Introducción a la captura de datos modificados en el almacén analítico de Azure Cosmos DB
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB
Use la captura de datos modificados (CDC) en el almacén analítico de Azure Cosmos DB como origen para Azure Data Factory o Azure Synapse Analytics para capturar cambios específicos en los datos.
Nota
Tenga en cuenta que la interfaz de servicio vinculado para la API de Azure Cosmos DB for MongoDB aún no está disponible en el flujo de datos. No obstante, podrá usar el punto de conexión de documentos de su cuenta con la interfaz de servicio vinculado "Azure Cosmos DB for NoSQL" como solución provisional hasta que se admita el servicio vinculado de Mongo. En un servicio vinculado NoSQL, seleccione "Introducir manualmente" para proporcionar la información de la cuenta de Cosmos DB y usar el punto de conexión del documento de la cuenta (p. ej.: https://[your-database-account-uri].documents.azure.com:443/) en lugar del punto de conexión de MongoDB (p. ej.: mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/)
Requisitos previos
- Una cuenta existente de Azure Cosmos DB.
- Si tiene una suscripción de Azure, cree una nueva cuenta.
- Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Como alternativa, puede probar Azure Cosmos DB gratis antes de confirmarlo.
Habilitación del almacén analítico
En primer lugar, habilite Azure Synapse Link en el nivel de cuenta y luego habilite el almacén analítico para los contenedores adecuados para la carga de trabajo.
