La inteligencia artificial (IA) y el aprendizaje automático (ML) ofrecen oportunidades y desafíos únicos para las operaciones que abarcan los mundos virtual y físico. La inteligencia artificial y el aprendizaje automático pueden reconocer correlaciones entre los datos de entrada del mundo real y los resultados, y tomar decisiones que automaticen sistemas industriales físicos complejos. Sin embargo, los sistemas de aprendizaje automático de IA no pueden realizar funciones cognitivas de nivel superior, como la exploración, la improvisación, el pensamiento creativo ni determinación de causalidad.
La enseñanza automática es un nuevo paradigma para los sistemas de aprendizaje automático que:
- Infunde experiencia en la materia en modelos de sistemas automatizados de IA.
- Utiliza el aprendizaje de refuerzo profundo para detectar patrones en el proceso de aprendizaje y adoptar comportamientos positivos en sus propios métodos.
- Aprovecha entornos simulados para generar grandes cantidades de datos sintéticos para casos de uso y escenarios específicos de un dominio.
El aprendizaje automático se centra en desarrollar algoritmos de aprendizaje novedosos o en mejorar los algoritmos existentes. La enseñanza automática se centra en la eficacia de los profesores mismos. Abstraerse de la complejidad de la IA para centrarse en la experiencia en la materia y en las condiciones del mundo real crea modelos eficaces de IA y ML que convierten los sistemas de control automatizados en sistemas autónomos.
En este artículo se abordan los conceptos y desarrollos históricos de la inteligencia artificial que se usan en la enseñanza automática. En un artículo relacionado se tratan los sistemas autónomos en detalle.
Historia de la automatización
Durante miles de años, los seres humanos han estado diseñando herramientas y máquinas físicas para realizar tareas de manera más eficaz. Estas tecnologías pretenden lograr resultados de manera más uniforme, con un costo menor y con un trabajo manual menos directo.
La Primera Revolución Industrial, desde finales del siglo XVIII hasta mediados del XIX, presentó máquinas para reemplazar los métodos de producción a mano en la fabricación. La Revolución Industrial aumentó la eficacia de la producción mediante la automatización con la alimentación a vapor y mediante la consolidación, al trasladar la producción de los hogares a las fábricas organizadas. La Segunda Revolución Industrial, desde mediados del siglo XIX hasta comienzos del XX, mejoró la capacidad de producción a través de la electrificación y las líneas de producción.
La Primera y la Segunda Guerras Mundiales introdujeron grandes avances en la teoría de la información, las comunicaciones y el procesamiento de señales. La creación del transistor permitió que la teoría de la información se aplicara fácilmente al control de los sistemas físicos. Esta Tercera Revolución Industrial permitió que los sistemas informáticos se adentraran en el control rígido de los sistemas físicos, como producción, transporte y atención sanitaria. Las ventajas de la automatización programada incluyen uniformidad, confiabilidad y seguridad.
La Cuarta Revolución Industrial presentó la noción de sistemas ciberfísicos y la Internet de las cosas (IoT) industrial. Los sistemas que las personas desean controlar se han vuelto demasiado grandes y complejos para escribir reglas totalmente preparadas. La inteligencia artificial permite que las máquinas inteligentes realicen tareas para las que normalmente se necesita inteligencia humana. El aprendizaje automático permite que las máquinas aprendan y mejoren automáticamente la experiencia sin que se programe explícitamente.
IA y ML
IA y ML no son nuevos conceptos, y muchas de las teorías se han mantenido inalteradas durante décadas, pero los avances tecnológicos recientes en el almacenamiento, el ancho de banda y la informática permiten predicciones de algoritmos más precisas y útiles. Una mayor capacidad de procesamiento de los dispositivos, la miniaturización, la capacidad de almacenamiento y la capacidad de red permiten la automatización adicional de sistemas y equipos. Estos avances también permiten la recopilación y la intercalación de enormes cantidades de datos de sensores en tiempo real.
La automatización cognitiva es la aplicación de software e IA a procesos y sistemas con una gran cantidad de información. La IA cognitiva puede potenciar a los trabajos manuales para aumentar la productividad, reemplazar a los trabajadores humanos en campos monótonos o peligrosos, y brindar nuevas perspectivas debido a los enormes volúmenes de datos que puede procesar. Las tecnologías cognitivas, como la visión artificial, el procesamiento de lenguajes naturales, los bots y la robótica, pueden realizar tareas que antes solo podían hacer los seres humanos.
Muchos sistemas de producción actuales automatizan y alcanzan impresionantes logros de ingeniería y fabricación mediante robots industriales. El uso y la evolución de la automatización industrial en los sectores manufactureros generan productos más seguros y de mayor calidad con un uso más eficiente de la energía y de las materias primas. Sin embargo, en la mayoría de los casos, los robots solo pueden funcionar en entornos sumamente estructurados. En general, se muestran inflexibles a cambiar y están altamente especializados en tareas inmediatas. Los robots también pueden ser caros de desarrollar debido a las reglas de hardware y software que rigen sus comportamientos.
La paradoja de la automatización afirma que, cuanto más eficiente se vuelve un sistema automatizado, más importante se vuelve el componente humano para el funcionamiento. El rol de los seres humanos cambia del trabajo mundano por unidad de trabajo a la mejora y la administración del sistema automatizado y a contribuir con su experiencia esencial del dominio. Si bien un sistema automatizado puede producir resultados de forma más eficaz, también puede generar pérdidas y problemas si está mal diseñado o no funciona correctamente. El uso eficaz de la automatización hace que los seres humanos sean más importantes, no menos.
Casos de uso de IA
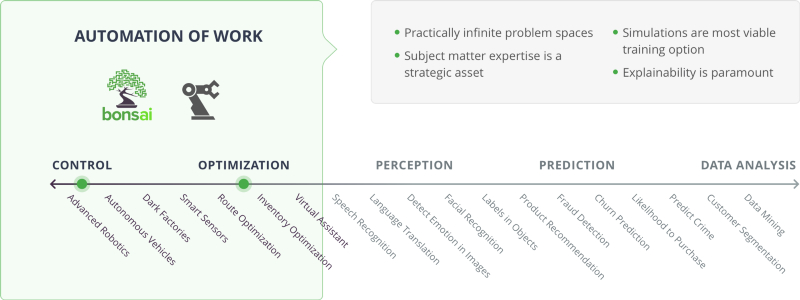
En el diagrama anterior, las categorías Control y Optimization (optimización) se relacionan con la automatización del trabajo. En este lado del espectro de la IA, existen prácticamente espacios de problema infinitos. La experiencia en la materia es un activo estratégico, las simulaciones son la opción de entrenamiento más factible, y la capacidad de explicación es primordial.
Los orquestadores incluyen la fabricación inteligente y la plataforma de enseñanza automática Bonsai. Entre los casos de uso se incluyen robótica avanzada, vehículos autónomos, fábricas a oscuras, sensores inteligentes, optimización de rutas, optimización de inventario y asistentes virtuales.
Aprendizaje de refuerzo
La enseñanza automática depende del aprendizaje de refuerzo (RL) para entrenar los modelos, detectar patrones en el proceso de aprendizaje y adoptar comportamientos positivos en sus propios métodos. El aprendizaje de refuerzo profundo (DRL) aplica el aprendizaje de refuerzo a las redes neuronales complejas de aprendizaje profundo.
El aprendizaje de refuerzo en el aprendizaje automático trata sobre la manera en que los agentes de software aprenden a maximizar las recompensas y los resultados deseados en sus entornos. El aprendizaje de refuerzo es uno de los tres paradigmas básicos del aprendizaje automático:
- El aprendizaje supervisado se generaliza a partir de datos etiquetados o estructurados.
- El aprendizaje sin supervisión comprime los datos no etiquetados ni estructurados.
- El aprendizaje de refuerzo funciona por medio del ensayo y error.
Aunque el aprendizaje supervisado es el aprendizaje por medio del ejemplo, el aprendizaje de refuerzo es el aprendizaje por medio de la experiencia. A diferencia del aprendizaje supervisado, que se centra en buscar y etiquetar conjuntos de datos adecuados, el aprendizaje de refuerzo se centra en diseñar modelos de cómo realizar tareas.
Los componentes clave del aprendizaje de refuerzo son:
- Agente: Entidad que puede tomar una decisión para cambiar el entorno actual.
- Entorno: Mundo físico o simulado en el que opera el agente.
- Estado: Situación actual del agente y su entorno.
- Acción: Interacción del agente en su entorno.
- Recompensa: Retroalimentación del entorno, a partir de una acción del agente.
- Política: Método o función para asignar el estado actual del agente y su entorno a las acciones.
El aprendizaje de refuerzo usa las políticas y las funciones de recompensa para evaluar las acciones del agente y proporcionar retroalimentación. A través de la toma de decisiones secuencial basada en el entorno actual, los agentes aprenden a maximizar la recompensa a lo largo del tiempo y a predecir las mejores acciones posibles en situaciones específicas.
