Alta disponibilidad con SQL Instancia administrada habilitada por Azure Arc
SQL Managed Instance habilitada por Azure Arc se implementa en Kubernetes como una aplicación contenedorizada. Usa construcciones de Kubernetes, como conjuntos con estado y almacenamiento persistente para proporcionar elementos integrados:
- Supervisión del estado
- Detección de errores
- Conmutación automática por error para mantener el estado del servicio.
Para aumentar la confiabilidad, también puede configurar SQL Managed Instance habilitada por Azure Arc a fin de implementar con réplicas adicionales en una configuración de alta disponibilidad. El controlador de datos de Servicios de datos de Arc administra:
- Supervisión
- Detección de errores
- Conmutación por error automática
El servicio de datos habilitado para Arc proporciona este servicio sin intervención del usuario. El servicio:
- Configuración del grupo de disponibilidad
- Configura los puntos de conexión de creación de reflejo de la base de datos
- Agrega bases de datos al grupo de disponibilidad
- Coordina la conmutación por error y la actualización.
En este documento se exploran ambos tipos de alta disponibilidad.
SQL Managed Instance habilitada por Azure Arc proporciona diferentes niveles de alta disponibilidad en función de si la instancia administrada de SQL se implementó como un nivel de servicio de Uso general o Crítico para la empresa.
Alta disponibilidad en el nivel de servicio De uso general
En el nivel de servicio De uso general, solo hay una réplica disponible y la alta disponibilidad se logra a través de la orquestación de Kubernetes. Por ejemplo, si un pod o nodo que contiene la imagen de contenedor de la instancia administrada se bloquea, Kubernetes intenta colocar otro pod o nodo y se asocia al mismo almacenamiento persistente. Durante este tiempo, la instancia administrada de SQL no está disponible para las aplicaciones. Las aplicaciones deben volver a conectarse y reintentar la transacción cuando el nuevo pod esté en marcha. Si load balancer es el tipo de servicio usado, las aplicaciones pueden volver a conectarse al mismo punto de conexión principal y Kubernetes redirigirá la conexión al nuevo punto de conexión principal. Si el tipo de servicio es nodeport, las aplicaciones tendrán que volver a conectarse a la nueva dirección IP.
Comprobación de la alta disponibilidad integrada
Para comprobar la alta disponibilidad de compilación proporcionada por Kubernetes, puede hacer lo siguiente:
- Eliminación del pod de una instancia administrada existente
- Comprobación de que Kubernetes se recupera de esta acción
Durante la recuperación, Kubernetes arranca otro pod y adjunta el almacenamiento persistente.
Requisitos previos
- El clúster de Kubernetes requiere almacenamiento compartido y remoto
- SQL Managed Instance habilitada por Azure Arc implementado con una réplica (valor predeterminado)
Vea los pods.
kubectl get pods -n <namespace of data controller>Elimine el pod de la instancia administrada.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Por ejemplo
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedVea los pods para comprobar que la instancia administrada se está recuperando.
kubectl get pods -n <namespace of data controller>Por ejemplo:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Después de recuperar todos los contenedores del pod, puede conectarse a la instancia administrada.
Alta disponibilidad en el nivel de servicio Crítico para la empresa
En el nivel de servicio Crítico para la empresa, además de lo que proporciona de forma nativa la orquestación de Kubernetes, SQL Instancia administrada para Azure Arc proporciona un grupo de disponibilidad independiente. El grupo de disponibilidad contenido se basa en la tecnología AlwaysOn de SQL Server y proporciona mayores niveles de disponibilidad. SQL Managed Instance habilitada por Azure Arc implementada con el nivel de servicio Crítico para la empresa se puede implementar con 2 o 3 réplicas. Estas réplicas siempre se mantienen sincronizadas entre sí.
Con los grupos de disponibilidad contenidos, los bloqueos de pod o los errores de nodo son transparentes para la aplicación. El grupo de disponibilidad independiente proporciona al menos otro pod que tiene todos los datos de la principal y está listo para tomar conexiones.
