Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El desencadenador de Azure SQL usa la funcionalidad de seguimiento de cambios SQL para supervisar los cambios en una tabla SQL y desencadenar una función cuando se crea, actualiza o elimina una fila. Para obtener detalles de configuración del seguimiento de cambios para su uso con el desencadenador de Azure SQL, vea Configuración del seguimiento de cambios. Para obtener información sobre los detalles de configuración de la extensión de Azure SQL para Azure Functions, vea Introducción al enlace SQL.
Las decisiones de escalado del desencadenador de Azure SQL para los planes De consumo y Premium se realizan mediante el escalado basado en el destino. Para más información, consulte Escalado basado en destino y revise las opciones de hospedaje de Azure Functions.
Nota:
La compatibilidad con los planes de consumo requiere la versión 3.1.284 o posterior de los enlaces de Azure SQL para Azure Functions.
Introducción a la funcionalidad
El enlace del desencadenador de Azure SQL usa un bucle de sondeo para comprobar si hay cambios, lo que desencadenará la función de usuario cuando se detecten cambios. A grandes rasgos, el bucle tiene el siguiente aspecto:
while (true) {
1. Get list of changes on table - up to a maximum number controlled by the Sql_Trigger_MaxBatchSize setting
2. Trigger function with list of changes
3. Wait for delay controlled by Sql_Trigger_PollingIntervalMs setting
}
Los cambios siempre se procesan en el orden en que se realizaron sus cambios, con los cambios más antiguos que se procesan primero. Dos notas sobre el procesamiento de cambios:
- Si se realizan cambios en varias filas a la vez, el orden exacto en el que se envían a la función se basa en el orden devuelto por la función CHANGETABLE.
- Los cambios se" agrupan por lotes" para una fila. Si se realizan varios cambios en una fila entre cada iteración del bucle, solo existe una entrada de cambio única para esa fila que mostrará la diferencia entre el último estado procesado y el estado actual
- Si se realizan cambios en un conjunto de filas y, a continuación, se realiza otro conjunto de cambios en la mitad de esas mismas filas, la mitad de las filas que no se han cambiado una segunda vez se procesan primero. Esta lógica de procesamiento se debe a la nota anterior con los cambios que se están procesando por lotes: el desencadenador solo verá el cambio "último" realizado y lo usará para el orden en que los procesa
Nota:
El seguimiento de cambios en Azure SQL puede detectar cambios a nivel de fila en tablas que utilizan tecnologías de cifrado como Always Encrypted o Transparent Data Encryption (TDE). Sin embargo, el disparador de Azure SQL no descifra ni expone los valores cifrados de las columnas en la carga útil de cambio. El disparador puede detectar que ha ocurrido un cambio, pero no puede acceder a los datos descifrados de esas columnas.
Para obtener más información sobre el seguimiento de cambios y cómo lo usan las aplicaciones, como los desencadenadores de Azure SQL, consulta Trabajar con el seguimiento de cambios .
Importante
Para lograr una seguridad óptima, debe usar el identificador de Entra de Microsoft con identidades administradas para las conexiones entre Functions y Azure SQL Database. Las identidades administradas hacen que la aplicación sea más segura mediante la eliminación de secretos de las implementaciones de aplicaciones, como las credenciales de los cadena de conexión, los nombres de servidor y los puertos que se usan. Puede aprender a usar identidades administradas en este tutorial: Conexión de una aplicación de funciones a Azure SQL con identidad administrada y enlaces SQL.
Ejemplo de uso
Hay disponibles más ejemplos del desencadenador de Azure SQL en el repositorio de GitHub.
En este ejemplo se hace referencia a una clase ToDoItem y una tabla de base de datos correspondiente:
namespace AzureSQL.ToDo
{
public class ToDoItem
{
public Guid Id { get; set; }
public int? order { get; set; }
public string title { get; set; }
public string url { get; set; }
public bool? completed { get; set; }
}
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
El seguimiento de cambios está habilitado en la base de datos y en la tabla:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
El desencadenador de Azure SQL enlaza a IReadOnlyList<SqlChange<T>>, una lista de objetos SqlChange, cada uno con 2 propiedades:
-
Item: el elemento que ha cambiado. El tipo del elemento debe seguir el esquema de tabla tal como se ve en la clase
ToDoItem. -
Operation: un valor de la enumeración
SqlChangeOperation. Los valores posibles sonInsert,UpdateyDelete.