El aprendizaje de refuerzo enseña al agente a completar un objetivo al recompensar un comportamiento deseado y no recompensar un comportamiento no deseado. En el diagrama siguiente se ilustra el flujo conceptual del aprendizaje de refuerzo y cómo interactúan los componentes clave:
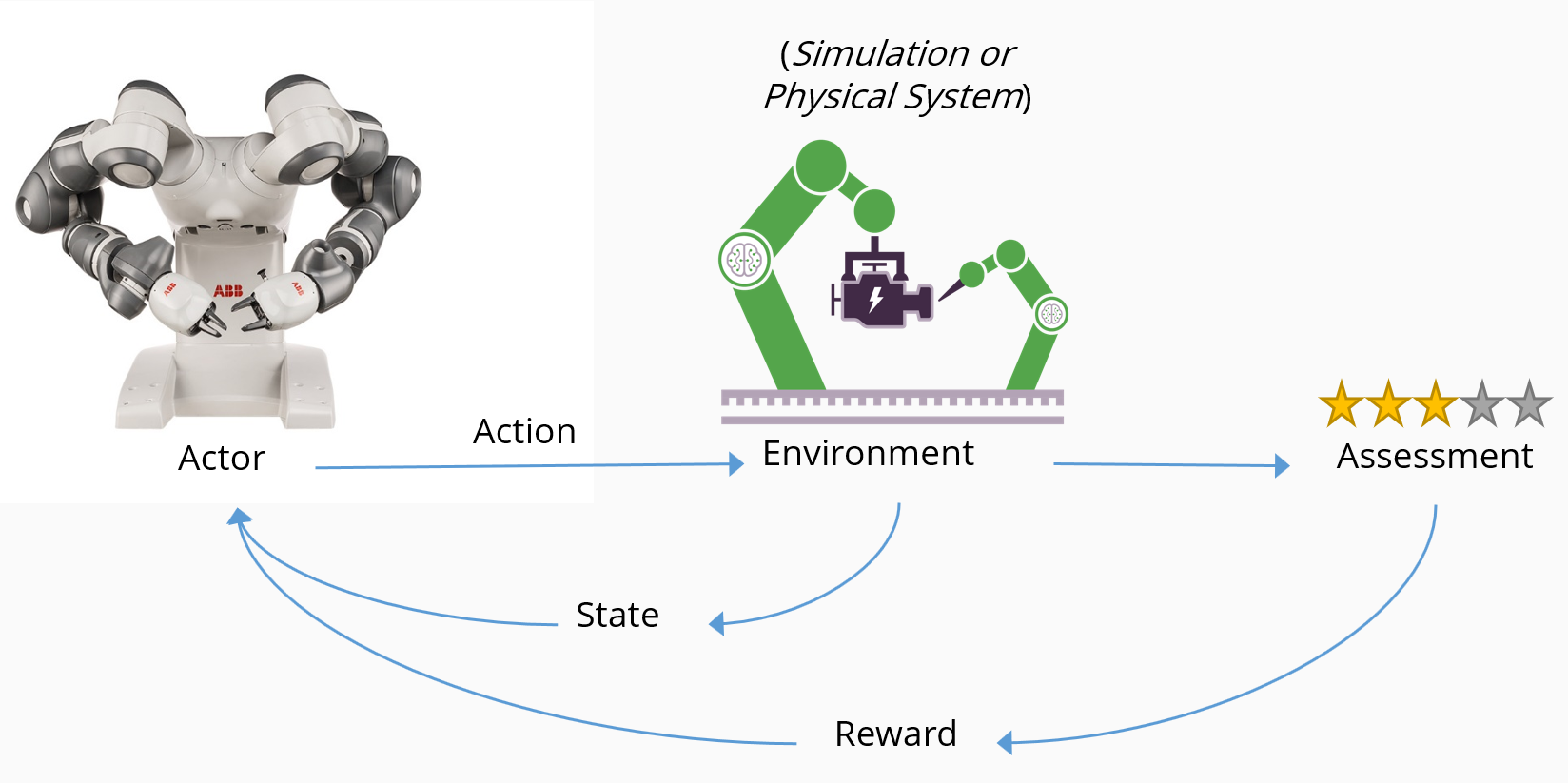
- Un agente —en este caso, un robot— realiza una acción en un entorno —en este caso, una línea de fabricación inteligente—.
- La acción hace que el entorno cambie de estado y devuelva su estado cambiado al agente.
- Un mecanismo de evaluación aplica una política para establecer qué consecuencia se debe entregar al agente.
- El mecanismo de recompensa fomenta acciones beneficiosas al entregar un premio positivo, y puede desalentar las acciones negativas al proporcionar una penalización.
- Las recompensas provocan que las acciones deseadas aumenten, mientras que las penalizaciones provocan que se reduzcan las acciones no deseadas.
Un problema puede ser estocástico (aleatorio) por naturaleza o determinista. Aunque un agente es lo más común, también puede haber varios agentes en el entorno. El agente detecta el entorno mediante observación. El entorno puede ser observable total o parcialmente, según lo determinen los sensores del agente, y las observaciones pueden ser discretas o continuas.
Cada observación va seguida de una acción, lo que hace que el entorno cambie. Este ciclo se repite hasta que se alcance un estado terminal. Normalmente, el sistema no tiene memoria, y el algoritmo simplemente se preocupa por el estado del que procede, el estado al que llega y el premio que recibe.
A medida que el agente aprende por medio del ensayo y error, necesita grandes cantidades de datos para evaluar sus acciones. El principal ámbito de aplicación del aprendizaje de refuerzo es en los dominios que tienen grandes cuerpos históricos de datos, o que pueden generar fácilmente datos simulados.
Funciones de recompensa
Una función de recompensa determina con cuánto y cuándo se debe recompensar una acción determinada. La definición de la estructura de las recompensas normalmente se deja a cargo del propietario del sistema. Ajustar este parámetro puede afectar significativamente a los resultados.
El agente utiliza la función de recompensa para obtener información sobre la física y la dinámica del mundo que lo rodea. El proceso fundamental por el que un agente aprende a maximizar su recompensa, al menos inicialmente, es el ensayo y error.
Equilibrio entre exploración y explotación
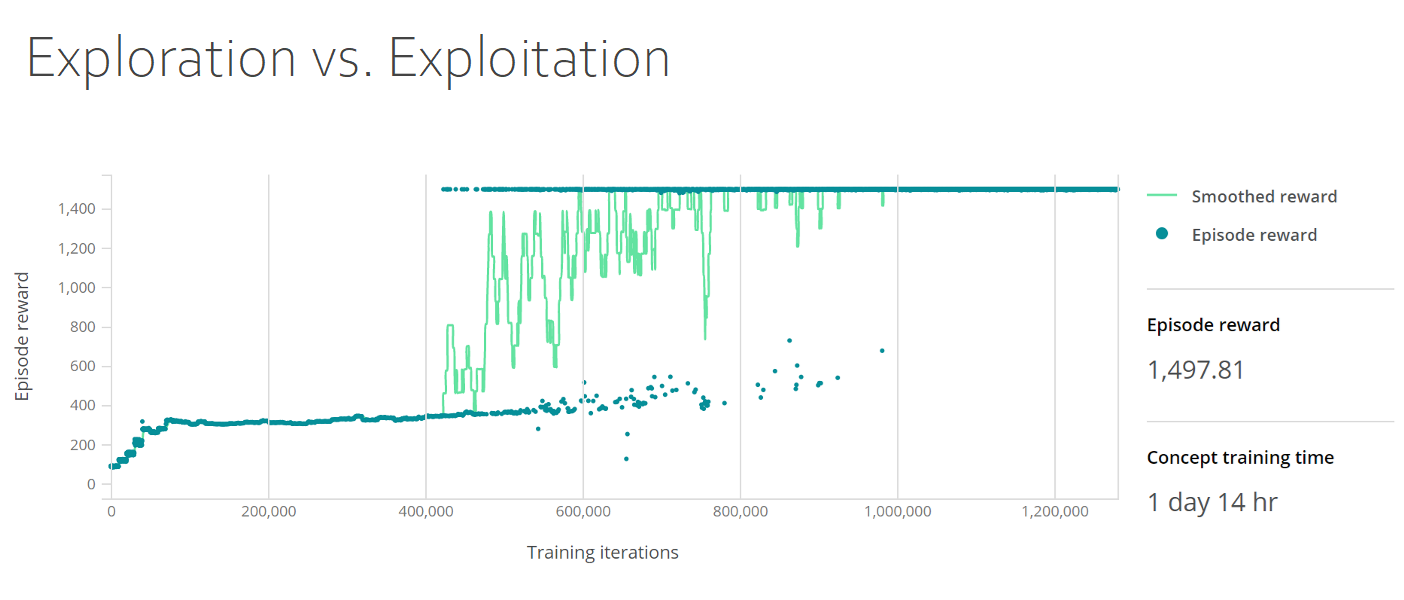
Según el objetivo y la función de recompensa, el agente debe equilibrar la exploración frente a la maximización de su recompensa. Esta elección se conoce como equilibrio entre exploración y explotación. Al igual que en muchos aspectos del mundo real, el agente debe equilibrar las ventajas de una mayor exploración del entorno, lo que puede dar lugar a mejores decisiones en el futuro, con la explotación del entorno, aprovechando todo el conocimiento que el agente tiene actualmente sobre todo el mundo para maximizar la recompensa. Realizar diferentes acciones puede ofrecer una perspectiva nueva, en especial si las acciones no se han intentado antes.
