Motor de ingesta independiente de los datos
En este artículo se explica cómo implementar escenarios de motor de ingesta independiente de los datos mediante una combinación de PowerApps, Azure Logic Apps y tareas de copia controladas por metadatos en Azure Data Factory.
Los escenarios del motor de ingesta independiente de los datos suelen centrarse en permitir que los usuarios legos (no los ingenieros de datos) publiquen recursos de datos en Data Lake para su posterior procesamiento. Para implementar este escenario, debe tener funcionalidades de incorporación que permiten:
- El registro de recursos de datos.
- La captura de metadatos y el aprovisionamiento de los flujos de trabajo.
- La programación de la ingesta.
Observe la interacción de estas funcionalidades:
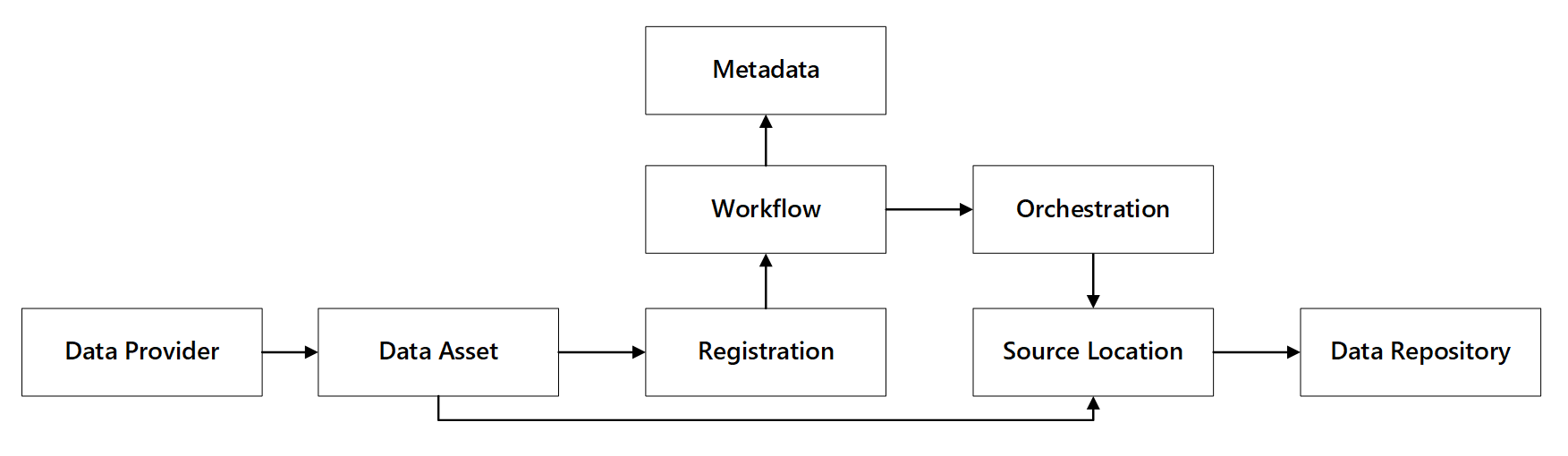
Figura 1: interacciones de las funcionalidades de registro de datos.
