Procedimientos recomendados para proyectos de ciencia de datos con análisis a escala de nube en Azure
Se recomiendan estos procedimientos recomendados para usar el análisis a escala de nube en Microsoft Azure con el objetivo de operacionalizar los proyectos de ciencia de datos.
Desarrollo de un plano técnico
El desarrollo de un plano técnico que agrupa un conjunto de servicios para los proyectos de ciencia de datos es esencial para mantener la coherencia entre los distintos casos de uso de los equipos de ciencia de datos. Se recomienda desarrollar un plano técnico coherente en forma de repositorio de plantillas que pueda usar para varios proyectos de ciencia de datos dentro de la empresa para ayudar a reducir los tiempos de implementación.
Directrices para plantillas de ciencia de datos
Desarrolle una plantilla de ciencia de datos para su organización con las siguientes directrices:
Desarrolle un conjunto de infraestructuras como plantillas de código para implementar un área de trabajo de Azure Machine Learning. Incluya recursos como un almacén de claves, una cuenta de almacenamiento, Azure Application Insights y un registro de contenedor.
Incluya la configuración de almacenes de datos y destinos de proceso en estas plantillas, como instancias de proceso, clústeres de proceso y Azure Databricks.
Procedimientos recomendados de implementación
Tiempo real
Incluya una implementación de Azure Data Factory o Azure Synapse en plantillas y Azure Cognitive Services.
Las plantillas deben proporcionar todas las herramientas necesarias para ejecutar la fase de exploración de ciencia de datos y la operacionalización inicial del modelo.
Consideraciones para una configuración inicial
En algunos casos, los científicos de datos de su organización pueden necesitar un entorno para realizar análisis rápidos en función de las necesidades. Esta situación es habitual cuando un proyecto de ciencia de datos no está configurado formalmente. Por ejemplo, podría faltar un administrador de proyectos, un código de costo o un centro de costos, que podrían ser necesarios para realizar cargos cruzados en Azure, porque el elemento que falta necesita aprobación. Es posible que los usuarios de su organización o equipo necesiten acceder a un entorno de ciencia de datos para comprender los datos y, posiblemente, evaluar la viabilidad de un proyecto. Además, es posible que algunos proyectos no requieran un entorno de ciencia de datos completo debido al pequeño número de productos de datos.
En otros casos, podría ser necesario un proyecto de ciencia de datos completo con un entorno dedicado, administración de proyectos, código de costo y centro de costos. Los proyectos completos de ciencia de datos son útiles para varios miembros del equipo que desean colaborar, compartir resultados y necesitan poner en marcha modelos después de que la fase de exploración se realice correctamente.
Proceso de configuración
Las plantillas se deben implementar por proyecto una vez configuradas. Cada proyecto debe recibir al menos dos instancias para que los entornos de desarrollo y producción se separen. En el entorno de producción, ninguna persona individual debe tener acceso y todo debe implementarse a través de canalizaciones de integración continua o desarrollo continuo y una entidad de servicio. Estos principios del entorno de producción son importantes porque Azure Machine Learning no proporciona un modelo de control de acceso basado en rol granular dentro de un área de trabajo. No puede limitar el acceso de los usuarios a un conjunto específico de experimentos, puntos de conexión o canalizaciones.
Los mismos derechos de acceso se aplican normalmente a diferentes tipos de artefactos. Es importante separar el desarrollo de producción para evitar que las canalizaciones o puntos de conexión de producción se eliminen dentro de un área de trabajo. Junto con la plantilla, es necesario crear un proceso para ofrecer a los equipos de productos de datos la opción de solicitar nuevos entornos.
Se recomienda configurar diferentes servicios de IA, como Azure Cognitive Services por proyecto. Al configurar diferentes servicios de IA por proyecto, se producen implementaciones para cada grupo de recursos de producto de datos. Esta directiva crea una separación clara desde el punto de vista del acceso a datos y mitiga el riesgo de que los equipos equivocados accedan a datos no autorizados.
Escenario de streaming
Para los casos de uso de streaming y en tiempo real, las implementaciones deben probarse en una versión de tamaño reducido de Azure Kubernetes Service (AKS). Las pruebas pueden estar en el entorno de desarrollo para ahorrar costos antes de implementar en AKS de producción o Azure App Service para contenedores. Debe realizar pruebas sencillas de entrada y salida para asegurarse de que los servicios responden como se espera.