En el panel de entrenamiento siguiente se muestra el equilibrio entre exploración y explotación. En el gráfico se muestran las recompensas suavizadas y las recompensas por episodio, donde las recompensas por episodio se ubican en el eje Y; y las iteraciones de entrenamiento, en el eje X. La densidad de las recompensas por episodio aumenta hasta 400 en las primeras 50 000 iteraciones y, después, sigue siendo constante hasta las 400 000 iteraciones, cuando aumenta a 1500 y permanece constante.
El efecto cobra
Las recompensas están sujetas a lo que se conoce en economía como el efecto cobra. Durante el dominio británico de la India colonial, el Gobierno decidió reducir la enorme población de cobras salvajes, para lo que ofrecía un premio por cada cobra muerta. Inicialmente, esta política tuvo éxito, ya que se mataron grandes cantidades de estas serpientes para reclamar la recompensa. Sin embargo, no pasó mucho tiempo hasta que la gente comenzó a engañar al sistema y a criar cobras a propósito para cobrar la recompensa. Finalmente, las autoridades observaron este comportamiento y cancelaron el programa. Ya sin ningún incentivo, los criadores de cobras liberaron a sus serpientes, con lo que la población de cobras salvajes terminó por aumentar en comparación con la situación al comienzo del incentivo.
El incentivo bien intencionado había hecho que la situación empeorara, no mejorara. La moraleja de esta historia es que los agentes aprenden el comportamiento que se incentiva, lo que podría no producir el resultado esperado.
Recompensas con forma
La creación de una función de recompensa con una forma determinada puede permitir que el agente aprenda una política adecuada con mayor facilidad y rapidez.
Una función escalonada es un ejemplo de una función de recompensa dispersa, que no indica al agente el grado de acierto de su acción. En la siguiente función de recompensa escalonada, solo una acción de distancia entre 0,0 y 0,1 genera una recompensa completa de 1,0. Cuando la distancia es mayor que 0,1, no hay ninguna recompensa.

Por el contrario, una función de recompensa con forma da al agente una señal de cuán próxima está la acción a la respuesta deseada. La siguiente función de recompensa con forma brinda una mayor recompensa en función de la proximidad de la respuesta a la acción 0,0 deseada. La curva de la función es una hipérbola. La recompensa es 1,0 para la distancia 0,0 y desciende gradualmente hasta 0,0 a medida que la distancia se acerca a 1,0.
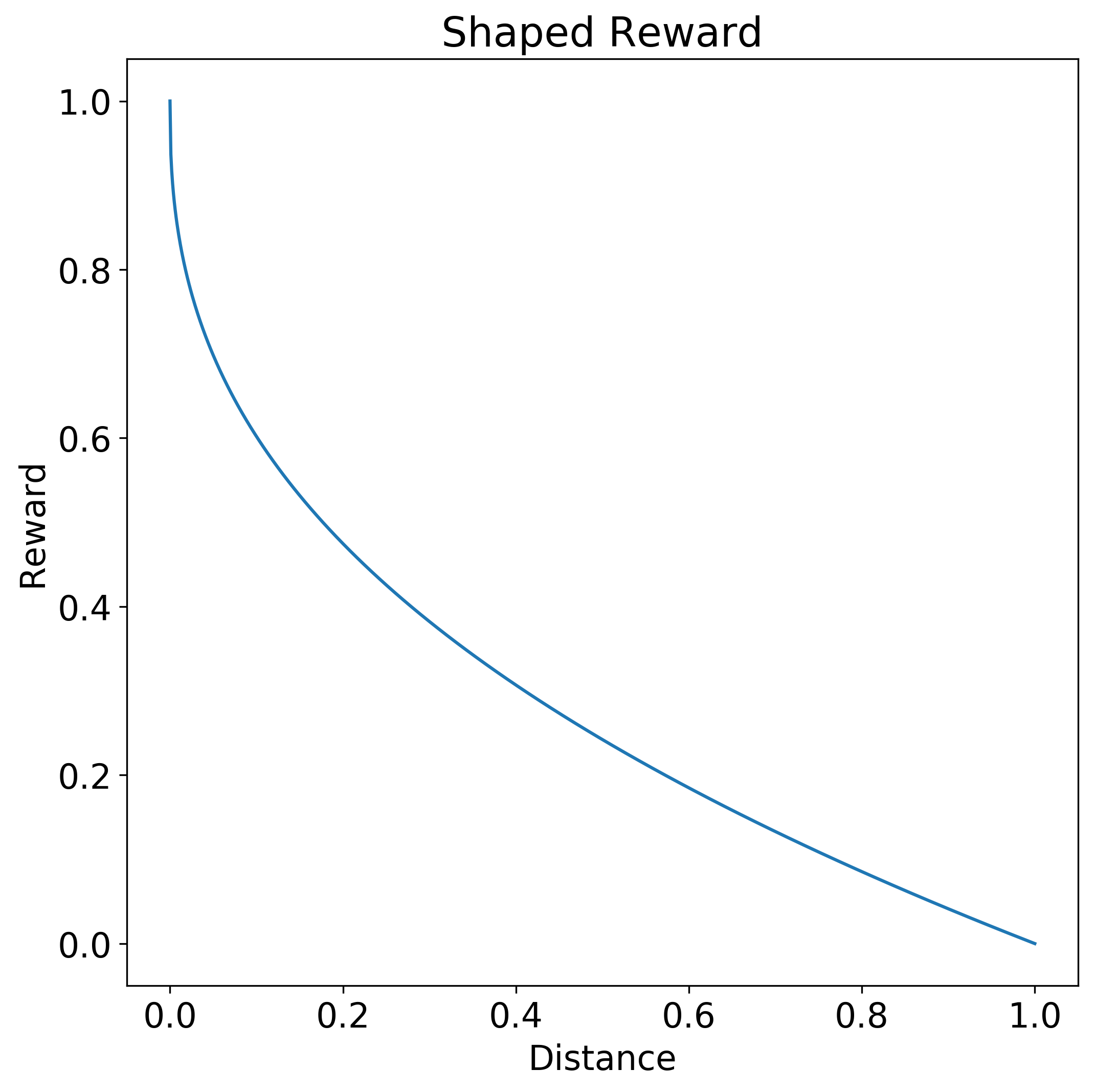
La aplicación de una forma puede descontar el valor de una recompensa futura frente a una recompensa más inmediata, o bien fomentar la exploración al reducir el tamaño de las recompensas en torno al objetivo.
A veces, una función de recompensa podría especificar consideraciones temporales y espaciales para fomentar secuencias ordenadas de acciones. Sin embargo, si una función de recompensa con forma se está volviendo grande y compleja, considere la posibilidad de dividir el problema en fases más pequeñas y usar redes conceptuales.
Redes conceptuales
Las redes conceptuales permiten especificar y reutilizar conocimiento específico de un dominio y experiencia en la materia para recopilar una ordenación deseada de comportamientos en una secuencia específica de tareas independientes. Las redes conceptuales ayudan a restringir el espacio de búsqueda en el que el agente puede operar y realizar acciones.
En la siguiente red conceptual para captar y apilar objetos, el cuadro Grasp and Stack (Captar y apilar) es el elemento principal de dos cuadros grises, Reach (Alcanzar) y Move (Mover), y de tres cuadros verdes, Orient (Orientar), Grasp (Captar) y Stack (Apilar).
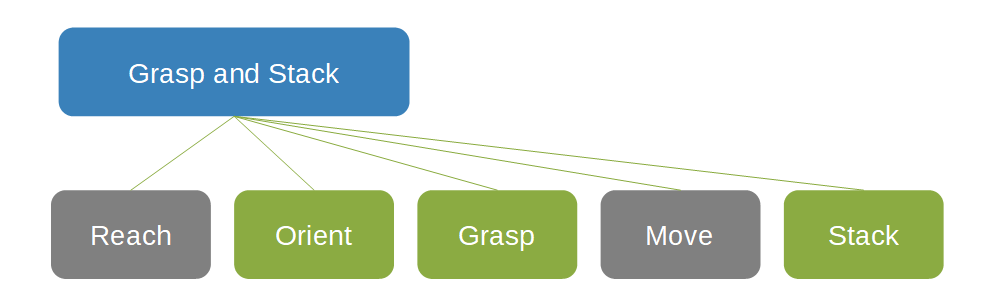
En general, las redes conceptuales permiten definir más fácilmente las funciones de recompensa. Cada concepto puede usar el enfoque más adecuado para esa tarea. La noción de redes conceptuales ayuda a la descomposición de la solución en sus elementos constitutivos. Los componentes se pueden reemplazar sin volver a entrenar todo el sistema, lo que permite la reutilización de modelos previamente entrenados y el uso de controladores existentes u otros componentes del ecosistema existentes. En especial en los sistemas de control industriales, la mejora por etapas incremental puede ser más conveniente que la eliminación y el reemplazo completos.