En el diagrama siguiente se muestra cómo implementar este proceso mediante una combinación de servicios de Azure:
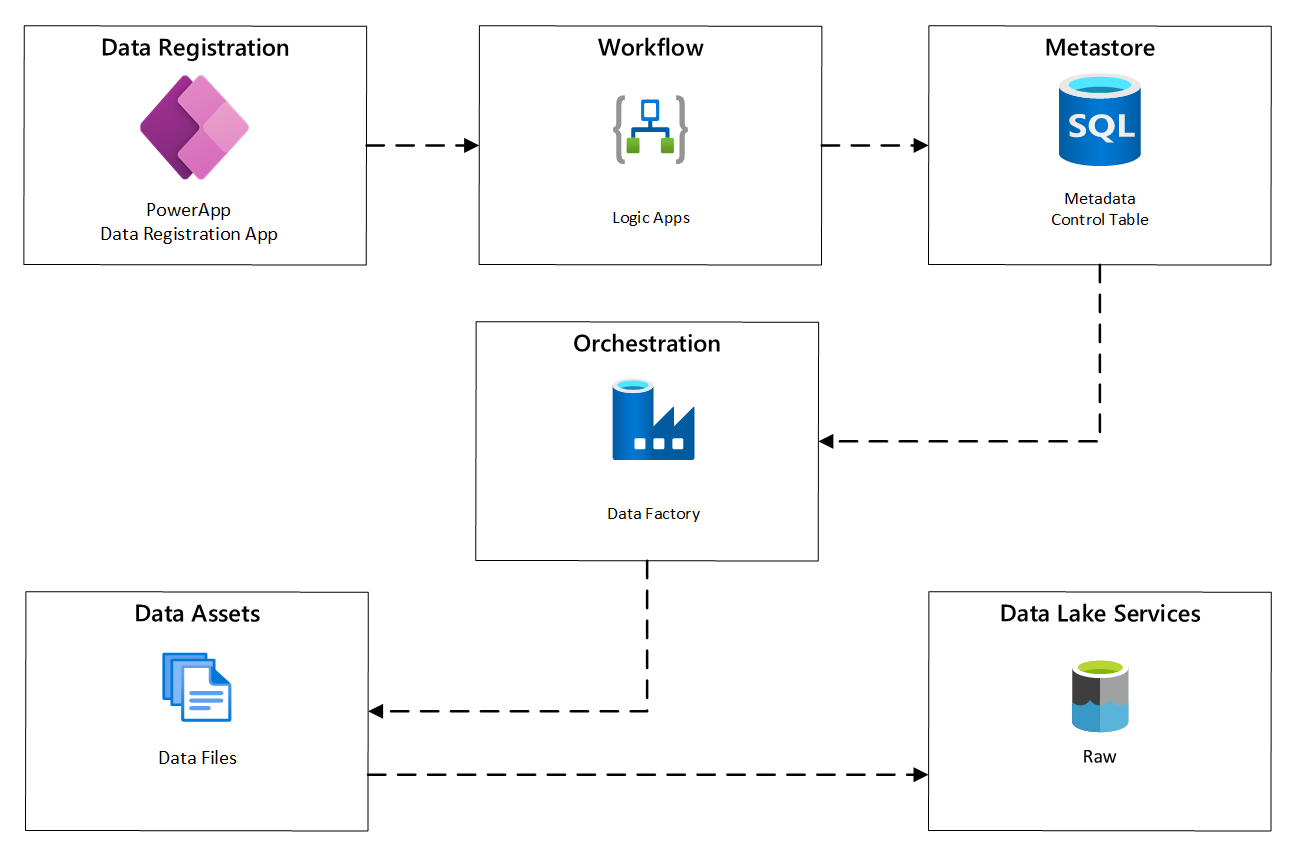
Figura 2: proceso de ingesta automatizado.
El registro de recursos de datos.
Para proporcionar los metadatos usados para controlar la ingesta automatizada, necesita el registro de los recursos de datos. La información que se captura contiene:
- Información técnica: nombre del recurso de datos, sistema de origen, tipo, formato y frecuencia.
- Información de gobernanza: propietario, administradores, visibilidad (con fines de detección) y confidencialidad.
PowerApps se usa para capturar los metadatos que describen cada recurso de datos. Use una aplicación controlada por modelos para escribir la información que se conserva en una tabla personalizada de Dataverse. Cuando los metadatos se crean o se actualizan en Dataverse, se desencadena un flujo de nube automatizado que invoca pasos de procesamiento adicionales.
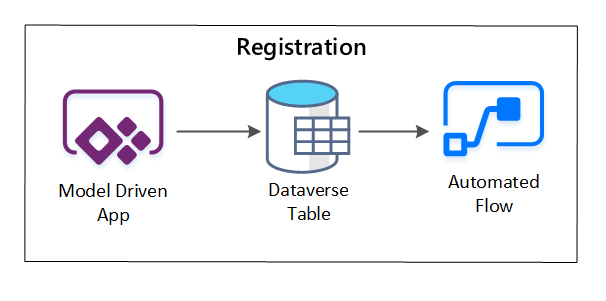
Figura 3: registro de los recursos de datos.