A continuación, puede implementar modelos en el servicio que desee. Este destino de proceso de implementación es el único que está disponible con carácter general y recomendado para cargas de trabajo de producción en un clúster de AKS. Este paso es más necesario si se requiere compatibilidad con la unidad de procesamiento gráfico (GPU) o la matriz de puertas programables por campo. Otras opciones de implementación nativa que admiten estos requisitos de hardware no están disponibles actualmente en Azure Machine Learning.
Azure Machine Learning requiere una asignación uno a uno a los clústeres de AKS. Cada nueva conexión a un área de trabajo de Azure Machine Learning interrumpe la conexión anterior entre AKS y Azure Machine Learning. Una vez mitigada esa limitación, se recomienda implementar clústeres de AKS centrales como recursos compartidos y adjuntarlos a sus respectivas áreas de trabajo.
Debe hospedarse otra instancia de AKS de prueba central si se deben realizar pruebas de esfuerzo antes de mover un modelo a AKS de producción. El entorno de prueba debe proporcionar el mismo recurso de proceso que el entorno de producción para asegurarse de que los resultados son lo más similares posibles al entorno de producción.
Escenario de Batch
No todos los casos de uso necesitan implementaciones de clúster de AKS. Un caso de uso no necesita la implementación de un clúster AKS si las grandes cantidades de datos solo necesitan puntuarse regularmente o se basan en un evento. Por ejemplo, las grandes cantidades de datos pueden basarse en el momento en el que caen los datos en una cuenta de almacenamiento específica. Las canalizaciones de Azure Machine Learning y los clústeres de proceso de Azure Machine Learning deben usarse para la implementación durante estos tipos de escenarios. Estas canalizaciones se deben organizar y ejecutar en Data Factory.
Identificación de los recursos de proceso adecuados
Antes de implementar un modelo en Azure Machine Learning en una instancia de AKS, el usuario debe especificar los recursos como CPU, RAM y GPU que se deben asignar para el modelo correspondiente. Definir estos parámetros puede ser un proceso complejo y tedioso. Es necesario realizar pruebas de esfuerzo con distintas configuraciones para identificar un buen conjunto de parámetros. Puede simplificar este proceso con la característica de generación de perfiles de modelos de Azure Machine Learning, que es un trabajo de larga duración que prueba diferentes combinaciones de asignación de recursos y usa una latencia identificada y tiempo de ida y vuelta (RTT) para recomendar una combinación óptima. Esta información puede ayudar a la implementación real del modelo en AKS.
Para actualizar modelos de forma segura en Azure Machine Learning, los equipos deben usar la característica de lanzamiento controlado (versión preliminar) para minimizar el tiempo de inactividad y mantener la coherencia del punto de conexión de REST del modelo.
Procedimientos recomendados y flujo de trabajo para MLOps
Inclusión de código de ejemplo en repositorios de ciencia de datos
Puede simplificar y acelerar los proyectos de ciencia de datos si los equipos tienen determinados artefactos y procedimientos recomendados. Se recomienda crear artefactos que todos los equipos de ciencia de datos puedan usar al trabajar con Azure Machine Learning y las herramientas respectivas del entorno del producto de datos. Los ingenieros de datos y aprendizaje automático deben crear y proporcionar los artefactos.
Estos artefactos deben incluir:
Cuadernos de ejemplo que muestran cómo:
- Cargar, montar y trabajar con productos de datos.
- Registrar métricas y parámetros.
- Enviar trabajos de entrenamiento a clústeres de proceso.
Artefactos necesarios para la operacionalización:
- Canalizaciones de ejemplo de Azure Machine Learning
- Instancias de ejemplo de Azure Pipelines
- Más scripts necesarios para ejecutar canalizaciones
Documentación
Uso de artefactos bien diseñados para operacionalizar canalizaciones
Los artefactos pueden acelerar las fases de exploración y operacionalización de los proyectos de ciencia de datos. Una estrategia de bifurcación de DevOps puede ayudar a escalar estos artefactos en todos los proyectos. Puesto que esta configuración promueve el uso de Git, los usuarios y el proceso de automatización general pueden beneficiarse de los artefactos proporcionados.
Sugerencia
Las canalizaciones de ejemplo de Azure Machine Learning deben crearse con el kit para desarrolladores de software (SDK) de Python o en función del lenguaje YAML. La nueva experiencia de YAML será más a prueba de futuro, ya que el equipo de producto de Azure Machine Learning está trabajando actualmente en un nuevo SDK y una interfaz de línea de comandos (CLI). El equipo del producto de Azure Machine Learning está seguro de que YAML servirá como lenguaje de definición para todos los artefactos en Azure Machine Learning.
