Implementación de un contenedor de Azure SQL Edge en Kubernetes
Importante
Azure SQL Edge se retirará el 30 de septiembre de 2025. Para obtener más información y opciones de migración, consulte el aviso de retirada.
Nota:
Azure SQL Edge ya no admite la plataforma ARM64.
Azure SQL Edge se puede implementar en un clúster de Kubernetes como un módulo de IoT Edge a través de Azure IoT Edge que se ejecuta en Kubernetes, o bien como un pod de contenedor independiente. En el resto de este artículo, nos centraremos en la implementación de contenedores independientes en un clúster de Kubernetes. Para obtener información sobre cómo implementar Azure IoT Edge en Kubernetes, consulte Azure IoT Edge en Kubernetes (versión preliminar).
En este tutorial se explica cómo configurar una instancia de Azure SQL Edge de alta disponibilidad en un contenedor en un clúster de Kubernetes.
- Creación de una contraseña de administrador del sistema
- Creación de almacenamiento
- Creación de la implementación
- Conexión con SQL Server Management Studio (SSMS)
- Comprobación de errores y recuperación
Kubernetes 1.6 y versiones posteriores admite clases de almacenamiento, notificaciones de volumen persistente y el tipo de volumen de disco de Azure. Puede crear y administrar las instancias de Azure SQL Edge de forma nativa en Kubernetes. En el ejemplo de este artículo se muestra cómo crear una implementación para lograr una configuración de alta disponibilidad similar a una instancia de clúster de conmutación por error de disco compartido. En esta configuración, Kubernetes desempeña el papel de orquestador de clústeres. Si se produce un error en una instancia de Azure SQL Edge de un contenedor, el orquestador arranca otra instancia del contenedor que se adjunta al mismo almacenamiento persistente.
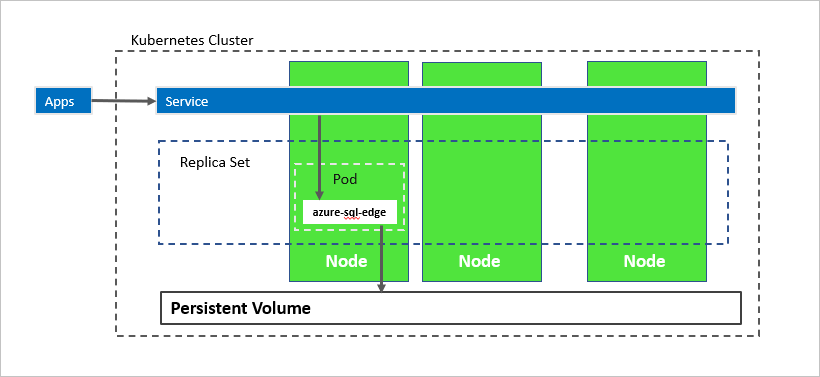
En el diagrama anterior, azure-sql-edge es un contenedor en un pod. Kubernetes orquesta los recursos del clúster. Un conjunto de réplicas garantiza que el pod se recupere automáticamente tras un error de nodo. Las aplicaciones se conectan al servicio. En este caso, el servicio representa un equilibrador de carga que hospeda una dirección IP que permanece igual tras un error de azure-sql-edge.
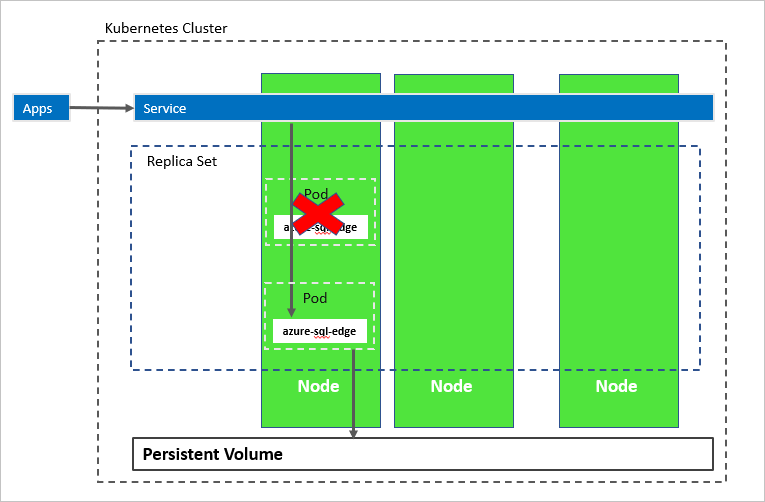
En el diagrama siguiente, se ha producido un error del contenedor azure-sql-edge. Como orquestador, Kubernetes garantiza el recuento correcto de instancias correctas en el conjunto de réplicas e inicia un nuevo contenedor de acuerdo con la configuración. El orquestador inicia un nuevo pod en el mismo nodo y azure-sql-edge se vuelve a conectar al mismo almacenamiento persistente. El servicio se conecta al nuevo azure-sql-edge creado.
