Descripción de los modelos de almacén de datos
Los sistemas empresariales actuales administran volúmenes cada vez mayores de datos heterogéneos. Esta heterogeneidad implica que un solo almacén de datos no suele ser la mejor opción. En su lugar, a menudo es mejor almacenar distintos tipos de datos en diferentes almacenes de datos, cada uno centrado en un patrón concreto de carga de trabajo o uso. El término persistencia de Polyglot se usa para describir soluciones que emplean una combinación de tecnologías de almacenamiento de datos. Por lo tanto, es importante comprender los principales modelos de almacenamiento y sus desventajas.
Seleccionar el almacén de datos adecuado para sus requisitos es una decisión de diseño clave. Existen literalmente cientos de implementaciones a elegir entre bases de datos SQL y NoSQL. Los almacenes de datos a menudo se clasifican según la forma de estructurar los datos y según los tipos de operaciones que admiten. Este artículo describe algunos de los modelos de almacenamiento más comunes. Tenga en cuenta que una tecnología de almacén de datos determinada puede admitir varios modelos de almacenamiento. Por ejemplo, un sistema de administración de bases de datos relacionales (RDBMS) también puede admitir el almacenamiento de clave-valor o de gráficos. De hecho, hay una tendencia general hacia el denominado soporte multimodelo, en el que un único sistema de base de datos es compatible con varios modelos. Pero aún así, es útil comprender los diferentes modelos en un nivel alto.
No todos los almacenes de datos de una determinada categoría proporcionan el mismo conjunto de características. La mayoría de los almacenes de datos proporcionan funciones del lado servidor para consultar y procesar datos. A veces, estas funciones están integradas en el motor de almacenamiento de datos. En otros casos, se separan las funcionalidades de almacenamiento y procesamiento de datos y puede haber varias opciones para el procesamiento y el análisis. Los almacenes de datos también admiten distintas interfaces de programación y administración.
Por lo general, lo primero que debe tener en cuenta es qué modelo de almacenamiento se ajusta mejor a sus requisitos. Posteriormente, debe considerar un almacén de datos determinado de esa categoría en función de factores como el conjunto de características, el costo y la facilidad de administración.
Nota
Consulte más información sobre cómo identificar y revisar los requisitos del servicio de datos para la adopción de la nube en Revisión de las opciones de datos. Del mismo modo, también puede obtener información en Revisión de las opciones de almacenamiento.
Sistemas de administración de bases de datos relacionales
Las bases de datos relacionales organizan los datos como una serie de tablas bidimensionales con filas y columnas. La mayoría de los proveedores proporcionan un dialecto del Lenguaje de consulta estructurado (SQL) para recuperar y administrar los datos. Normalmente, un sistema de administración de bases de datos relacionales implementa un mecanismo transaccionalmente coherente que se ajusta al modelo ACID (atomicidad, coherencia, aislamiento, durabilidad) para actualizar la información.
Normalmente, un RDBMS admite un modelo de esquema basado en escritura, en la que la estructura de los datos se define por adelantado y todas las operaciones de lectura o escritura deben usar ese esquema.
Este modelo es muy útil cuando es importante contar con unas sólidas garantías de coherencia, en las que todos los cambios son atómicos y las transacciones siempre dejan los datos en un estado coherente. Sin embargo, un RDBMS generalmente no se puede escalar horizontalmente sin particionar los datos de alguna manera. Además, los datos de un RDBMS se deben normalizar, lo que no es adecuado para todos los conjuntos de datos.
Servicios de Azure
- Azure SQL Database | (Base de referencia de seguridad)
- Azure Database for MySQL | (Base de referencia de seguridad)
- Azure Database for PostgreSQL | (Base de referencia de seguridad)
- Azure Database for MariaDB | (Base de referencia de seguridad)
Carga de trabajo
- Los registros se crean y actualizan con frecuencia.
- Se deben realizar varias operaciones en una sola transacción.
- Las relaciones se aplican mediante restricciones de base de datos.
- Se usan índices para optimizar el rendimiento de las consultas.
Tipo de datos
- Los datos están muy normalizados.
- Los esquemas de base de datos son necesarios y se aplican.
- Relaciones de muchos a muchos entre entidades de datos de la base de datos.
- Las restricciones se definen en el esquema y se imponen en todos los datos de la base de datos.
- Los datos necesitan una integridad elevada. Los índices y las relaciones deben mantenerse con precisión.