En el siguiente ejemplo muestra una función de C# que se invoca cuando se producen cambios en la tabla ToDo:
using System;
using System.Collections.Generic;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Extensions.Sql;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
namespace AzureSQL.ToDo
{
public static class ToDoTrigger
{
[Function("ToDoTrigger")]
public static void Run(
[SqlTrigger("[dbo].[ToDo]", "SqlConnectionString")]
IReadOnlyList<SqlChange<ToDoItem>> changes,
FunctionContext context)
{
var logger = context.GetLogger("ToDoTrigger");
foreach (SqlChange<ToDoItem> change in changes)
{
ToDoItem toDoItem = change.Item;
logger.LogInformation($"Change operation: {change.Operation}");
logger.LogInformation($"Id: {toDoItem.Id}, Title: {toDoItem.title}, Url: {toDoItem.url}, Completed: {toDoItem.completed}");
}
}
}
}
Ejemplo de uso
Hay disponibles más ejemplos del desencadenador de Azure SQL en el repositorio de GitHub.
En este ejemplo, se hace referencia a una clase ToDoItem, a una clase SqlChangeToDoItem, a una enumeración SqlChangeOperation y una tabla de base de datos correspondiente:
En un archivo independiente ToDoItem.java:
package com.function;
import java.util.UUID;
public class ToDoItem {
public UUID Id;
public int order;
public String title;
public String url;
public boolean completed;
public ToDoItem() {
}
public ToDoItem(UUID Id, int order, String title, String url, boolean completed) {
this.Id = Id;
this.order = order;
this.title = title;
this.url = url;
this.completed = completed;
}
}
En un archivo independiente SqlChangeToDoItem.java:
package com.function;
public class SqlChangeToDoItem {
public ToDoItem item;
public SqlChangeOperation operation;
public SqlChangeToDoItem() {
}
public SqlChangeToDoItem(ToDoItem Item, SqlChangeOperation Operation) {
this.Item = Item;
this.Operation = Operation;
}
}
En un archivo independiente SqlChangeOperation.java:
package com.function;
import com.google.gson.annotations.SerializedName;
public enum SqlChangeOperation {
@SerializedName("0")
Insert,
@SerializedName("1")
Update,
@SerializedName("2")
Delete;
}
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
El seguimiento de cambios está habilitado en la base de datos y en la tabla:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
El desencadenador de Azure SQL enlaza a SqlChangeToDoItem[], una matriz de objetos SqlChangeToDoItem, cada uno con 2 propiedades:
-
item: el elemento que ha cambiado. El tipo del elemento debe seguir el esquema de tabla tal como se ve en la clase
ToDoItem. -
operation: un valor de la enumeración
SqlChangeOperation. Los valores posibles sonInsert,UpdateyDelete.
En el siguiente ejemplo, se muestra una función de Java que se invoca cuando se producen cambios en la tabla ToDo:
package com.function;
import com.microsoft.azure.functions.ExecutionContext;
import com.microsoft.azure.functions.annotation.FunctionName;
import com.microsoft.azure.functions.sql.annotation.SQLTrigger;
import com.function.Common.SqlChangeToDoItem;
import com.google.gson.Gson;
import java.util.logging.Level;
public class ProductsTrigger {
@FunctionName("ToDoTrigger")
public void run(
@SQLTrigger(
name = "todoItems",
tableName = "[dbo].[ToDo]",
connectionStringSetting = "SqlConnectionString")
SqlChangeToDoItem[] todoItems,
ExecutionContext context) {
context.getLogger().log(Level.INFO, "SQL Changes: " + new Gson().toJson(changes));
}
}
Ejemplo de uso
Hay disponibles más ejemplos del desencadenador de Azure SQL en el repositorio de GitHub.
