobre qué modelo sería mejor para su caso de uso.