- Los datos requieren una sólida coherencia. Las transacciones funcionan de forma que garantizan que todos los datos sean totalmente coherentes para todos los usuarios y procesos.
- El tamaño de las entradas de datos individuales es de tamaño pequeño a medio.
Ejemplos
- Administración de inventario
- Administración de pedidos
- Informes de base de datos
- Control
Almacenes clave-valor
Un almacén de pares de clave-valor asocia cada valor de datos a una clave única. La mayoría de los almacenes clave valor solo admiten operaciones simples de consulta, inserción y eliminación. Para modificar un valor (parcial o completamente), una aplicación debe sobrescribir los datos existentes para todo el valor. En la mayoría de las implementaciones, leer o escribir un valor único es una operación atómica.
Una aplicación puede almacenar datos arbitrarios como un conjunto de valores. La aplicación debe proporcionar la información de esquema. El almacén de pares de clave-valor simplemente recupera o almacena el valor por clave.
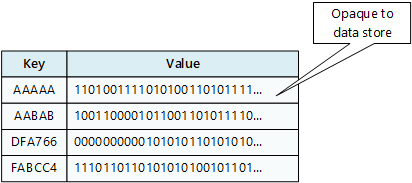
Los almacenes de pares de clave-valor están altamente optimizados para las aplicaciones que realizan búsquedas simples, pero son menos adecuados si necesita consultar datos entre diferentes almacenes de pares de clave-valor. Los almacenes de pares de clave-valor tampoco están optimizados para realizar consultas por el valor.
Un único almacén clave/valor puede ser sumamente escalable, ya que el almacén de datos puede distribuir fácilmente los datos entre varios nodos de máquinas independientes.
Servicios de Azure
- Azure Cosmos DB for Table y Azure Cosmos DB for NoSQL | (Base de referencia de seguridad de Azure Cosmos DB)
- Azure Cache for Redis | (Base de referencia de seguridad)
- Azure Table Storage | (Base de referencia de seguridad)
Carga de trabajo
- Se accede a los datos mediante una sola clave, como un diccionario.
- No se necesitan combinaciones, bloqueos ni uniones.
- No se usa ningún mecanismo de agregación.
- Los índices secundarios no se suelen usar.
Tipo de datos
- Cada clave está asociada a un valor único.
- No hay ninguna aplicación del esquema.
- No existen relaciones entre entidades.
Ejemplos
- Almacenamiento en caché de datos
- Administración de sesiones
- Administración de perfiles y preferencias de usuario
- Recomendación de producto y servicio
Bases de datos de documentos
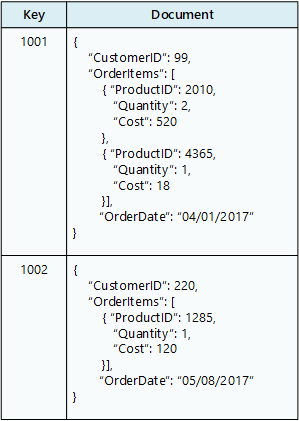
Una base de datos de documentos almacena una colección de documentos, donde cada documento consta de campos con nombre y datos. Los datos pueden ser valores simples o elementos complejos como listas y colecciones secundarias. Los documentos se recuperan mediante claves únicas.
Normalmente, un documento contiene los datos de una sola entidad, como un cliente o un pedido. Un documento puede contener información que se podría distribuir en varias tablas relacionales de un RDBMS. No es necesario que los documentos tengan la misma estructura. Las aplicaciones pueden almacenar datos diferentes en documentos a medida que cambian los requisitos empresariales.
Servicio de Azure
Carga de trabajo
- Las operaciones de inserción y actualización son comunes.
- No hay ningún error de coincidencia de impedancia relacional de objetos. Los documentos pueden coincidir mejor con las estructuras de objetos usadas en el código de la aplicación.
- Los documentos individuales se recuperan y escriben como un solo bloque.
- Los datos necesitan un índice en varios campos.
Tipo de datos
- Los datos pueden administrarse de manera no normalizada.
- El tamaño de los datos de documentos individuales es relativamente pequeño.
- Cada tipo de documento puede usar su propio esquema.
- Los documentos pueden incluir campos opcionales.
- Los datos del documento son semiestructurados, lo que significa que los tipo de datos de cada campo no se definen estrictamente.
