Tutorial: Configuración de un lote de productos de datos
En este tutorial, aprenderá a configurar servicios de productos de datos que ya están implementados. Use Azure Data Factory para integrar y organizar los datos y use Microsoft Purview para detectar, administrar y controlar los recursos de datos.
Obtenga información sobre cómo:
- Crear e implementar los recursos necesarios
- Asignar roles y permisos de acceso
- Conectar recursos para la integración de datos
Este tutorial le ayuda a familiarizarse con los servicios que se implementan en el grupo de recursos de productos de datos de ejemplo <DMLZ-prefix>-dev-dp001. Experimente cómo interactúan los servicios de Azure entre sí y qué medidas de seguridad están en vigor.
A medida que implemente los nuevos componentes, tendrá la oportunidad de investigar cómo Purview conecta la gobernanza del servicio para crear un mapa holístico y actualizado del panorama de datos. El resultado es la detección automatizada de datos, la clasificación de datos confidenciales y el linaje de datos de principio a fin.
Prerrequisitos
Antes de empezar a configurar el lote de productos de datos, asegúrese de cumplir estos requisitos previos:
Suscripción de Azure. Si no tiene una suscripción de Azure, puede crear una cuenta gratuita de Azure.
Permisos para la suscripción de Azure. Para configurar Purview y Azure Synapse Analytics para la implementación, debe tener el rol Administrador de acceso de usuario o el rol Propietario en la suscripción de Azure. Establecerá más asignaciones de roles para servicios y entidades de servicio en el tutorial.
Recursos implementados. Para completar el tutorial, estos recursos deben estar ya implementados en la suscripción de Azure:
- Zona de aterrizaje de administración de datos. Para obtener más información, consulte el repositorio de GitHub de la zona de aterrizaje de administración de datos.
- Zona de aterrizaje de datos. Para más información, consulte el repositorio de GitHub de la zona de aterrizaje de datos.
- Lote de productos de datos. Para más información, consulte el repositorio de GitHub del lote de productos de datos.
Cuenta de Microsoft Purview. La cuenta se crea como parte de la implementación de la zona de aterrizaje de administración de datos.
Entorno de ejecución de integración autohospedado. El entorno de ejecución se crea como parte de la implementación de la zona de aterrizaje de datos.
Nota
En este tutorial, los marcadores de posición hacen referencia a los recursos de requisitos previos que implementa antes de comenzar el tutorial:
<DMLZ-prefix>hace referencia al prefijo que escribió al crear la implementación de la zona de aterrizaje de administración de datos.<DLZ-prefix>hace referencia al prefijo que escribió al crear la implementación de la zona de aterrizaje de datos.<DP-prefix>hace referencia al prefijo que escribió al crear la implementación del lote de productos de datos.
Creación de instancias de Azure SQL Database
Para comenzar este tutorial, cree dos instancias de SQL Database de ejemplo. Usará las bases de datos para simular orígenes de datos CRM y ERP en secciones posteriores.
En Azure Portal, en los controles globales del portal, seleccione el icono de Cloud Shell para abrir un terminal de Azure Cloud Shell. Seleccione Bash para el tipo de terminal.

En Cloud Shell, ejecute el siguiente script. El script busca el grupo de recursos
<DLZ-prefix>-dev-dp001y el servidor Azure SQL<DP-prefix>-dev-sqlserver001que se encuentra en el grupo de recursos. A continuación, el script crea las dos instancias de SQL Database en el servidor<DP-prefix>-dev-sqlserver001. Las bases de datos se rellenan previamente con datos de ejemplo de AdventureWorks. Los datos incluyen las tablas que se usan en este tutorial.Asegúrese de reemplazar el valor del marcador de posición del parámetro
subscriptionpor su propio id. de suscripción de Azure.# Azure SQL Database instances setup # Create the AdatumCRM and AdatumERP databases to simulate customer and sales data. # Use the ID for the Azure subscription you used to deployed the data product. az account set --subscription "<your-subscription-ID>" # Get the resource group for the data product. resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dp001')==\`true\`].name") # Get the existing Azure SQL Database server name. sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") # Create the first SQL Database instance, AdatumCRM, to create the customer's data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumCRM --service-objective Basic --sample-name AdventureWorksLT # Create the second SQL Database instance, AdatumERP, to create the sales data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumERP --service-objective Basic --sample-name AdventureWorksLT
Cuando el script termina de ejecutarse, en el servidor de Azure SQL <DP-prefix>-dev-sqlserver001, tiene dos nuevas instancias de SQL Database, AdatumCRM y AdatumERP. Ambas bases de datos están en el nivel de proceso Básico. Las bases de datos se encuentran en el mismo grupo de recursos <DLZ-prefix>-dev-dp001 que usó para implementar el lote de productos de datos.
Configuración de Purview para catalogar el lote de productos de datos
A continuación, complete los pasos para configurar Purview para catalogar el lote de productos de datos. Para empezar, cree una entidad de servicio. A continuación, configure los recursos necesarios y asigne roles y permisos de acceso.
Creación de una entidad de servicio
En Azure Portal, en los controles globales del portal, seleccione el icono de Cloud Shell para abrir un terminal de Azure Cloud Shell. Seleccione Bash para el tipo de terminal.
Revise el siguiente script:
- Reemplace el valor del marcador de posición del parámetro
subscriptionIdpor su propio id. de suscripción de Azure. - Reemplace el valor del marcador de posición del parámetro
spnamepor el nombre que quiere usar para la entidad de servicio. El nombre de la entidad de servicio debe ser único en la suscripción.
Después de actualizar los valores de parámetro, ejecute el script en Cloud Shell.
# Replace the parameter values with the name you want to use for your service principal name and your Azure subscription ID. spname="<your-service-principal-name>" subscriptionId="<your-subscription-id>" # Set the scope to the subscription. scope="/subscriptions/$subscriptionId" # Create the service principal. az ad sp create-for-rbac \ --name $spname \ --role "Contributor" \ --scope $scope- Reemplace el valor del marcador de posición del parámetro
Consulte la salida JSON de un resultado similar al ejemplo siguiente. Anote o copie los valores de la salida para usarlos en pasos posteriores.
{ "appId": "<your-app-id>", "displayName": "<service-principal-display-name>", "name": "<your-service-principal-name>", "password": "<your-service-principal-password>", "tenant": "<your-tenant>" }
Configuración del acceso y los permisos de la entidad de servicio
En la salida JSON generada en el paso anterior, busque los siguientes valores devueltos:
- Id. de entidad de servicio (
appId) - Clave de entidad de servicio (
password)
La entidad de servicio debe tener los siguientes permisos:
- Rol Lector de datos de Storage Blob en las cuentas de almacenamiento.
- Permisos de lector de datos en las instancias de SQL Database.
Para configurar la entidad de servicio con el rol y los permisos necesarios, complete los pasos siguientes.
Permisos de la cuenta de Azure Storage
En Azure Portal, vaya a la cuenta de Azure Storage
<DLZ-prefix>devraw. En el menú del recurso, seleccione Control de acceso (IAM).
Seleccione Agregar>Agregar asignación de roles.
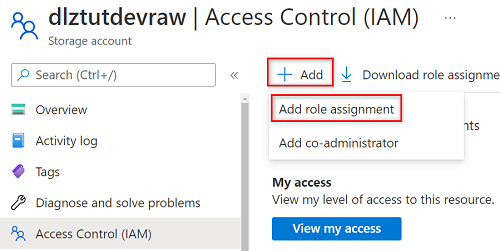
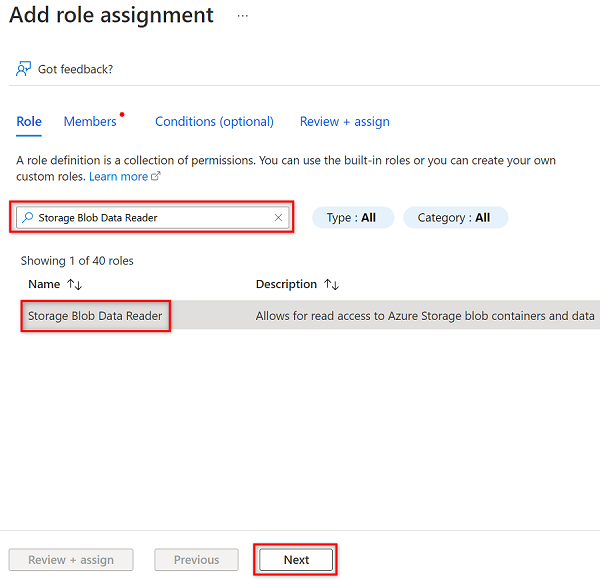
En Agregar asignación de roles, en la pestaña Rol, busque y seleccione Lector de datos de Storage Blob. Después, seleccione Siguiente.
En Miembros, elija Seleccionar miembros.
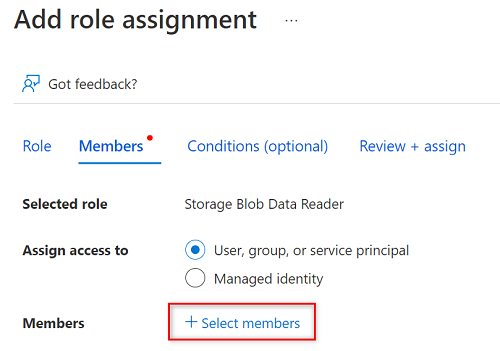
En Seleccionar miembros, busque el nombre de la entidad de servicio que creó.

En los resultados de la búsqueda, seleccione la entidad de servicio y, a continuación, elija Seleccionar.
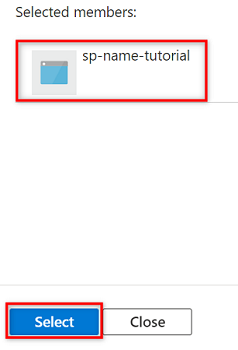
Para completar la asignación de roles, seleccione Revisar y asignar dos veces.
Repita los pasos de esta sección para las cuentas de almacenamiento restantes:
<DLZ-prefix>devencur<DLZ-prefix>devwork
Permisos de SQL Database
Para establecer permisos de SQL Database, conéctese a la máquina virtual de Azure SQL mediante el editor de consultas. Dado que todos los recursos están detrás de un punto de conexión privado, primero debe iniciar sesión en Azure Portal mediante una máquina virtual de host Azure Bastion.
En Azure Portal, conéctese a la máquina virtual implementada en el grupo de recursos <DMLZ-prefix>-dev-bastion. Si no está seguro de cómo conectarse a la máquina virtual mediante el servicio de host Bastion, consulte Conexión a una máquina virtual.
Para agregar la entidad de servicio como usuario en la base de datos, es posible que primero tenga que agregarse como administrador de Microsoft Entra. En los pasos 1 y 2, se agrega como administrador de Microsoft Entra. En los pasos 3 a 5, se conceden permisos a la entidad de servicio a una base de datos. Cuando haya iniciado sesión en el portal desde la máquina virtual de host Bastion, busque máquinas virtuales de Azure SQL en Azure Portal.
Vaya a la máquina virtual
<DP-prefix>-dev-sqlserver001de Azure SQL. En el menú del recurso, en Configuración, seleccione Microsoft Entra ID.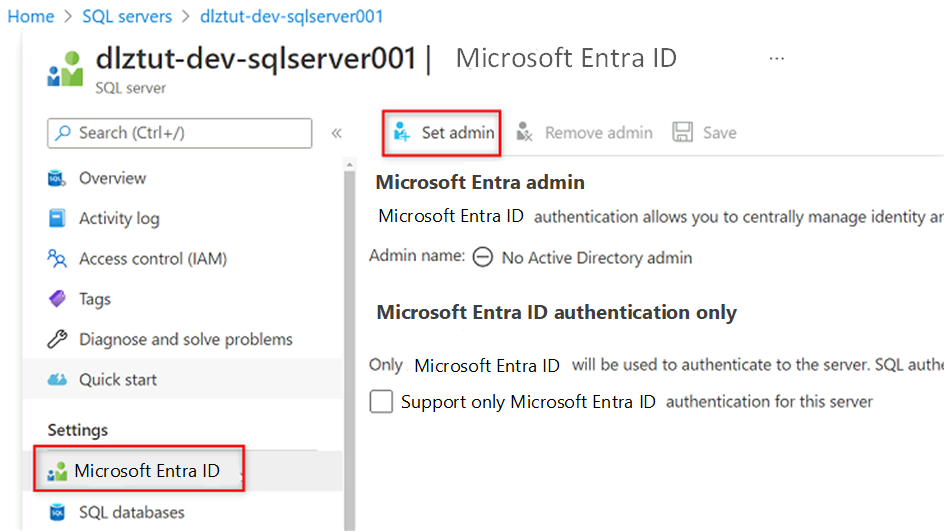
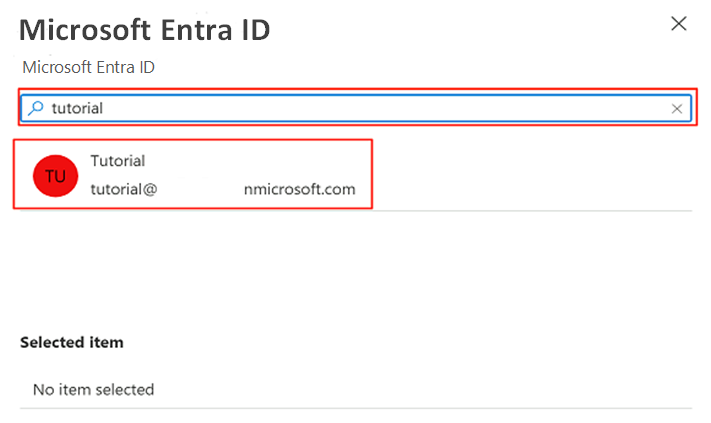
En la barra de comandos, seleccione Establecer administrador. Busque y seleccione su propia cuenta. Elija Seleccionar.
En el menú del recurso, seleccione Bases de datos SQL y, después, seleccione la base de datos
AdatumCRM.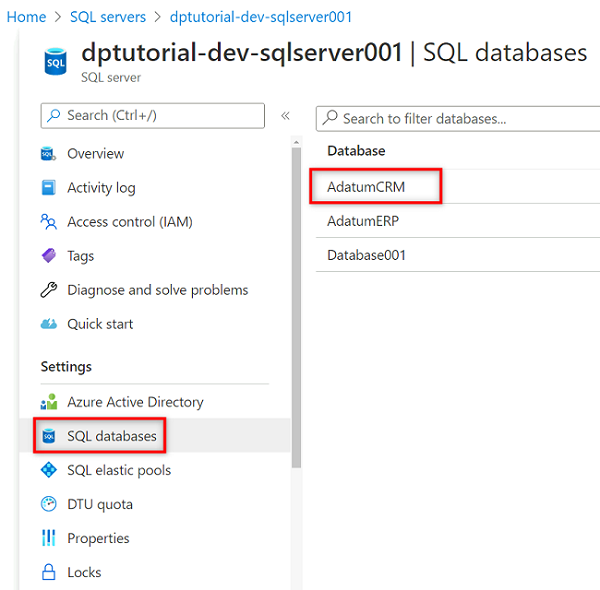
En el menú del recurso AdatumCRM, seleccione Editor de consultas (versión preliminar). En Autenticación de Active Directory, seleccione el botón Continuar como para iniciar sesión.
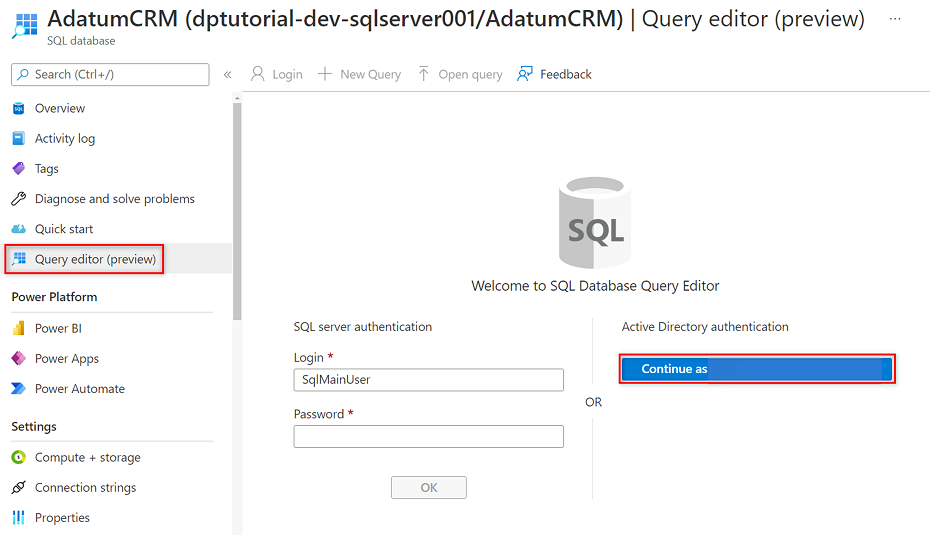
En el editor de consultas, revise las siguientes instrucciones para reemplazar
<service principal name>por el nombre de la entidad de servicio que ha creado (por ejemplo,purview-service-principal). A continuación, ejecute las instrucciones.CREATE USER [<service principal name>] FROM EXTERNAL PROVIDER GO EXEC sp_addrolemember 'db_datareader', [<service principal name>] GO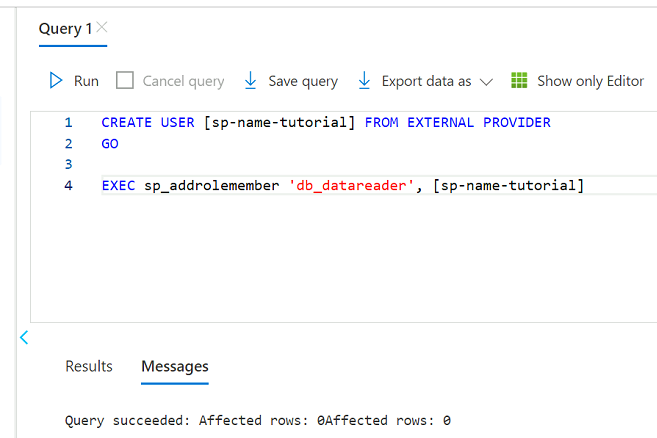
Repita los pasos 3 a 5 para la base de datos AdatumERP.