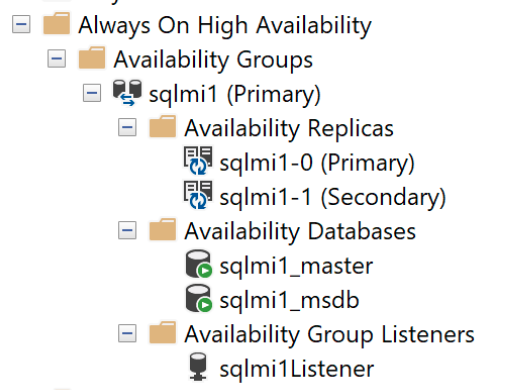
Grupos de disponibilidad contenidos
Un grupo de disponibilidad enlaza una o varias bases de datos de usuario a un grupo lógico para que, cuando se produzca una conmutación por error, todo el grupo de bases de datos conmute por error a la réplica secundaria como una unidad única. Un grupo de disponibilidad solo replica los datos de las bases de datos de usuario, pero no los datos de las bases de datos del sistema, como inicios de sesión, permisos o trabajos del agente. Un grupo de disponibilidad contenido incluye metadatos de bases de datos del sistema, como las bases de datos msdb y master. Cuando se crean o modifican inicios de sesión en la réplica principal, también se crean automáticamente en las réplicas secundarias. De forma similar, cuando se crea o modifica un trabajo del agente en la réplica principal, las réplicas secundarias también reciben esos cambios.
SQL Managed Instance habilitada por Azure Arc toma este concepto de grupo de disponibilidad contenido y agrega el operador de Kubernetes para poder realizar la implementación y la administración a gran escala.
Funcionalidades que permiten los grupos de disponibilidad contenidos:
Cuando se implementan con varias réplicas, se crea un único grupo de disponibilidad que recibe el mismo nombre que la instancia administrada de SQL habilitada para Arc. De manera predeterminada, un grupo de disponibilidad contenido tiene tres réplicas, incluida la principal. Todas las operaciones CRUD del grupo de disponibilidad se administran internamente, incluida la creación del grupo de disponibilidad o la unión de réplicas al grupo de disponibilidad creado. No se pueden crear más grupos de disponibilidad en una instancia de .
Todas las bases de datos se agregan automáticamente al grupo de disponibilidad, incluidas todas las bases de datos del usuario y el sistema, como
masterymsdb. Esta funcionalidad proporciona una vista de un solo sistema de las réplicas del grupo de disponibilidad. Observe las bases de datoscontainedag_masterycontainedag_msdbsi se conecta directamente a la instancia. Las bases de datoscontainedag_*representanmasterymsdbdentro del grupo de disponibilidad.Se aprovisiona automáticamente un punto de conexión externo para conectarse a las bases de datos del grupo de disponibilidad. Este punto de conexión