Flujo de trabajo de aprovisionamiento o captura de los metadatos
En la fase de flujo de trabajo de aprovisionamiento, se validan y se conservan los datos recopilados en la fase de registro en el metastore. Se realizan los pasos técnicos y de validación empresarial, entre los que se incluyen:
- La validación de la fuente de distribución de los datos de entrada.
- El desencadenamiento del flujo de trabajo de aprobación.
- El procesamiento lógico para desencadenar la conservación de los metadatos en el almacén de metadatos.
- La auditoría de las actividades.
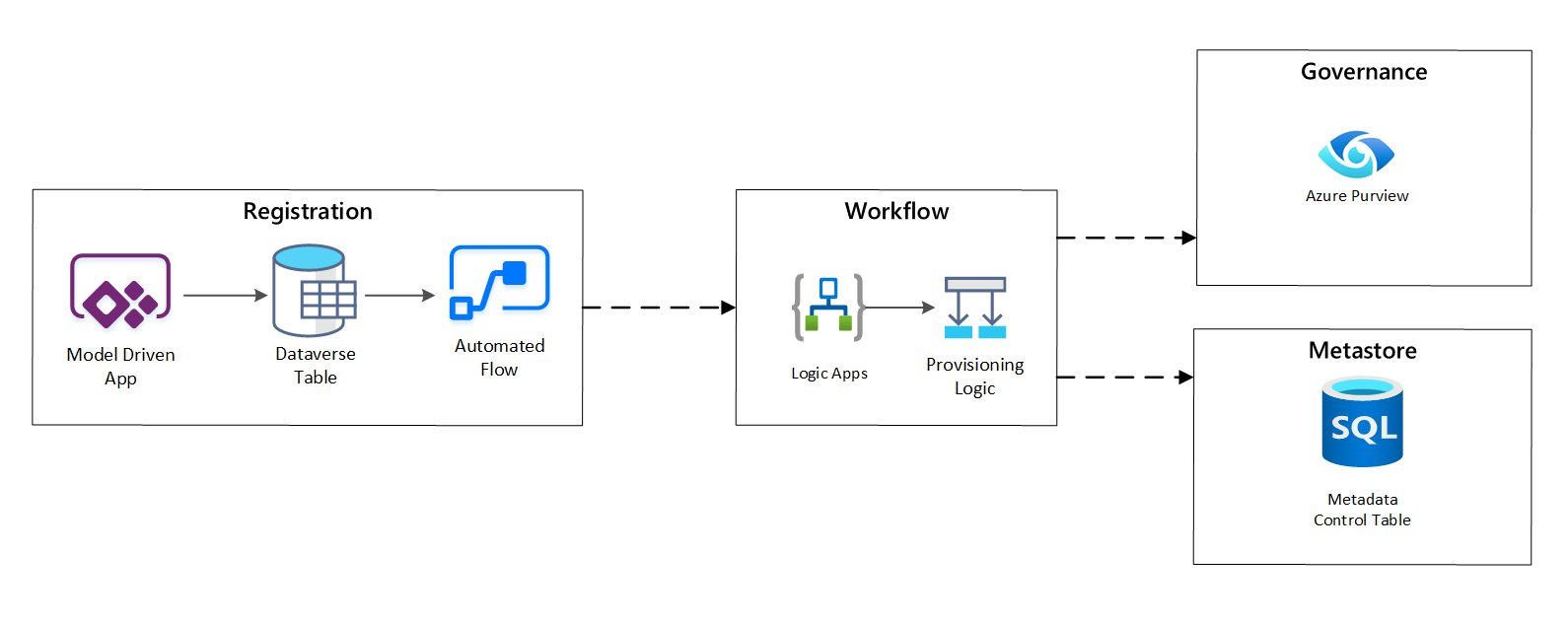
Figura 4: flujo de trabajo de registro.