Configuración del almacén de claves
Purview lee la clave de entidad de servicio de una instancia de Azure Key Vault. El almacén de claves se crea en la implementación de la zona de aterrizaje de administración de datos. Los pasos siguientes son necesarios para configurar el almacén de claves:
Adición de la clave de entidad de servicio como un secreto en el almacén de claves.
Concesión de permisos de lector de secretos MSI de Purview en el almacén de claves.
Adición del almacén de claves a Purview como una conexión de almacén de claves.
Creación de una credencial en Purview que apunte al secreto del almacén de claves.
Adición de permisos para agregar un secreto al almacén de claves
En Azure Portal, vaya al servicio Azure Key Vault. Busque el almacén de claves
<DMLZ-prefix>-dev-vault001.
En el menú del recurso, seleccione Control de acceso (IAM). En la barra de comandos, seleccione Agregar y, luego, Agregar asignación de roles.
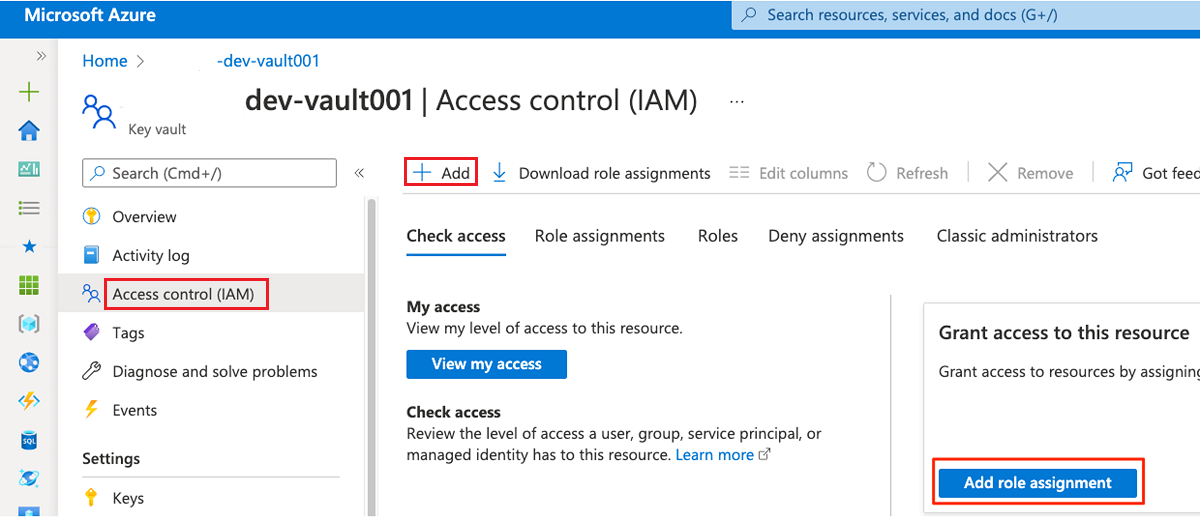
En la pestaña Rol, busque y seleccione Administrador de almacén de claves. Seleccione Siguiente.
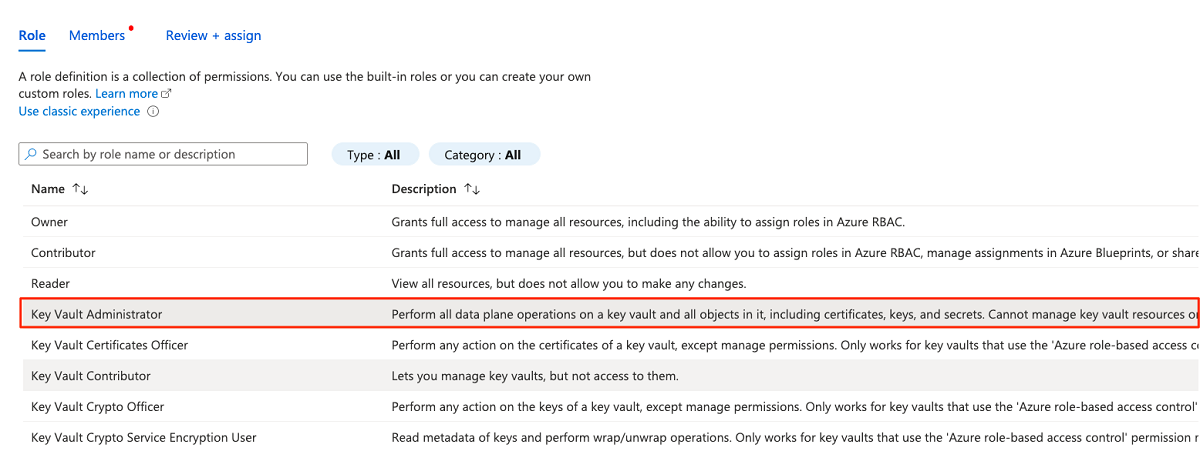
En Miembros, elija Seleccionar miembros para agregar la cuenta que ha iniciado sesión actualmente.
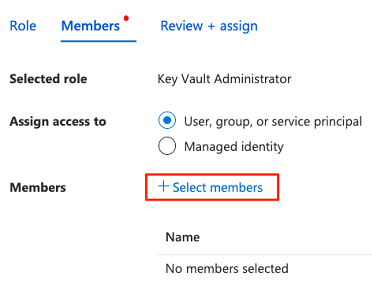
En Seleccionar miembros, busque la cuenta que ha iniciado sesión actualmente. Seleccione la cuenta y, a continuación, elija Seleccionar.
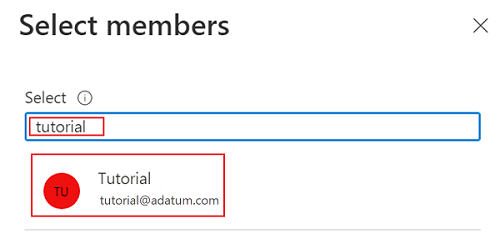
Para completar el proceso de asignación de roles, seleccione Revisar y asignar dos veces.
Incorporación de un secreto al almacén de claves
Complete los pasos siguientes para iniciar sesión en Azure Portal desde la máquina virtual de host Bastion.
En el menú del recurso de almacén de claves
<DMLZ-prefix>-dev-vault001, seleccione Secretos. En la barra de comandos, seleccione Generar o importar para crear un nuevo secreto.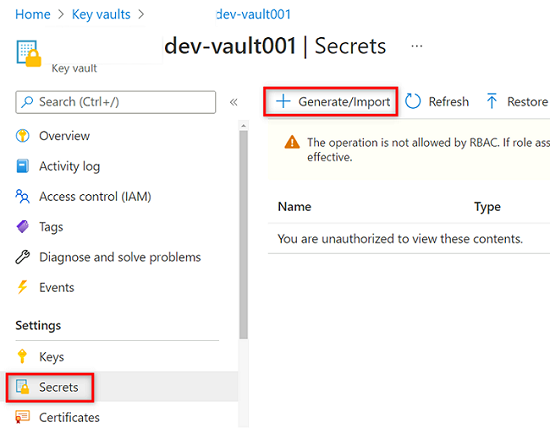
En Crear un secreto, seleccione o escriba los valores siguientes:
Configuración Acción Opciones de carga Seleccione Manual. Nombre Escriba el secreto de la entidad de servicio. Valor Escriba la contraseña de la entidad de servicio que ha creado antes. 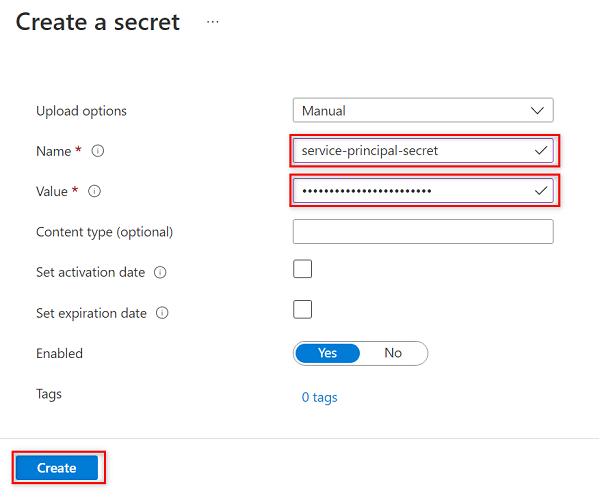
Nota:
En este paso se crea un secreto denominado
service-principal-secreten el almacén de claves mediante la clave de contraseña de la entidad de servicio. Purview usa el secreto para conectarse a los orígenes de datos y examinarlos. Si escribe una contraseña incorrecta, no podrá completar las secciones siguientes.Seleccione Crear.
Configuración de permisos de Purview en el almacén de claves
Para que la instancia de Purview lea los secretos almacenados en el almacén de claves, debe asignar a Purview los permisos pertinentes en el almacén de claves. Para establecer los permisos, agregue la identidad administrada de Purview al rol Lector de secretos del almacén de claves.
En el menú del recurso del almacén de claves
<DMLZ-prefix>-dev-vault001, seleccione Control de acceso (IAM).En la barra de comandos, seleccione Agregar y, luego, Agregar asignación de roles.
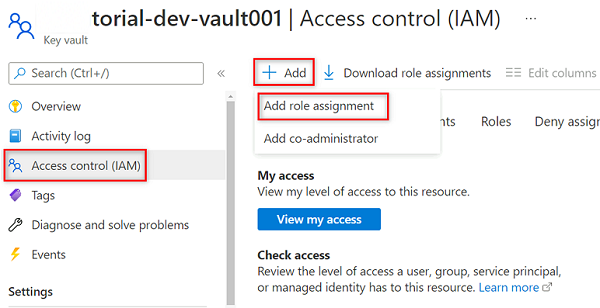
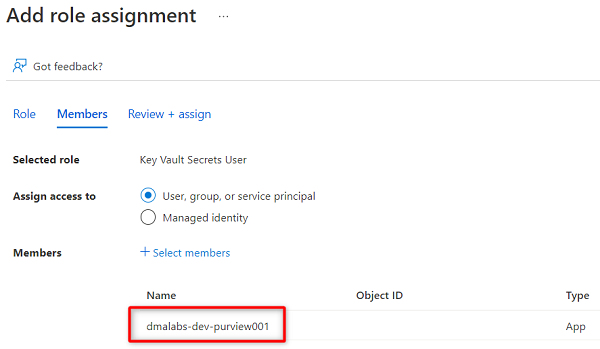
En Rol, busque y seleccione Usuario de secretos de almacén de claves. Seleccione Siguiente.
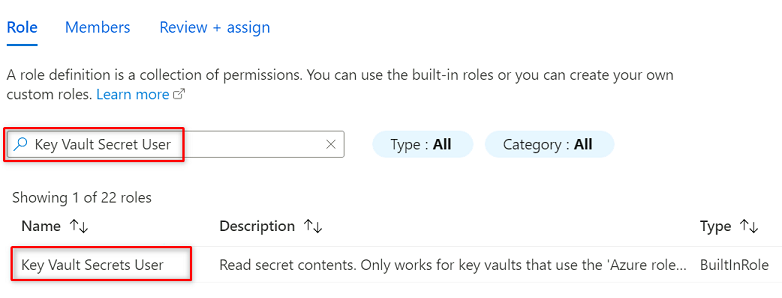
En Miembros, elija Seleccionar miembros.
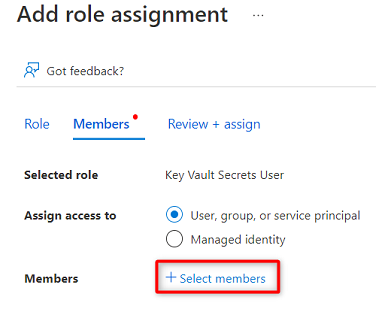
Busque la instancia de Purview
<DMLZ-prefix>-dev-purview001. Seleccione la instancia para agregar la cuenta pertinente. A continuación, elija Seleccionar.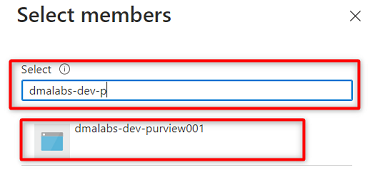
Para completar el proceso de asignación de roles, seleccione Revisar y asignar dos veces.
Configuración de una conexión del almacén de claves en Purview
Para configurar una conexión del almacén de claves a Purview, debe iniciar sesión en Azure Portal mediante una máquina virtual de host Azure Bastion.
En Azure Portal, vaya a la cuenta de Purview
<DMLZ-prefix>-dev-purview001. En Introducción, en Abrir portal de gobernanza de Microsoft Purview, seleccione Abrir.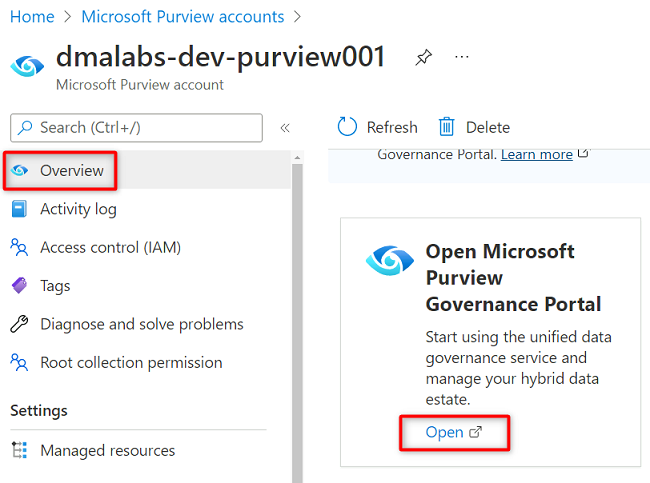
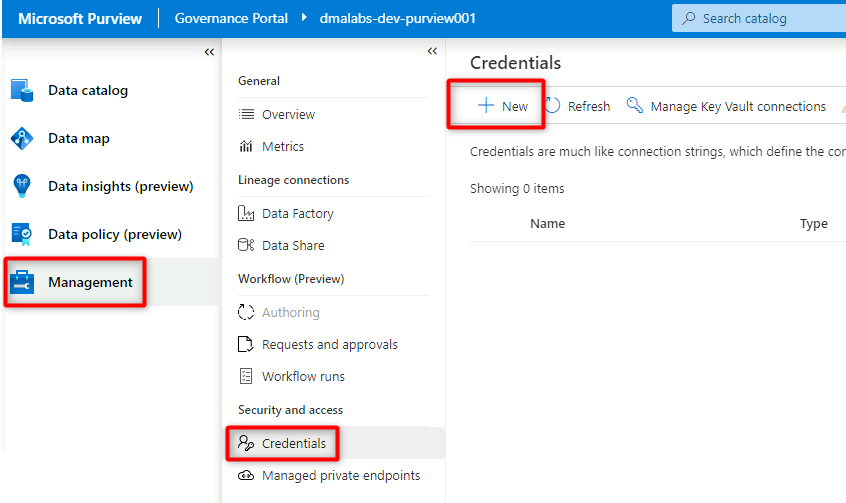
En Purview Studio, seleccione Administración>Credenciales. En la barra de comandos Credenciales, seleccione Administrar conexiones de Key Vault y, a continuación, seleccione Nueva.