Aprendizaje curricular y aprendizaje por imitación
Dividir el problema en tareas secuenciales independientes con redes conceptuales permite desglosar el problema en grados de dificultad y presentarlo al agente como un plan de estudios con una dificultad creciente. Este enfoque por fases comienza con un problema sencillo, permite al agente practicar y, luego, le presenta retos cada vez más desafiantes a medida que aumenta su capacidad. La función de recompensa cambia y evoluciona a medida que el agente se vuelve más capaz en su tarea. Este enfoque de aprendizaje curricular ayuda a guiar la exploración y reduce enormemente el tiempo de entrenamiento necesario.
También se puede restringir el espacio de búsqueda de políticas para el agente si se indica que se aprenda imitando el comportamiento de un experto externo. El aprendizaje por imitación usa patrones guiados por expertos para limitar el espacio de estados que explora el agente. El aprendizaje por imitación permite el aprendizaje de soluciones conocidas con mayor rapidez, pero a costa de no descubrir soluciones novedosas.
Un ejemplo de aprendizaje por imitación es enseñar a un agente de un coche autónomo a imitar las acciones de un conductor humano. El agente aprende a conducir, pero también hereda los defectos y la idiosincrasia del instructor.
Diseño de sistemas de IA basados en aprendizaje de refuerzo
La estrategia siguiente es una guía práctica para construir y crear sistemas de IA basados en aprendizaje de refuerzo:
- Formule y itere los estados, condiciones terminales, acciones y recompensas.
- Genere funciones de recompensas y asígneles forma según sea necesario.
- Asigne recompensas para objetivos secundarios específicos.
- Descuente las recompensas de manera agresiva si es necesario.
- Experimente con los estados iniciales.
- Experimente con un muestreo de ejemplos de entrenamiento.
- Limite la variación de los parámetros de la dinámica de simulación durante el entrenamiento.
- Generalice durante la predicción y mantenga la uniformidad del entrenamiento lo más posible.
- Introduzca algún ruido físicamente relevante para dar cabida al ruido en las máquinas reales.
Simulaciones
Los sistemas de inteligencia artificial necesitan muchísimos datos y deben tener exposición a muchos escenarios con el fin de asegurarse de que estén entrenados para tomar las decisiones adecuadas. Los sistemas suelen exigir prototipos costosos que corren el riesgo de sufrir daños en entornos del mundo real. El costo de recopilar y etiquetar manualmente los datos de entrenamiento de alta fidelidad es alto, tanto en cuanto a tiempo como a trabajo directo. El uso de simuladores y datos de entrenamiento densamente etiquetados generados por simuladores es un medio eficaz para abordar gran parte de este déficit de datos.
La maldición de la dimensión hace referencia a los fenómenos que surgen cuando se trabaja con grandes cantidades de datos en espacios de múltiples dimensiones. Modelar con precisión determinados escenarios y conjuntos de problemas requiere el uso de redes neuronales profundas. Estas propias redes presentan múltiples dimensiones, con muchos parámetros que deben ajustarse. A medida que aumenta la dimensionalidad, el volumen del espacio aumenta a una tasa que permite que los datos del mundo real se dispersen, lo que dificulta la recopilación de datos suficientes para realizar correlaciones estadísticamente significativas. Sin datos suficientes, el entrenamiento genera un modelo que no se ajusta a los datos y no se generaliza bien a los nuevos datos, lo que impide alcanzar el propósito de un modelo.
El problema es doble:
- El algoritmo de entrenamiento tiene una gran capacidad de aprendizaje para modelar el problema con precisión, pero necesita más datos para evitar el ajuste insuficiente.
- Recopilar y etiquetar esta gran cantidad de datos, si bien es factible, es difícil, caro y propenso a errores.
Las simulaciones ofrecen una alternativa a tener que recopilar grandes cantidades de datos de entrenamiento del mundo real, ya que modelan de manera virtual los sistemas en sus entornos físicos previstos. Las simulaciones permiten el entrenamiento en entornos peligrosos, o en condiciones difíciles de reproducir en el mundo real, como en varios tipos de condiciones meteorológicas. Los datos simulados artificialmente evitan la dificultad de la recopilación de datos y mantienen los algoritmos correctamente alimentados con escenarios de ejemplo que les permiten generalizar el mundo real con precisión.
Las simulaciones son el origen de entrenamiento ideal para el aprendizaje de refuerzo profundo, ya que son:
- Flexibles a los entornos personalizados.
- Seguras y rentables para la generación de datos.
- Paralelizables, lo que permite tiempos de entrenamiento más breves.
Las simulaciones están disponibles en una amplia gama de industrias y sistemas, como ingeniería mecánica y eléctrica, vehículos autónomos, seguridad y redes, transporte y logística, y robótica.
Entre las herramientas de simulación se incluyen:
- Simulink, herramienta de programación gráfica desarrollada por MathWorks para el modelado, la simulación y el análisis de sistemas dinámicos.
- Gazebo, herramienta que permite simular de forma precisa las poblaciones de robots en entornos interiores y exteriores complejos.
- Microsoft AirSim, plataforma de simulación robótica de código abierto.
Paradigma de la enseñanza automática
La enseñanza automática ofrece un nuevo paradigma para la creación de sistemas de aprendizaje automático, que aleja el foco de los algoritmos y lo pone en la generación e implementación correctas de modelos. La enseñanza automática identifica patrones en el propio proceso de aprendizaje y adopta un comportamiento positivo en su propio método. Gran parte de la actividad del aprendizaje automático se centra en mejorar los algoritmos existentes o desarrollar algoritmos de aprendizaje novedosos. Por el contrario, la enseñanza automática se centra en la eficacia de los profesores mismos.
Enseñanza automática:
- Combina la experiencia en la materia de expertos humanos en el dominio con IA y ML.
- Automatiza la generación y administración de algoritmos y modelos de aprendizaje de refuerzo profundo.
- Integra simulaciones para la optimización y escalabilidad de los modelos.
- Permite una mejor explicación del comportamiento de los modelos resultantes.
En gran medida, el estado del aprendizaje automático ha sido determinado por unos pocos expertos en algoritmos. Estos expertos comprenden enormemente el aprendizaje automático y pueden cambiar el algoritmo o la arquitectura de ML para satisfacer las métricas necesarias de rendimiento o precisión. La cantidad de expertos en ML en todo el mundo puede calcularse en torno a las decenas de miles, lo que reduce la adopción de soluciones de ML. La subyugante complejidad de los modelos coloca las funcionalidades del ML fuera del alcance de muchos.
Aunque los expertos en ML son pocos, abundan los expertos en la materia. En todo el mundo hay decenas de millones de expertos en distintos dominios. La enseñanza automática se aprovecha de este grupo mayor de expertos que comprenden la semántica de los problemas y pueden proporcionar ejemplos, pero no necesitan conocer las complejidades del aprendizaje automático. La enseñanza automática es la abstracción fundamental necesaria para programar de forma eficaz la experiencia en la materia al codificar qué enseñar y cómo enseñar. Los expertos en la materia sin conocimientos de IA pueden desglosar su experiencia en pasos y tareas, criterios y resultados deseados.
En el caso de los ingenieros, la enseñanza automática eleva el listón de la abstracción más allá de la selección de algoritmos de IA y el ajuste de los hiperparámetros, para centrarse en problemas de dominio de aplicación más valiosos. Los ingenieros que construyen sistemas autónomos pueden crear modelos precisos y detallados de sistemas y entornos, y hacerlos inteligentes mediante métodos como el aprendizaje profundo, el aprendizaje por imitación y el aprendizaje de refuerzo. Otra consecuencia bienvenida de la enseñanza automática es un menor tiempo para la implementación de modelos, ya que se reduce o elimina la necesidad de intervención manual de los expertos de aprendizaje automático durante el desarrollo.
La enseñanza automática simplifica el proceso de creación de soluciones de aprendizaje automático mediante el examen de prácticas comunes de ML y la adopción de estrategias beneficiosas en sus propios métodos. Con las instrucciones y la configuración del desarrollador, Bonsai —el servicio de enseñanza automática en la plataforma de sistemas autónomos de Microsoft— puede automatizar el desarrollo de modelos de IA en un sistema de IA.
Bonsai brinda un panel central fácilmente comprensible que realiza un seguimiento del estado actual de cada proyecto con herramientas de control de versiones. El uso de esta infraestructura de enseñanza automática garantiza que los resultados del modelo se puedan reproducir, y permite que los desarrolladores actualicen fácilmente los sistemas de IA con futuros avances en los algoritmos de IA.