Una vez aprobadas las solicitudes de ingesta, el flujo de trabajo usa la API REST de Azure Purview para insertar los orígenes en Azure Purview.
Flujo de trabajo detallado para incorporar productos de datos
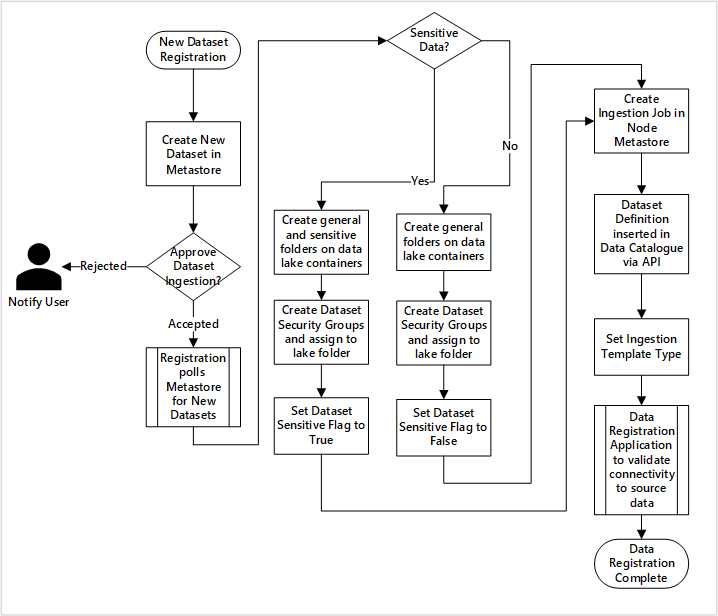
Figura 5: ingesta de nuevos conjuntos de datos (automatizada).
En la ilustración 5 se muestra el proceso de registro detallado para automatizar la ingesta de orígenes de datos nuevos:
- Se registran los detalles de origen, incluidos los entornos de producción y de la factoría de datos.
- Se capturan las restricciones de calidad, formato y forma de datos.
- Los equipos de aplicaciones de datos deben indicar si los datos son confidenciales (datos personales); esta clasificación impulsa el proceso durante el cual se crean carpetas del lago de datos para ingerir datos sin procesar, enriquecidos y mantenidos. El origen asigna nombres a los datos sin procesar y enriquecidos y el producto de datos, a los datos mantenidos.
- La entidad de servicio y los grupos de seguridad se crean para ingerir y otorgar acceso a un conjunto de datos.
- Se crea un trabajo de ingesta en la zona de aterrizaje de datos del metastore de Data Factory.
- Una API inserta la definición de datos en Azure Purview.
- Sujeto a la validación del origen de datos y a la aprobación por parte del equipo de operaciones, los detalles se publican en un metastore de Data Factory.
La programación de la ingesta.
En Azure Data Factory, las tareas de copia controladas por metadatos proporcionan una funcionalidad que permite que las canalizaciones de orquestación se controlen mediante filas dentro de una tabla de control almacenada en Azure SQL Database. Puede usar la herramienta Copiar datos para crear previamente canalizaciones controladas por metadatos.
Una vez creada una canalización, el flujo de trabajo de aprovisionamiento agrega entradas a la tabla de control para admitir la ingesta de orígenes identificados por los metadatos de registro de los recursos de datos. Tanto las canalizaciones de Azure Data Factory como la instancia de Azure SQL Database que contiene el metastore de la tabla de control pueden existir dentro de cada zona de aterrizaje de datos para la creación de orígenes de datos y su ingesta en zonas de aterrizaje de datos.