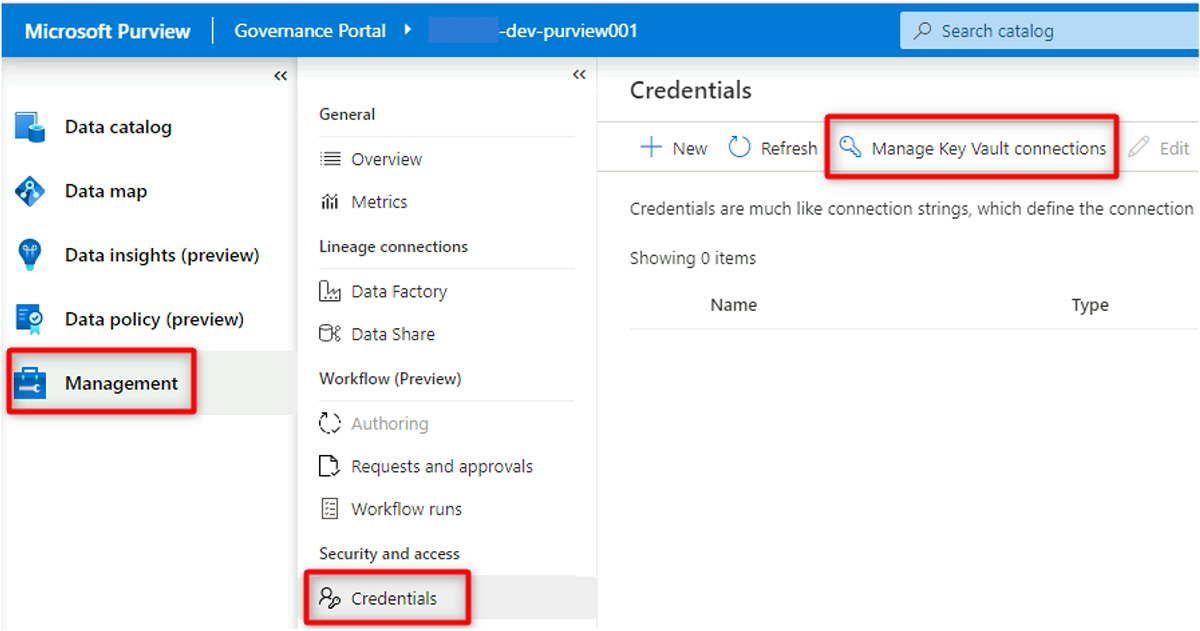
En Nueva conexión de almacén de claves, seleccione o escriba la siguiente información:
Configuración Acción Nombre Escriba <DMLZ-prefix>-dev-vault001. Suscripción de Azure Seleccione la suscripción que hospeda el almacén de claves. Nombre de almacén de claves Seleccione el almacén de claves <DMLZ-prefix>-dev-vault001. 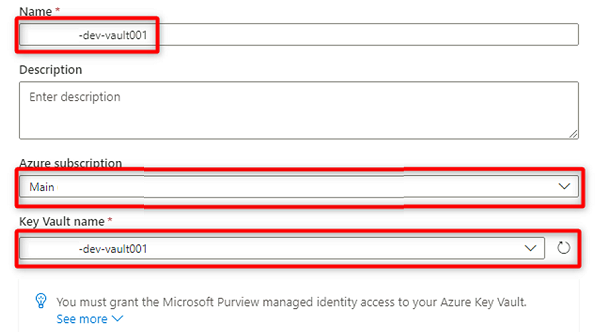
Seleccione Crear.
En Confirmar concesión de acceso, seleccione Confirmar.
Creación de una credencial en Purview
El último paso para configurar el almacén de claves es crear una credencial en Purview que apunte al secreto que creó en el almacén de claves para la entidad de servicio.
En Purview Studio, seleccione Administración>Credenciales. En la barra de comandos Credenciales, seleccione Nueva.
En Nueva credencial, seleccione o escriba la siguiente información:
Configuración Acción Nombre Escriba purviewServicePrincipal. Método de autenticación Seleccione Entidad de servicio. Id. de inquilino El valor se rellena automáticamente. Id. de entidad de servicio Escriba el id. de aplicación o el id. de cliente de la entidad de servicio. Conexión de Key Vault Seleccione la conexión de almacén de claves que ha creado en la sección anterior. Nombre del secreto Escriba el nombre del secreto en el almacén de claves (service-principal-secret). 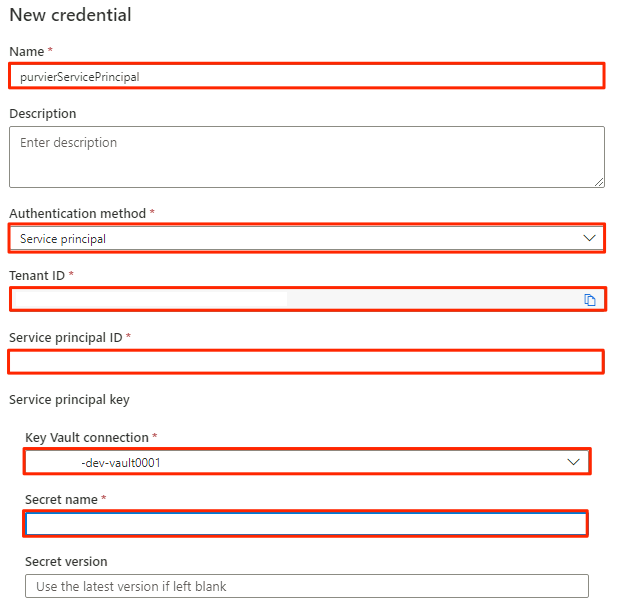
Seleccione Crear.
Registrar orígenes de datos
En este momento, Purview puede conectarse a la entidad de servicio. Ahora puede registrar y configurar los orígenes de datos.
Registro cuentas de Azure Data Lake Storage Gen2
En los pasos siguientes se describe el proceso para registrar una cuenta de almacenamiento de Azure Data Lake Storage Gen2.
En Purview Studio, seleccione el icono de mapa de datos, seleccione Orígenes y, a continuación, seleccione Registrar.
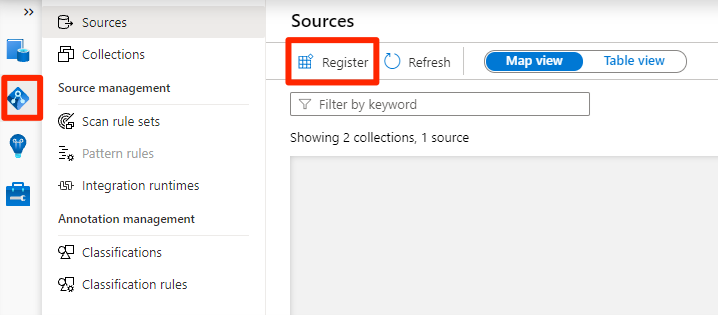
En Registrar orígenes, seleccione Azure Data Lake Storage Gen2 y, luego, Continuar.

En Registrar orígenes (Azure Data Lake Storage Gen2), seleccione o escriba la siguiente información:
Configuración Acción Nombre Escriba <DLZ-prefix>dldevraw. Suscripción de Azure Seleccione la suscripción que hospeda la cuenta de almacenamiento. Nombre de cuenta de almacenamiento Seleccione la cuenta de almacenamiento pertinente. Punto de conexión Este valor se rellena automáticamente según la selección de cuenta de almacenamiento. Selección de una colección Seleccione la recopilación raíz. 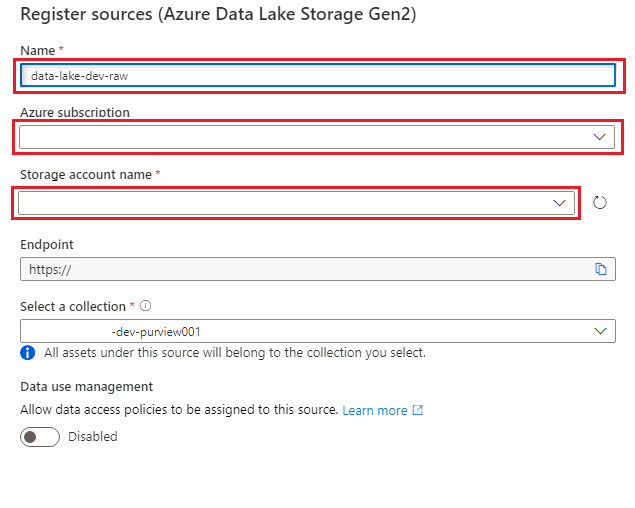
Seleccione Registrar para crear el origen de datos.
Repita estos pasos para las siguientes cuentas de almacenamiento:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Registro de la instancia de SQL Database como origen de datos
En Purview Studio, seleccione el icono de Mapa de datos, seleccione Orígenes y, a continuación, seleccione Registrar.
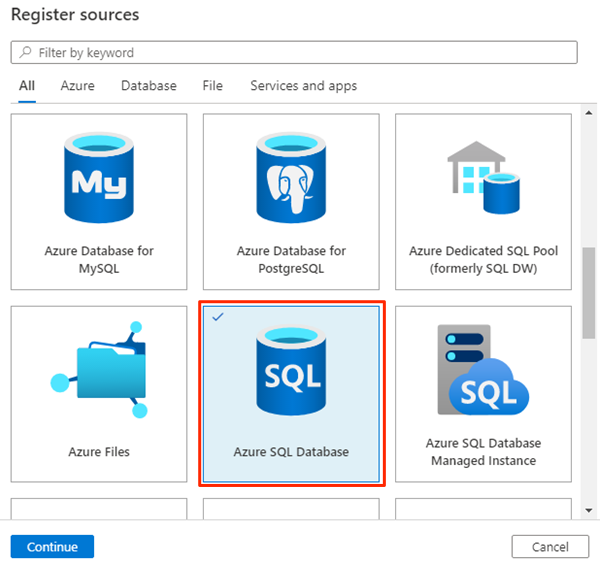
En Registrar orígenes, seleccione Azure SQL Database y luego Continuar.
En Registrar orígenes (Azure SQL Database), seleccione o escriba la siguiente información:
Configuración Acción Nombre Escriba SQLDatabase (el nombre de la base de datos creada en Creación de instancias de Azure SQL Database). Suscripción Seleccione la suscripción que hospeda la base de datos. Nombre del servidor Escriba <DP-prefix>-dev-sqlserver001. 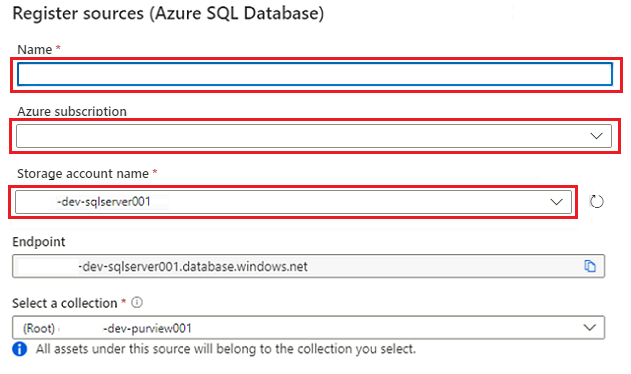
Seleccione Registrar.
Configuración de exámenes
A continuación, configure exámenes para los orígenes de datos.
Examen del origen de datos de Azure Data Lake Storage Gen2
En Purview Studio, vaya al mapa de datos. En el origen de datos, seleccione el icono Nuevo examen.
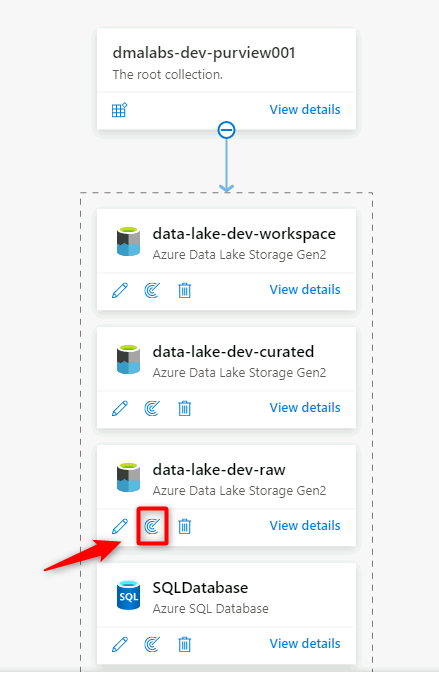
En el nuevo panel de examen, seleccione o escriba la siguiente información:
Configuración Acción Nombre Escriba Scan_<DLZ-prefix>devraw. Conectar mediante entorno de ejecución de integración Seleccione el entorno de ejecución de integración autohospedado que se implementó con la zona de aterrizaje de datos. Credential: Seleccione la entidad de servicio que configuró para Purview. 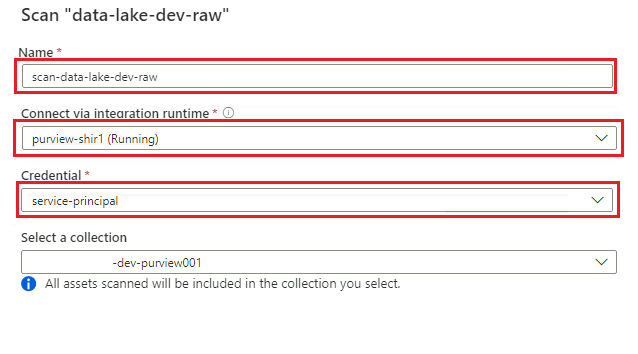
Seleccione Probar conexión para comprobar la conectividad y que los permisos están en vigor. Seleccione Continuar.
En Ámbito del examen, seleccione toda la cuenta de almacenamiento como ámbito del examen y, a continuación, seleccione Continuar.
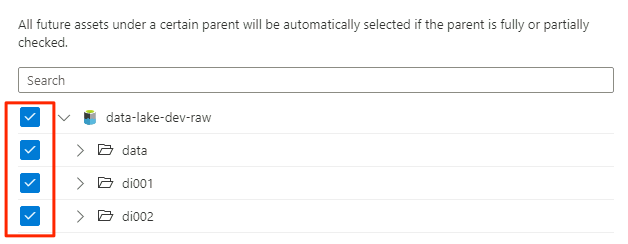
En Seleccionar un conjunto de reglas de examen, seleccione AdlsGen2 y seleccione Continuar.
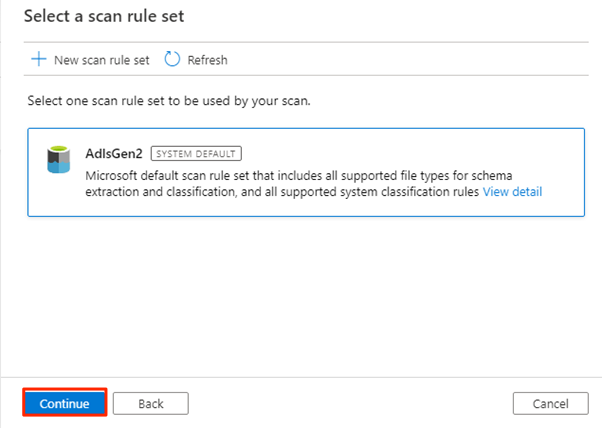
En Establecer un desencadenador de examen, seleccione Una vez y, a continuación, Continuar.
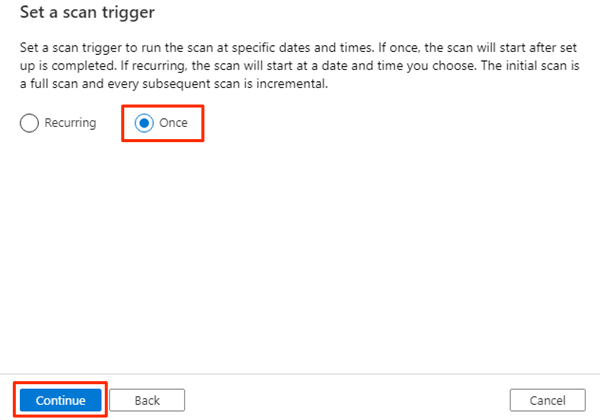
En Revisar el examen, revise la configuración del examen. Seleccione Guardar y ejecutar para iniciar el examen.
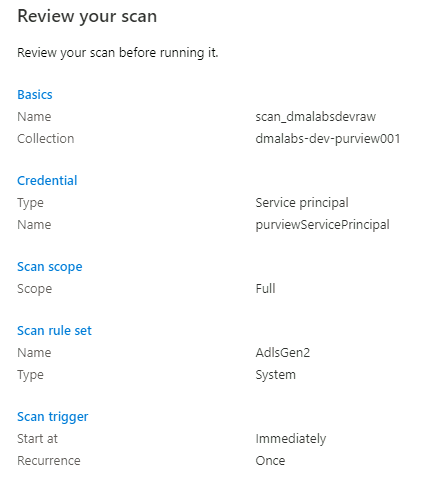
Repita estos pasos para las siguientes cuentas de almacenamiento:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Examine el origen de datos de Azure SQL Database
En el origen de datos de Azure SQL Database, seleccione Nuevo examen.