Habilitación de Azure Synapse Link: Habilitación de Azure Synapse Link para una cuenta de Azure Cosmos DB
Habilite el almacén analítico para loa contenedores:
Opción Guía Habilitar para un contenedor nuevo específico Habilitación de Azure Synapse Link para contenedores nuevos Habilitar para un contenedor existente específico Habilitación de Azure Synapse Link para contenedores existentes
Creación de un recurso de Azure de destino mediante flujos de datos
La característica de captura de datos modificados del almacén analítico está disponible a través de la característica de flujo de datos de Azure Data Factory o Azure Synapse Analytics. Para esta guía, use Azure Data Factory.
Importante
También puede usar Azure Synapse Analytics. Primero, cree un área de trabajo de Azure Synapse si no tiene ninguna aún. En el área de trabajo recién creada, seleccione la pestaña Desarrollar, Agregar nuevo recurso, y luego seleccione Flujo de datos.
Cree una instancia de Azure Data Factory si aún no tiene uno.
Sugerencia
Si es posible, cree la factoría de datos en la misma región donde reside la cuenta de Azure Cosmos DB.
Inicie la factoría de datos recién creada.
En la factoría de datos, seleccione la pestaña Flujos de datos, y luego seleccione Nuevo flujo de datos.
Asigne un nombre único al flujo de datos recién creado. En este ejemplo, el flujo de datos se denomina
cosmoscdc.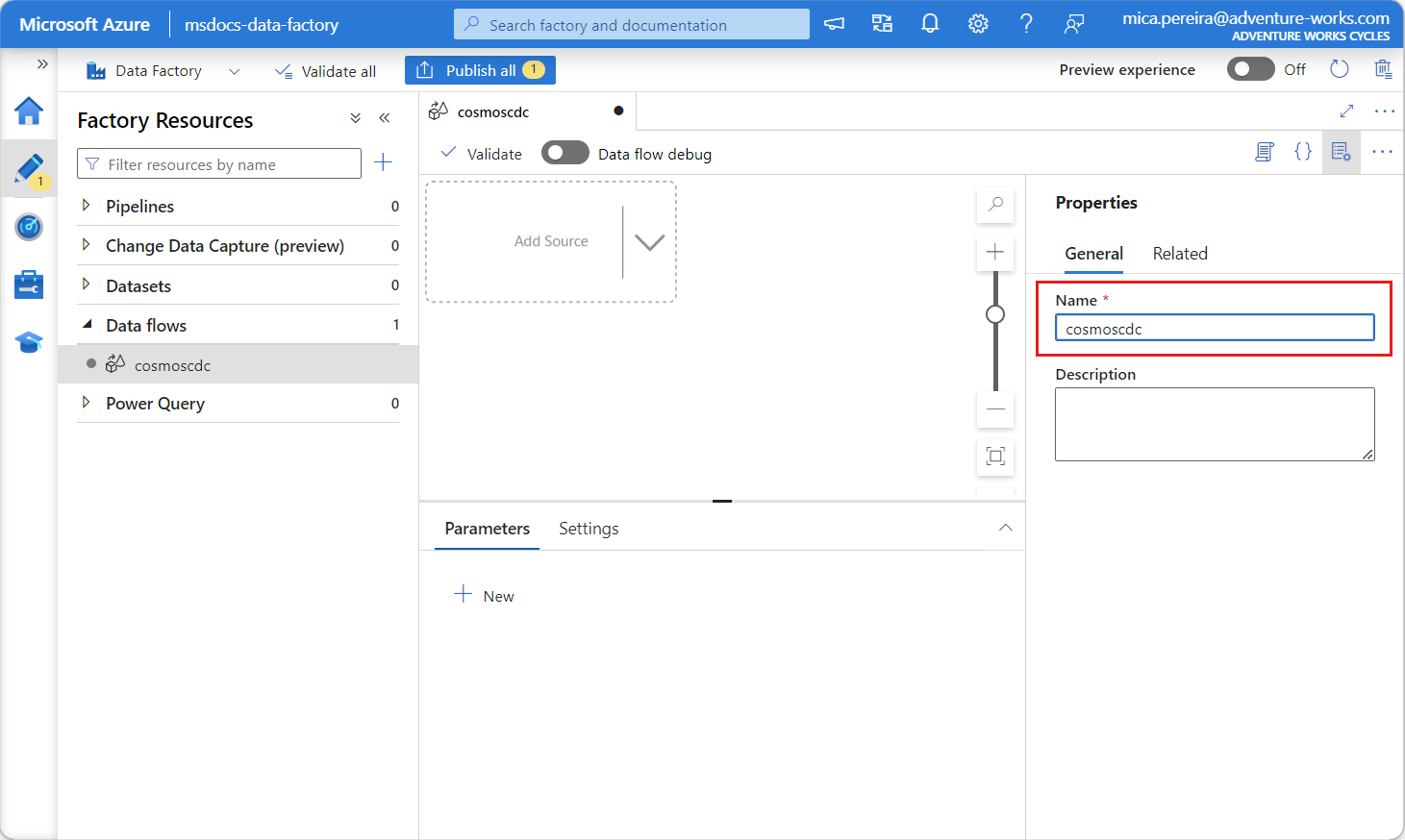