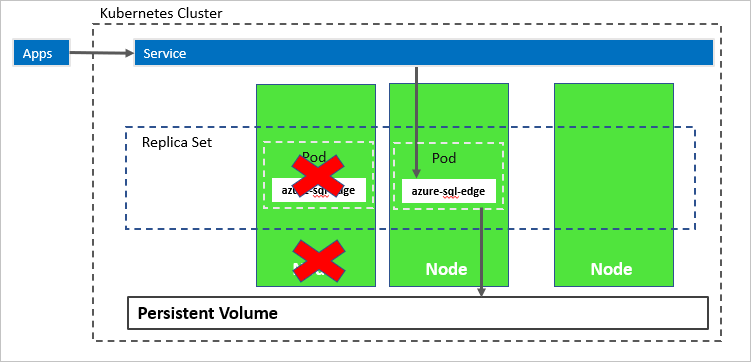
En el diagrama siguiente, se ha producido un error en el nodo que hospeda el contenedor azure-sql-edge. El orquestador inicia el nuevo pod en otro nodo y azure-sql-edge se vuelve a conectar al mismo almacenamiento persistente. El servicio se conecta al nuevo azure-sql-edge creado.
Requisitos previos
Clúster de Kubernetes
El tutorial requiere un clúster de Kubernetes. En los pasos se usa kubectl para administrar el clúster.
En este tutorial, usamos Azure Kubernetes Service para implementar Azure SQL Edge. Consulte Implementación de un clúster de Azure Kubernetes Service (AKS) para crear un clúster de Kubernetes de un solo nodo en AKS con
kubectly conectarse a él.
Nota
Para protegerse frente a errores de nodo, un clúster de Kubernetes requiere más de un nodo.
CLI de Azure
- Las instrucciones de este tutorial se han validado con la CLI de Azure 2.10.1.
Creación de un espacio de nombres de Kubernetes para la implementación de SQL Edge
Cree un nuevo espacio de nombres en el clúster de Kubernetes. Este espacio de nombres se usa para implementar SQL Edge y todos los artefactos necesarios. Para obtener más información sobre los espacios de nombres de Kubernetes, consulte Espacios de nombres.
kubectl create namespace <namespace name>
Creación de una contraseña de administrador del sistema
Cree una contraseña de administrador del sistema en el clúster de Kubernetes. Kubernetes puede administrar información de configuración confidencial (por ejemplo, las contraseñas) como secretos.
El siguiente comando crea una contraseña para la cuenta SA:
kubectl create secret generic mssql --from-literal=MSQL_SA_PASSWORD="<password>" -n <namespace name>
Reemplace MyC0m9l&xP@ssw0rd por una contraseña compleja.
Creación de almacenamiento
Configure un volumen persistente y una notificación de volumen persistente en el clúster de Kubernetes. Complete los pasos siguientes:
Cree un manifiesto para definir la clase de almacenamiento y la notificación de volumen persistente. El manifiesto especifica el aprovisionamiento de almacenamiento, los parámetros y la directiva de recuperación. El clúster de Kubernetes usa este manifiesto para crear el almacenamiento persistente.
En el siguiente ejemplo de YAML se define una clase de almacenamiento y una notificación de volumen persistente. El almacenamiento de la clase de almacenamiento es
azure-diskporque este clúster de Kubernetes está en Azure. El tipo de cuenta de almacenamiento esStandard_LRS. La notificación de volumen persistente se denominamssql-data. Los metadatos de la notificación de volumen persistente incluyen una anotación que lo vuelve a conectar con la clase de almacenamiento.kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: azure-disk provisioner: kubernetes.io/azure-disk parameters: storageaccounttype: Standard_LRS kind: managed --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: mssql-data annotations: volume.beta.kubernetes.io/storage-class: azure-disk spec: accessModes: - ReadWriteOnce resources: requests: storage: 8GiGuarde el archivo (por ejemplo, pvc.yaml).
Cree la notificación de volumen persistente en Kubernetes.
kubectl apply -f <Path to pvc.yaml file> -n <namespace name><Path to pvc.yaml file>es la ubicación en la que ha guardado el archivo.El volumen persistente se crea automáticamente como una cuenta de Azure Storage y se enlaza a la notificación de volumen persistente.