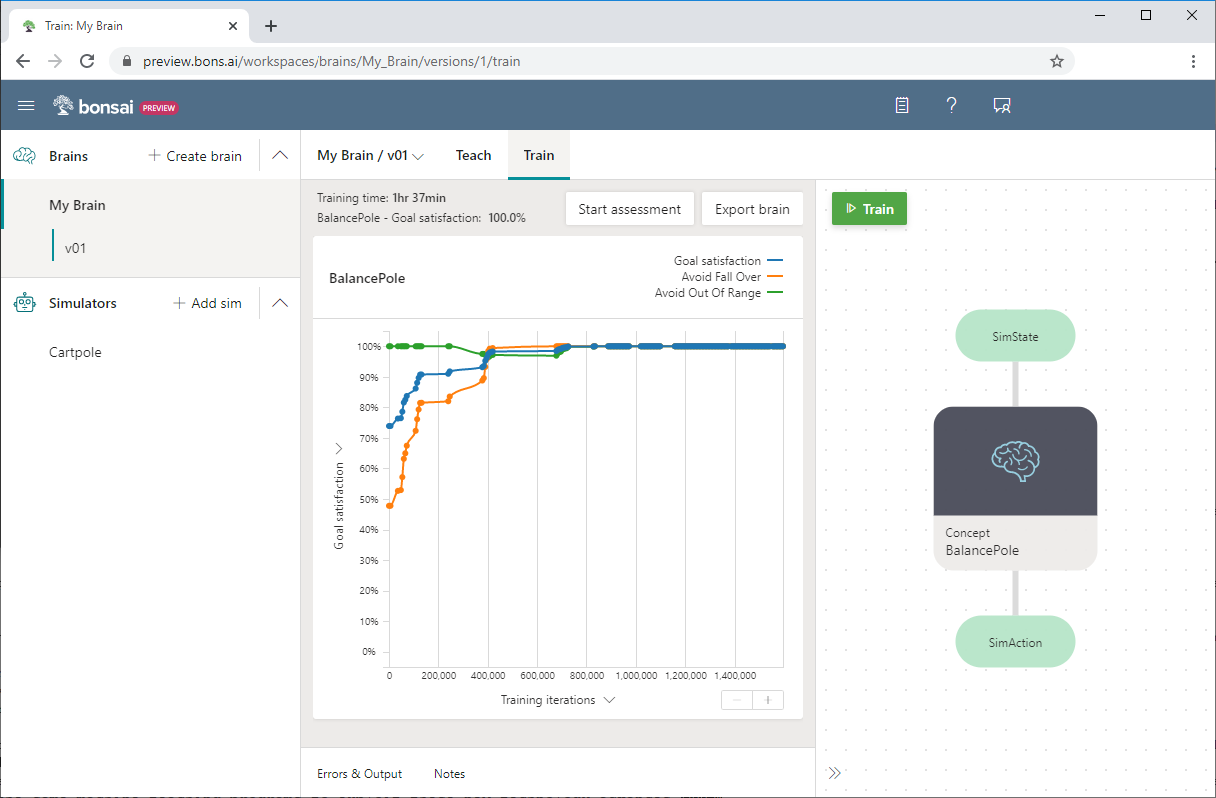
Un cambio de perspectiva hacia una metodología de enseñanza automática promueve la adopción del aprendizaje automático con un proceso más simplificado y accesible con el fin de generar e implementar modelos de aprendizaje automático. La enseñanza automática permite a los expertos de un dominio aplicar la eficacia del aprendizaje de refuerzo profundo como herramienta. La enseñanza automática cambia el foco de la tecnología de IA de los algoritmos y técnicas de aprendizaje automático a la aplicación de estos algoritmos a problemas del mundo real por parte de expertos del dominio.
Proceso de la enseñanza automática
El desarrollo y la implementación de la enseñanza automática constan de tres fases: Creación, entrenamiento e implementación.
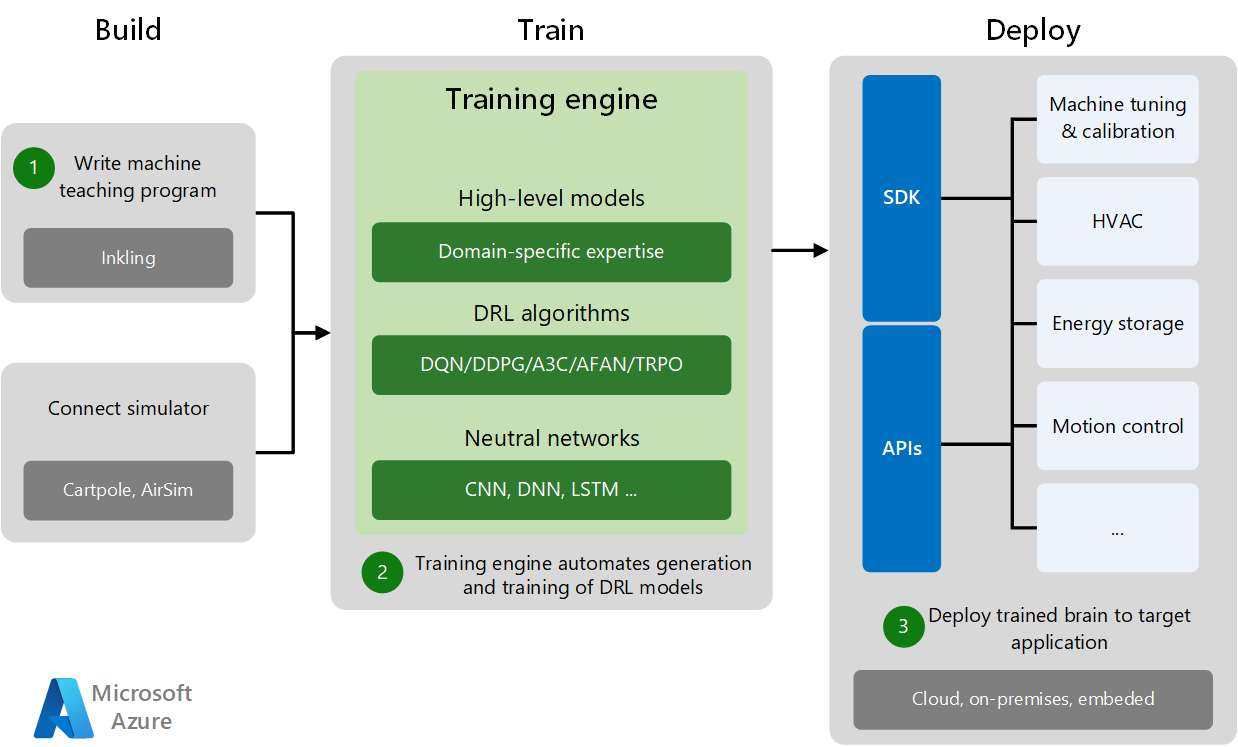
- La fase de creación consiste en escribir el programa de enseñanza automática y conectarse a un simulador de entrenamiento específico del dominio. Los simuladores generan suficientes datos de entrenamiento para los experimentos y las prácticas de la máquina.
- En la fase de entrenamiento, el motor de entrenamiento automatiza la generación y el entrenamiento del modelo de aprendizaje de refuerzo profundo mediante la combinación de modelos de dominio de alto nivel con algoritmos de aprendizaje de refuerzo profundo y redes neuronales adecuados.
- En la fase de implementación se implementa el modelo entrenado en la aplicación de destino en la nube, en el entorno local o insertado en el sitio. Los SDK y las API de implementación específicos implementan sistemas de IA entrenados en varias aplicaciones de destino, llevan a cabo la optimización de la máquina y controlan los sistemas físicos.
Los entornos simulados generan grandes cantidades de datos sintéticos que cubren muchos casos de uso y escenarios. Las simulaciones ofrecen una generación de datos segura y rentable para el entrenamiento de los algoritmos del modelo y menores tiempos de entrenamiento con paralelización de la simulación. Las simulaciones ayudan a entrenar los modelos en diferentes tipos de escenarios y condiciones del entorno, de manera mucho más rápida y segura de lo que es factible en el mundo real.
Los expertos en la materia pueden supervisar los agentes a medida que trabajan para solucionar problemas en entornos simulados, y proporcionan comentarios e instrucciones que permiten a los agentes adaptarse dinámicamente dentro de la simulación. Una vez completado el entrenamiento, los ingenieros implementan los agentes entrenados en el hardware real, donde pueden usar su conocimiento para alimentar los sistemas autónomos en el mundo real.
Aprendizaje automático y enseñanza automática
La enseñanza automática y el aprendizaje automático son complementarios y pueden evolucionar de forma independiente. La investigación en aprendizaje automático se centra en hacer mejor al alumno mediante la mejora de los algoritmos de aprendizaje automático. La investigación en enseñanza automática se centra en que el profesor sea más productivo en la creación de los modelos de aprendizaje automático. Las soluciones de enseñanza automática requieren varios algoritmos de aprendizaje automático para generar y probar los modelos a lo largo del proceso de enseñanza.
En el diagrama siguiente se muestra una canalización representativa para crear un modelo de aprendizaje automático:
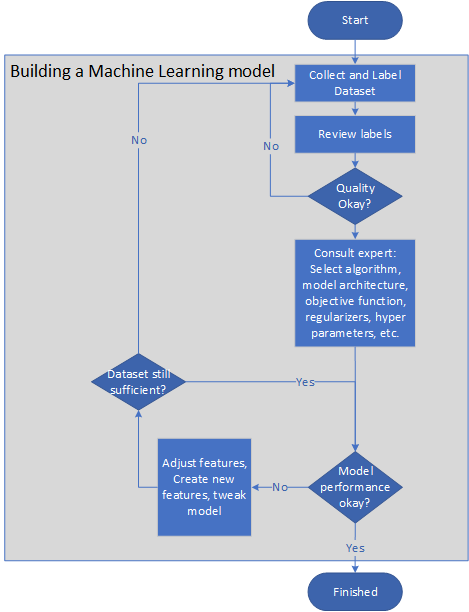
- El propietario del problema recopila y etiqueta conjuntos de datos, o elabora una guía de etiqueta para que la tarea de etiquetado pueda externalizarse.