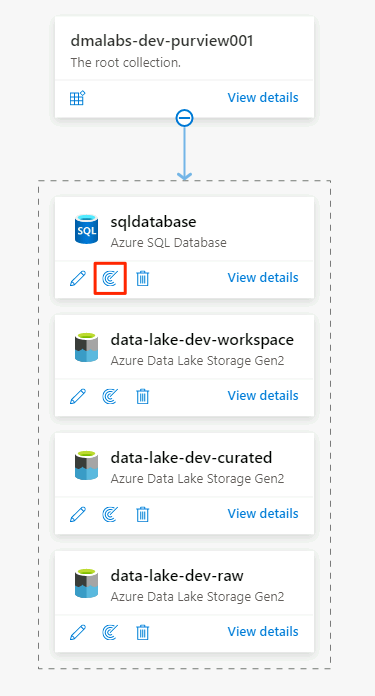
En el nuevo panel de examen, seleccione o escriba la siguiente información:
Configuración Acción Nombre Escriba Scan_Database001. Conectar mediante entorno de ejecución de integración Seleccione Purview-SHIR. Nombre de la base de datos Seleccione el nombre de la base de datos. Credential: Seleccione la credencial del almacén de claves que creó en Purview. Extracción del linaje (vista previa) seleccione Desactivado. 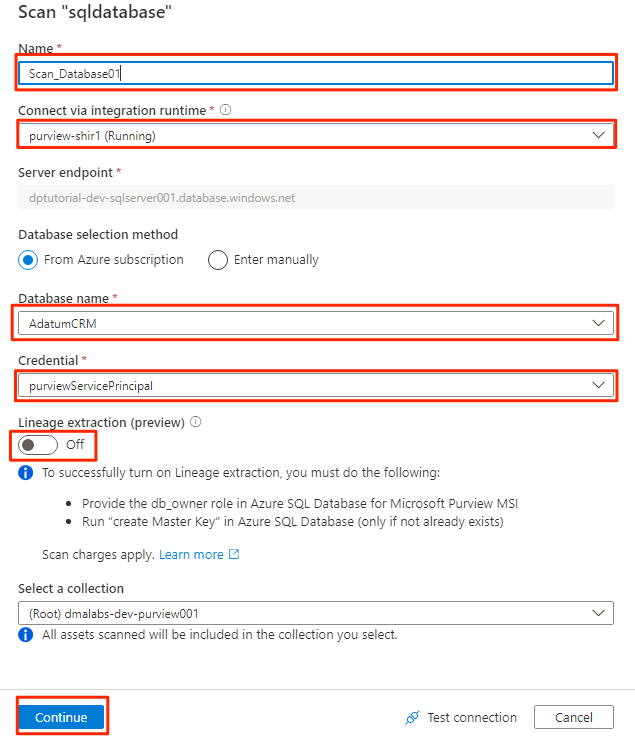
Seleccione Probar conexión para comprobar la conectividad y que los permisos están en vigor. Seleccione Continuar.
Seleccione el ámbito del examen. Para examinar toda la base de datos, use el valor predeterminado.
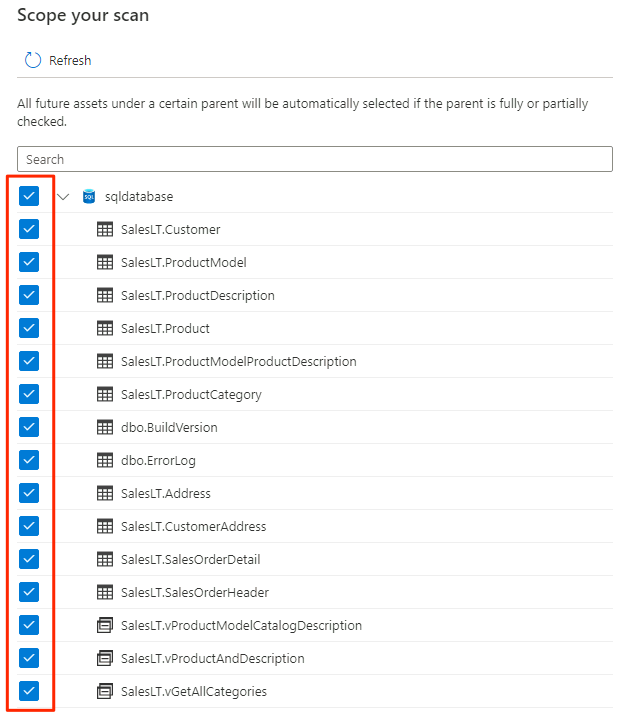
En Seleccionar un conjunto de reglas de examen, seleccione AzureSqlDatabase y seleccione Continuar.
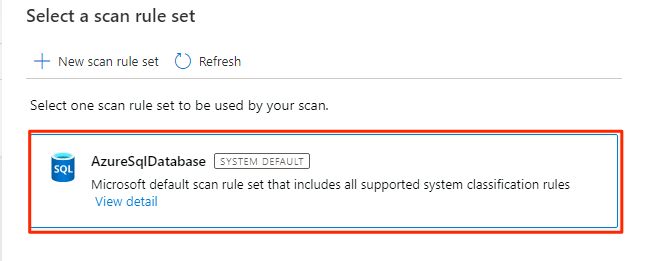
En Establecer un desencadenador de examen, seleccione Una vez y, a continuación, Continuar.
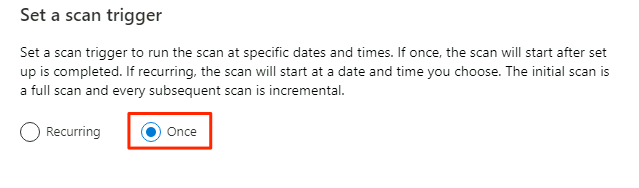
En Revisar el examen, revise la configuración del examen. Seleccione Guardar y ejecutar para iniciar el examen.
Repita estos pasos para la base de datos AdatumERP.
Purview ahora está configurado para la gobernanza de datos para los orígenes de datos registrados.
Copia de datos de SQL Database en Data Lake Storage Gen2
En los pasos siguientes, usará la herramienta Copiar datos en Data Factory para crear una canalización para copiar las tablas de las instancias AdatumCRM y AdatumERP de SQL Database en los archivos CSV en la cuenta <DLZ-prefix>devraw de Data Lake Storage Gen2.
El entorno está bloqueado para el acceso público, por lo que primero debe configurar puntos de conexión privados. Para usar los puntos de conexión privados, iniciará sesión en Azure Portal en el explorador local y, a continuación, se conectará a la máquina virtual de host Bastion para acceder a los servicios de Azure necesarios.
Creación de puntos de conexión privados
Para configurar puntos de conexión privados para los recursos necesarios:
En el grupo de recursos
<DMLZ-prefix>-dev-bastion, seleccione<DMLZ-prefix>-dev-vm001.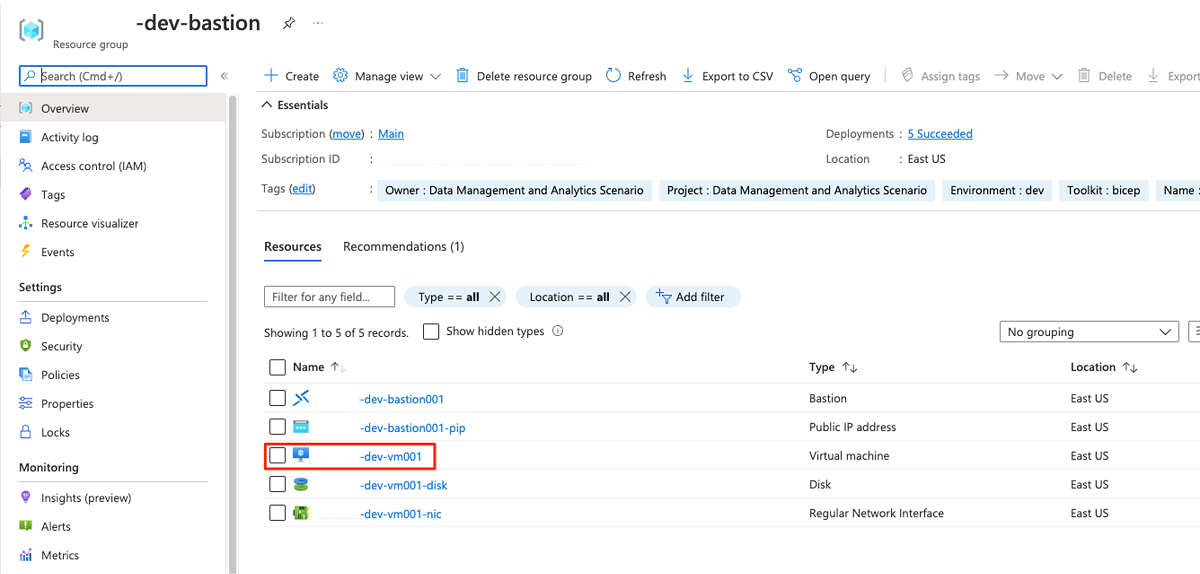
En la barra de comandos, seleccione Conectar y, a continuación, Bastion.
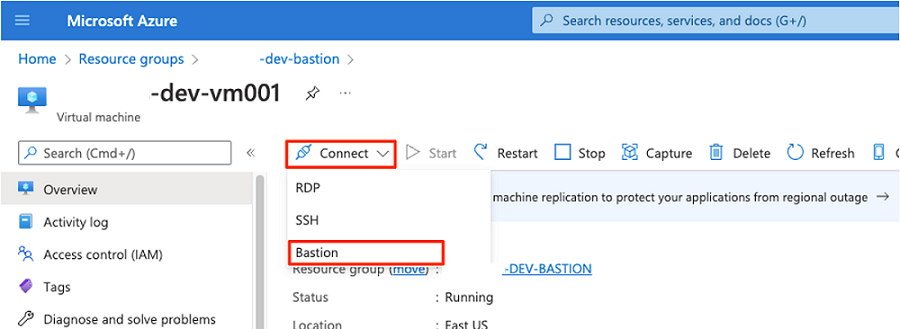
Escriba el nombre de usuario y la contraseña de la máquina virtual y, a continuación, seleccione Conectar.
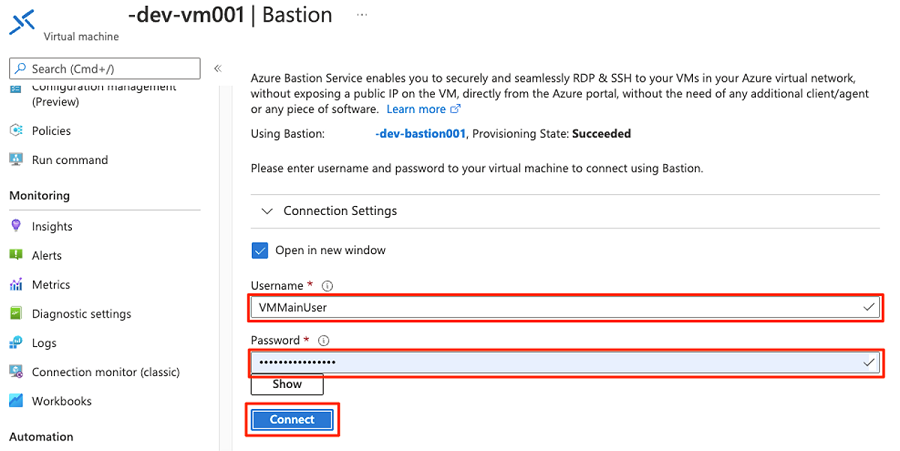
En el explorador web de la máquina virtual, vaya a Azure Portal. Vaya al grupo de recursos
<DLZ-prefix>-dev-shared-integrationy abra la factoría de datos<DLZ-prefix>-dev-integration-datafactory001.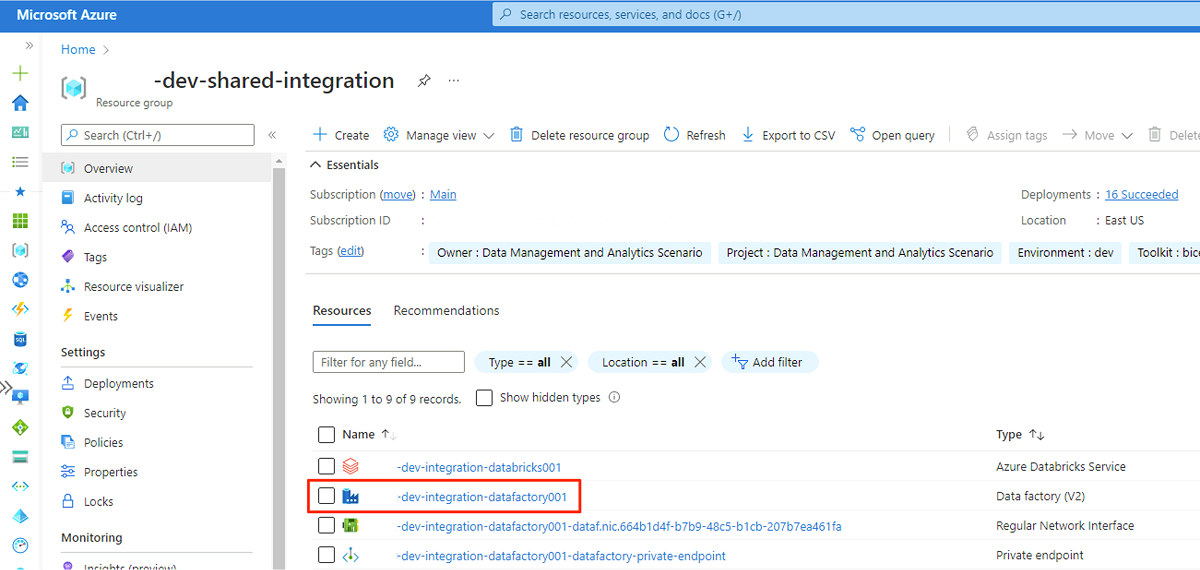
En Introducción, en Abrir Azure Data Factory Studio, seleccione Abrir.
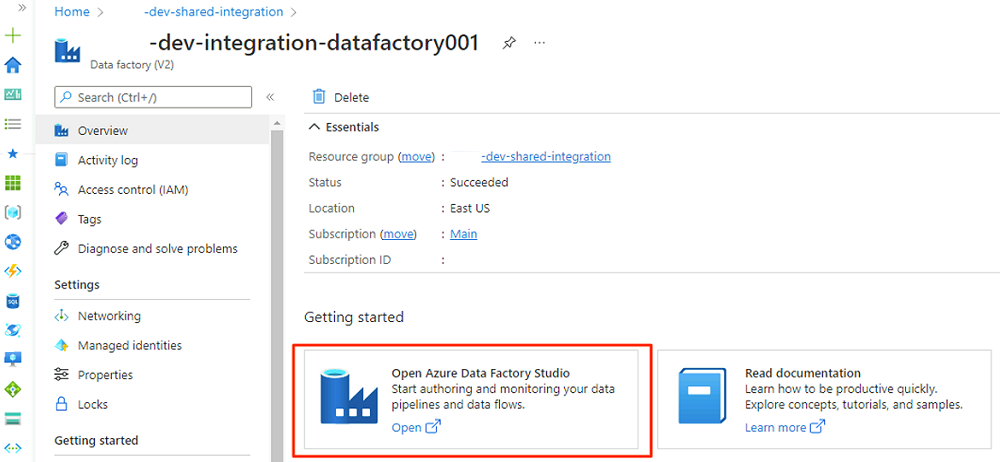
En el menú Data Factory Studio, seleccione el icono Administrar (se parece a una caja de herramientas cuadrada con una llave sobre ella). En el menú del recurso, seleccione Puntos de conexión privados administrados para crear los puntos de conexión privados necesarios para conectar Data Factory a otros servicios protegidos de Azure.