<managed_instance_name>-external-svcdesempeña el rol de escucha de grupo de disponibilidad.
Implementación de SQL Instancia administrada habilitada por Azure Arc con varias réplicas mediante Azure Portal
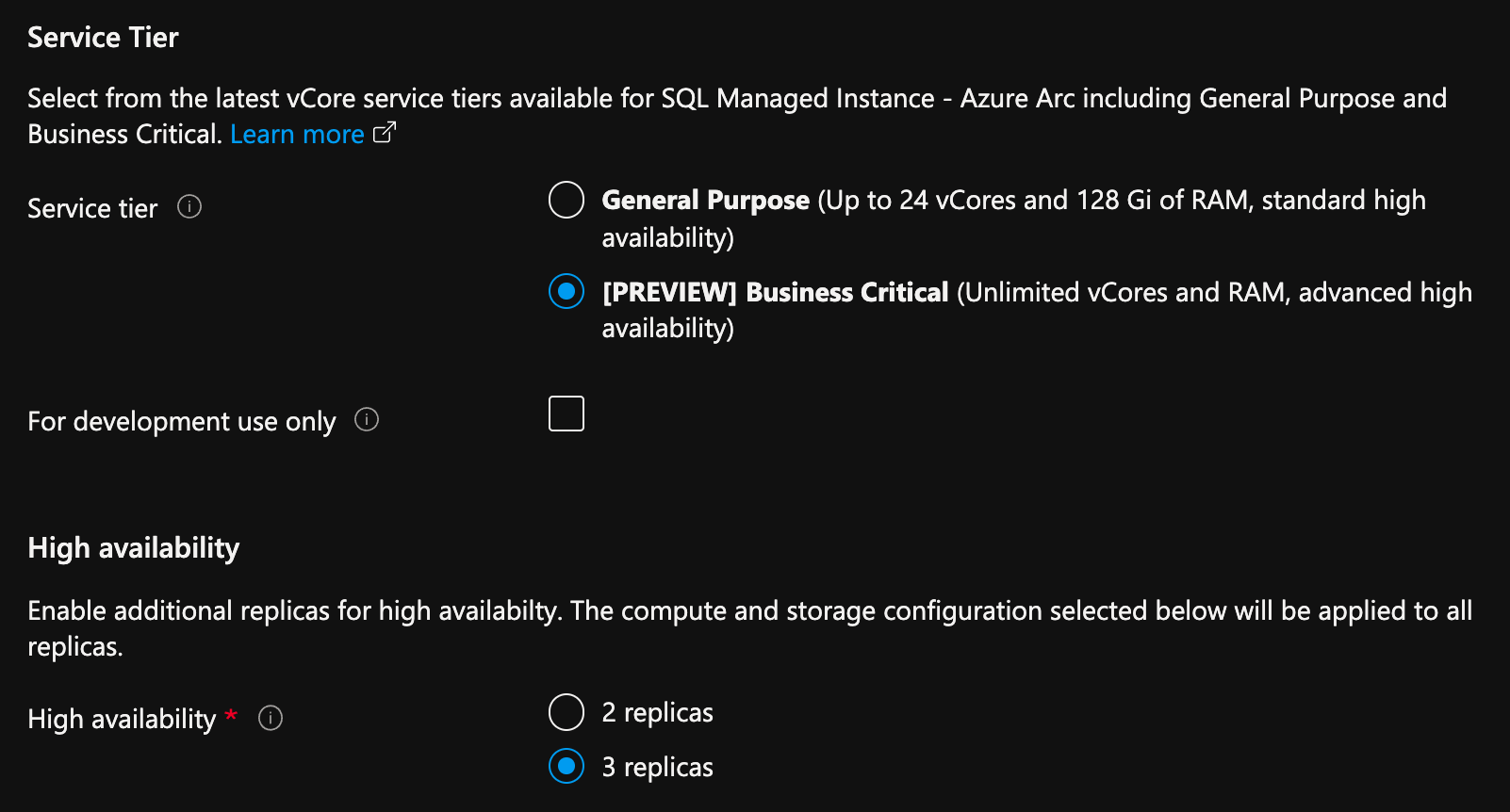
En Azure Portal, en la página Crear SQL Instancia administrada habilitada por Azure Arc:
- Seleccione Configurar proceso + almacenamiento en Proceso y almacenamiento. Se muestra la configuración avanzada en el portal.
- En Nivel de servicio, seleccione Crucial para la empresa.
- Marque "Solo para uso de desarrollo", si se va a usar con fines de desarrollo.
- En Alta disponibilidad, seleccione 2 réplicas o 3 réplicas.
Implementación con varias réplicas mediante la CLI de Azure
Cuando se implementa una Instancia administrada SQL habilitada por Azure Arc en Crítico para la empresa nivel de servicio, la implementación crea varias réplicas. La configuración de los grupos de disponibilidad contenidos de esas instancias se realiza automáticamente durante el aprovisionamiento.
Por ejemplo, el comando siguiente crea una instancia administrada con tres réplicas.
Modo de conexión indirecta:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Ejemplo:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Modo de conexión directa:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Ejemplo:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
De manera predeterminada, todas las réplicas se configuran en modo sincrónico. Esto significa que las actualizaciones de la instancia principal se replican sincrónicamente en cada una de las instancias secundarias.
Visualización y supervisión del estado de alta disponibilidad
Una vez completada la implementación, conéctese al punto de conexión principal desde SQL Server Management Studio.
Compruebe y recupere el punto de conexión de la réplica principal y conéctese a él desde SQL Server Management Studio.
Por ejemplo, si la instancia de SQL se implementó mediante service-type=loadbalancer, ejecute el siguiente comando para recuperar el punto de conexión al que conectarse:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
or
kubectl get sqlmi -A
Obtención de los puntos de conexión principales y secundarios y el estado de un grupo de disponibilidad
Use los comandos kubectl describe sqlmi o az sql mi-arc show para ver los puntos de conexión principales y secundarios, así como el estado de alta disponibilidad.