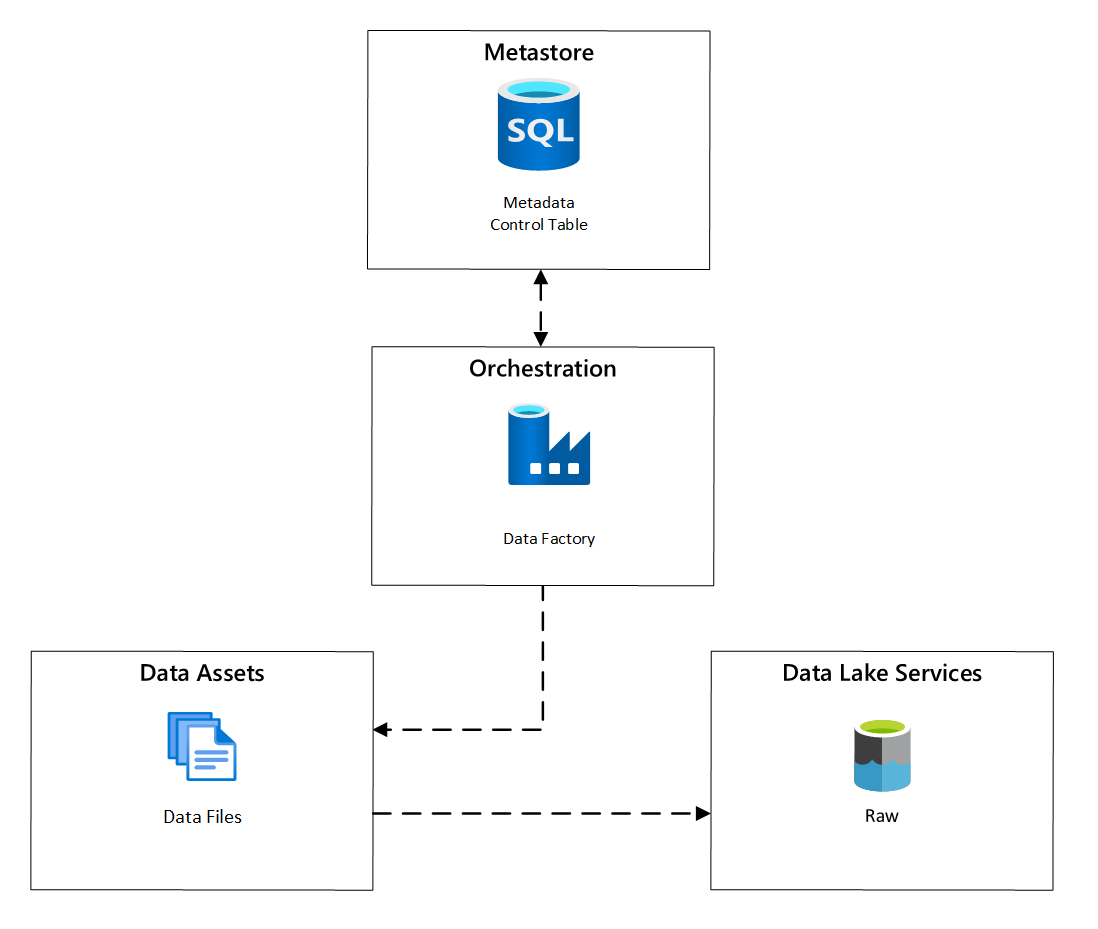
Figura 6: programación de la ingesta de los recursos de datos.
Flujo de trabajo detallado para ingerir nuevos orígenes de datos
En el diagrama siguiente se muestra cómo se extraen los orígenes de datos registrados en un metastore de SQL Database de Data Factory y cómo se ingieren los datos al principio:
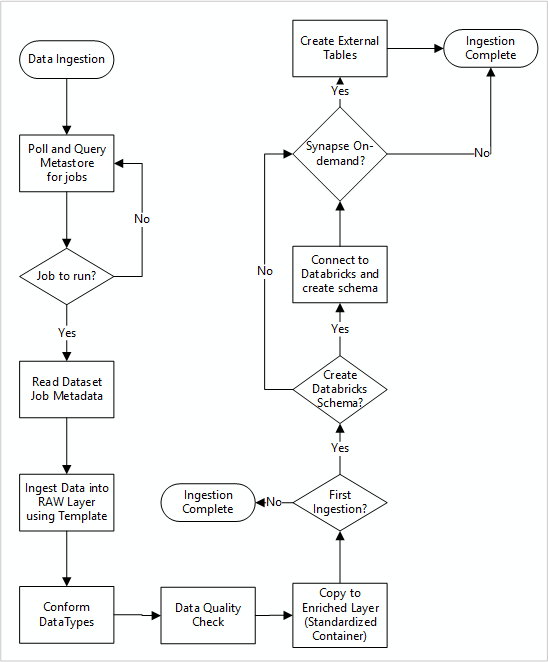
La canalización maestra de la ingesta de Data Factory lee las configuraciones de un metastore de SQL Database de Data Factory y se ejecuta de forma iterativa con los parámetros correctos. Los datos se mueven con poco o ningún cambio de la capa de origen a la capa sin procesar de Azure Data Lake. La forma de los datos se valida en función del metastore de Data Factory. El formato de los archivos se convierte a Apache Parquet o Avro y estos se copian después en la capa enriquecida.