La aprobación de solicitudes de acceso para los puntos de conexión privados se describe en una sección posterior. Después de aprobar las solicitudes de acceso al punto de conexión privado, su estado de aprobación es Aprobado, como en el ejemplo siguiente de la cuenta de almacenamiento
<DLZ-prefix>devencur.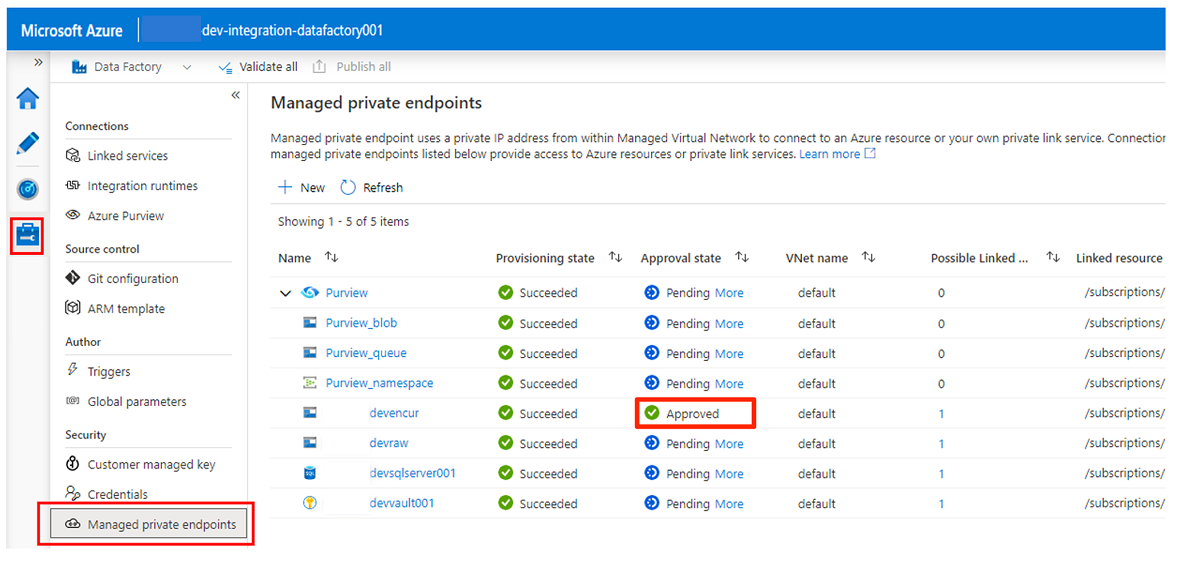
Antes de aprobar las conexiones de punto de conexión privado, seleccione Nueva. Escriba Azure SQL para buscar el conector de Azure SQL Database que usa para crear un nuevo punto de conexión privado administrado para la máquina virtual
<DP-prefix>-dev-sqlserver001de Azure SQL. La máquina virtual contiene las bases de datosAdatumCRMyAdatumERPque creó anteriormente.En Nuevo punto de conexión privado administrado (Azure SQL Database), en Nombre, escriba data-product-dev-sqlserver001. Escriba la suscripción de Azure que usó para crear los recursos. En Nombre del servidor, seleccione
<DP-prefix>-dev-sqlserver001para que pueda conectarse a ella desde esta factoría de datos en las secciones siguientes.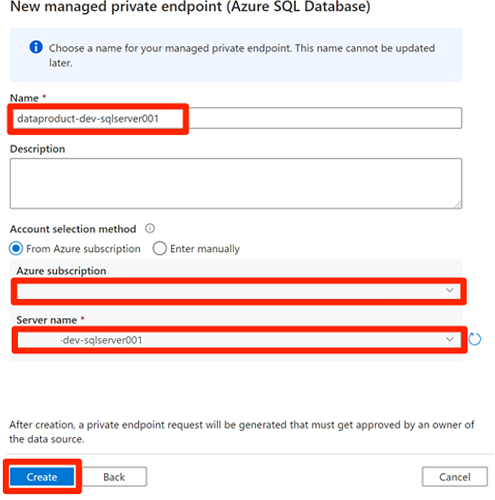



Aprobación de solicitudes de acceso de punto de conexión privado
Para conceder a Data Factory acceso a los puntos de conexión privados de los servicios necesarios, tiene un par de opciones:
Opción 1: en cada servicio al que solicite acceso, en Azure Portal, vaya a la opción de conexiones de red o de punto de conexión privado del servicio y apruebe las solicitudes de acceso al punto de conexión privado.
Opción 2: ejecute los siguientes scripts en Azure Cloud Shell en modo Bash para aprobar a la vez todas las solicitudes de acceso a los puntos de conexión privados necesarios.
# Storage managed private endpoint approval # devencur resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devencur')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # devraw resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devraw')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # SQL Database managed private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-dp001')==\`true\`].name") sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $sqlServerName --type Microsoft.Sql/servers -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $sqlServerName --type Microsoft.Sql/servers --description "Approved" # Key Vault private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-metadata')==\`true\`].name") keyVaultName=$(az keyvault list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'dev-vault001')==\`true\`].name") endPointConnectionID=$(az network private-endpoint-connection list -g $resourceGroupName -n $keyVaultName --type Microsoft.Keyvault/vaults -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].id") az network private-endpoint-connection approve -g $resourceGroupName --id $endPointConnectionID --resource-name $keyVaultName --type Microsoft.Keyvault/vaults --description "Approved" # Purview private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dev-governance')==\`true\`].name") purviewAcctName=$(az purview account list -g $resourceGroupName -o tsv --query "[?contains(@.name, '-dev-purview001')==\`true\`].name") for epn in $(az network private-endpoint-connection list -g $resourceGroupName -n $purviewAcctName --type Microsoft.Purview/accounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") do az network private-endpoint-connection approve -g $resourceGroupName -n $epn --resource-name $purviewAcctName --type Microsoft.Purview/accounts --description "Approved" done
En el ejemplo siguiente se muestra cómo la cuenta de almacenamiento <DLZ-prefix>devraw administra las solicitudes de acceso de punto de conexión privado. En el menú de recursos de la cuenta de almacenamiento, seleccione Redes. En la barra de comandos, seleccione Conexiones de punto de conexión privado.

Para algunos recursos de Azure, seleccione Conexiones de punto de conexión privado en el menú de recursos. En la captura de pantalla siguiente se muestra un ejemplo del servidor de Azure SQL.
Para aprobar una solicitud de acceso de punto de conexión privado, en Conexiones de punto de conexión privado, seleccione la solicitud de acceso pendiente y, a continuación, seleccione Aprobar:

Después de aprobar la solicitud de acceso en cada servicio necesario, la solicitud puede tardar unos minutos en mostrarse como Aprobada en Puntos de conexión privados administrados en Data Factory Studio. Incluso si selecciona Actualizar en la barra de comandos, el estado de aprobación puede ser obsoleto durante unos minutos.
Cuando haya terminado de aprobar todas las solicitudes de acceso para los servicios necesarios, en Puntos de conexión privados administrados, el valor Estado de aprobación para todos los servicios es Aprobado:
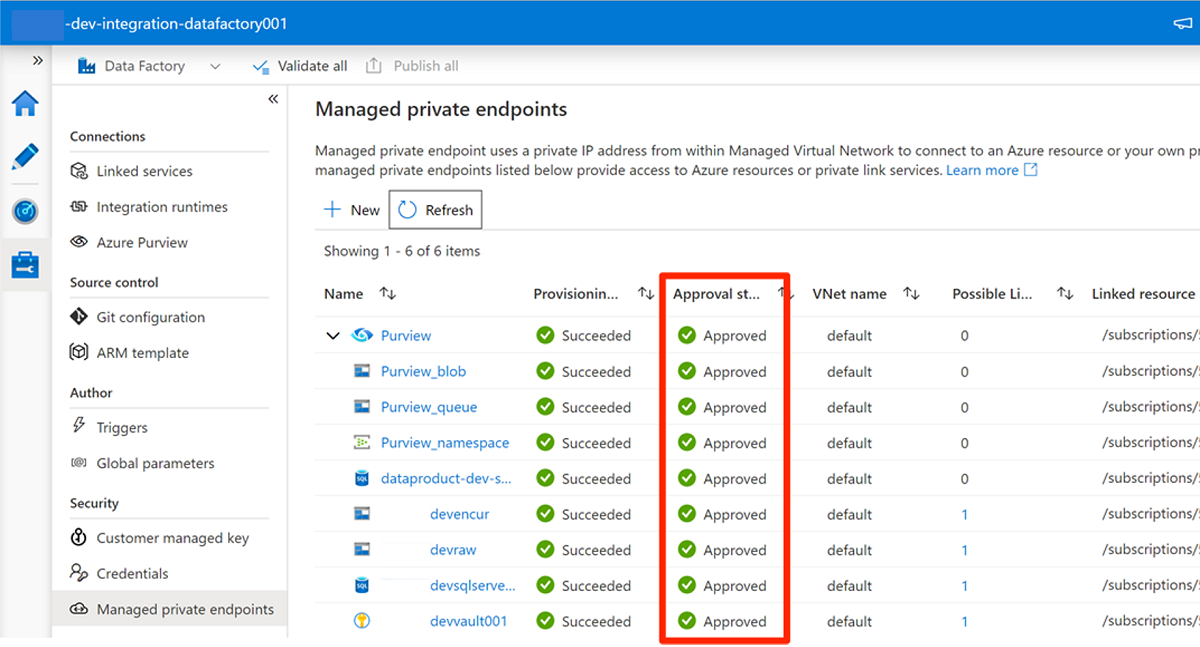
Asignaciones de roles
Cuando termine de aprobar solicitudes de acceso a punto de conexión privado, agregue los permisos de rol adecuados para que Data Factory acceda a estos recursos:
- Las instancias de SQL Database
AdatumCRMyAdatumERPen el servidor de Azure SQL<DP-prefix>-dev-sqlserver001 - Las cuentas de almacenamiento
<DLZ-prefix>devraw,<DLZ-prefix>devencury<DLZ-prefix>devwork - La cuenta de Purview
<DMLZ-prefix>-dev-purview001
Máquina virtual de Azure SQL
Para agregar asignaciones de roles, comience con la máquina virtual de Azure SQL. En el grupo de recursos
<DMLZ-prefix>-dev-dp001, vaya a<DP-prefix>-dev-sqlserver001.En el menú del recurso, seleccione Control de acceso (IAM). En la barra de comandos, seleccione Agregar>Agregar asignación de roles.
En la pestaña Rol, seleccione Colaborador y, a continuación, Siguiente.
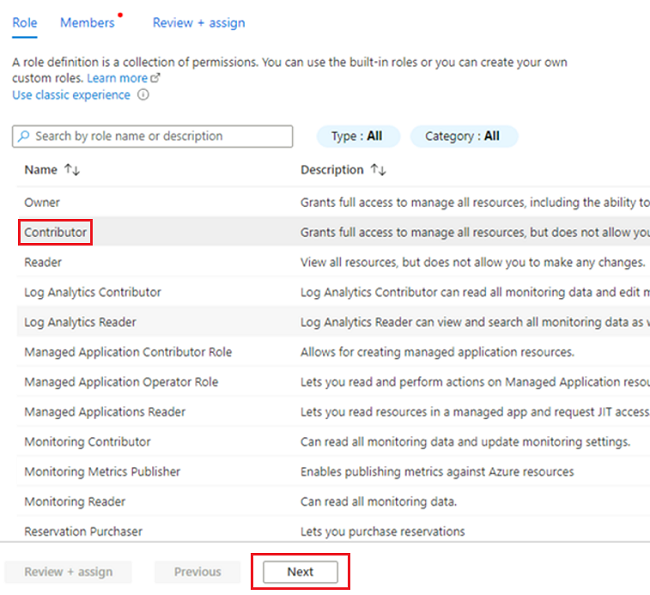
En Miembros, para Asignar acceso a, seleccione Identidad administrada. En Miembros, elija Seleccionar miembros.
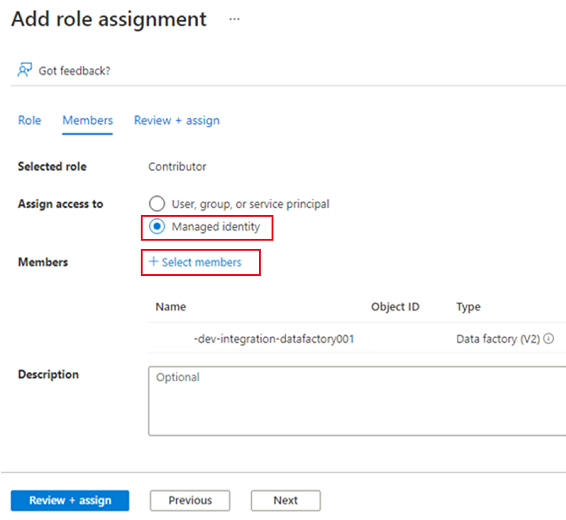
En Seleccionar identidades administradas, seleccione la suscripción de Azure. En Identidad administrada, seleccione Data Factory (V2) para ver las factorías de datos disponibles. En la lista de factorías de datos, seleccione Azure Data Factory <DLZ-prefix>-dev-integration-datafactory001. Elija Seleccionar.
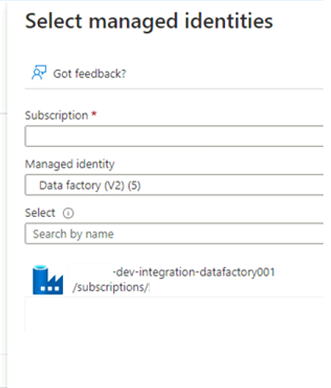
Seleccione Revisar y asignar dos veces para completar el proceso.
Cuentas de almacenamiento
A continuación, asigne los roles necesarios a las cuentas de almacenamiento <DLZ-prefix>devraw, <DLZ-prefix>devencur y <DLZ-prefix>devwork.
Para asignar los roles, complete los mismos pasos que usó para crear la asignación de roles de servidor de Azure SQL. Pero, para el rol, seleccione Colaborador de datos de Storage Blob en lugar de Colaborador.
Después de asignar roles para las tres cuentas de almacenamiento, Data Factory puede conectarse a las cuentas de almacenamiento y acceder a ellas.
Microsoft Purview
El último paso para agregar asignaciones de roles es agregar el rol Conservador de datos de Purview en Microsoft Purview a la cuenta de identidad administrada de la factoría de datos <DLZ-prefix>-dev-integration-datafactory001. Complete los pasos siguientes para que Data Factory pueda enviar información de recursos del catálogo de datos desde varios orígenes de datos a la cuenta de Purview.
En el grupo de recursos
<DMLZ-prefix>-dev-governance, vaya a la cuenta<DMLZ-prefix>-dev-purview001de Purview.En Purview Studio, seleccione el icono Asignación de datos y, a continuación, seleccione Colecciones.
Seleccione la pestaña Asignaciones de roles para la colección. En Conservadores de datos, agregue la identidad administrada para
<DLZ-prefix>-dev-integration-datafactory001: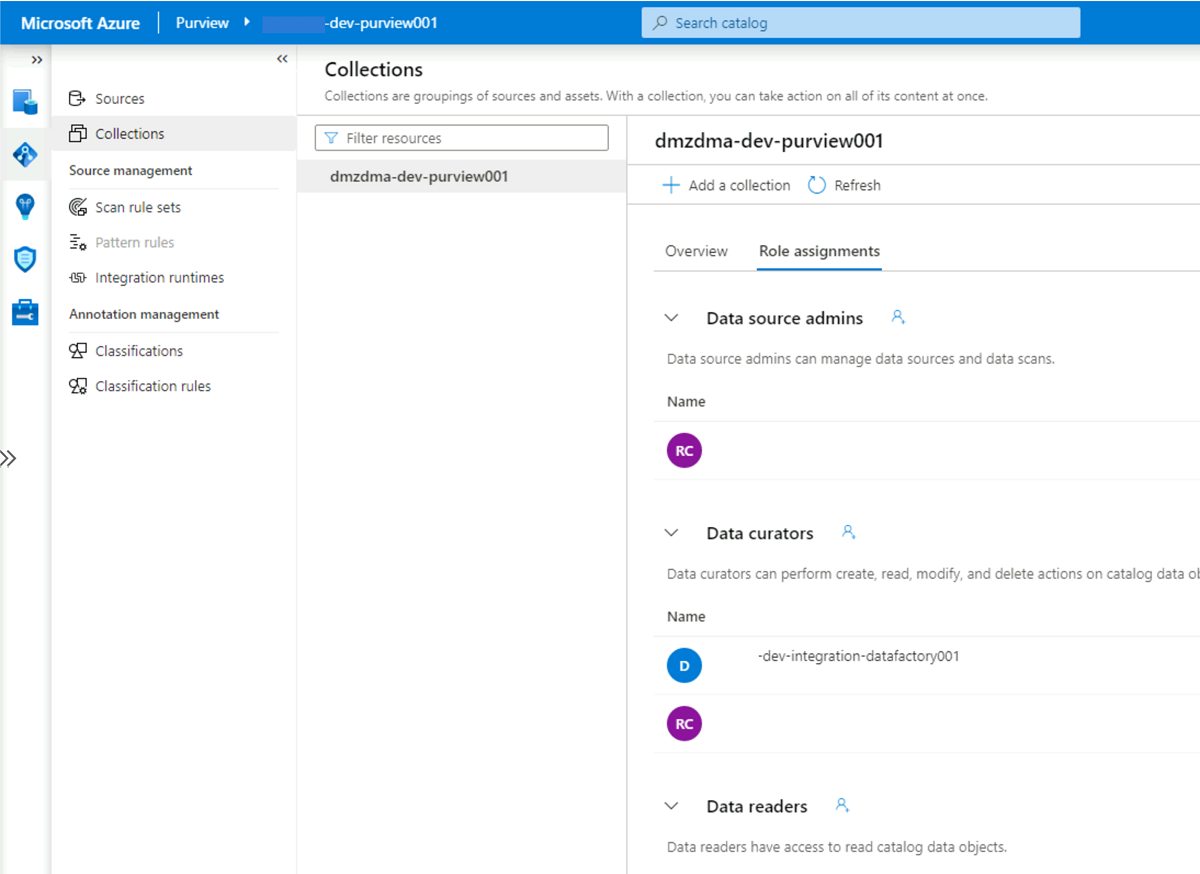
Conexión de Data Factory a Purview
Se establecen los permisos y Purview puede ver ahora la factoría de datos. El siguiente paso consiste en que <DMLZ-prefix>-dev-purview001 se conecte a <DLZ-prefix>-dev-integration-datafactory001.
