Tutorial: Uso de Azure Cache for Redis como caché semántica
En este tutorial, usará Azure Cache for Redis como caché semántica con un modelo de lenguaje grande (LLM) basado en IA. Azure OpenAI Service se usa para generar respuestas LLM a consultas y almacenar en caché esas respuestas mediante Azure Cache for Redis, lo que proporciona respuestas más rápidas y reduce los costos.
Dado que Azure Cache for Redis ofrece la funcionalidad de vector de búsqueda integrada, también puede realizar almacenamiento en caché semántico. Puede devolver respuestas almacenadas en caché para consultas idénticas y también para las consultas que son similares en cuanto a su significado, aunque el texto no sea el mismo.
En este tutorial, aprenderá a:
- Creación de una instancia de Azure Cache for Redis configurada para el almacenamiento en caché semántico
- Use LangChain u otras bibliotecas populares de Python.
- Use Azure OpenAI Service para generar texto a partir de modelos de IA y almacenar en caché los resultados.
- Consulte los beneficios de rendimiento del uso del almacenamiento en caché con los LLM.
Importante
Este tutorial le guía en la creación de un cuaderno de Jupyter Notebook. Puede seguir este tutorial con un archivo de código de Python (.py) y obtener resultados similares, pero tendrá que agregar todos los bloques de código de este tutorial al archivo .py y ejecutarlo una vez para ver los resultados. En otras palabras, Jupyter Notebooks proporciona resultados intermedios a medida que se ejecutan celdas, pero este no es el comportamiento que debería esperar al trabajar en un archivo de código de Python.
Importante
Si en lugar de ello quiere seguir el tutorial en un cuaderno de Jupyter completo, descargue el archivo del cuaderno de Jupyter llamado semanticcache.ipynb y guárdelo en la nueva carpeta semanticcache.
Requisitos previos
Una suscripción a Azure: cree una cuenta gratuita.
Acceso concedido a Azure OpenAI en la suscripción de Azure que quiera. Actualmente, debe hacer una solicitud para obtener acceso a Azure OpenAI. Para solicitar acceso a Azure OpenAI, rellene el formulario de https://aka.ms/oai/access.
Jupyter Notebooks (opcional)
