Creación de una conexión de datos de Event Grid para Azure Data Explorer
En este artículo, aprenderá a ingerir blobs desde la cuenta de almacenamiento en Azure Data Explorer mediante una conexión de datos de Event Grid. Creará una conexión de datos de Event Grid que establece una suscripción de Azure Event Grid. La suscripción de Event Grid enruta los eventos desde la cuenta de almacenamiento a Azure Data Explorer mediante Azure Event Hubs.
Nota:
La ingesta admite un tamaño de archivo máximo de 6 GB. Se recomienda ingerir archivos de entre 100 MB y 1 GB.
Para obtener información sobre cómo crear la conexión mediante los SDK de Kusto, consulte Crear una conexión de datos de Event Grid con SDK.
Para información general sobre la ingesta en Azure Data Explorer desde Event Grid, consulte Conexión a Event Grid.
Nota:
Para lograr el mejor rendimiento con la conexión de Event Grid, establezca la propiedad de ingesta rawSizeBytes a través de los metadatos del blob. Para obtener más información, vea propiedades de ingesta.
Requisitos previos
- Suscripción a Azure. Cree una cuenta de Azure gratuita.
- Un clúster y la base de datos de Azure Data Explorer. Cree un clúster y una base de datos.
- Una tabla de destino. Cree una tabla o use una tabla existente.
- Una asignación de ingesta para la tabla.
- Una cuenta de almacenamiento. Una suscripción de notificación de Event Grid se puede establecer en cuentas de Azure Storage para
BlobStorage,StorageV2o Data Lake Storage Gen2. - Tener el proveedor de recursos de Event Grid registrado.
Creación de una conexión de datos de Event Grid
En esta sección, establecerá una conexión entre Event Grid y la tabla de Azure Data Explorer.
Vaya al clúster de Azure Data Explorer en Azure Portal.
En Datos, seleccione Bases de datos>TestDatabase.
En Configuración, seleccione Conexiones de datos y, a continuación, seleccione Agregar conexión de datos>Event Grid (Blob Storage).
Rellene el formulario de conexión de datos de Event Grid con la siguiente información:
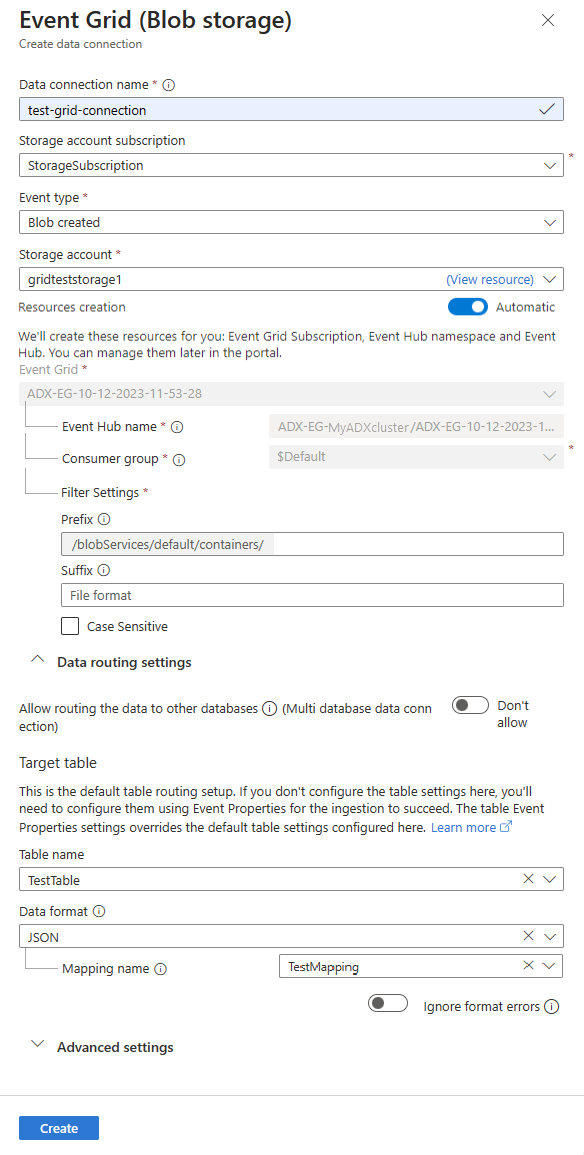
Configuración Valor sugerido Descripción del campo Nombre de la conexión de datos test-grid-connection Nombre de la conexión que desea crear en Azure Data Explorer. Los nombres de conexiones de datos solo pueden contener caracteres alfanuméricos, guiones y puntos, y tener como máximo 40 caracteres. Suscripción de la cuenta de almacenamiento Su Id. de suscripción El identificador de la suscripción en la que reside la cuenta de almacenamiento. Tipo de evento Blob creado o Blob con el nombre cambiado Tipo de evento que desencadena la ingesta. El evento Blob con el nombre cambiado solo se admite para el almacenamiento de ADLSv2. Para cambiar el nombre de un blob, vaya al blob en Azure Portal, haga clic con el botón derecho en el blob y seleccione Cambiar nombre. Estos son los tipos que se admiten: Microsoft.Storage.BlobCreated o Microsoft.Storage.BlobRenamed. Cuenta de almacenamiento gridteststorage1 Nombre de la cuenta de almacenamiento que creó anteriormente. Creación