En Purview Studio, seleccione el icono Administración y, a continuación, seleccione Data Factory. Seleccione Nueva para crear una conexión de Data Factory.
En el panel Nuevas conexiones de Data Factory, escriba la suscripción de Azure y seleccione la factoría de datos
<DLZ-prefix>-dev-integration-datafactory001. Seleccione Aceptar.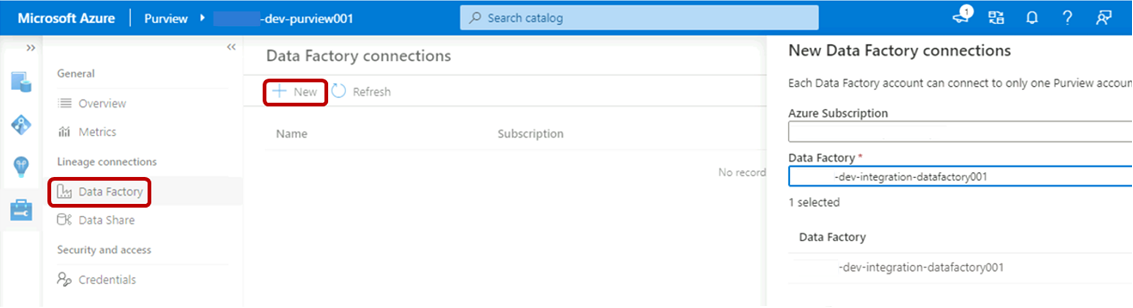
En la instancia
<DLZ-prefix>-dev-integration-datafactory001de Data Factory Studio, en Administrar>Azure Purview, actualice la cuenta de Azure Purview.La integración de
Data Lineage - Pipelineahora muestra el icono Conectado en verde.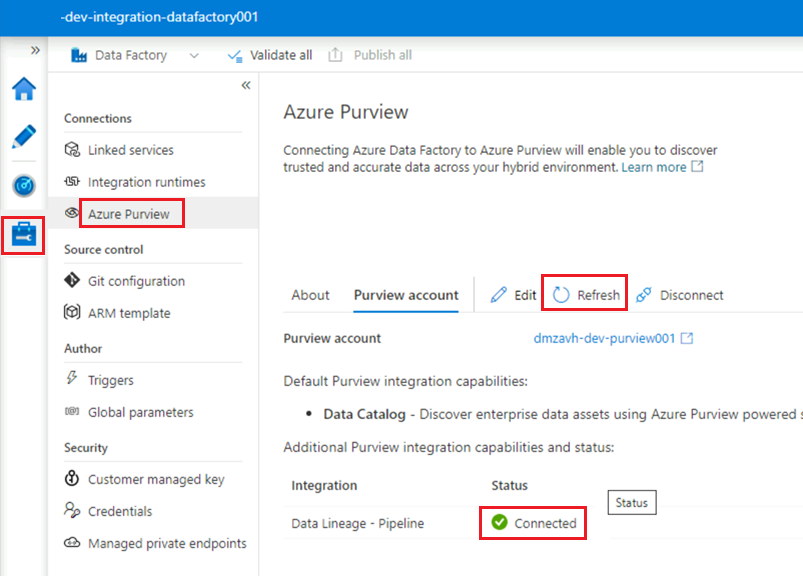

Creación de una canalización de ETL
Ahora que <DLZ-prefix>-dev-integration-datafactory001 tiene los permisos de acceso necesarios, cree una actividad de copia en Data Factory para mover datos de instancias de SQL Database a la cuenta de almacenamiento sin procesar <DLZ-prefix>devraw.
Uso de la herramienta Copiar datos con AdatumCRM
Este proceso extrae los datos del cliente de la instancia AdatumCRM de SQL Database y los copia en el almacenamiento Data Lake Storage Gen2.
En Data Factory Studio, seleccione el icono Autor y, a continuación, seleccione Recursos de fábrica. Seleccione el signo más (+) y la herramienta Copiar datos.
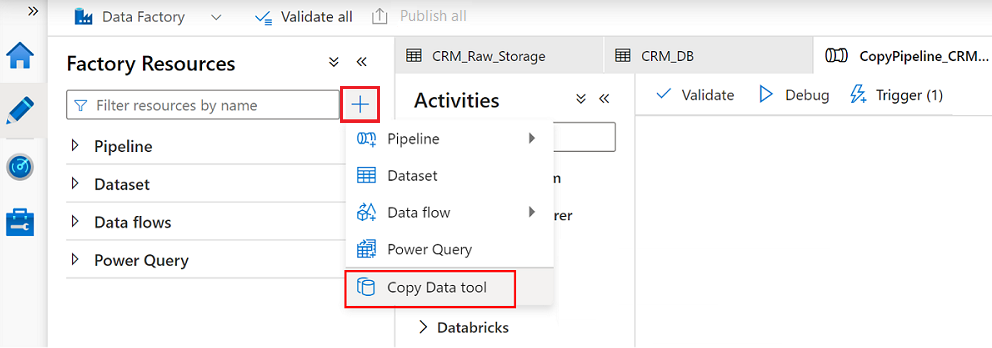
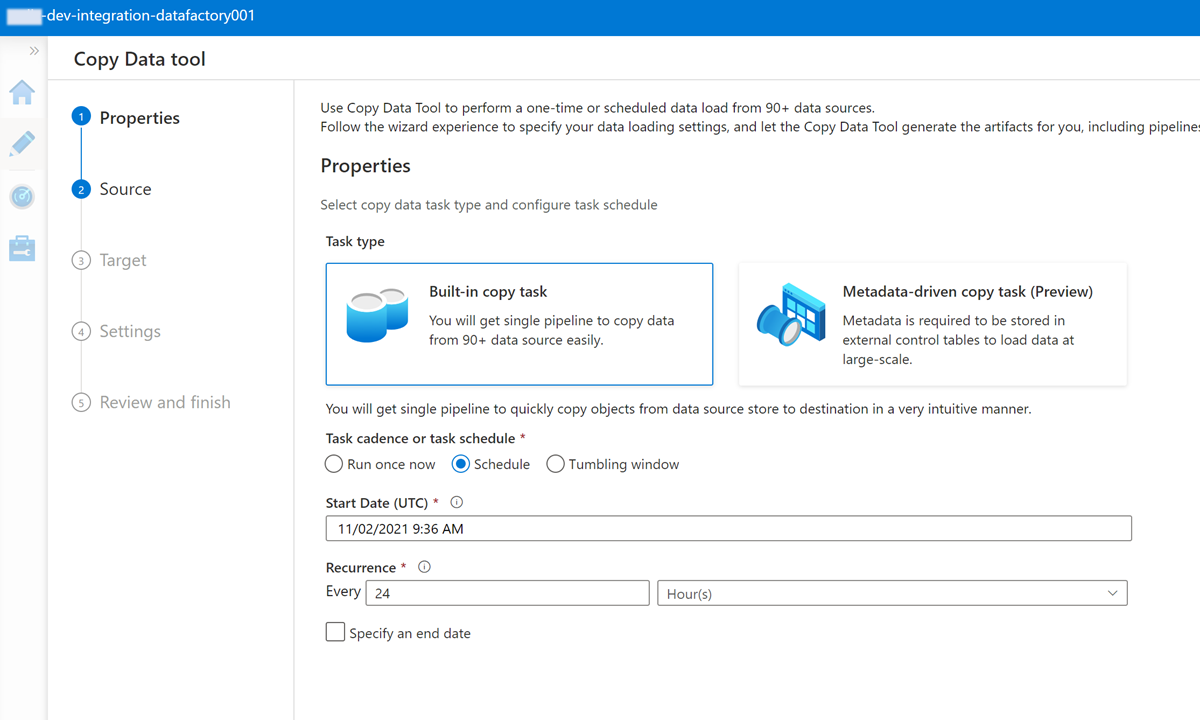
Complete cada paso en el Asistente para la herramienta Copiar datos:
Para crear un desencadenador para ejecutar la canalización cada 24 horas, seleccione Programar.
Para crear un servicio vinculado para conectar esta factoría de datos a la instancia
AdatumCRMde SQL Database en el servidor<DP-prefix>-dev-sqlserver001(origen), seleccione Nueva conexión.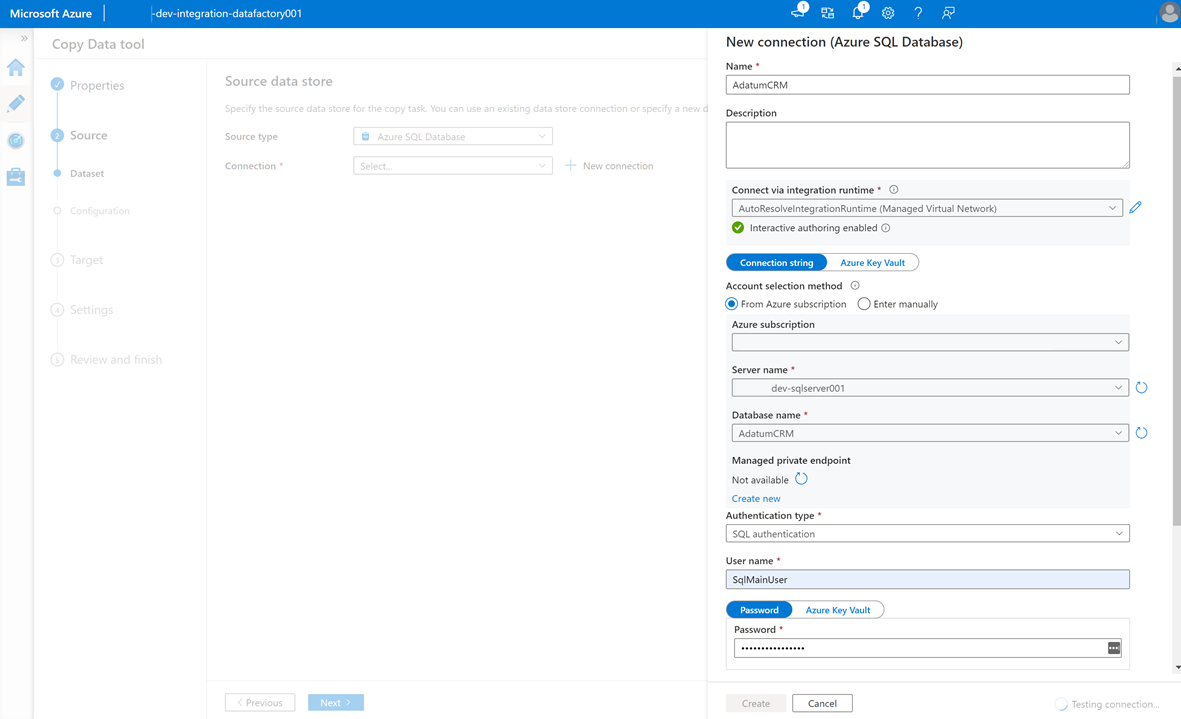
Nota:
Si experimenta errores al conectarse o acceder a los datos en las instancias de SQL Database o en las cuentas de almacenamiento, revise los permisos de la suscripción de Azure. Asegúrese de que la factoría de datos tiene las credenciales necesarias y los permisos de acceso a cualquier recurso problemático.
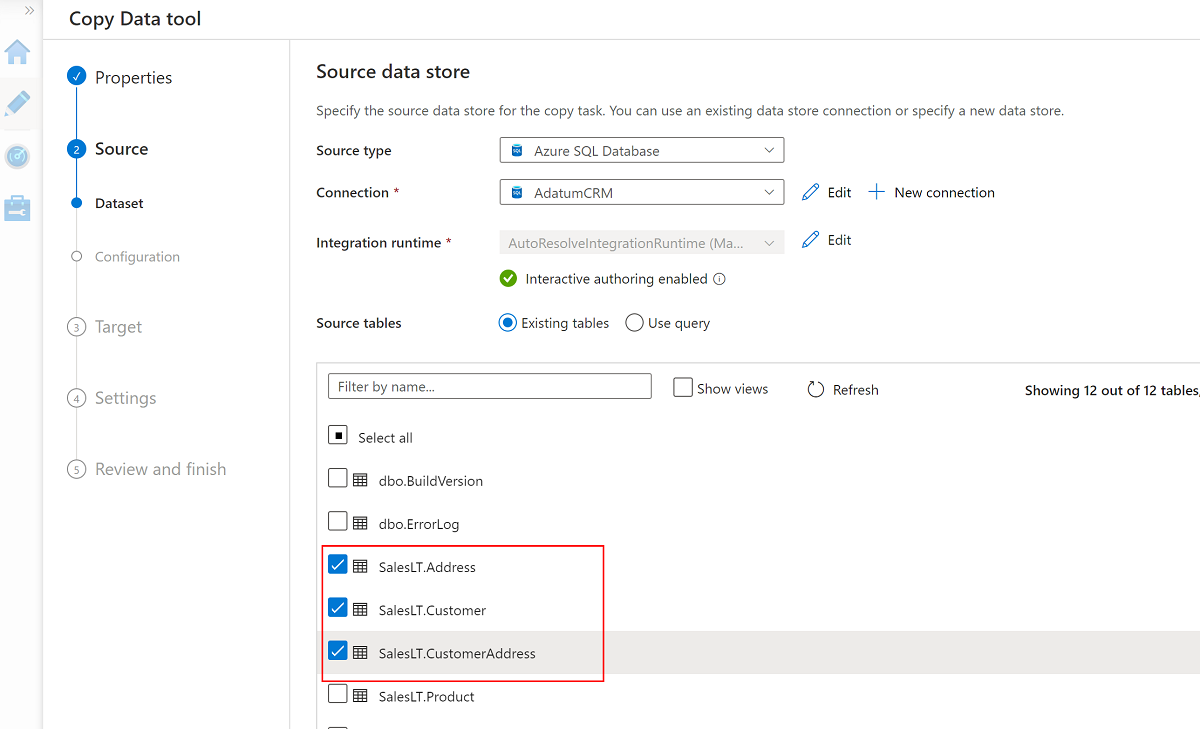
Seleccione estas tres tablas:
SalesLT.AddressSalesLT.CustomerSalesLT.CustomerAddress
Cree un nuevo servicio vinculado para acceder al almacenamiento
<DLZ-prefix>devrawde Azure Data Lake Storage Gen2 (destino).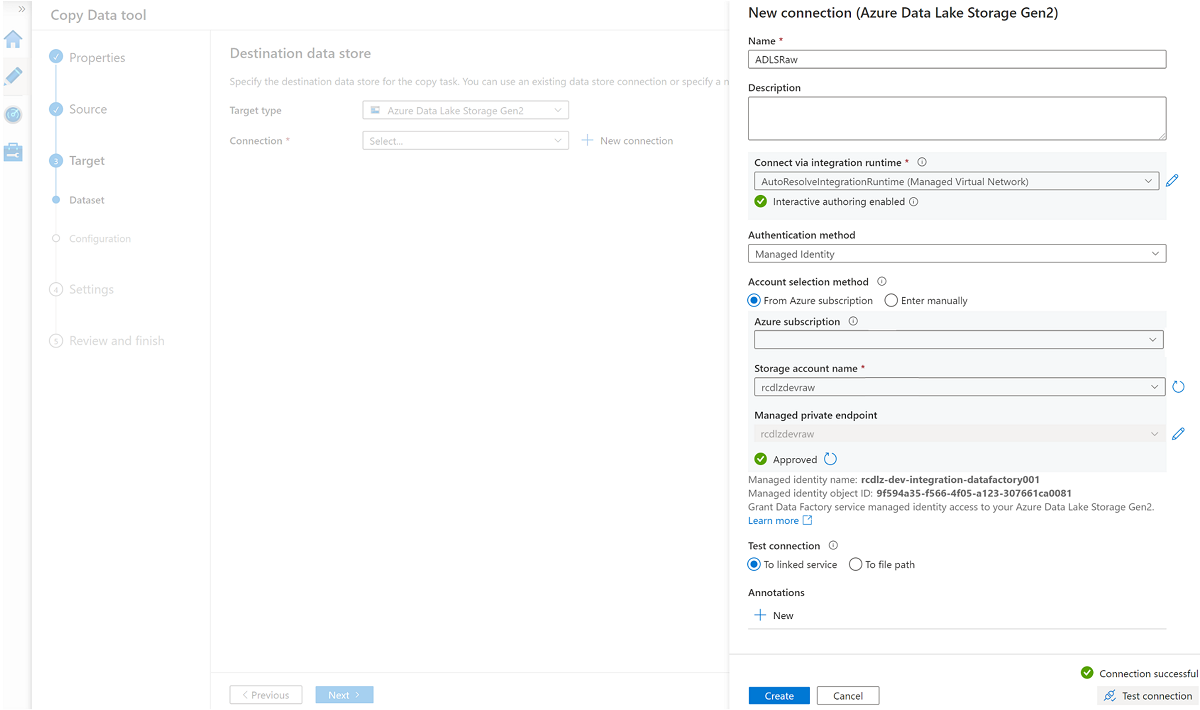
Examine las carpetas del almacenamiento
<DLZ-prefix>devrawy seleccione Datos como destino.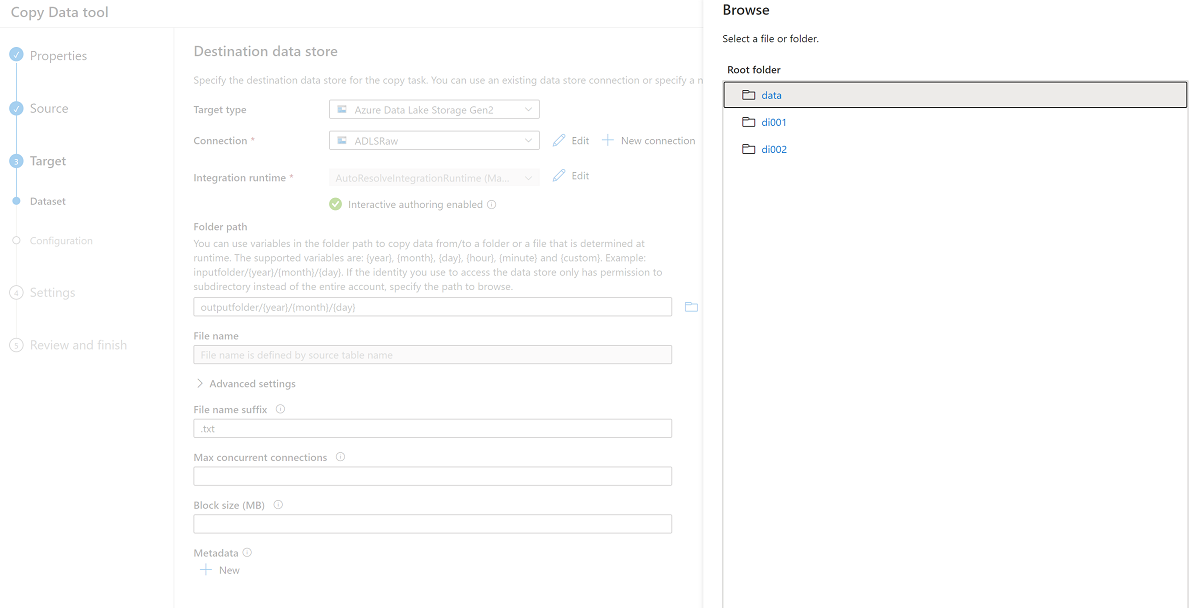
Cambie el sufijo de nombre de archivo a .csv y use las demás opciones predeterminadas.