- El propietario del problema revisa las etiquetas hasta que su calidad es satisfactoria.
- Los expertos en aprendizaje automático seleccionan un algoritmo, una arquitectura del modelo, una función objetiva, regularizadores y conjuntos de validación cruzada.
- Los ingenieros entrenan el modelo cíclicamente, ajustando las características o creando nuevas características para mejorar la precisión y velocidad del modelo.
- El modelo se prueba en una pequeña muestra. Si el sistema no supera correctamente la prueba, se repiten los pasos anteriores.
- El rendimiento del modelo se supervisa en el campo. Si el rendimiento cae por debajo de un nivel crítico, se repiten los pasos anteriores para modificar el modelo.
La enseñanza automática automatiza la creación de estos modelos, lo que disminuye la necesidad de intervención manual en el proceso de aprendizaje para mejorar la selección de características o ejemplos, o el ajuste de los hiperparámetros. En efecto, la enseñanza automática presenta un nivel de abstracción en los elementos de IA del modelo, lo que permite al desarrollador centrarse en el conocimiento del dominio. Además, esta abstracción permite que el algoritmo de IA se reemplace por nuevos algoritmos más innovadores en su momento, sin necesidad de volver a especificar el problema.
El rol del profesor es optimizar la transferencia de conocimiento al algoritmo de aprendizaje para que pueda generar un modelo útil. Los profesores también desempeñan un papel fundamental en la recopilación y el etiquetado de los datos. Los profesores pueden filtrar datos sin etiquetar para seleccionar ejemplos específicos, o ver los datos de ejemplo disponibles y adivinar su etiqueta en función de su propia intuición o sesgo. Del mismo modo, dadas dos características en un conjunto grande sin etiquetar, los profesores pueden calcular que una es mejor que la otra.
En la siguiente imagen se muestra el proceso general de la enseñanza automática:
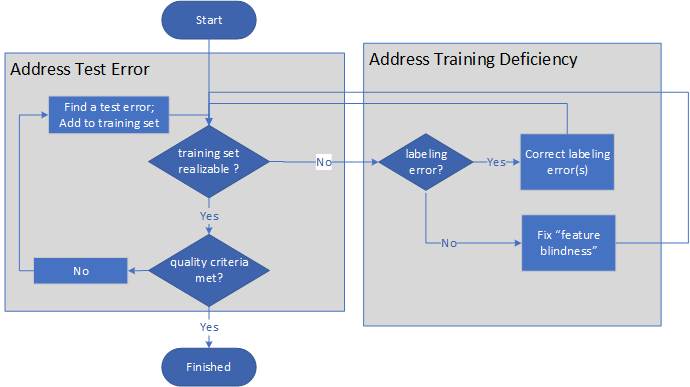
- En primer lugar, el profesor cuestiona si un conjunto de entrenamiento es viable.
- Si el conjunto de entrenamiento no es viable, el profesor determina si el problema se debe a un etiquetado inadecuado o deficiencias de las características. Después de corregir el etiquetado o de agregar características, el profesor vuelve a evaluar si el conjunto de entrenamiento es viable.
- Si el conjunto de entrenamiento es viable, el profesor evalúa si se cumplen los criterios de calidad de entrenamiento.
- Si no se cumplen los criterios de calidad, el profesor busca los errores de prueba y agrega las correcciones al conjunto de entrenamiento y luego repite los pasos de evaluación.
- Una vez que el conjunto de entrenamiento es viable y se cumplen los criterios de calidad, el proceso finaliza.
El proceso es un par de bucles indefinidos y termina solo cuando el modelo y el entrenamiento mismo tienen la calidad suficiente.
La capacidad de aprendizaje del modelo aumenta a petición. No es necesaria la regularización tradicional, ya que el profesor controla la capacidad del sistema de aprendizaje agregando características solo cuando es necesario.
Enseñanza automática y programación tradicional
La enseñanza automática es una forma de programación. El objetivo tanto de la programación como de la enseñanza automática es crear una función. Los pasos para crear una función de destino sin estado que devuelva el valor Y dada una entrada X son similares para ambos procesos:
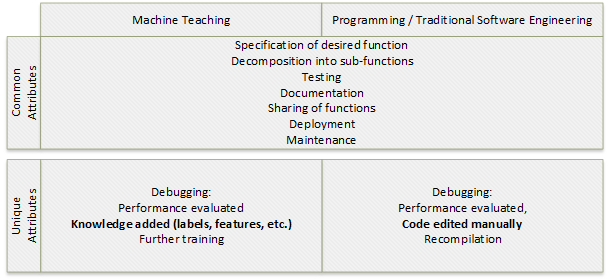
- Especificar la función de destino.
- Descomponer la función de destino en subfunciones, si procede.
- Depurar y probar las funciones y subfunciones.
- Documentar las funciones.
- Compartir las funciones.
- Implementar las funciones.
- Mantener las funciones con ciclos de depuración programados y no programados.
La depuración o evaluación del rendimiento de la solución tiene atributos diferentes entre los dos procesos. En la programación, la depuración implica la edición y recompilación manuales del código. En la enseñanza automática, la depuración incluye la adición de características y etiquetas de conocimiento, y un entrenamiento adicional.
La creación de una función de clasificación de destino que devuelve la clase Y dada la entrada X implica un algoritmo de aprendizaje automático, mientras que el proceso de enseñanza automática es como el conjunto de pasos de programación anteriores.
En la tabla siguiente se muestran algunas similitudes conceptuales entre la programación tradicional y la enseñanza automática:
| Programar | Enseñanza automática |
|---|---|
| Compilador | Algoritmos de aprendizaje automático, máquinas de vectores de soporte (SVM), redes neuronales, motor de entrenamiento |
| Sistemas operativos, servicios, entornos de desarrollo integrado (IDE) | Entrenamiento, muestreo, selección de características, servicio de entrenamiento automático |
| Marcos de trabajo | ImageNet, word2vec |
| Lenguajes de programación, como Python y C# | Inkling, etiquetas, características, esquemas |
| Experiencia en programación | Experiencia en enseñanza |
| Control de versiones | Control de versiones |
| Procesos de desarrollo, como especificaciones, pruebas unitarias, implementación, supervisión | Procesos de enseñanza, como recopilación de datos, pruebas, publicación |
Un concepto eficaz que permite a los ingenieros de software escribir sistemas que solucionan problemas complejos es la descomposición. La descomposición utiliza conceptos más sencillos para expresar otros más complejos. Los profesores de enseñanza automática pueden aprender a descomponer problemas complejos de aprendizaje automático con las herramientas y experiencias adecuadas. La disciplina de enseñanza automática puede llevar las expectativas de éxito de enseñar a una máquina a un nivel comparable al de la programación.
Proyectos de enseñanza automática
Requisitos previos:
- Cierta experiencia con la recopilación, exploración, limpieza, preparación y análisis de datos
- Familiaridad con los conceptos básicos del aprendizaje automático, como funciones objetivas, entrenamiento, validación cruzada y regularización
Al compilar un proyecto de enseñanza automática, empiece con un modelo realista, pero relativamente simple, para permitir una iteración y formulación rápidas. A continuación, mejore de manera iterativa la fidelidad del modelo y haga que el modelo sea más generalizable a través de una mejor cobertura del escenario.
En el diagrama siguiente se muestran las fases del desarrollo iterativo del modelo de enseñanza automática. Cada paso sucesivo requiere un mayor número de ejemplos de entrenamiento.