de recursos Automático Activar la creación automática de recursos significa que Azure Data Explorer crea una suscripción a Event Grid, un espacio de nombres de Event Hubs y Event Hubs automáticamente. De lo contrario, deberá crear estos recursos manualmente para garantizar la creación de la conexión de datos. Consulte Creación manual de recursos para la ingesta de Event Grid Si lo desea, puede realizar un seguimiento de temas específicos de Event Grid. Establezca los filtros para las notificaciones de la manera siguiente:
- El campo prefijo es el prefijo literal del asunto. Como el patrón que se aplica es comienza por, puede abarcar varios contenedores, carpetas o blobs. No se permiten comodines.
- Para definir un filtro en el contenedor de blobs, el campo debe establecerse de la siguiente manera:
/blobServices/default/containers/[container prefix]. - Para definir un filtro en un prefijo de blob (o en una carpeta en Azure Data Lake Gen2), el campo debe establecerse de la siguiente manera:
/blobServices/default/containers/[container name]/blobs/[folder/blob prefix].
- Para definir un filtro en el contenedor de blobs, el campo debe establecerse de la siguiente manera:
- El campo sufijo es el sufijo literal del blob. No se permiten comodines.
- El campo Distinguir mayúsculas de minúsculas indica si los filtros de prefijos y sufijos distinguen mayúsculas de minúsculas.
Para obtener más información sobre el filtrado de eventos, consulte Eventos de Blob Storage.
- El campo prefijo es el prefijo literal del asunto. Como el patrón que se aplica es comienza por, puede abarcar varios contenedores, carpetas o blobs. No se permiten comodines.
Si lo desea, puede especificar la configuración de enrutamiento de datos de acuerdo con la siguiente información. No es necesario especificar todos los valores de configuración de enrutamiento de datos. También se aceptan configuraciones parciales.
Configuración Valor sugerido Descripción del campo Permite el enrutamiento de los datos a otras bases de datos (conexión de datos de varias bases de datos) No permitir Active esta opción si desea invalidar la base de datos de destino predeterminada asociada a la conexión de datos. Para más información acerca del enrutamiento de bases de datos, consulte Enrutamiento de eventos. Nombre de tabla TestTable La tabla que creó en TestDatabase. Formato de datos JSON Los formatos admitidos son APACHEAVRO, Avro, CSV, JSON, ORC, PARQUET, PSV, RAW, SCSV, SOHSV, TSV, TSVE, TXT y W3CLOG. Las opciones de compresión admitidas son zip y gzip. Nombre de asignación TestTable_mapping La asignación que creó en TestDatabase, que asigna los datos entrantes a los nombres de columnas y tipos de datos de TestTable. Si no se especifica, se genera automáticamente una asignación de datos de identidad derivada del esquema de la tabla. Omitir errores de formato Ignore Active esta opción si desea omitir los errores de formato para el formato de datos JSON. Nota:
Los nombres de tabla y de asignación distinguen mayúsculas de minúsculas.