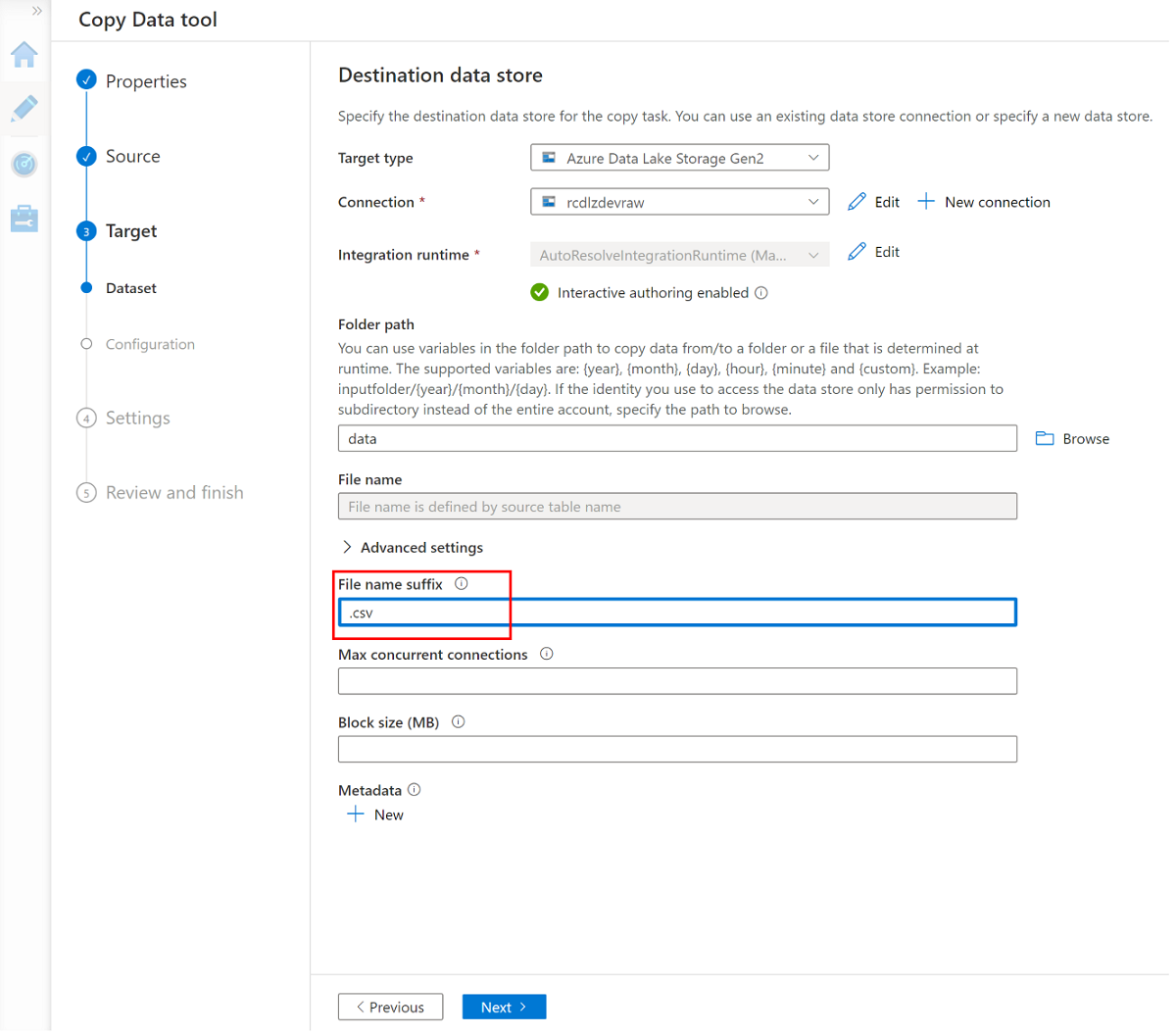
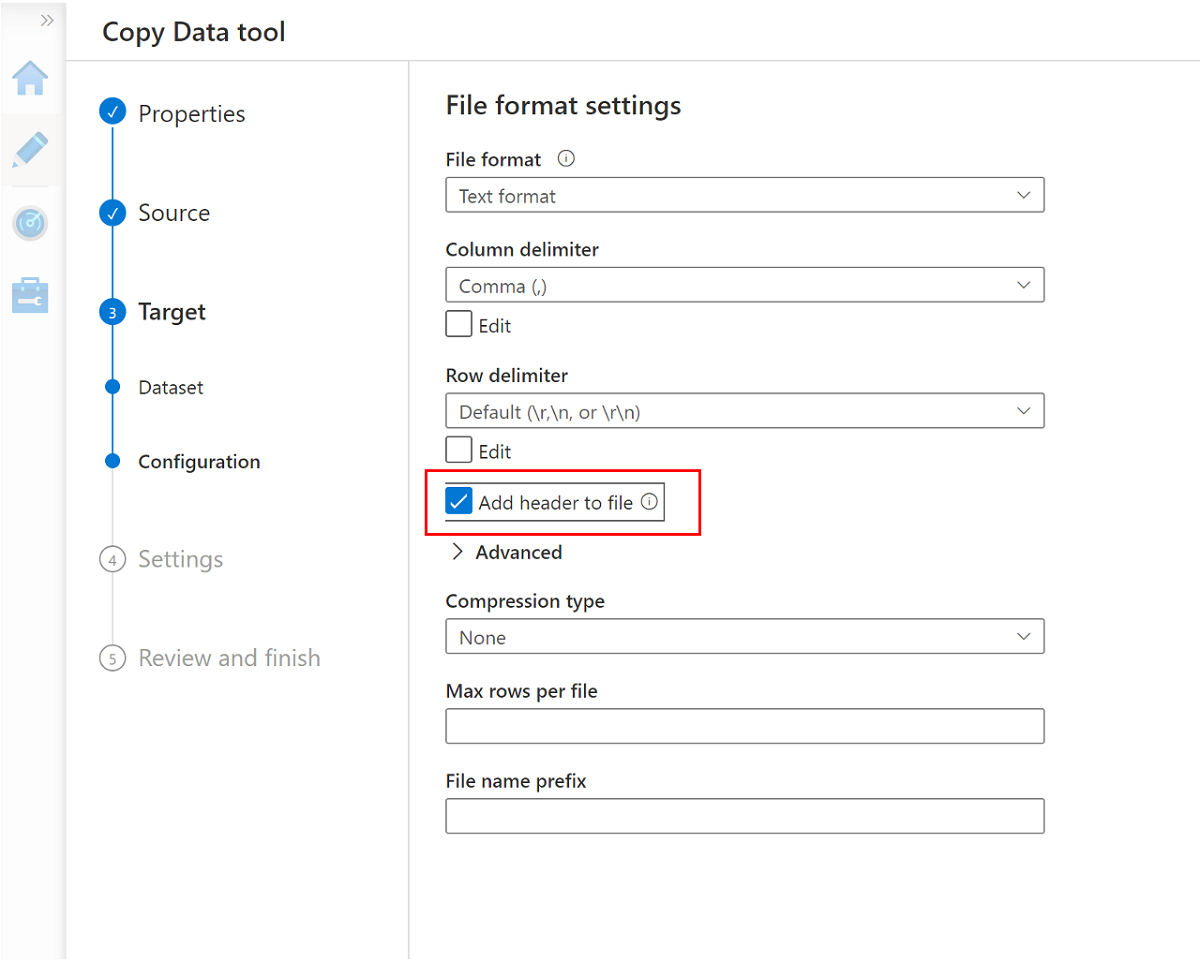
Vaya al panel siguiente y seleccione Agregar encabezado a archivo.
Cuando termine el asistente, el panel Implementación finalizada tendrá un aspecto similar al de este ejemplo:
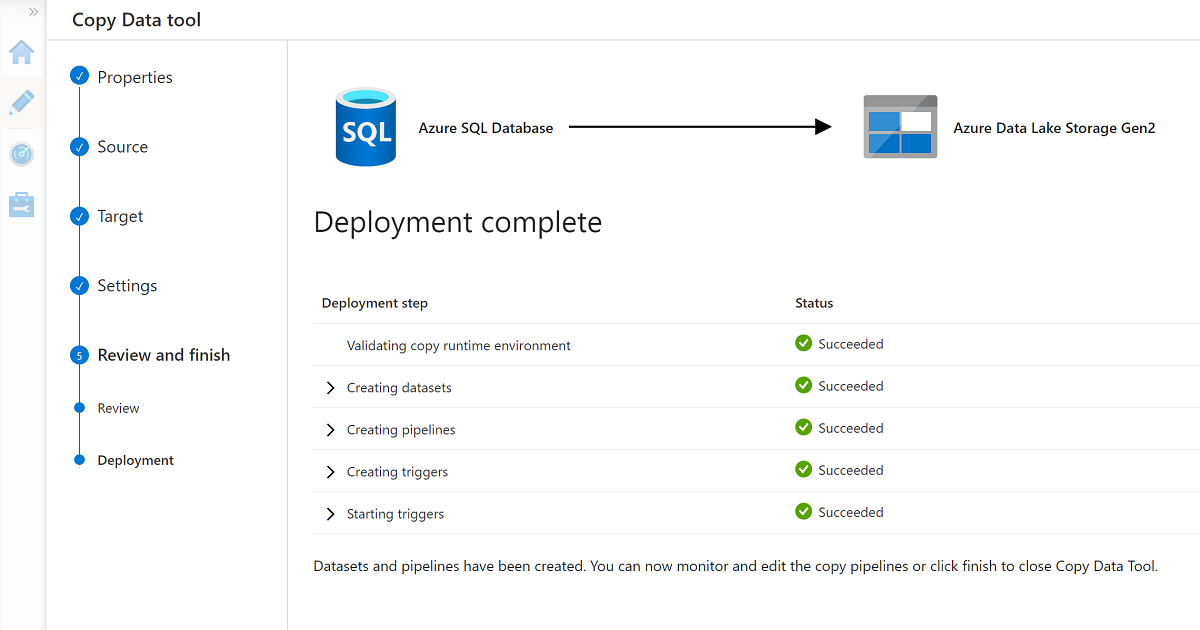




La nueva canalización aparece en Canalizaciones.
Ejecución de la canalización
Este proceso crea tres archivos .csv en la carpeta Data\CRM, uno para cada una de las tablas seleccionadas de la base de datos AdatumCRM.
Cambie el nombre de la canalización
CopyPipeline_CRM_to_Raw.Cambie el nombre de los conjuntos de datos
CRM_Raw_StorageyCRM_DB.En la barra de comandos Recursos de fábrica, seleccione Publicar todo.
Seleccione la canalización
CopyPipeline_CRM_to_Rawy, en la barra de comandos de canalización, seleccione Desencadenar para copiar las tres tablas de SQL Database en Data Lake Storage Gen2.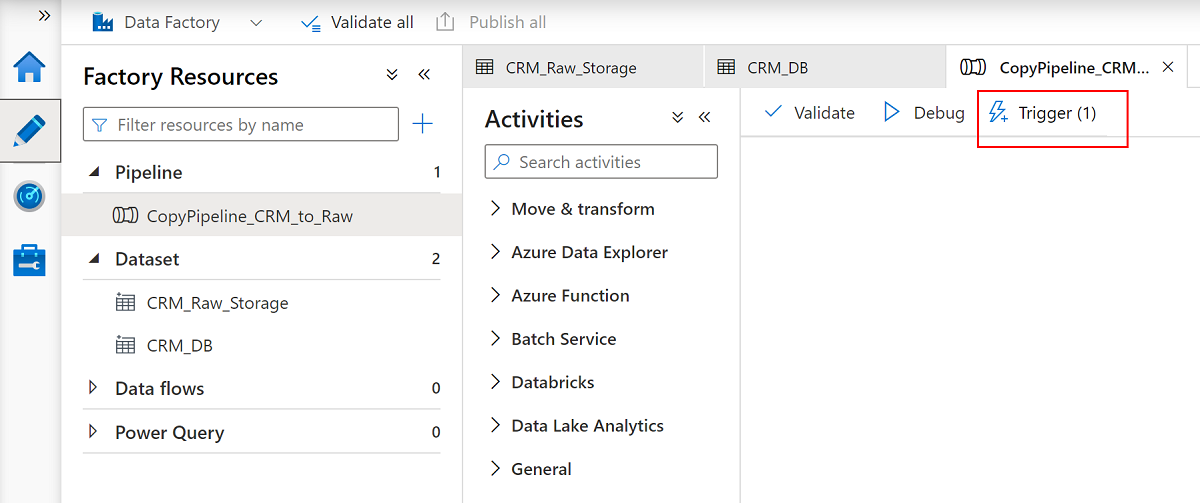
Uso de la herramienta Copiar datos con AdatumERP
A continuación, extraiga los datos de la base de datos AdatumERP. Los datos representan los datos de ventas procedentes del sistema ERP.
Aún en Data Factory Studio, cree una nueva canalización mediante la herramienta Copiar datos. Esta vez, va a enviar los datos de ventas desde la carpeta de datos de la cuenta de almacenamiento
AdatumERPa<DLZ-prefix>devraw, de la misma manera que hizo con los datos de CRM. Complete los mismos pasos, pero use la base de datosAdatumERPcomo origen.Cree la programación para que se desencadene cada hora.