El ejemplo hace referencia a una tabla de base de datos ToDoItem:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
El seguimiento de cambios está habilitado en la base de datos y en la tabla:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
El desencadenador de Azure SQL enlaza a todoChanges, una lista de objetos, cada uno con 2 propiedades:
- item: el elemento que ha cambiado. La estructura del elemento seguirá el esquema de tabla.
-
operation: los posibles valores son
Insert,UpdateyDelete.
El siguiente ejemplo muestra una función de PowerShell que se invoca cuando se producen cambios en la tabla ToDo.
A continuación se muestran los datos de enlace del archivo function.json:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
En la sección de configuración se explican estas propiedades.
A continuación se muestra código de PowerShell de ejemplo para la función en el archivo run.ps1:
using namespace System.Net
param($todoChanges)
# The output is used to inspect the trigger binding parameter in test methods.
# Use -Compress to remove new lines and spaces for testing purposes.
$changesJson = $todoChanges | ConvertTo-Json -Compress
Write-Host "SQL Changes: $changesJson"
Ejemplo de uso
Hay disponibles más ejemplos del desencadenador de Azure SQL en el repositorio de GitHub.
El ejemplo hace referencia a una tabla de base de datos ToDoItem:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
El seguimiento de cambios está habilitado en la base de datos y en la tabla:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
El desencadenador de SQL enlaza a todoChanges, una lista de objetos, cada uno con 2 propiedades:
- item: el elemento que ha cambiado. La estructura del elemento seguirá el esquema de tabla.
-
operation: los posibles valores son
Insert,UpdateyDelete.
En el siguiente ejemplo, se muestra una función de JavaScript que se invoca cuando se producen cambios en la tabla ToDo.
A continuación se muestran los datos de enlace del archivo function.json:
{
"name": "todoChanges",
"type": "sqlTrigger",
"direction": "in",
"tableName": "dbo.ToDo",
"connectionStringSetting": "SqlConnectionString"
}
En la sección de configuración se explican estas propiedades.
A continuación, se muestra código de JavaScript de ejemplo para la función en el archivo index.js:
module.exports = async function (context, todoChanges) {
context.log(`SQL Changes: ${JSON.stringify(todoChanges)}`)
}
Ejemplo de uso
Hay disponibles más ejemplos del desencadenador de Azure SQL en el repositorio de GitHub.
El ejemplo hace referencia a una tabla de base de datos ToDoItem:
CREATE TABLE dbo.ToDo (
[Id] UNIQUEIDENTIFIER PRIMARY KEY,
[order] INT NULL,
[title] NVARCHAR(200) NOT NULL,
[url] NVARCHAR(200) NOT NULL,
[completed] BIT NOT NULL
);
El seguimiento de cambios está habilitado en la base de datos y en la tabla:
ALTER DATABASE [SampleDatabase]
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);
ALTER TABLE [dbo].[ToDo]
ENABLE CHANGE_TRACKING;
El desencadenador de SQL enlaza a una variable todoChanges, una lista de objetos, cada uno con dos propiedades:
- item: el elemento que ha cambiado. La estructura del elemento seguirá el esquema de tabla.
-
operation: los posibles valores son
Insert,UpdateyDelete.
En el siguiente ejemplo se muestra una función de Python que se invoca cuando se producen cambios en la tabla ToDo.