Ejemplos
- Catálogo de productos
- Administración de contenido
- Administración de inventario
Bases de datos de gráficos
Una base de datos de grafos almacena dos tipos de información: nodos y bordes. Los bordes especifican las relaciones entre los nodos. Los nodos y los bordes pueden tener propiedades que proporcionan información acerca de ese nodo o borde de forma parecida a las columnas de una tabla. Los bordes también pueden tener una dirección que indica la naturaleza de la relación.
Las bases de datos de grafos pueden realizar consultas en la red de nodos y bordes y analizar las relaciones entre entidades de forma eficaz. El siguiente diagrama muestra la base de datos del personal de una organización estructurada como un grafo. Las entidades son los empleados y los departamentos y los bordes indican las relaciones jerárquicas y el departamento en el que trabajan los empleados.
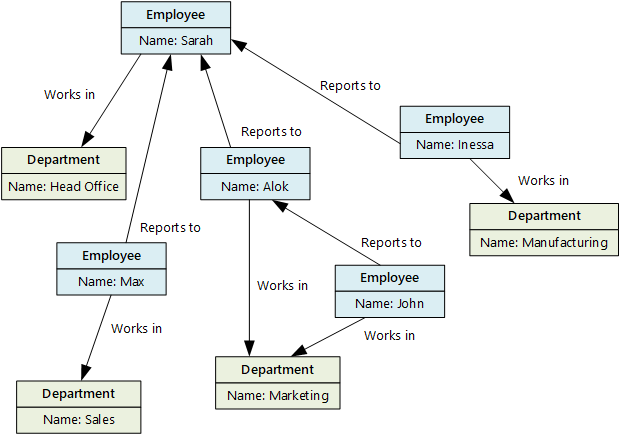
Esta estructura facilita la realización de consultas como "Buscar todos los empleados que dependen directa o indirectamente de Sarah" o "¿Quién trabaja en el mismo departamento que John?". En el caso de gráficos grandes con una gran cantidad de entidades y relaciones, puede realizar análisis muy complejos con mucha rapidez. Muchas bases de datos de grafos proporcionan un lenguaje de consulta que puede usar para recorrer una red de relaciones de forma eficaz.
Servicios de Azure
- Azure Cosmos DB for Apache Gremlin | (Base de referencia de seguridad)
- SQL Server | (Base de referencia de seguridad)
Carga de trabajo
- Relaciones complejas entre elementos de datos que implican muchos saltos entre los elementos de datos relacionados.
- La relación entre elementos de datos es dinámica y cambia con el tiempo.
- Las relaciones entre objetos son ciudadanos de primera clase, sin requerir claves externas ni combinaciones que recorrer.
Tipo de datos
- Nodos y relaciones.
- Los nodos son similares a las filas de tabla o documentos JSON.
- Las relaciones son tan importantes como los nodos y se exponen directamente en el lenguaje de consulta.
- Los objetos compuestos, como una persona con varios números de teléfono, tienden a dividirse en nodos independientes más pequeños que se combinan con relaciones que se pueden recorrer
Ejemplos
- Organigramas
- Gráficos sociales
- Detección de fraudes
- Motores de recomendaciones
Análisis de datos
Los almacenes de análisis de datos proporcionan masivamente soluciones paralelas para ingerir, almacenar y analizar datos. Los datos se distribuyen entre varios servidores para maximizar la escalabilidad. Los formatos de archivo de datos de gran tamaño, como los archivos con delimitadores (CSV), Parquet y ORC, se usan ampliamente en el análisis de datos. Los datos históricos se suelen almacenar en almacenes de datos como Blob Storage o Azure Data Lake Storage Gen2, a los que Azure Synapse, Databricks o HDInsight acceden posteriormente como tablas externas. En el artículo Uso de tablas externas con Synapse SQL se describe un escenario típico en el que se usan los datos almacenados como archivos Parquet para el rendimiento.
Servicios de Azure
- Azure Synapse Analytics | (Base de referencia de seguridad)
- Azure Data Lake | (Base de referencia de seguridad)
- Azure Data Explorer | (Base de referencia de seguridad)
- Azure Analysis Services
- HDInsight | (Base de referencia de seguridad)
- Azure Databricks | (Base de referencia de seguridad)
Carga de trabajo
- Análisis de datos
- BI empresarial
Tipo de datos
- Datos históricos de varios orígenes.