Cree un servicio vinculado a la instancia
AdatumERPde SQL Database.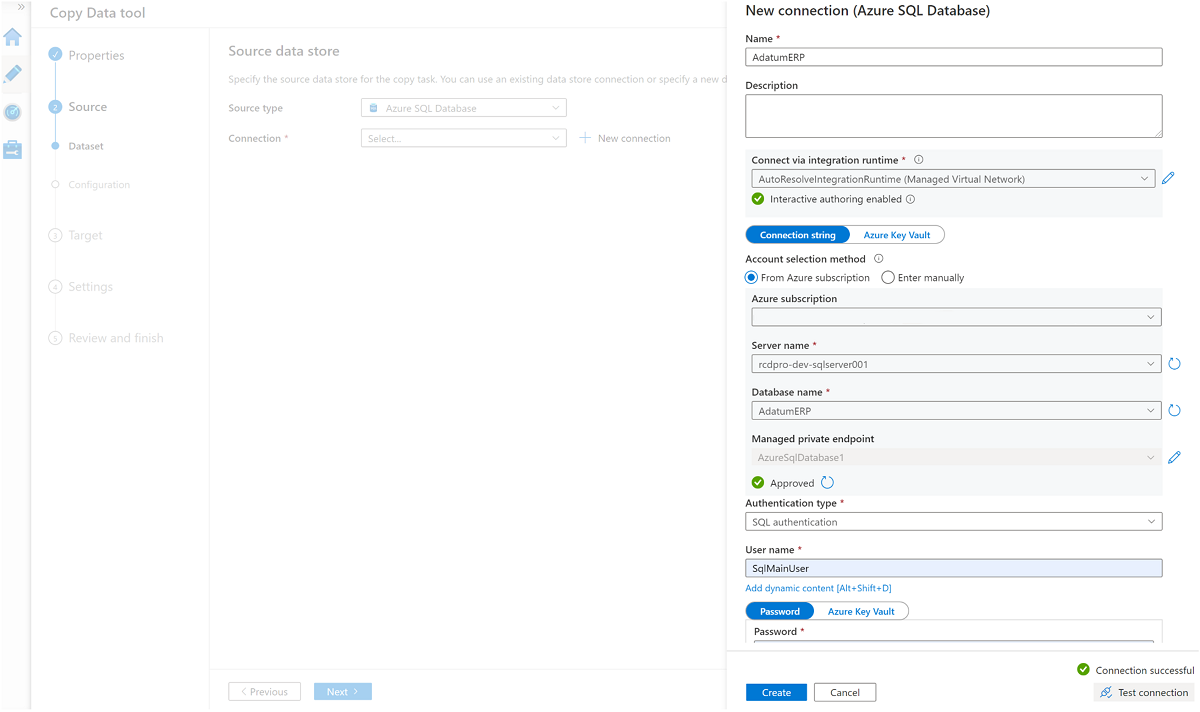
Seleccione estas siete tablas:
SalesLT.ProductSalesLT.ProductCategorySalesLT.ProductDescriptionSalesLT.ProductModelSalesLT.ProductModelProductDescriptionSalesLT.SalesOrderDetailSalesLT.SalesOrderHeader
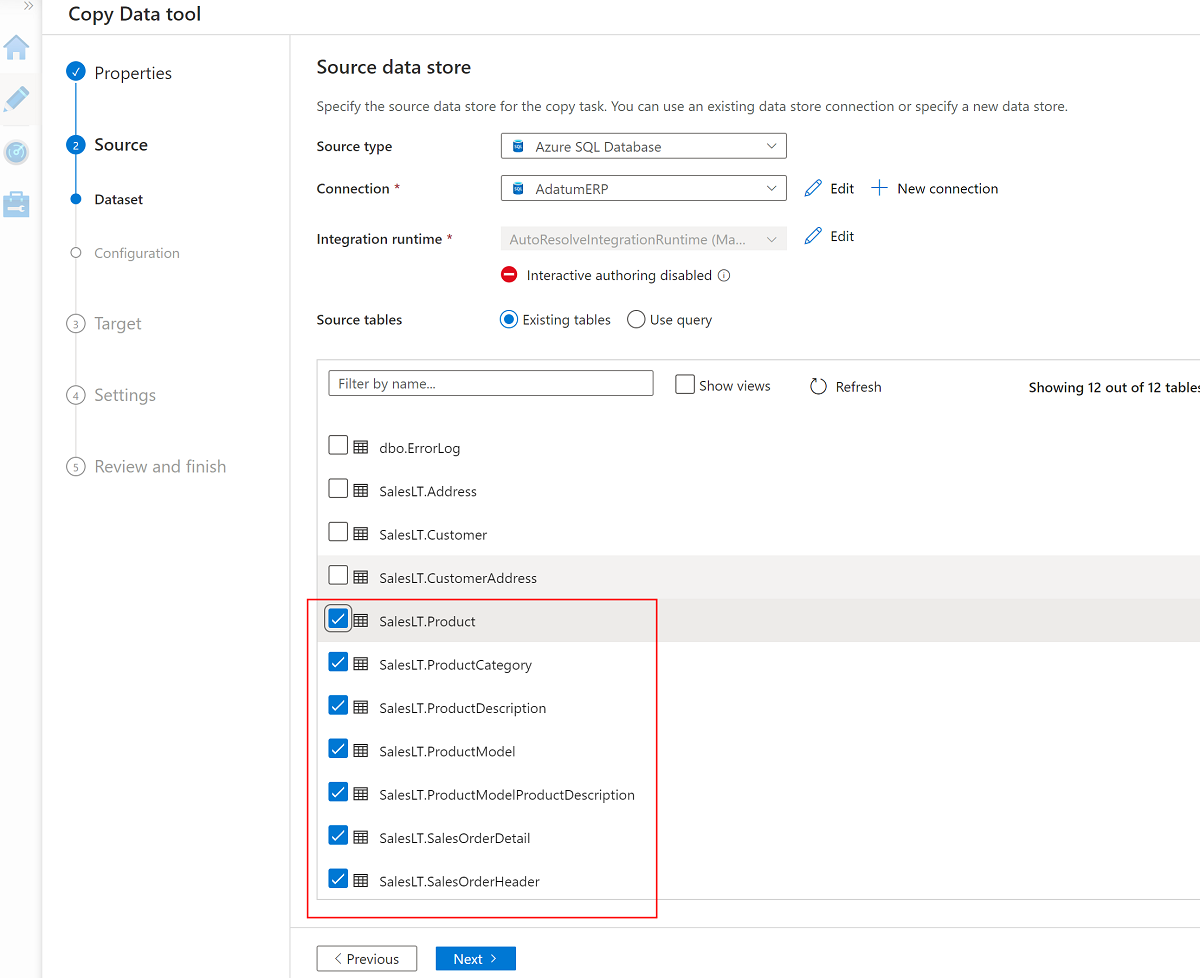
Use el servicio vinculado existente en la cuenta de almacenamiento
<DLZ-prefix>devrawy establezca la extensión de archivo en .csv.
Seleccione Agregar encabezado a archivo.
Vuelva a completar el asistente y cambie el nombre de la canalización
CopyPipeline_ERP_to_DevRaw. A continuación, en la barra de comandos, seleccione Publicar todo. Por último, ejecute el desencadenador en esta canalización recién creada para copiar las siete tablas seleccionadas de SQL Database en Data Lake Storage Gen2.

Cuando termine estos pasos, hay 10 archivos CSV en el almacenamiento <DLZ-prefix>devraw de Data Lake Storage Gen2. En la sección siguiente, se conservan los archivos del almacenamiento <DLZ-prefix>devencur de Data Lake Storage Gen2.
Conservación de datos en Data Lake Storage Gen2
Cuando termine de crear los 10 archivos CSV en el almacenamiento <DLZ-prefix>devraw sin procesar de Data Lake Storage Gen2, transforme estos archivos según sea necesario cuando los copie en el almacenamiento <DLZ-prefix>devencur conservado de Data Lake Storage Gen2.
Siga usando Azure Data Factory para crear estas nuevas canalizaciones para orquestar el movimiento de datos.
Conservación de datos de CRM en el cliente
Cree un flujo de datos que obtenga los archivos CSV de la carpeta Data\CRM en <DLZ-prefix>devraw. Transforme los archivos y copie los archivos transformados en formato de archivo .parquet en la carpeta Data\Customer en <DLZ-prefix>devencur.
En Azure Data Factory, vaya a la factoría de datos y seleccione Orquestar.
En General, asigne el nombre
Pipeline_transform_CRMa la canalización.En el panel Actividades, expanda Move and Transform (Mover y transformar). Arrastre la actividad de flujo de datos y colóquela en el lienzo de la canalización.
En Agregar flujo de datos, seleccione Crear nuevo flujo de datos y asigne el nombre
CRM_to_Customeral flujo de datos. Seleccione Finalizar.Nota
En la barra de comandos del lienzo de canalización, active Depuración de flujo de datos. En el modo de depuración, puede probar interactivamente la lógica de transformación en un clúster activo de Apache Spark. Los clústeres de flujo de datos tardan entre cinco y siete minutos en estar preparados. Se recomienda activar la depuración antes de comenzar el desarrollo del flujo de datos.

Cuando haya terminado de seleccionar las opciones en el flujo de datos
CRM_to_Customer, la canalizaciónPipeline_transform_CRMtendrá un aspecto similar al de este ejemplo: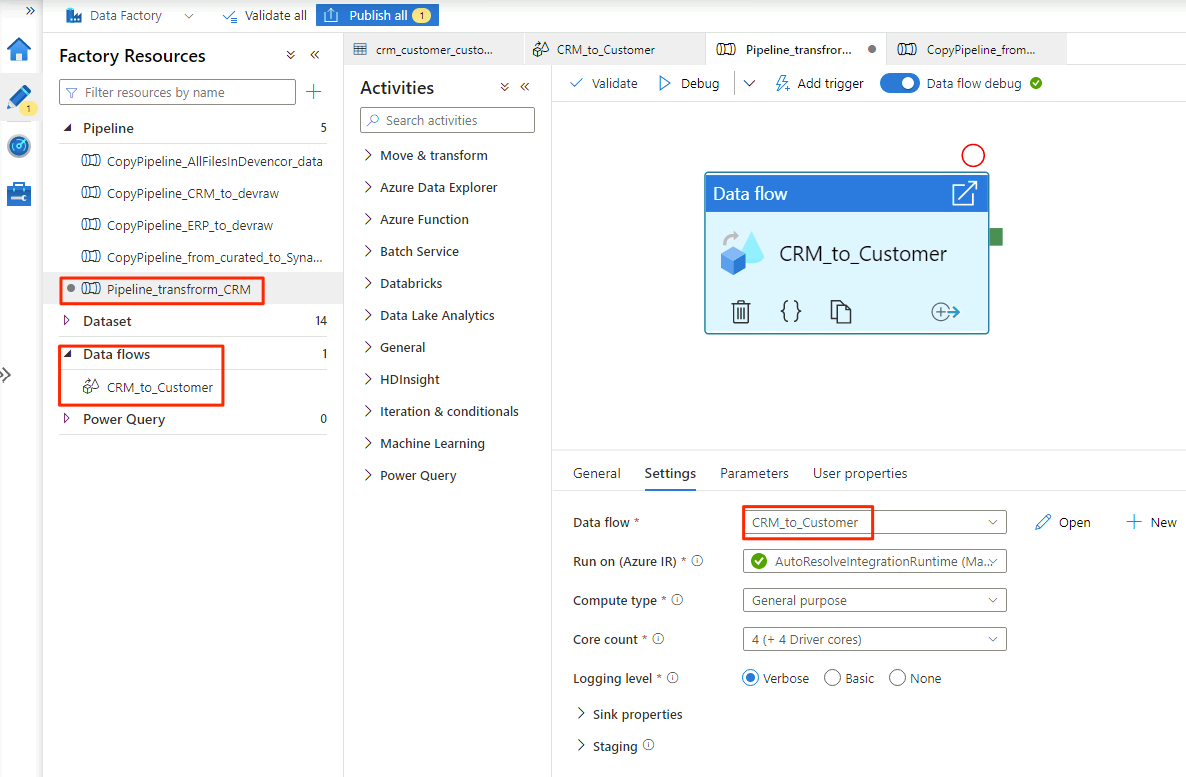
El flujo de datos tiene el aspecto de este ejemplo:
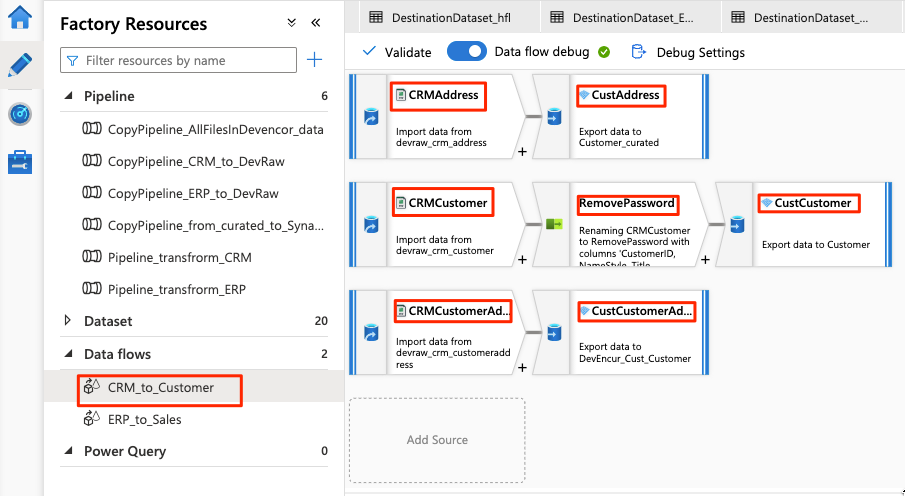
A continuación, modifique esta configuración en el flujo de datos para el origen
CRMAddress:Cree un conjunto de datos de Data Lake Storage Gen2. Use el formato DelimitedText. Asigne el nombre
DevRaw_CRM_Addressal conjunto de datos.Conecte el servicio vinculado a
<DLZ-prefix>devraw.Seleccione el archivo
Data\CRM\SalesLTAddress.csvcomo origen.
Modifique esta configuración en el flujo de datos para el receptor
CustAddress:Cree un conjunto de datos denominado
DevEncur_Cust_Address.Seleccione la carpeta Data\Customer en
<DLZ-prefix>devencurcomo receptor.En Configuración\Salida en un único archivo, convierta el archivo en Address.parquet.
Para el resto de la configuración del flujo de datos, use la información de las tablas siguientes para cada componente. Tenga en cuenta que CRMAddress y CustAddress son las dos primeras filas. Úselas como ejemplos para los demás objetos.
Un elemento que no está en ninguna de las tablas siguientes es el modificador de esquema RemovePasswords. En la captura de pantalla anterior se muestra que este elemento va entre CRMCustomer y CustCustomer. Para agregar este modificador de esquema, vaya a Seleccionar configuración y quite PasswordHash y PasswordSalt.
CRMCustomer devuelve un esquema de 15 columnas del archivo .crv. CustCustomer escribe solo 13 columnas después de que el modificador de esquema quite las dos columnas de contraseña.
La tabla completa
| Nombre | Tipo de objeto | Nombre del conjunto de datos | Almacén de datos | Tipo de formato | Servicio vinculado | Archivo o carpeta |
|---|---|---|---|---|---|---|
CRMAddress |
source | DevRaw_CRM_Address |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTAddress.csv |
CustAddress |
sink | DevEncur_Cust_Address |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Address.parquet |
CRMCustomer |
source | DevRaw_CRM_Customer |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTCustomer.csv |
CustCustomer |
sink | DevEncur_Cust_Customer |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Customer.parquet |
CRMCustomerAddress |
source | DevRaw_CRM_CustomerAddress |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\CRM\SalesLTCustomerAddress.csv |
CustCustomerAddress |
sink | DevEncur_Cust_CustomerAddress |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\CustomerAddress.parquet |
La tabla ERP para ventas
Ahora, repita pasos similares para crear una canalización Pipeline_transform_ERP, cree un flujo de datos ERP_to_Sales para transformar los archivos .csv en la carpeta Data\ERP de <DLZ-prefix>devraw y copie los archivos transformados en la carpeta Data\Sales de <DLZ-prefix>devencur.
En la tabla siguiente, encontrará los objetos que se van a crear en el flujo de datos ERP_to_Sales y la configuración que necesita modificar para cada objeto. Cada archivo .csv se asigna a un receptor .parquet.
| Nombre | Tipo de objeto | Nombre del conjunto de datos | Almacén de datos | Tipo de formato | Servicio vinculado | Archivo o carpeta |
|---|---|---|---|---|---|---|
ERPProduct |
source | DevRaw_ERP_Product |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProduct.csv |
SalesProduct |
sink | DevEncur_Sales_Product |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\Product.parquet |
ERPProductCategory |
source | DevRaw_ERP_ProductCategory |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductCategory.csv |
SalesProductCategory |
sink | DevEncur_Sales_ProductCategory |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductCategory.parquet |
ERPProductDescription |
source | DevRaw_ERP_ProductDescription |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductDescription.csv |
SalesProductDescription |
sink | DevEncur_Sales_ProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductDescription.parquet |
ERPProductModel |
source | DevRaw_ERP_ProductModel |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductModel.csv |
SalesProductModel |
sink | DevEncur_Sales_ProductModel |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModel.parquet |
ERPProductModelProductDescription |
source | DevRaw_ERP_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductModelProductDescription.csv |
SalesProductModelProductDescription |
sink | DevEncur_Sales_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModelProductDescription.parquet |
ERPProductSalesOrderDetail |
source | DevRaw_ERP_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductSalesOrderDetail.csv |
SalesProductSalesOrderDetail |
sink | DevEncur_Sales_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderDetail.parquet |
ERPProductSalesOrderHeader |
source | DevRaw_ERP_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | DelimitedText | devraw |
Data\ERP\SalesLTProductSalesOrderHeader.csv |
SalesProductSalesOrderHeader |
sink | DevEncur_Sales_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderHeader.parquet |