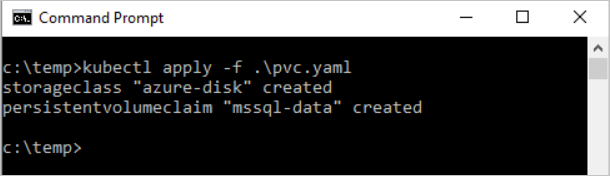
Compruebe la notificación de volumen persistente.
kubectl describe pvc <PersistentVolumeClaim> -n <name of the namespace><PersistentVolumeClaim>es el nombre de la notificación de volumen persistente.En el paso anterior, la notificación de volumen persistente se denomina
mssql-data. Para ver los metadatos sobre la notificación de volumen persistente, ejecute el siguiente comando:kubectl describe pvc mssql-data -n <namespace name>Los metadatos devueltos incluyen un valor denominado
Volume. Este valor se asigna al nombre del blob.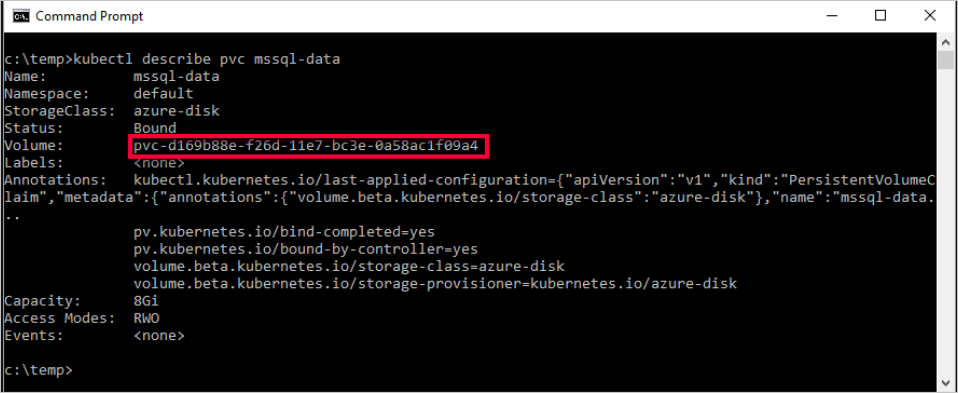
Compruebe el volumen persistente.
kubectl describe pv -n <namespace name>kubectldevuelve metadatos sobre el volumen persistente que se ha creado automáticamente y se ha enlazado a la notificación de volumen persistente.
Creación de la implementación
En este ejemplo, el contenedor que hospeda la instancia de Azure SQL Edge se describe como un objeto de implementación de Kubernetes. La implementación crea un conjunto de réplicas. El conjunto de réplicas crea el pod.
En este paso, cree un manifiesto para describir el contenedor basado en la imagen de Docker de Azure SQL Edge. El manifiesto hace referencia a la notificación de volumen persistente mssql-data y al secreto mssql que ya ha aplicado al clúster de Kubernetes. El manifiesto también describe un servicio. Este servicio es un equilibrador de carga. El equilibrador de carga garantiza que la dirección IP se conserva después de que se recupere la instancia de Azure SQL Edge.
Cree un manifiesto (un archivo YAML) para describir la implementación. En el ejemplo siguiente se describe una implementación, incluido un contenedor basado en la imagen de contenedor de Azure SQL Edge.
apiVersion: apps/v1 kind: Deployment metadata: name: sqledge-deployment spec: replicas: 1 selector: matchLabels: app: sqledge template: metadata: labels: app: sqledge spec: volumes: - name: sqldata persistentVolumeClaim: claimName: mssql-data containers: - name: azuresqledge image: mcr.microsoft.com/azure-sql-edge:latest ports: - containerPort: 1433 volumeMounts: - name: sqldata mountPath: /var/opt/mssql env: - name: MSSQL_PID value: "Developer" - name: ACCEPT_EULA value: "Y" - name: MSSQL_SA_PASSWORD valueFrom: secretKeyRef: name: mssql key: MSSQL_SA_PASSWORD - name: MSSQL_AGENT_ENABLED value: "TRUE" - name: MSSQL_COLLATION value: "SQL_Latin1_General_CP1_CI_AS" - name: MSSQL_LCID value: "1033" terminationGracePeriodSeconds: 30 securityContext: fsGroup: 10001 --- apiVersion: v1 kind: Service metadata: name: sqledge-deployment spec: selector: app: sqledge ports: - protocol: TCP port: 1433 targetPort: 1433 name: sql type: LoadBalancerCopie el código anterior en un nuevo archivo denominado
sqldeployment.yaml. Actualice los siguientes valores:MSSQL_PID
value: "Developer": configura el contenedor para ejecutar la edición Developer de Azure SQL Edge. La edición Developer no tiene licencia para los datos de producción. Si la implementación es para su uso en producción, establezca la edición adecuada enPremium.Nota
Para obtener más información, consulte Obtención de una licencia de Azure SQL Edge.