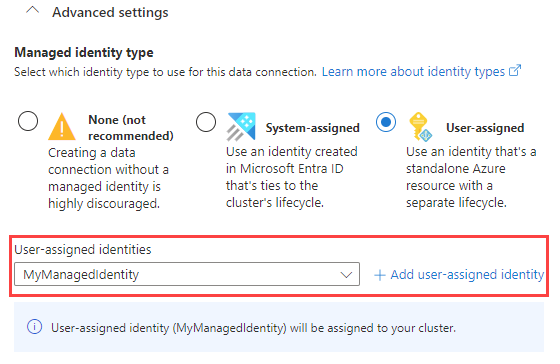
Si lo desea, en Configuración avanzada, puede especificar el tipo de identidad administrada que usa la conexión de datos. De forma predeterminada, se selecciona Asignada por el sistema.
Si selecciona Asignada por el usuario, deberá asignar manualmente una identidad administrada. Si selecciona un usuario que aún no está asignado al clúster, se le asignará automáticamente. Para obtener más información, consulte Configuración de identidades administradas para el clúster de Azure Data Explorer.
Si selecciona Ninguna, la cuenta de almacenamiento y el centro de eventos se autenticarán a través de cadenas de conexión. No se recomienda este método.
Seleccione Crear



Usar la conexión de datos de Event Grid
En esta sección se muestra cómo desencadenar la ingesta desde Azure Blob Storage o Azure Data Lake Gen 2 al clúster después de la creación del blob o el cambio de nombre del blob.
Seleccione la pestaña pertinente en función del tipo de SDK de almacenamiento que se usa para cargar blobs.
En el ejemplo de código siguiente se usa el SDK de Azure Blob Storage para cargar un archivo en Azure Blob Storage. La carga desencadena la conexión de datos de Event Grid, que ingiere los datos en Azure Data Explorer.
var azureStorageAccountConnectionString = <storage_account_connection_string>;
var containerName = <container_name>;
var blobName = <blob_name>;
var localFileName = <file_to_upload>;
var uncompressedSizeInBytes = <uncompressed_size_in_bytes>;
var mapping = <mapping_reference>;
// Create a new container if it not already exists.
var azureStorageAccount = new BlobServiceClient(azureStorageAccountConnectionString);
var container = azureStorageAccount.GetBlobContainerClient(containerName);
container.CreateIfNotExists();
// Define blob metadata and uploading options.
IDictionary<String, String> metadata = new Dictionary<string, string>();
metadata.Add("rawSizeBytes", uncompressedSizeInBytes);
metadata.Add("kustoIngestionMappingReference", mapping);
var uploadOptions = new BlobUploadOptions
{
Metadata = metadata,
};
// Upload the file.
var blob = container.GetBlobClient(blobName);
blob.Upload(localFileName, uploadOptions);
Nota:
Azure Data Explorer no eliminará los blobs con posterioridad a la ingesta. Conserve los blobs de tres a cinco días mediante el ciclo de vida de Azure Blob Storage para administrar la eliminación de blobs.
Nota:
No se admite el desencadenamiento de la ingesta después de una operación CopyBlob para las cuentas de almacenamiento que tienen habilitada la característica de espacio de nombres jerárquico.
Importante
No se recomienda generar eventos de almacenamiento a partir de código personalizado y enviarlos a Event Hubs. Si decide hacerlo, asegúrese de que los eventos producidos cumplen estrictamente el esquema de eventos de almacenamiento y las especificaciones de formato JSON adecuadas.
Eliminar una conexión de datos de Event Grid
Para quitar la conexión de Event Grid desde Azure Portal, siga estos pasos:
- Vaya al clúster. En el menú de la izquierda, seleccione Bases de datos. A continuación, seleccione la base de datos que contiene la tabla de destino.
- En el menú de la izquierda, seleccione Conexiones de datos. A continuación, active la casilla situada junto a la conexión de datos de Event Grid correspondiente.
- Seleccione Eliminar en la barra de menús superior.