Ejemplo:
kubectl describe sqlmi sqldemo -n my-namespace
or
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Ejemplo:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
Puede conectarse al punto de conexión principal con SQL Server Management Studio y comprobar las DMV como:
SELECT * FROM sys.dm_hadr_availability_replica_states
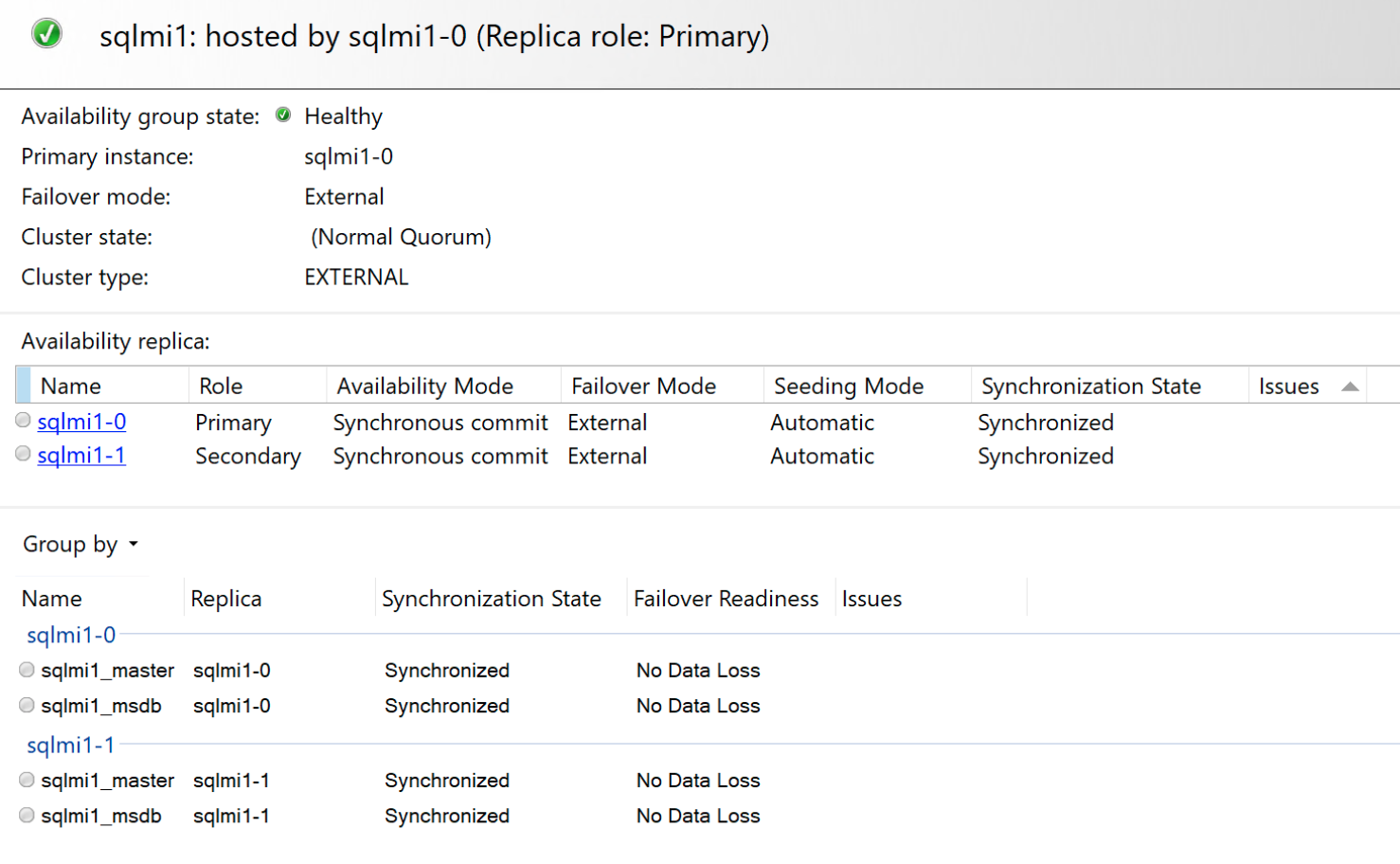
Y el panel de disponibilidad contenida:
Escenarios de conmutación por error
A diferencia de los Grupos de disponibilidad Always On de SQL Server, el grupo de disponibilidad contenido es una solución administrada de alta disponibilidad. Por lo tanto, los modos de conmutación por error son limitados en comparación con los modos típicos disponibles con los Grupos de disponibilidad Always On de SQL Server.
Implemente instancias administradas de SQL del nivel de servicio Crítico para la empresa en una configuración de dos o tres réplicas. Los efectos de los errores y la posterior capacidad de recuperación son diferentes con cada configuración. Una instancia de tres réplicas proporciona un nivel superior de disponibilidad y recuperación, que una instancia de dos réplicas.