Configuración de los valores de origen para el contenedor del almacén analítico
Ahora cree y configure un origen para que fluya datos desde el almacén analítico de la cuenta de Azure Cosmos DB.
Seleccione Agregar origen.

En el campo Nombre del flujo de salida, escriba cosmos.

En la sección Tipo de origen, seleccione Insertado.

En el campo Conjunto de datos, seleccione Azure: Azure Cosmos DB for NoSQL.

Cree un nuevo servicio vinculado para la cuenta que se denomine cosmoslinkedservice. Seleccione la cuenta existente de Azure Cosmos DB for NoSQL en el cuadro de diálogo emergente Nuevo servicio vinculado, y luego seleccione Aceptar. En este ejemplo, se selecciona una cuenta de Azure Cosmos DB for NoSQL existente denominada
msdocs-cosmos-sourcey una base de datos denominadacosmicworks.
Seleccione Analítico para el tipo de almacén.

Seleccione la pestaña Opciones de origen.
En Opciones de origen, seleccione el contenedor de destino y habilite Depuración del flujo de datos. En este ejemplo, el contenedor se denomina
products.
Seleccione Depuración de flujo de datos. En el cuadro de diálogo emergente Activar depuración del flujo de datos, conserve las opciones predeterminadas y luego seleccione Aceptar.

La pestaña Opciones de origen también contiene otras opciones que puede habilitar. Esta tabla describe esas opciones:
| Opción | Descripción |
|---|---|
| Capturar actualizaciones intermedias | Habilite esta opción si desea capturar el historial de cambios en los elementos, incluidos los cambios intermedios entre las lecturas de captura de datos modificados. |
| Capturar eliminaciones | Habilite esta opción para capturar registros eliminados por el usuario y aplicarlos en el receptor. Las eliminaciones no se pueden aplicar en los receptores de Azure Data Explorer ni Azure Cosmos DB. |
| Capturar los TTL del almacén transaccional | Habilite esta opción para capturar los registros eliminados de los TTL (período de vida) del almacén transaccional de Azure Cosmos DB y aplicarlos en el receptor. Las eliminaciones de TTL no se pueden aplicar en los receptores de Azure Data Explorer ni Azure Cosmos DB. |
| Tamaño por lotes en bytes | Esta configuración es de hecho gigabytes. Especifique el tamaño en gigabytes si desea realizar la captura de datos de cambios por lotes. |
| Configuraciones adicionales | Configuraciones adicionales del almacén analítico de Azure Cosmos DB y sus valores. (por ejemplo: spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
Trabajar con opciones de origen
Al comprobar cualquiera de las opciones Capture intermediate updates, Capture Deltes y Capture Transactional store TTLs, el proceso CDC creará y rellenará el campo __usr_opType en el receptor con los valores siguientes:
| Value | Descripción | Opción |
|---|---|---|
| 1 | UPDATE | Capturar actualizaciones intermedias |
| 2 | INSERT | No hay ninguna opción para las inserciones, está activada de forma predeterminada |
| 3 | USER_DELETE | Capturar eliminaciones |
| 4 | TTL_DELETE | Capturar los TTL del almacén transaccional |
Si tiene que diferenciar los registros eliminados de TTL de los documentos eliminados por usuarios o aplicaciones, compruebe las opciones Capture intermediate updates y Capture Transactional store TTLs. A continuación, tiene que adaptar los procesos CDC, las aplicaciones o consultas para usar __usr_opType según lo necesario para sus necesidades empresariales.
Sugerencia
Si es necesario que los consumidores de bajada restauren el orden de las actualizaciones con la opción "capturar actualizaciones intermedias", el campo de marca de tiempo del sistema _ts se puede usar como campo de ordenación.
Creación y configuración de los valores de receptor para las operaciones de actualización y eliminación
En primer lugar, cree un receptor de Azure Blob Storage sencillo y luego configure el receptor para que filtre los datos a solo operaciones específicas.
Cree una cuenta y un contenedor de Azure Blob Storage, si aún no los tiene. Para los ejemplos siguientes, usaremos una cuenta denominada
msdocsblobstoragey un contenedor denominadooutput.Sugerencia
Si es posible, cree la cuenta de almacenamiento en la misma región donde reside la cuenta de Azure Cosmos DB.
De nuevo en Azure Data Factory, cree un nuevo receptor para la captura de datos modificados desde el origen
cosmos.
Asigne un nombre único al receptor. En este ejemplo, el receptor se denomina
storage.
En la sección Tipo de receptor, seleccione Insertado. En el campo Conjunto de datos, seleccione Delta.