A continuación se muestra código python de ejemplo para el archivo function_app.py:
import json
import logging
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="ToDoTrigger")
@app.sql_trigger(arg_name="todo",
table_name="ToDo",
connection_string_setting="SqlConnectionString")
def todo_trigger(todo: str) -> None:
logging.info("SQL Changes: %s", json.loads(todo))
Atributos
La biblioteca de C# usa el atributo SqlTrigger para declarar los desencadenadores de Azure SQL en la función, que tiene las siguientes propiedades:
| Propiedad de atributo | Descripción |
|---|---|
| TableName | Necesario. Nombre de la tabla que el desencadenador supervisada. |
| ConnectionStringSetting | Necesario. Nombre de una configuración de aplicación que contiene la cadena de conexión de la base de datos que contiene la tabla que supervisada en busca de cambios. El nombre de la configuración de la cadena de conexión se corresponde con la configuración de la aplicación (en local.settings.jsonpara el desarrollo local) que contiene la cadena de conexión a la instancia de Azure SQL o SQL Server. |
| LeasesTableName | Opcional. Nombre de la tabla utilizada para almacenar concesiones. Si no se especifica, el nombre de la tabla de concesiones será Leases_{FunctionId}_{TableId}. Puede encontrar más información sobre cómo se genera aquí. |
anotaciones
En la biblioteca de runtime de funciones de Java, utilice la anotación @SQLTrigger (com.microsoft.azure.functions.sql.annotation.SQLTrigger) en los parámetros cuyo valor provendría de Azure SQL. Esta anotación admite los siguientes elementos:
| Elemento | Descripción |
|---|---|
| nombre | Necesario. Nombre del parámetro al que enlaza el desencadenador. |
| tableName | Necesario. Nombre de la tabla que el desencadenador supervisada. |
| connectionStringSetting | Necesario. Nombre de una configuración de aplicación que contiene la cadena de conexión de la base de datos que contiene la tabla que supervisada en busca de cambios. El nombre de la configuración de la cadena de conexión se corresponde con la configuración de la aplicación (en local.settings.jsonpara el desarrollo local) que contiene la cadena de conexión a la instancia de Azure SQL o SQL Server. |
| LeasesTableName | Opcional. Nombre de la tabla utilizada para almacenar concesiones. Si no se especifica, el nombre de la tabla de concesiones será Leases_{FunctionId}_{TableId}. Puede encontrar más información sobre cómo se genera aquí. |
Configuración
En la siguiente tabla se explican las propiedades de configuración de enlace que se establecen en el archivo function.json.
| Propiedad de function.json | Descripción |
|---|---|
| nombre | Necesario. Nombre del parámetro al que enlaza el desencadenador. |
| tipo | Necesario. Se debe establecer en sqlTrigger. |
| dirección | Necesario. Se debe establecer en in. |
| tableName | Necesario. Nombre de la tabla que el desencadenador supervisada. |
| connectionStringSetting | Necesario. Nombre de una configuración de aplicación que contiene la cadena de conexión de la base de datos que contiene la tabla que supervisada en busca de cambios. El nombre de la configuración de la cadena de conexión se corresponde con la configuración de la aplicación (en local.settings.jsonpara el desarrollo local) que contiene la cadena de conexión a la instancia de Azure SQL o SQL Server. |
| LeasesTableName | Opcional. Nombre de la tabla utilizada para almacenar concesiones. Si no se especifica, el nombre de la tabla de concesiones será Leases_{FunctionId}_{TableId}. Puede encontrar más información sobre cómo se genera aquí. |
Configuración opcional
Las siguientes opciones opcionales se pueden configurar para el desencadenador de SQL para el desarrollo local o para las implementaciones en la nube.
host.json
En esta sección se describen las opciones de configuración disponibles para este enlace en la versión 2.x y posteriores. La configuración del archivo host.json se aplica a todas las funciones de una instancia de la aplicación de funciones. Para más información sobre las opciones de configuración de la aplicación de funciones, consulte host.json referencia para Azure Functions.