Un recurso de Azure OpenAI con los modelos text-embedding-ada-002 (versión 2) y gpt-35-turbo-instruct implementados. Actualmente, estos modelos solo están disponibles en determinadas regiones. Consulte la guía de implementación de recursos para obtener instrucciones sobre cómo implementar los modelos.
Creación de una instancia de Azure Redis Cache
Siga la guía de Inicio rápido: Creación de una caché de Redis Enterprise. En la página Avanzado, asegúrese de que ha agregado el módulo RediSearch y ha elegido la directiva de clúster Enterprise. Todas las demás opciones de configuración pueden coincidir con el valor predeterminado descrito en el inicio rápido.
La caché tarda unos minutos en crearse. Mientras tanto, puede avanzar al siguiente paso.
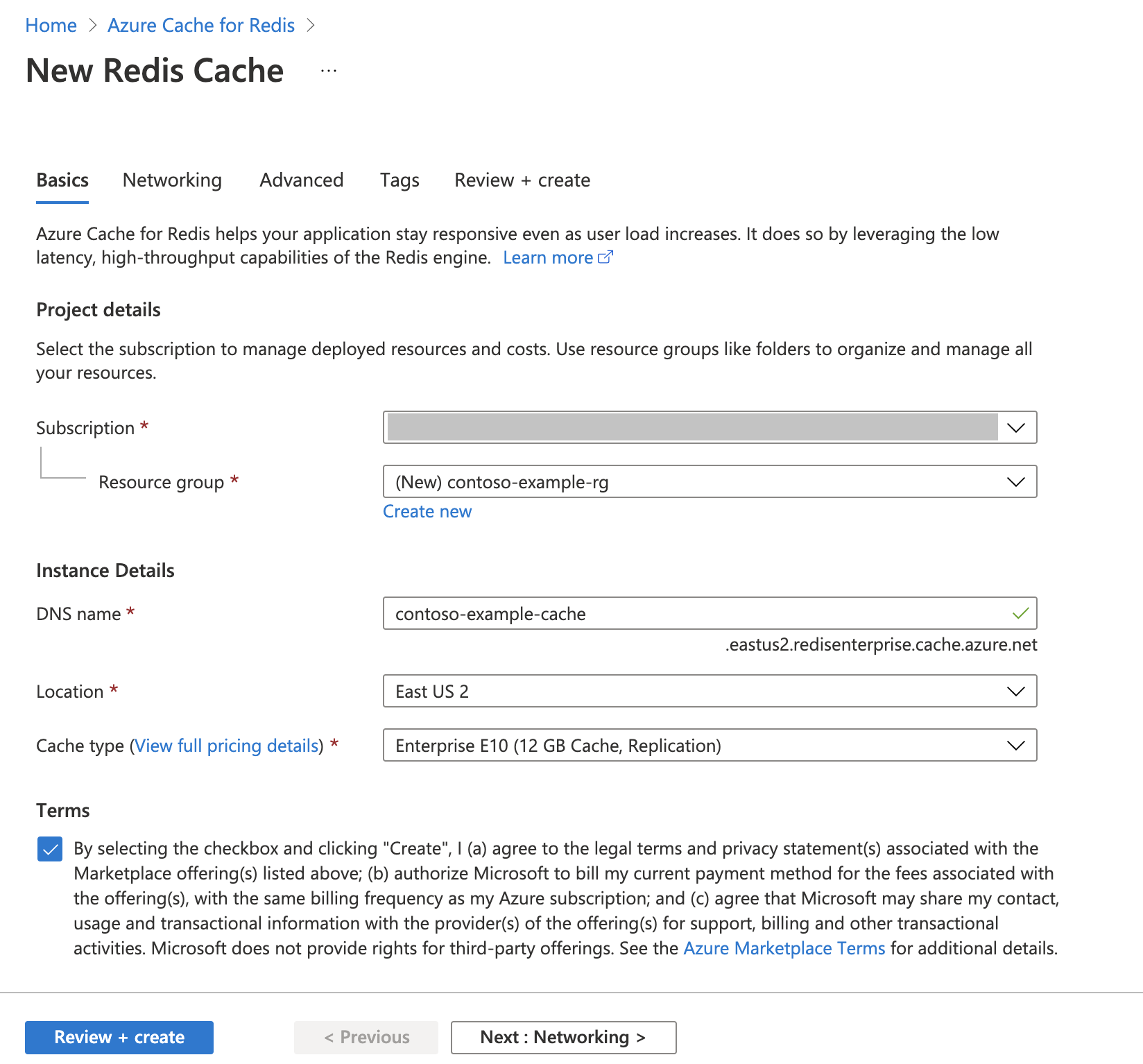
Configurado su entorno de desarrollo
Cree una carpeta en el equipo local llamada semanticcache en la ubicación donde normalmente guarde los proyectos.
Cree un archivo de Python (tutorial.py) o un cuaderno de Jupyter Notebook (tutorial.ipynb) en la carpeta.
Instale los paquetes de Python necesarios:
pip install openai langchain redis tiktoken
Creación de modelos de Azure OpenAI
Asegúrese de que tiene dos modelos implementados en el recurso de Azure OpenAI:
Un LLM que proporciona respuestas de texto. Usamos el modelo GPT-3.5-turbo-instruct para este tutorial.
Un modelo de inserciones que convierte las consultas en vectores para permitir compararlas con las consultas anteriores. Usamos el modelo text-embeding-ada-002 (versión 2) para este tutorial.
Consulte Implementación de un modelo para obtener instrucciones más detalladas. Registre el nombre que ha elegido para cada implementación de modelo.
Importar bibliotecas y configurar la información de conexión
Para realizar correctamente una llamada en Azure OpenAI, necesita un punto de conexión y una clave. También necesita un punto de conexión y una clave para conectarse a Azure Cache for Redis.
Vaya al recurso de Azure OpenAI en Azure Portal.
Busque Punto de conexión y claves en la sección Administración de recursos del recurso de Azure OpenAI. Copie el punto de conexión y la clave de acceso, ya que necesita ambos para autenticar las llamadas API. Punto de conexión de ejemplo:
https://docs-test-001.openai.azure.com. Puede usarKEY1oKEY2.Vaya a la página de Información general de su recurso de Azure Cache for Redis en Azure Portal. Copie el punto de conexión.