- Normalmente se desnormaliza en un esquema de "estrella" o "copo de nieve", que consta de tablas de hechos y dimensiones.
- Suele cargarse con datos nuevos de forma programada.
- Las tablas de dimensiones suelen incluir varias versiones históricas de una entidad, conocida como dimensión de variación lenta.
Ejemplos
- Almacenamiento de datos empresarial
Bases de datos de familia de columnas
Una base de datos de familia de columnas organiza los datos en filas y columnas. En su forma más simple, una base de datos de familia de columnas puede parecer muy similar a una base de datos relacional, al menos desde el punto de vista conceptual. La eficacia real de una base de datos de familia de columnas radica en su enfoque desnormalizado para estructurar datos dispersos.
Puede pensar en una base de datos de familia de columnas como un elemento que contiene datos tabulares con filas y columnas, pero las columnas se dividen en grupos conocidos como familias de columnas. Cada familia de columnas contiene un conjunto de columnas que están relacionadas de forma lógica entre ellas y que se pueden recuperar o manipular normalmente como una unidad. Otros datos a los que se accede de forma independiente se pueden almacenar en familias de columnas independientes. En una familia de columnas, se pueden agregar nuevas columnas dinámicamente y las filas se pueden dispersar (es decir, no es necesario que una fila tenga un valor para cada columna).
El siguiente diagrama muestra un ejemplo con dos familias de columnas, Identity y Contact Info. Los datos de una sola entidad tienen la misma clave de fila en cada familia de columnas. Esta estructura, en la que las filas de cualquier objeto determinado de una familia de columnas puede variar dinámicamente, constituye una ventaja importante del enfoque de familia de columnas, que hace que este tipo de almacén de datos resulte muy adecuado para almacenar datos estructurados y volátiles.

A diferencia de un almacén clave/valor o una base de datos de documentos, la mayoría de las bases de datos de familia de columnas almacenan los datos en el orden de la clave, en lugar de mediante el cálculo de un algoritmo hash. Muchas implementaciones le permiten crear índices en columnas específicas de una familia de columnas. Los índices le permiten recuperar datos por el valor de las columnas, en lugar de por la clave de fila.
Las operaciones de lectura y escritura de una fila son normalmente atómicas con una sola familia de columnas, aunque algunas implementaciones proporcionan atomicidad en toda la fila abarcando varias familias de columnas.
Servicios de Azure
- Azure Cosmos DB for Apache Cassandra | (Base de referencia de seguridad)
- HBase en HDInsight | (Base de referencia de seguridad)
Carga de trabajo
- La mayoría de las bases de datos de familia de columnas realizan operaciones de escritura muy rápidamente.
- Las operaciones de actualización y eliminación son poco habituales.
- Diseñado para proporcionar acceso de baja latencia y alto rendimiento.
- Admite el acceso de consulta sencillo a un conjunto determinado de campos dentro de un registro mucho más grande.
- Escalable a gran escala.
Tipo de datos
- Los datos se almacenan en tablas formadas por una columna de clave y una o varias familias de columnas.
- Las columnas específicas pueden variar en filas individuales.
- Se accede a las celdas individuales a través de los comandos GET y PUT.
- Se devuelven varias filas utilizando un comando SCAN.
Ejemplos
- Recomendaciones
- Personalización
- datos del sensor
- Telemetría
- Mensajería
- Análisis de redes sociales
- Análisis web
- Supervisión de la actividad
- El tiempo y otros datos de serie temporal
Bases de datos de motor de búsqueda
Una base de datos de motor de búsqueda permite que las aplicaciones busquen información contenida en almacenes de datos externos. Una base de datos de motor de búsqueda puede indexar volúmenes de datos masivos y proporcionar acceso a estos índices casi en tiempo real.
Los índices pueden ser multidimensionales y pueden admitir búsquedas de texto sin formato en grandes volúmenes de datos de texto. La indexación se puede realizar mediante un modelo de extracción, desencadenado por la base de datos de motor de búsqueda, o mediante un modelo de inserción, iniciado por un código externo de la aplicación.
La búsqueda puede ser exacta o aproximada. Una búsqueda aproximada busca documentos que coinciden con un conjunto de términos y calcula el grado de coincidencia. Algunos motores de búsqueda también admiten el análisis lingüístico que puede devolver coincidencias basadas en sinónimos, expansiones de género (por ejemplo, una coincidencia entre dogs a pets) y lematización (coincidencia de palabras con la misma raíz).