| Configuración | Valor predeterminado | Descripción |
|---|---|---|
| MaxBatchSize | 100 | El número máximo de cambios procesados con cada iteración del bucle desencadenador antes de enviarse a la función desencadenada. |
| PollingIntervalMs | 1 000 | El retraso en milisegundos entre el procesamiento de cada lote de cambios. (1000 ms es 1 segundo) |
| MaxChangesPerWorker | 1 000 | El límite máximo de número de cambios pendientes en la tabla de usuario que se permiten por cada trabajo de aplicación. Si el recuento de cambios supera este límite, podría dar lugar a un escalado horizontal. La configuración solo se aplica a las aplicaciones de Azure Functions con escalado controlado por tiempo de ejecución habilitado. |
Archivo de host.json de ejemplo
Este es un ejemplo host.json archivo con la configuración opcional:
{
"version": "2.0",
"extensions": {
"Sql": {
"MaxBatchSize": 300,
"PollingIntervalMs": 1000,
"MaxChangesPerWorker": 100
}
},
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
},
"logLevel": {
"default": "Trace"
}
}
}
local.setting.json
El archivo local.settings.json almacena la configuración de la aplicación y la configuración que usan las herramientas locales de desarrollo. La configuración del archivo local.settings.json solo se usa al ejecutar el proyecto de forma local. Al publicar el proyecto en Azure, asegúrese de agregar también cualquier configuración necesaria a la configuración de la aplicación para la aplicación de funciones.
Importante
Dado que local.settings.json puede contener secretos, como cadenas de conexión, nunca debe almacenarlo en un repositorio remoto. Las herramientas que admiten Functions proporcionan maneras de sincronizar la configuración del archivo local.settings.json con la configuración de la aplicación en la aplicación de funciones en la que se implementa el proyecto.
| Configuración | Valor predeterminado | Descripción |
|---|---|---|
| Sql_Trigger_BatchSize | 100 | El número máximo de cambios procesados con cada iteración del bucle desencadenador antes de enviarse a la función desencadenada. |
| Sql_Trigger_PollingIntervalMs | 1 000 | El retraso en milisegundos entre el procesamiento de cada lote de cambios. (1000 ms es 1 segundo) |
| Sql_Trigger_MaxChangesPerWorker | 1 000 | El límite máximo de número de cambios pendientes en la tabla de usuario que se permiten por cada trabajo de aplicación. Si el recuento de cambios supera este límite, podría dar lugar a un escalado horizontal. La configuración solo se aplica a las aplicaciones de Azure Functions con escalado controlado por tiempo de ejecución habilitado. |
Archivo de local.settings.json de ejemplo
Este es un ejemplo local.settings.json archivo con la configuración opcional:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"SqlConnectionString": "",
"Sql_Trigger_MaxBatchSize": 300,
"Sql_Trigger_PollingIntervalMs": 1000,
"Sql_Trigger_MaxChangesPerWorker": 100
}
}
Configuración del seguimiento de cambios (requerido)
La configuración del seguimiento de cambios para su uso con el desencadenador de Azure SQL requiere dos pasos. Estos pasos se pueden completar desde cualquier herramienta SQL que admita la ejecución de consultas, como Visual Studio Code, Azure Data Studio o SQL Server Management Studio.
Habilite el seguimiento de cambios en la base de datos SQL, cambiando
your database namepor el nombre de la base de datos donde se ubicará la tabla que se va a supervisar:ALTER DATABASE [your database name] SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);La opción
CHANGE_RETENTIONespecifica el período de tiempo durante el cual se va a conservar la información del seguimiento de cambios (historial de cambios). La retención del historial de cambios de la base de datos SQL podría afectar a la funcionalidad del desencadenador. Por ejemplo, con el ejemplo de configuración anterior, si la función de Azure está desactivada durante varios días y, a continuación, se reanuda, la base de datos contendrá los cambios que se produjeron en los últimos dos días.La opción
AUTO_CLEANUPse usa para habilitar o deshabilitar la tarea de limpieza que quita la información de seguimiento de cambios antigua. Si se produce un problema temporal que impide que el desencadenador se ejecute, desactivar la limpieza automática puede ser útil para pausar la eliminación de información anterior al período de retención hasta que dicho problema se resuelva.Encontrará más información sobre las opciones de seguimiento de cambios en la documentación de SQL.