Busque Claves de acceso en la sección Configuración. Copie la clave de acceso. Puede usar
PrimaryoSecondary.Agregue el código siguiente en una nueva celda de código:
# Code cell 2 import openai import redis import os import langchain from langchain.llms import AzureOpenAI from langchain.embeddings import AzureOpenAIEmbeddings from langchain.globals import set_llm_cache from langchain.cache import RedisSemanticCache import time AZURE_ENDPOINT=<your-openai-endpoint> API_KEY=<your-openai-key> API_VERSION="2023-05-15" LLM_DEPLOYMENT_NAME=<your-llm-model-name> LLM_MODEL_NAME="gpt-35-turbo-instruct" EMBEDDINGS_DEPLOYMENT_NAME=<your-embeddings-model-name> EMBEDDINGS_MODEL_NAME="text-embedding-ada-002" REDIS_ENDPOINT = <your-redis-endpoint> REDIS_PASSWORD = <your-redis-password>Actualice el valor de
API_KEYyRESOURCE_ENDPOINTcon los valores de clave y punto de conexión de la implementación de Azure OpenAI.Establezca
LLM_DEPLOYMENT_NAMEyEMBEDDINGS_DEPLOYMENT_NAMEen el nombre de los dos modelos implementados en Azure OpenAI Service.Actualice
REDIS_ENDPOINTyREDIS_PASSWORDcon el punto de conexión y el valor de clave de la instancia de Azure Cache for Redis.Importante
Se recomienda encarecidamente usar variables de entorno o un administrador de secretos, como Azure Key Vault, para pasar la información de clave de API, punto de conexión Y nombre de implementación. Estas variables se establecen en texto no cifrado aquí por motivos de simplicidad.
Ejecute la celda de código 2.
Inicialización de los modelos de IA
A continuación, inicialice los modelos LLM y de inserciones.
Agregue el código siguiente en una nueva celda de código:
# Code cell 3 llm = AzureOpenAI( deployment_name=LLM_DEPLOYMENT_NAME, model_name="gpt-35-turbo-instruct", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION, ) embeddings = AzureOpenAIEmbeddings( azure_deployment=EMBEDDINGS_DEPLOYMENT_NAME, model="text-embedding-ada-002", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION )Ejecute la celda de código 3.
Configuración de Redis como caché semántica
A continuación, especifique Redis como una caché semántica para el LLM.
Agregue el código siguiente en una nueva celda de código:
# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.05))Importante
El valor del parámetro
score_thresholddetermina la similitud de dos consultas para devolver un resultado almacenado en caché. Cuanto menor sea el número, más similares deben ser las consultas. Puede jugar con este valor para ajustarlo a la aplicación.Ejecute la celda de código 4.
Consulta y obtención de respuestas del LLM
Por último, consulte el LLM para obtener una respuesta generada mediante IA. Si usa un cuaderno de Jupyter Notebook, puede agregar %%time en la parte superior de la celda para generar como salida la cantidad de tiempo necesario para ejecutar el código.
Agregue el código siguiente a una nueva celda de código y ejecútelo:
# Code cell 5 %%time response = llm("Please write a poem about cute kittens.") print(response)Debería aparecer una salida similar a la siguiente:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 2.67 sEl elemento
Wall timemuestra un valor de 2,67 segundos. Esa es la cantidad de tiempo real que se tardó en consultar el LLM y en que el LLM generase una respuesta.Vuelva a ejecutar la celda 5. Debería ver exactamente la misma salida, pero con un valor del elemento Wall time más pequeño:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 575 msEl elemento Wall time parece acortarse en un factor de 5 hasta los 575 milisegundos.
Cambie la consulta de
Please write a poem about cute kittensaWrite a poem about cute kittensy vuelva a ejecutar la celda 5. Debería ver exactamente la misma salida y un valor de Wall time inferior al de la consulta original. Aunque la consulta ha cambiado, el significado semántico de la consulta sigue siendo el mismo para que se devuelva la misma salida almacenada en caché. Esta es la ventaja del almacenamiento en caché semántico.
