Aplicaciones de datos (alineadas con el origen)
Si ha decidido no implementar un motor independiente de datos para ingerirlos una vez desde orígenes operativos, o si las conexiones complejas no se facilitan en el motor de datos independiente, debe crear una aplicación de datos alineada con el origen. Debe seguir el mismo flujo que un motor independiente de datos al ingerir datos de orígenes de datos externos.
Información general
El grupo de recursos de aplicación es responsable de la ingesta y el enriquecimiento de datos solo de orígenes externos, como los de telemetría, finanzas y CRM. Esta capa puede funcionar en tiempo real, por lotes y en microlotes.
En esta sección se explica la infraestructura implementada para cada grupo de recursos de la aplicación de datos en una zona de aterrizaje de datos.
Sugerencia
En el caso de la malla de datos, puede optar por implementar uno de estos por origen o por dominio. Los principios de normalización de datos, calidad de los datos y linaje de datos deben seguirse. Los equipos de operaciones de plataforma de datos pueden desarrollar fragmentos de código estándar y llamarlos para lograr esto.
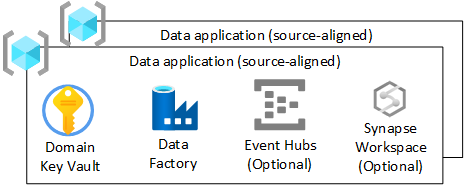
Para cada grupo de recursos de la aplicación de datos (alineada con el origen) en la zona de aterrizaje de datos, debe crear:
- Una instancia de Azure Key Vault
- Un instancia de Azure Data Factory para ejecutar canalizaciones de ingeniería desarrolladas para transformar datos sin formato a enriquecidos.
- Una entidad de servicio que usa la aplicación de datos (alineada con el origen) para implementar trabajos de ingesta en Azure Databricks (solo si usa Azure Databricks).
También puede crear instancias de otros servicios, como Azure Event Hubs, Azure IoT Hub, Azure Stream Analytics y Azure Machine Learning.
Nota:
Debe usar un motor de Spark como Azure Synapse Spark o Azure Databricks para aplicar Delta Lake Estándar.
Si decide usar Azure Databricks, se recomienda implementar Azure Data Factory en lugar del área de trabajo de Azure Synapse Analytics para reducir el área expuesta a solo las características necesarias.
Sin embargo, si necesita un área de desarrollo integral con canalizaciones y Spark, use Azure Synapse Analytics. Aplique una directiva para permitir solo el uso de Spark y canalizaciones para evitar la creación de silos en un grupo de Azure Synapse SQL.
Azure Key Vault
Use la funcionalidad de Azure Key Vault para almacenar secretos en Azure siempre que sea posible.
Cada grupo de recursos de la aplicación de datos (alineada con el origen) o dominio de datos (si es malla) tendrá un Key Vault de Azure. Esto garantizará que la clave de cifrado, el secreto y la derivación de certificados cumplan los requisitos del entorno. Esto permite una mejor separación de las tareas administrativas y también reduce el riesgo de mezclar claves, integraciones y secretos de diferentes clasificaciones.
Todas las claves relacionadas con la aplicación de datos (alineada con el origen) deben estar contenidas en Azure Key Vault.
Importante
Los almacenes de claves de la aplicación de datos (alineada con el origen) deben seguir el modelo de privilegios mínimos y deben evitar tanto los límites de escalado de transacciones como el uso compartido de secretos entre entornos.
Azure Data Factory
Implemente una instancia de Azure Data Factory para permitir que las canalizaciones escritas por el equipo de la aplicación de datos conviertan datos sin procesar en datos enriquecidos mediante canalizaciones desarrolladas. Use flujos de datos de asignación para las transformaciones y desglose para usar el área de trabajo de Azure Databricks (ingesta) o Azure Synapse Spark para transformaciones complejas.
Debe conectar Azure Data Factory a la instancia de DevOps del repositorio de la aplicación de datos (alineada con el origen). Esta conexión permite implementaciones de CI/CD.
Event Hubs
Si la aplicación de datos (alineada con el origen) tiene un requisito para transmitir datos, puede implementar instancias de Event Hubs de bajada en el grupo de recursos de la aplicación de datos (alineada con el origen).