persistentVolumeClaim: este valor requiere una entrada paraclaimName:que se asigne al nombre usado para la notificación de volumen persistente. En este tutorial se usamssql-data.name: MSSQL_SA_PASSWORD: Configura la imagen de contenedor para establecer la contraseña de administrador del sistema, tal como se define en esta sección.valueFrom: secretKeyRef: name: mssql key: MSSQL_SA_PASSWORDCuando Kubernetes implementa el contenedor, hace referencia al secreto denominado
mssqlpara obtener el valor de la contraseña.
Nota
Al usar el tipo de servicio
LoadBalancer, se puede acceder a la instancia de Azure SQL Edge de forma remota (mediante Internet) en el puerto 1433.Guarde el archivo (por ejemplo,
sqledgedeploy.yaml).Cree la implementación.
kubectl apply -f <Path to sqledgedeploy.yaml file> -n <namespace name><Path to sqldeployment.yaml file>es la ubicación en la que ha guardado el archivo.
Se crean la implementación y el servicio. La instancia de Azure SQL Edge está en un contenedor, que está conectado al almacenamiento persistente.
Para ver el estado del pod, escriba
kubectl get pod -n <namespace name>.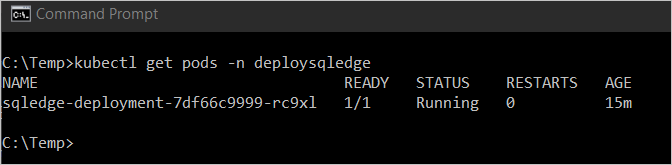
En la imagen anterior, el pod tiene un estado de
Running. Este estado indica que el contenedor está listo. Esto podría tardar varios minutos.Nota
Una vez creada la implementación, pueden pasar unos minutos hasta que el pod se pueda ver. El retraso se debe a que el clúster extrae la imagen de contenedor de Azure SQL Edge del centro de Docker. Una vez que se extrae la imagen por primera vez, las implementaciones posteriores pueden ser más rápidas si la implementación se realiza en un nodo que ya tiene la imagen almacenada en la memoria caché.
Compruebe que los servicios se está ejecutando. Ejecute el siguiente comando:
kubectl get services -n <namespace name>Este comando devuelve los servicios que se están ejecutando, así como sus direcciones IP internas y externas. Anote la dirección IP externa del servicio
mssql-deployment. Use esta dirección IP para conectarse a Azure SQL Edge.
Para obtener más información sobre el estado de los objetos en el clúster de Kubernetes, ejecute:
az aks browse --resource-group <MyResourceGroup> --name <MyKubernetesClustername>
Conexión a la instancia de Azure SQL Edge
Si ha configurado el contenedor como se ha descrito, puede conectarse con una aplicación desde fuera de la red virtual de Azure. Use la cuenta sa y la dirección IP externa del servicio. Use la contraseña que ha configurado como secreto de Kubernetes. Para obtener más información sobre cómo conectarse a una instancia de Azure SQL Edge, consulte Conexión a Azure SQL Edge.
Comprobación de errores y recuperación
Para comprobar los errores y la recuperación, puede eliminar el pod. Siga estos pasos:
Muestre el pod que ejecuta Azure SQL Edge.
kubectl get pods -n <namespace name>Anote el nombre del pod que ejecuta Azure SQL Edge.
Elimine el pod.
kubectl delete pod sqledge-deployment-7df66c9999-rc9xlsqledge-deployment-7df66c9999-rc9xles el valor devuelto del paso anterior para el nombre del pod.
Kubernetes vuelve a crear automáticamente el pod para recuperar una instancia de Azure SQL Edge y se conecta al almacenamiento persistente. Use kubectl get pods para comprobar que se ha implementado un nuevo pod. Use kubectl get services para comprobar que la dirección IP del nuevo contenedor es la misma.
Resumen
En este tutorial, ha aprendido a implementar contenedores de Azure SQL Edge en un clúster de Kubernetes para la alta disponibilidad.
- Creación de una contraseña de administrador del sistema
- Creación de almacenamiento
- Creación de la implementación
- Conexión con Azure SQL Edge Management Studio (SSMS)
- Comprobación de errores y recuperación