Cambio del umbral de similitud
Pruebe a ejecutar una consulta similar con un significado diferente, como
Please write a poem about cute puppies. Observe que aquí también se devuelve el resultado almacenado en caché. El significado semántico de la palabrapuppiesestá lo suficientemente cerca de la palabrakittensque se devuelve en el resultado almacenado en caché.El umbral de similitud se puede modificar para determinar cuándo debe devolver la caché semántica un resultado almacenado en caché y cuándo debe devolver una nueva salida del LLM. En la celda de código 4, cambie
score_thresholdde0.05a0.01:# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.01))Vuelva a intentar la consulta
Please write a poem about cute puppies. Debe recibir una nueva salida específica para cachorros:Oh, little balls of fluff and fur With wagging tails and tiny paws Puppies, oh puppies, so pure The epitome of cuteness, no flaws With big round eyes that melt our hearts And floppy ears that bounce with glee Their playful antics, like works of art They bring joy to all they see Their soft, warm bodies, so cuddly As they curl up in our laps Their gentle kisses, so lovingly Like tiny, wet, puppy taps Their clumsy steps and wobbly walks As they explore the world anew Their curiosity, like a ticking clock Always eager to learn and pursue Their little barks and yips so sweet Fill our days with endless delight Their unconditional love, so complete ... For they bring us love and laughter, year after year Our cute little pups, in every way. CPU times: total: 15.6 ms Wall time: 4.3 sEs probable que tenga que ajustar el umbral de similitud en función de la aplicación para asegurarse de que se usa la confidencialidad correcta al determinar qué consultas almacenar en caché.
Limpieza de recursos
Si desea seguir usando los recursos que creó en este artículo, mantenga el grupo de recursos.
De lo contrario, para evitar cargos relacionados con los recursos, si ha terminado de usarlos, puede eliminar el grupo de recursos de Azure que creó.
Advertencia
La eliminación de un grupo de recursos es irreversible. Cuando elimine un grupo de recursos, todos los recursos del grupo de recursos se eliminan permanentemente. Asegúrese de no eliminar por accidente el grupo de recursos o los recursos equivocados. Si ha creado los recursos en un grupo de recursos existente que tiene recursos que desea conservar, puede eliminar cada recurso individualmente en lugar de eliminar el grupo de recursos.
Eliminación de un grupo de recursos
Inicie sesión en Azure Portal y después seleccione Grupos de recursos.
Seleccione el grupo de recursos que se eliminará.
Si hay muchos grupos de recursos, en Filtro para cualquier campo, escriba el nombre del grupo de recursos que creó para completar este artículo. En la lista de resultados de búsqueda, seleccione el grupo de recursos.
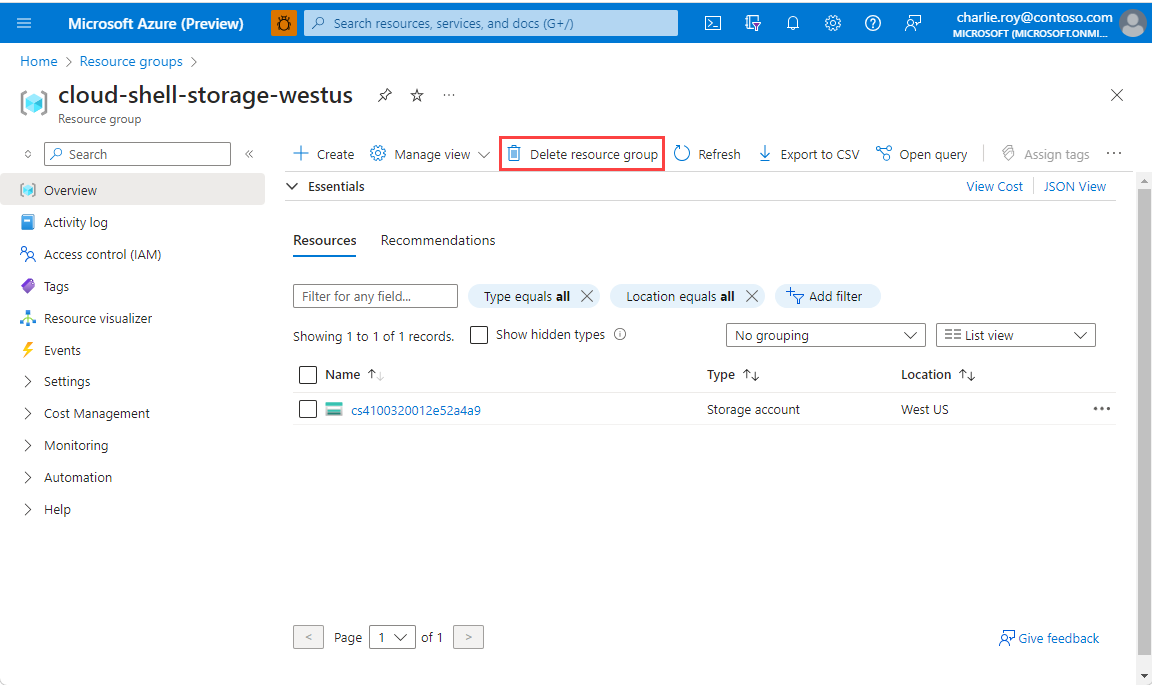
Seleccione Eliminar grupo de recursos.