En una configuración de dos réplicas, cuando ambos estados de nodo son SYNCHRONIZED, si la réplica principal deja de estar disponible, la réplica secundaria se promueve automáticamente a la principal. Cuando la réplica con error está disponible, se actualiza con todos los cambios pendientes. Si hay problemas de conectividad entre las réplicas, es posible que la principal no confirme ninguna transacción, ya que todas las transacciones deben confirmarse en ambas réplicas antes de que se devuelva un resultado correcto en la réplica principal.
En una configuración de tres réplicas, una transacción debe confirmarse en al menos dos de las tres réplicas antes de devolver un mensaje de operación realizada correctamente a la aplicación. En caso de error, una de las réplicas secundarias se promueve automáticamente a la principal mientras Kubernetes intenta recuperar la réplica con errores. Cuando la réplica está disponible, se vuelve a unir automáticamente con el grupo de disponibilidad contenido y se sincronizan los cambios pendientes. Si hay problemas de conectividad entre las réplicas y más de 2 réplicas no están sincronizadas, la réplica principal no confirmará ninguna transacción.
Nota:
Se recomienda implementar una instancia de SQL Managed Instance del nivel de servicio Crítico para la empresa en una configuración de tres réplicas y no en una configuración de dos réplicas para conseguir que la pérdida de datos sea casi inexistente.
Para conmutar por error desde la réplica principal a una de las secundarias, en el caso de un evento planeado, ejecute el siguiente comando:
Si se conecta a la réplica principal, puede usar la siguiente instrucción T-SQL para conmutar por error la instancia de SQL a una de las réplicas secundarias:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
Si se conecta a la réplica secundaria, puede usar la siguiente instrucción T-SQL para promover la réplica secundaria deseada a la réplica principal.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Réplica principal preferida
También puede establecer una réplica específica para que sea la réplica principal mediante la CLI de AZ, como se muestra a continuación:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Ejemplo:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Nota:
Kubernetes intentará establecer la réplica preferida, pero no se garantiza que lo consiga.
Restauración de una base de datos en una instancia de varias réplicas
Se requieren pasos adicionales para restaurar una base de datos en un grupo de disponibilidad. En los pasos siguientes se muestra cómo restaurar una base de datos en una instancia administrada y agregarla a un grupo de disponibilidad.
Exponga el punto de conexión externo de la instancia principal mediante la creación de un nuevo servicio Kubernetes.
Determine el pod que hospeda la réplica principal. Conéctese a la instancia administrada y ejecute:
SELECT @@SERVERNAMELa consulta devuelve el pod que hospeda la réplica principal.
Cree el servicio Kubernetes en la instancia principal mediante la ejecución del comando siguiente si el clúster de Kubernetes usa
NodePortservicios. Reemplace<podName>por el nombre del servidor devuelto en el paso anterior,<serviceName>por el nombre preferido para el servicio Kubernetes creado.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortPara un servicio LoadBalancer, ejecute el mismo comando, con la excepción de que el tipo del servicio creado es
LoadBalancer. Por ejemplo:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerEste es un ejemplo de este comando en ejecución en Azure Kubernetes Service, donde el pod que hospeda la réplica principal es
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerObtenga la dirección IP del servicio Kubernetes creado:
kubectl get services -n <namespaceName>Restaure la base de datos en el punto de conexión de la instancia principal.
Agregue el archivo de copia de seguridad de la base de datos en el contenedor de instancia principal.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Ejemplo
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcRestaure el archivo de copia de seguridad de la base de datos mediante la ejecución del comando siguiente.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOEjemplo
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOAgregue la base de datos al grupo de disponibilidad.
Para que la base de datos se agregue al grupo de disponibilidad, debe ejecutarse en modo de recuperación completa y debe realizarse una copia de seguridad del registro. Ejecute las instrucciones TSQL siguientes para agregar la base de datos restaurada al grupo de disponibilidad.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>En el ejemplo siguiente se agrega una base de datos denominada
WideWorldImportersrestaurada en la instancia:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Importante
Como procedimiento recomendado, debe eliminar el servicio Kubernetes creado anteriormente mediante la ejecución de este comando:
kubectl delete svc sql2-0-p -n arc
Limitaciones
Los grupos de disponibilidad de SQL Managed Instance habilitada por Azure Arc tienen las mismas limitaciones que los grupos de disponibilidad del clúster de macrodatos. Para obtener más información, consulte Implementación de clústeres de macrodatos de SQL Server con alta disponibilidad.
Contenido relacionado
Obtenga más información sobre las características y funcionalidades de SQL Managed Instance habilitada por Azure Arc