Los datos ingeridos se conectan a un área de trabajo de ingeniería y ciencia de datos de Azure Databricks y se crea una definición de los datos dentro del metastore de Apache Hive de la zona de aterrizaje de los datos.
Si necesita usar un grupo de Azure Synapse SQL sin servidor para exponer datos, la solución personalizada debe crear vistas de los datos en el lago.
Si necesita cifrado de nivel de fila o de columna, la solución personalizada debe aterrizar los datos en el lago e ingerirlos directamente en tablas internas de los grupos de SQL y configurar la seguridad adecuada en el proceso de los grupos de SQL.
Metadatos capturados
Al usar la ingesta de datos automatizada, puede consultar los metadatos asociados y crear paneles para:
- Realizar un seguimiento de los trabajos y las marcas de tiempo de carga de datos más recientes de los productos de datos relacionados con sus funciones.
- Realizar un seguimiento de los productos de datos disponibles.
- Aumentar los volúmenes de datos.
- Obtener actualizaciones en tiempo real sobre los errores de trabajo.
Los metadatos operativos se pueden usar para supervisar:
- Trabajos, pasos de trabajos y sus dependencias.
- Historial de rendimiento y rendimiento del trabajo.
- Crecimiento del volumen de datos.
- Errores de trabajo.
- Cambios en los metadatos de origen.
- Funciones empresariales que dependen de productos de datos.
Uso de la API REST de Azure Purview para detectar datos
Para registrar los datos durante la primera ingesta deben usarse las API REST de Azure Purview. Puede usar las API para enviar datos al catálogo de datos poco después de su ingesta.
Para más información, consulte Uso de las API REST de Azure Purview.
Registrar orígenes de datos
Use la siguiente llamada API para registrar nuevos orígenes de datos:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
Parámetros URI para el origen de datos:
| Nombre | Obligatorio | Tipo | Descripción |
|---|---|---|---|
accountName |
True | String | Nombre de la cuenta de Azure Purview |
dataSourceName |
Verdadero | String | Nombre del origen de datos |
Uso de la API REST de Azure Purview para detectar datos
En los ejemplos siguientes se muestra cómo usar la API REST de Azure Purview para registrar orígenes de datos con cargas:
Registro de un origen de datos de Azure Data Lake Storage Gen2:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Registro de un origen de datos de Azure SQL Database:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Nota:
<collection-name> es una colección actual que existe en una cuenta de Azure Purview.
Creación de un examen
Aprenda a crear credenciales para autenticar orígenes en Azure Purview antes de configurar y ejecutar un examen.
Use la siguiente llamada API para examinar orígenes de datos:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
Parámetros URI para un examen:
| Nombre | Obligatorio | Tipo | Descripción |
|---|---|---|---|
accountName |
True | String | Nombre de la cuenta de Azure Purview |
dataSourceName |
Verdadero | String | Nombre del origen de datos |
newScanName |
Verdadero | String | Nombre del nuevo examen |
Uso de la API REST de Azure Purview para examinar
En los ejemplos siguientes se muestra cómo usar la API REST de Azure Purview para examinar orígenes de datos con cargas:
Examine el origen de datos de Azure Data Lake Storage Gen2:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Examine un origen de datos de Azure SQL Database:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Use la siguiente llamada API para examinar orígenes de datos:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run