Habilite el seguimiento de cambios en la tabla, sustituyendo
your table namepor el nombre de la tabla que se va a supervisar (cambiando el esquema, si procede):ALTER TABLE [dbo].[your table name] ENABLE CHANGE_TRACKING;El desencadenador debe tener acceso de lectura tanto en la tabla que se está supervisando en busca de cambios como en las tablas del sistema de seguimiento de cambios. Cada desencadenador de función tiene una tabla de seguimiento de cambios asociada y una tabla de concesiones en un esquema
az_func. El desencadenador crea estas tablas si aún no existen. Encontrará más información sobre estas estructuras de datos en la documentación de la biblioteca de enlaces de Azure SQL.
Activación del escalado controlado por tiempo de ejecución
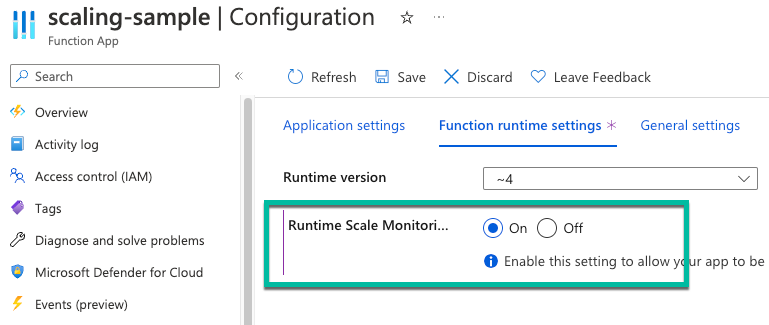
Opcionalmente, las funciones pueden escalar automáticamente en función del número de cambios pendientes de procesarse en la tabla de usuario. Para permitir que las funciones se escalen correctamente en el plan Premium al usar desencadenadores de Azure SQL, debe habilitar la supervisión del escalado basado en tiempo de ejecución.
En Azure Portal, en la aplicación de funciones, seleccione Configuración.
En la pestaña Configuración del entorno de ejecución de la función, en Supervisión de escalado en tiempo de ejecución, seleccione Activado.
Compatibilidad con los reintentos
Encontrará más información sobre la compatibilidad con la compatibilidad de reintento del desencadenador de SQL y las tablas de concesiones en el repositorio de GitHub.
Reintentos de inicio
Si se produce una excepción durante el inicio, el tiempo de ejecución del host intenta reiniciar automáticamente el agente de escucha del desencadenador con una estrategia de retroceso exponencial. Estos reintentos continúan hasta que el agente de escucha se inicia correctamente o se cancela el inicio.
Reintentos de conexión interrumpidos
Si la función se inicia correctamente, pero un error hace que la conexión se interrumpa (por ejemplo, el servidor se queda sin conexión), la función continúa intentando volver a abrir la conexión hasta que la función se detenga o la conexión se realice correctamente. Si la conexión se vuelve a establecer correctamente, toma los cambios de procesamiento donde se dejó.
Tenga en cuenta que estos reintentos están fuera de la lógica de reintento de conexión inactiva integrada que SqlClient tiene, que se puede configurar con las ConnectRetryCount opciones y ConnectRetryIntervalcadena de conexión. Los reintentos de conexión inactivos integrados se intentan primero y, si no se pueden volver a conectar, el enlace de desencadenador intenta volver a establecer la propia conexión.
Reintentos de excepción de función
Si se produce una excepción en la función de usuario al procesar los cambios, el lote de filas que se está procesando se vuelve a intentar en 60 segundos. Otros cambios se procesan como normales durante este tiempo, pero las filas del lote que provocaron la excepción se omiten hasta que haya transcurrido el período de tiempo de espera.
Si se produce un error en la ejecución de la función cinco veces en una fila para una fila determinada, esa fila se omite por completo para todos los cambios futuros. Dado que las filas de un lote no son deterministas, es posible que las filas de un lote con errores terminen en lotes diferentes en invocaciones posteriores. Esto significa que no todas las filas del lote con errores se omitirán necesariamente. Si otras filas del lote eran las que provocaban la excepción, las filas "buenas" podrían acabar en un lote diferente que no produzca un error en futuras invocaciones.