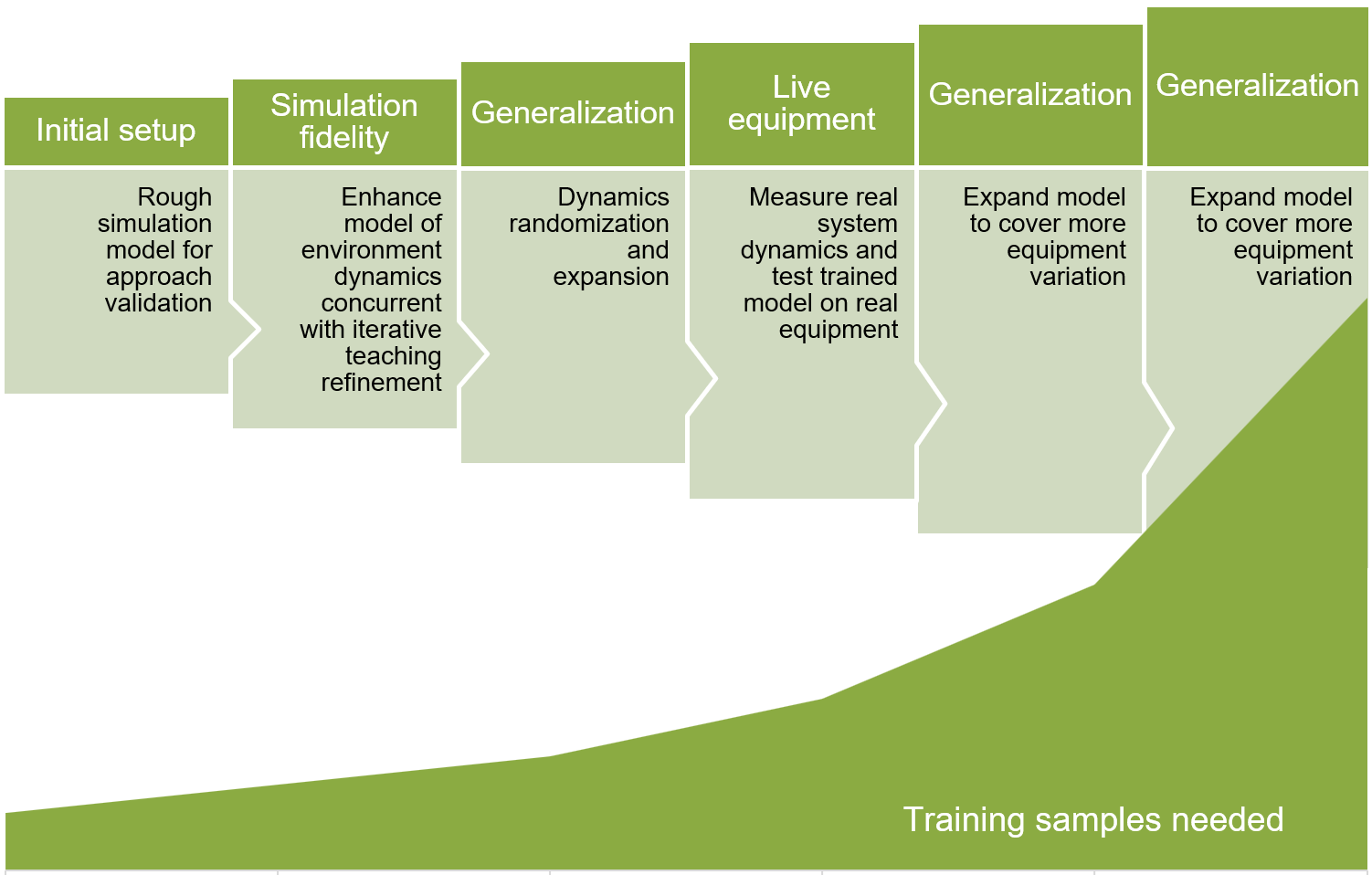
- Configure el modelo de simulación aproximado inicial para la validación del enfoque.
- Mejore la fidelidad de la simulación mediante el modelado de la dinámica del entorno de manera simultánea con las mejoras de enseñanza iterativas.
- Generalice el modelo con aleatorización y la expansión dinámicas.
- Mida la dinámica del sistema real y pruebe el modelo entrenado en el equipo real.
- Expanda el modelo para cubrir una variación de equipos.
La definición de parámetros exactos para proyectos de enseñanza automática requiere un poco de experimentación y exploración empírica. Una plataforma de enseñanza automática, como Bonsai en la plataforma de sistemas autónomos de Microsoft utiliza innovaciones y simulaciones de aprendizaje de refuerzo profundo para ayudar a simplificar el desarrollo de modelos de inteligencia artificial.
Proyecto de ejemplo
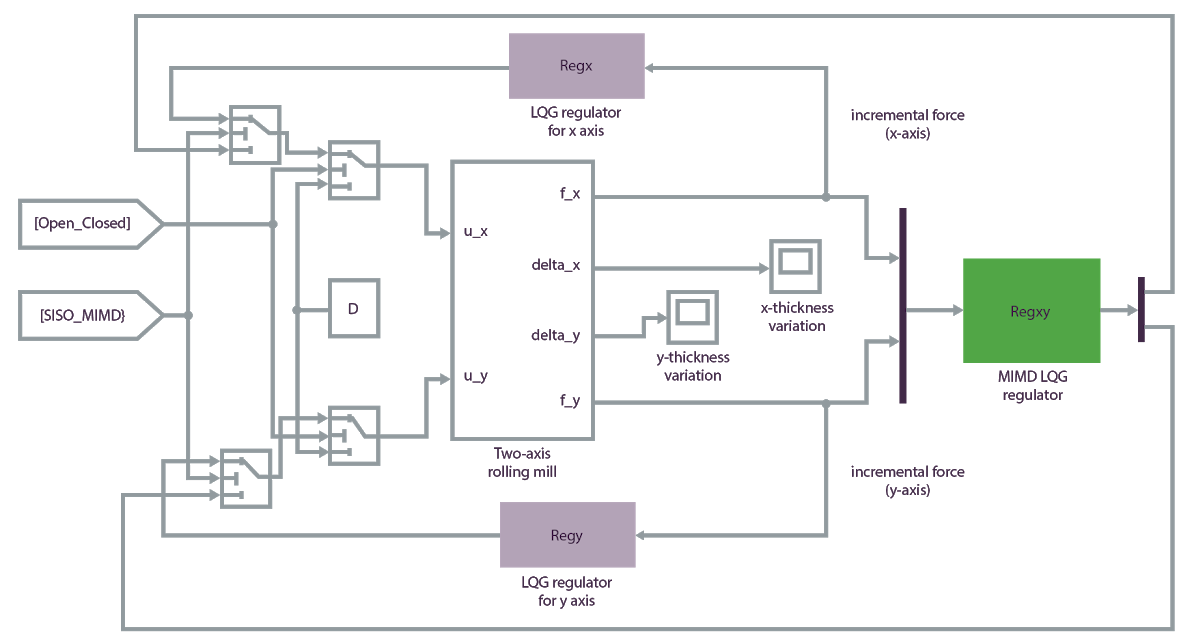
Un ejemplo de un proyecto de IA de sistemas autónomos es el caso de uso de una optimización de los procesos de fabricación. El objetivo es optimizar la tolerancia del grosor de un perfil de acero que se fabrica en una línea de producción. Los rodillos aplican presión en una pieza de acero para darle forma hasta el grosor diseñado.
Las entradas de estado de la máquina en el sistema IA son la fuerza de presión, el error de los rodillos y el ruido de los rodillos. Las acciones de control del sistema de IA son comandos del accionador para controlar el funcionamiento y el movimiento de los rodillos, y optimizar la tolerancia del grosor del perfil de acero.
En primer lugar, busque o desarrolle un simulador que pueda simular agentes, sensores y el entorno. El siguiente modelo de simulación de Matlab ofrece un entorno de entrenamiento preciso para este sistema de IA:
Use el servicio de enseñanza automática Bonsai en la plataforma de sistemas autónomos de Microsoft para crear un plan de enseñanza automática en un modelo, entrenar el modelo con el simulador e implementar el sistema de IA entrenado en la planta de producción real. Inkling es un lenguaje con fines específicos para describir formalmente los planes de enseñanza automática. En Bonsai, puede usar Inkling para deconstruir el problema en el esquema:

A continuación, defina los conceptos clave y cree un plan de estudios para enseñar al sistema de IA; para ello, especifique la función de recompensa para el estado de la simulación:

El sistema de IA aprende practicando la tarea de optimización en la simulación, siguiendo los conceptos de la enseñanza automática. Puede cargar la simulación en Bonsai, donde se proporcionan visualizaciones del progreso del entrenamiento mientras se ejecuta.
Después de generar y entrenar el modelo o cerebro, puede exportarlo para implementarlo en la planta de producción, donde los comandos óptimos de los accionadores se transmiten del motor de IA para apoyar las decisiones del operario en tiempo real.
Otras aplicaciones de ejemplo
En los siguientes ejemplos de enseñanza automática se crean políticas para controlar los movimientos de los sistemas físicos. En ambos casos, la creación manual de una política para el agente es inviable o muy difícil. Al permitir que el agente explore el espacio en la simulación y guiarlo para tomar decisiones a través de las funciones de recompensa, se generan soluciones precisas.
Cartpole
En el proyecto de muestra Cartpole de Bonsai, el objetivo es enseñar a un mástil a permanecer vertical en un carro en movimiento. El mástil está conectado mediante una unión no activada al carro, que se mueve a lo largo de una pista sin fricción. La información del sensor disponible incluye la posición y la velocidad del carro, y el ángulo de mástil y la velocidad angular.
Al aplicar una fuerza al carro, se controla el sistema. Las acciones admitidas del agente son empujar el carro a la izquierda o a la derecha. El programa brinda una recompensa positiva por cada incremento temporal que el mástil permanece en posición vertical. El episodio termina cuando el mástil está a más de 15 grados de la vertical o el carro se mueve más de un número predefinido de unidades desde el centro.
En el ejemplo se usa el lenguaje Inkling para escribir el programa de enseñanza automática, y el simulador Cartpole proporcionado para acelerar y mejorar el entrenamiento.