En el panel Eliminar un grupo de recursos, escriba el nombre del grupo de recursos para confirmar y, a continuación, seleccione Eliminar.
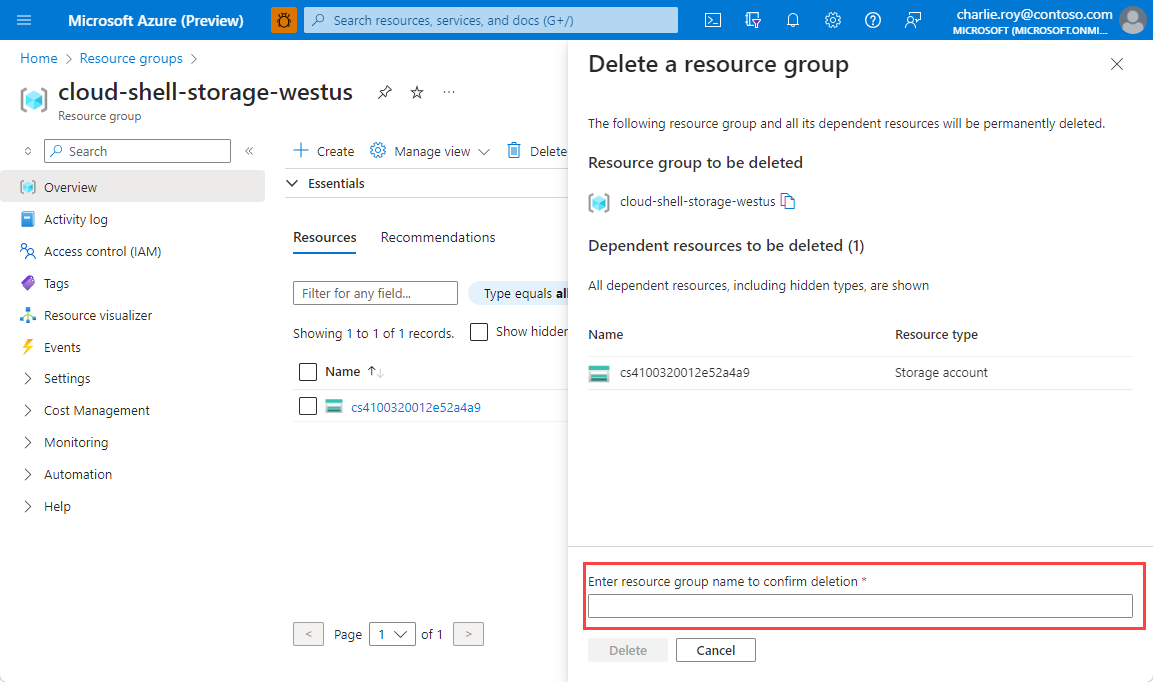
En unos instantes, el grupo de recursos y todos sus recursos se eliminan.
Contenido relacionado
- Más información sobre Azure Cache for Redis
- Más información sobre las funcionalidades de vector de búsqueda de Azure Cache for Redis
- Tutorial: Uso de la búsqueda de similitud de vectores en Azure Cache for Redis
- Lea cómo crear una aplicación con tecnología de inteligencia artificial con OpenAI y Redis
- Compilar una aplicación de preguntas y respuestas con respuestas semánticas