Servicio de Azure
Carga de trabajo
- Índices de datos de varios orígenes y servicios.
- Las consultas son ad-hoc y pueden ser complejas.
- Se requiere la búsqueda de texto completo.
- Se necesita una consulta de autoservicio ad-hoc.
Tipo de datos
- Texto semiestructurado o no estructurado
- Texto con referencia a los datos estructurados
Ejemplos
- Catálogos de productos
- Búsqueda de sitio
- Registro
Bases de datos de series temporales
Los datos de series temporales son un conjunto de valores que se organizan por horas. Las bases de datos de series temporales recopilan normalmente grandes cantidades de datos en tiempo real a partir de un gran número de orígenes. Las actualizaciones son poco frecuentes y las eliminaciones se realizan a menudo como operaciones masivas. Aunque los registros que se escriben en una base de datos de series temporales suelen ser pequeños, suele haber un gran número de registros y el tamaño total de los datos puede crecer rápidamente.
Servicio de Azure
Carga de trabajo
- Los registros suelen anexarse secuencialmente en orden cronológico.
- Una proporción de operaciones masiva (95-99 %) son las escrituras.
- Las actualizaciones son poco frecuentes.
- Las eliminaciones se producen de forma masiva y se realizan en bloques contiguos o registros.
- Los datos se leen secuencialmente en orden cronológico ascendente o descendente, a menudo en paralelo.
Tipo de datos
- Se usa una marca de tiempo como clave principal y mecanismo de ordenación.
- Las etiquetas pueden definir información adicional sobre el tipo, el origen y otra información sobre la entrada.
Ejemplos
- Supervisión y telemetría de eventos.
- Sensor u otros datos de IoT.
Almacenamiento de objetos
El almacenamiento de objetos está optimizado para almacenar y recuperar objetos binarios grandes (imágenes, archivos, transmisiones de vídeo y audio, objetos de datos de aplicación de gran tamaño, documentos e imágenes de disco de máquina virtual). Los archivos de datos de gran tamaño también se usan con frecuencia en este modelo, por ejemplo, los archivos con delimitadores (CSV), Parquet y ORC. Los almacenes de objetos pueden administrar cantidades enormes de datos no estructurados.
Servicio de Azure
- Azure Blob Storage | (Base de referencia de seguridad)
- Azure Data Lake Storage Gen2 | (Base de referencia de seguridad)
Carga de trabajo
- Identificado por clave.
- El contenido suele ser un recurso, como un delimitador, una imagen o un archivo de vídeo.
- El contenido debe ser duradero y externo a cualquier capa de aplicación.
Tipo de datos
- El tamaño de los datos es grande.
- El valor es opaco.
Ejemplos
- Imágenes, vídeos, documentos de Office y archivos PDF
- HTML estático, JSON, CSS
- Archivos de registro y auditoría
- Copias de seguridad de bases de datos
Archivos compartidos
En ocasiones, el uso de archivos planos simples puede ser el medio más eficaz para almacenar y recuperar información. El uso de recursos compartidos de archivos permite acceder a los archivos a través de una red. Si se proporciona la seguridad adecuada y los mecanismos de control de acceso simultáneo, el uso compartido de datos de esta forma puede permitir a los servicios distribuidos proporcionar un acceso altamente escalable a los datos para realizar operaciones básicas, de nivel bajo, tales como solicitudes sencillas de lectura y escritura.
Servicio de Azure
Carga de trabajo
- Migración de las aplicaciones existentes que interactúan con el sistema de archivos.
- Requiere la interfaz SMB.
Tipo de datos
- Archivos en un conjunto jerárquico de carpetas.
- Se puede acceder con bibliotecas estándar de E/S.
Ejemplos
- Archivos heredados
- Contenido compartido accesible entre una serie de máquinas virtuales o instancias de aplicaciones
Con el conocimiento de los diferentes modelos de almacenamiento de datos, el siguiente paso es evaluar la carga de trabajo y la aplicación y decidir qué almacén de datos satisfará sus necesidades específicas. Use el árbol de decisión de almacenamiento de datos como ayuda en este proceso.
Pasos siguientes
- Servicios y soluciones de almacenamiento en la nube de Azure
- Revisión de las opciones de almacenamiento
- Introducción a Almacenamiento de Azure
- Introducción a Azure Data Explorer
Recursos relacionados
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de