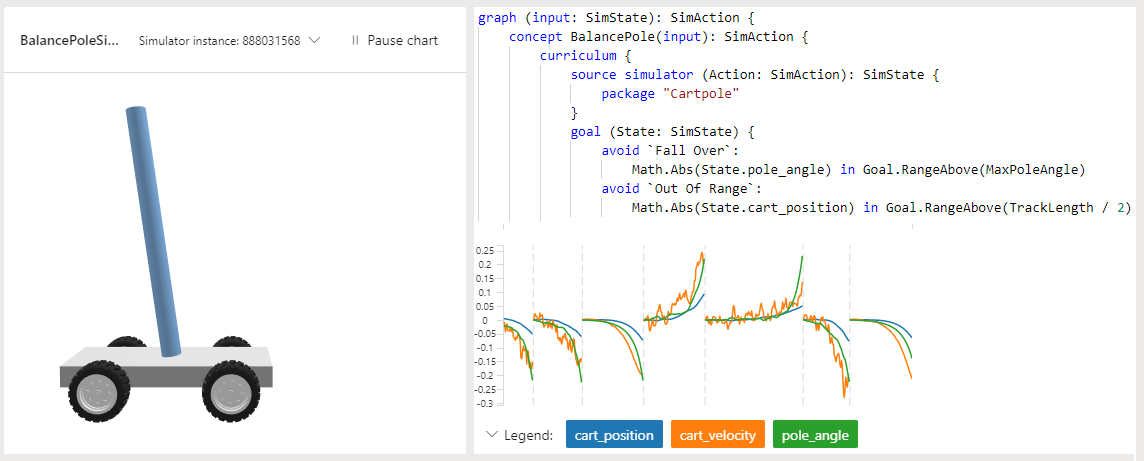
La siguiente captura de pantalla de Bonsai muestra un entrenamiento de Cartpole, con la satisfacción del objetivo en el eje Y, y las iteraciones de entrenamiento en el eje X. En el panel de Bonsai también se muestra el porcentaje de satisfacción del objetivo y el tiempo total de entrenamiento.
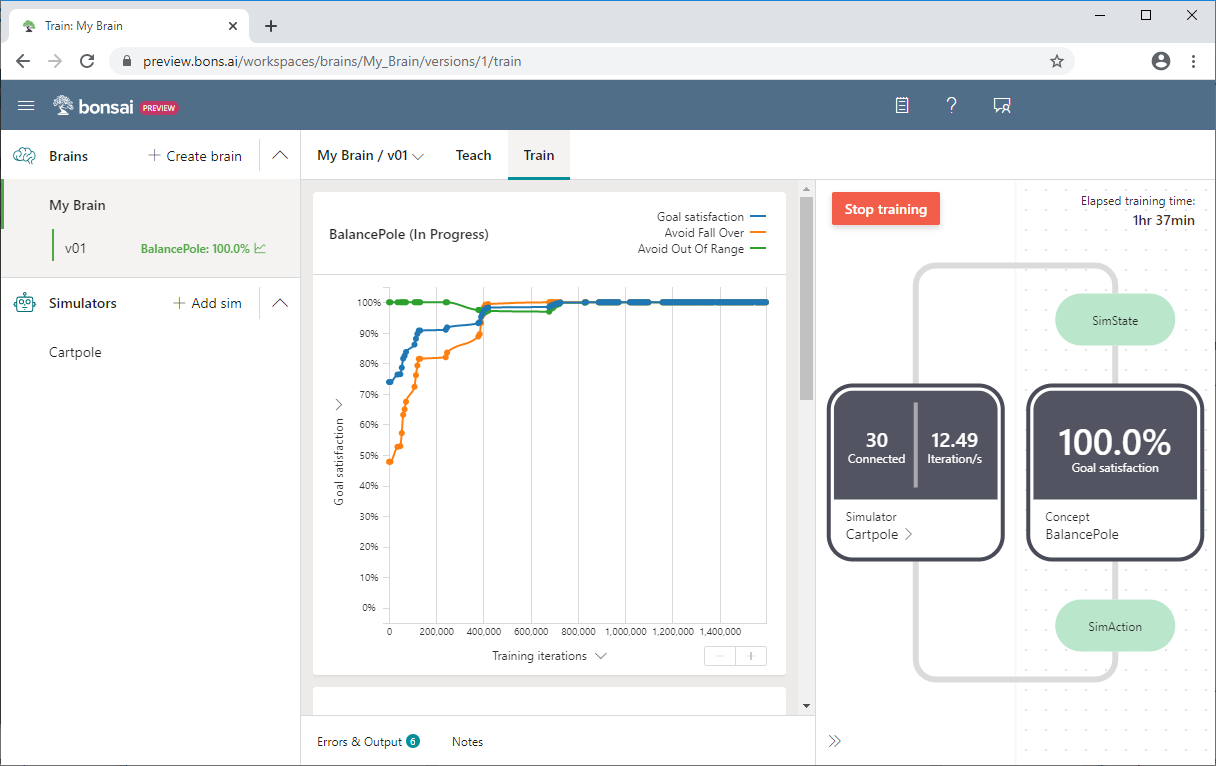
Para obtener más información sobre el ejemplo de Cartpole o probarlo por su cuenta, consulte Información sobre cómo enseñar a un agente de IA a equilibrar un mástil.
Perforación petrolera
La aplicación Horizontal Oil Drilling es un controlador de movimiento para automatizar las plataformas petrolíferas que perforan horizontalmente. Un operador controla la broca subterránea con un joystick para mantener la broca dentro del esquisto bituminoso, a la vez que evita los obstáculos. La broca realiza la menor cantidad posible de acciones de dirección, para agilizar la perforación. El objetivo es usar el aprendizaje de refuerzo para automatizar el control de la perforación petrolífera horizontal.
La información disponible del sensor incluye la dirección de la fuerza de la broca, el peso de la broca, la fuerza lateral y el ángulo de perforación. Las acciones admitidas del agente son subir la broca, bajarla, y moverla a la izquierda o a la derecha. El programa brinda una recompensa positiva cuando la broca está dentro de la distancia de tolerancia de las paredes de la cámara. El modelo aprende a adaptarse a los distintos planos de pozos, las posiciones iniciales y las imprecisiones del sensor.
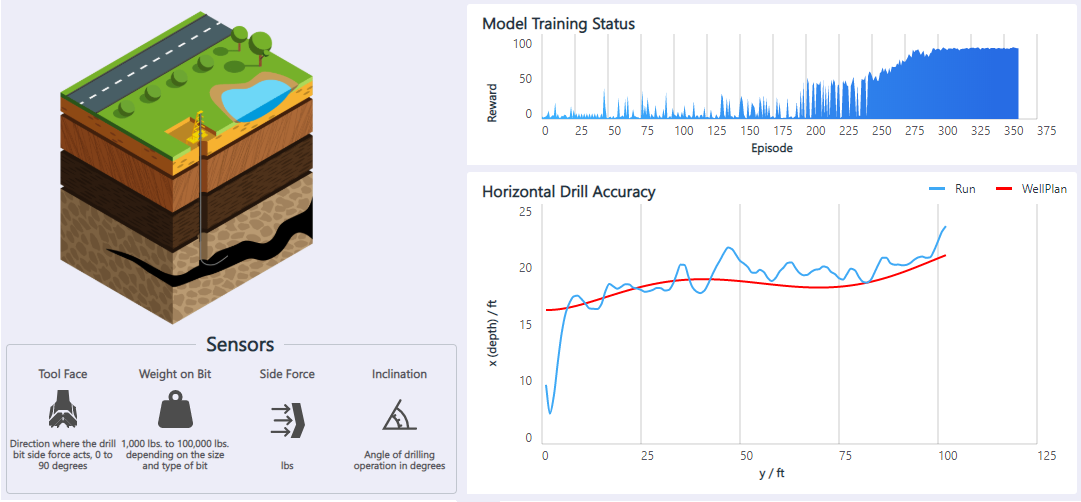
Para obtener más información y una demostración de esta solución, consulte Control de movimiento: Perforación petrolera horizontal.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Jose Contreras | Director principal de ingeniería de software
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
- Enseñanza automática para sistemas autónomos
- Sistemas autónomos con IA de Microsoft
- Autonomía para sistemas de control industrial
- Enseñanza automática: Cómo la experiencia de los usuarios hace que la IA sea aún más eficaz
- Microsoft amplía la disponibilidad de las herramientas de sistemas autónomos para ingenieros y desarrolladores
- Espacio de innovación: Sistemas autónomos (vídeo)
- The AI Blog de Microsoft
- Plataforma de informática y robótica aérea (AirSim)
- Gazebo
- Simulink
Más información sobre la enseñanza automática:
- "Bonsai, AI for Everyone", 2 de marzo de 2016
- "AI use cases: innovations solving more than just toy problems", 2 de marzo de 2017
- Patrice Y. Simard, Saleema Amershi, David M. Chickering, et al., "Machine Teaching: A New Paradigm for Building Machine Learning Systems", 2017
- Carlos E. Perez, "Deep Teaching: The Sexiest Job of the Future", 29 de julio de 2017
- Tambet Matiisen, "Demystifying deep reinforcement learning", 19 de diciembre de 2015
- Andrej Karpathy, "Deep Reinforcement Learning: Pong from Pixels", 31 de mayo de 2016
- David Kestenbaum, "Pop Quiz: How Do You Stop Sea Captains From Killing Their Passengers?", 10 de septiembre de 2010