Cree un nuevo servicio vinculado para su cuenta mediante Azure Blob Storage denominado storagelinkedservice. Seleccione la cuenta existente de Azure Blob Storage en el cuadro de diálogo emergente Nuevo servicio vinculado, y luego seleccione Aceptar. En este ejemplo, se selecciona una cuenta de Azure Blob Storage existente denominada
msdocsblobstorage.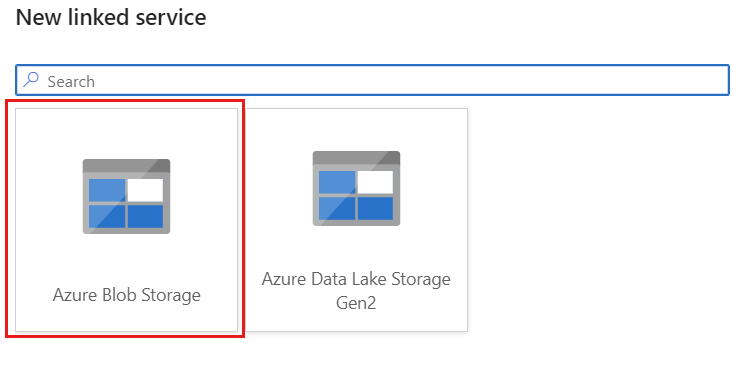

Seleccione la pestaña Configuración.
En Configuración, establezca la ruta de acceso de la carpeta según el nombre del contenedor de blobs. En este ejemplo, el nombre del contenedor es
output.
Busque la sección Método de actualización y cambie las selecciones para permitir solo las operaciones de eliminación y actualización. Además, especifique las Columnas de clave como una Lista de columnas usando el campo
{_rid}como identificador único.
Seleccione Validar para asegurarse de que no haya ningún error u omisión. A continuación, seleccione Publicar para publicar el flujo de datos.

Programación de la ejecución de la captura de datos modificados
Una vez publicado un flujo de datos, puede agregar una nueva canalización para mover y transformar los datos.
Crear una canalización. Asigne un nombre único a la canalización. En este ejemplo, la canalización se denomina
cosmoscdcpipeline.
En la sección Actividades, expanda la opción Mover y transformar, y luego seleccione Flujo de datos.

Asigne un nombre único a la actividad de flujo de datos. En este ejemplo, la actividad se denomina
cosmoscdcactivity.En la pestaña Configuración, seleccione el flujo de datos denominado
cosmoscdcque ha creado anteriormente en esta guía. A continuación, seleccione un tamaño de proceso basado en el volumen de datos y la latencia necesaria para la carga de trabajo.
Sugerencia
En el caso de los tamaños de datos incrementales mayores de 100 GB, se recomienda el tamaño personalizado con un recuento de núcleos de 32 (+16 núcleos de controladores).
Seleccione Agregar desencadenador. Programe esta canalización para que se ejecute con una cadencia que sea adecuada para la carga de trabajo. En este ejemplo, la canalización está configurada para ejecutarse cada cinco minutos.


Nota:
La ventana de periodicidad mínima para las ejecuciones de captura de datos modificados es de un minuto.
Seleccione Validar para asegurarse de que no haya ningún error u omisión. A continuación, seleccione Publicar para publicar la canalización.
Observe los datos colocados en el contenedor de Azure Blob Storage como salida del flujo de datos mediante la captura de datos modificados del almacén analítico de Azure Cosmos DB.

Nota:
El tiempo de arranque inicial del clúster puede tardar hasta tres minutos. Para evitar el tiempo de inicio del clúster en las ejecuciones posteriores de captura de datos modificados, configure el valor Tiempo de vida del clúster de flujo de datos. Para más información sobre el entorno de ejecución de integración y el TTL, consulte Entorno de ejecución de integración en Azure Data Factory.
Trabajos simultáneos
El tamaño del lote en las opciones de origen, o las situaciones en las que el receptor tarda en ingerir el flujo de cambios, pueden provocar la ejecución de varios trabajos al mismo tiempo. Para evitar esta situación, establezca la opción Simultaneidad en 1 en la configuración de la canalización, para asegurarse de que no se desencadenan nuevas ejecuciones hasta que finalice la ejecución actual.