Las canalizaciones de ejemplo no funcionarán de forma predefinida para cada proyecto, pero se pueden usar como base de referencia. Puede ajustar las canalizaciones de muestra en función de los proyectos. Una canalización debe incluir los aspectos más relevantes de cada proyecto. Por ejemplo, una canalización puede hacer referencia a un destino de proceso y productos de datos, definir parámetros, entradas y pasos de ejecución. Se debe hacer el mismo proceso para Azure Pipelines. Azure Pipelines también debe usar el SDK de Azure Machine Learning o la CLI.
Las canalizaciones deben mostrar cómo:
- Conectar a un área de trabajo desde una canalización de DevOps.
- Comprobar si el proceso necesario está disponible.
- Enviar un trabajo.
- Registrar e implementar un modelo.
Los artefactos no se adaptan a todos los proyectos todo el tiempo y pueden requerir personalización, pero tener una base puede acelerar la operacionalización e implementación de un proyecto.
Estructuración del repositorio de MLOps
En algunos casos, los usuarios pierden la pista de dónde encontrar y almacenar los artefactos. Para evitar estas situaciones, debe solicitar más tiempo para comunicarse y construir una estructura de carpetas de nivel superior para el repositorio estándar. Todos los proyectos deben seguir la estructura de carpetas.
Nota:
Los conceptos mencionados en esta sección se pueden usar en entornos locales, Amazon Web Services, Palantir y entornos de Azure.
En la imagen siguiente, se ilustra en este diagrama la estructura general de carpetas propuesta para un repositorio de MLOps (operaciones de Machine Learning):
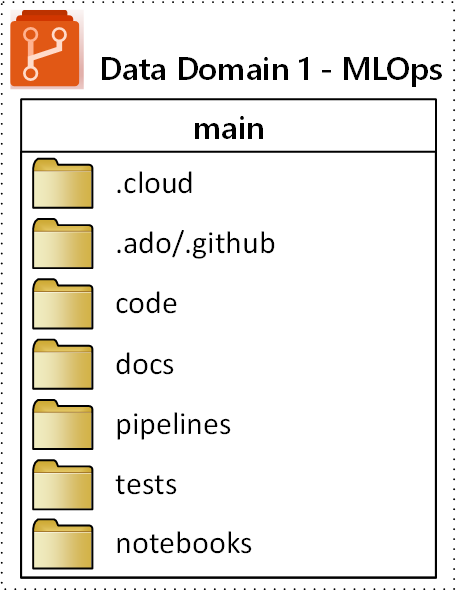
Los siguientes propósitos se aplican a cada carpeta del repositorio:
| Carpeta | Propósito |
|---|---|
.cloud |
Almacene código y artefactos específicos de la nube en esta carpeta. Los artefactos incluyen archivos de configuración para el área de trabajo de Azure Machine Learning, incluidas las definiciones de destino de proceso, los trabajos, los modelos registrados y los puntos de conexión. |
.ado/.github |
Almacene artefactos de Azure DevOps o GitHub, como canalizaciones de YAML o propietarios de código en esta carpeta. |
code |
Esta carpeta debe incluir el código real que se desarrolla como parte del proyecto. Esta carpeta puede contener paquetes de Python y algunos scripts que se usan para los pasos respectivos de la canalización de aprendizaje automático. Se recomienda separar los pasos individuales que deben realizarse en esta carpeta. Los pasos comunes son el preprocesamiento, el entrenamiento del modelo y el registro de modelos. Se deben definir dependencias como las dependencias de Conda, las imágenes de Docker u otras para cada carpeta. |
docs |
Use esta carpeta con fines de documentación. Esta carpeta almacena imágenes y archivos Markdown para describir el proyecto. |
pipelines |
Almacene las definiciones de canalizaciones de Azure Machine Learning en YAML o Python en esta carpeta. |
tests |
Escriba en esta carpeta las pruebas unitarias y de integración que deben ejecutarse para detectar errores e incidencias al principio del proyecto. |
notebooks |
Separe los cuadernos Jupyter Notebook del proyecto Python real con esta carpeta. Dentro de la carpeta, cada individuo debe tener una subcarpeta para comprobar sus cuadernos y evitar conflictos de combinación de Git. |