Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
La integración continua es el procedimiento de probar cada cambio realizado en el código base automáticamente y tan pronto como sea posible. La entrega continua sigue las pruebas realizadas durante la integración continua y envía los cambios a un sistema de ensayo o producción.
En Azure Data Factory, la integración continua y la entrega (CI/CD) significa mover canalizaciones de Data Factory de un entorno (desarrollo, prueba, producción) a otro. Azure Data Factory utiliza plantillas Azure Resource Manager para almacenar la configuración de las distintas entidades de ADF (canalizaciones, conjuntos de datos, flujos de datos, etc.). Se sugieren dos métodos para promover una factoría de datos a otro entorno:
- Implementación automatizada mediante la integración de Data Factory con Azure Pipelines
- Cargue manualmente una plantilla de Resource Manager mediante la integración de la experiencia de usuario de Data Factory con Azure Resource Manager.
Nota:
Se recomienda usar el módulo Az de PowerShell de Azure para interactuar con Azure. Para empezar, consulte Install Azure PowerShell. Para obtener información sobre cómo migrar al módulo Az PowerShell, consulte Migrate Azure PowerShell de AzureRM a Az.
Ciclo de vida de CI/CD
Nota:
Para más información, consulte Mejoras de implementación continua.
A continuación se muestra información general del ciclo de vida de CI/CD en una factoría de datos de Azure configurada con Azure Repos Git. Para obtener más información sobre cómo configurar un repositorio de Git, consulte control Source en Azure Data Factory.
Se crea una factoría de datos de desarrollo y se configura con Azure Repos Git. Todos los desarrolladores deben tener permiso para autorizar recursos de Data Factory, como canalizaciones y conjuntos de datos.
Un desarrollador crea una rama de características para realizar un cambio. Las confirmaciones firmadas no son compatibles en Data Factory. Depuran sus ejecuciones de canalización con los cambios más recientes. Para obtener más información sobre cómo depurar una ejecución de canalización, consulte Desarrollo iterativo y depuración con Azure Data Factory.
Cuando un desarrollador está satisfecho con los cambios, crea una solicitud de incorporación de cambios desde la rama de características a la rama principal o de colaboración para que otros equipos del mismo nivel revisen sus cambios.
Una vez aprobada una solicitud de incorporación de cambios y los cambios se combinan en la rama principal, los cambios se publican en la factoría de desarrollo.
Cuando el equipo esté listo para implementar los cambios en una fábrica de prueba o UAT (pruebas de aceptación de usuario), el equipo se dirige a su versión de Azure Pipelines e implementa la versión deseada de la factoría de desarrollo en UAT. Esta implementación se realiza como parte de una tarea de Azure Pipelines y usa Resource Manager parámetros de plantilla para aplicar la configuración adecuada.
Una vez comprobados los cambios en la fábrica de pruebas, realice la implementación en la fábrica de producción mediante la siguiente tarea de versión de canalizaciones.
Nota:
Solo la fábrica de desarrollo está asociada a un repositorio de Git. Los generadores de pruebas y producción no deben tener un repositorio git asociado a ellos y solo deben actualizarse a través de una canalización de Azure DevOps o a través de una plantilla de Administración de recursos.
En la imagen siguiente se resaltan los distintos pasos de este ciclo de vida.
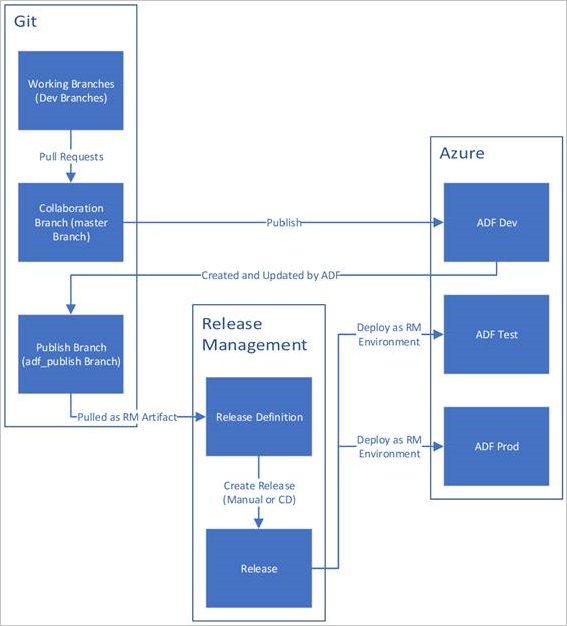
Procedimientos recomendados para CI/CD
Si usa la integración de Git con la factoría de datos y tiene una canalización de CI/CD que mueve los cambios desde el entorno de desarrollo al de prueba y, luego, al de producción, los procedimientos recomendados son los siguientes:
Integración de Git. Configure únicamente tu fábrica de datos de desarrollo con la integración de Git. Los cambios en los entornos de prueba y producción se implementan a través de CI/CD y no se necesita la integración Git.
Script anterior y posterior a la implementación. Antes del paso de implementación de Resource Manager en CI/CD, debe completar determinadas tareas, como detener y reiniciar desencadenadores y realizar la limpieza. Se recomienda usar scripts de PowerShell antes y después de la tarea de implementación. Para más información, vea Actualización de desencadenadores activos. El equipo de Data Factory ha proporcionado el script que se va a usar y que se encuentra en la parte inferior de esta página.
Nota:
Use el PrePostDeploymentScript.Ver2.ps1 si desea desactivar o activar solo los desencadenadores que se han modificado en lugar de activar todos los desencadenadores durante CI/CD.
Advertencia
Asegúrese de usar PowerShell Core en la tarea de ADO para ejecutar el script.
Advertencia
Si no usa las versiones más recientes del módulo de PowerShell y Data Factory, puede que se produzcan errores de deserialización al ejecutarse los comandos.
Entornos de ejecución de integración y uso compartido. Los entornos de ejecución de integración no cambian a menudo y son similares en todas las fases de CI/CD. Por tanto, Data Factory espera que el usuario tenga el mismo nombre, tipo y subtipo de entorno de ejecución de integración en todas las etapas de CI/CD. Si quiere compartir entornos de ejecución de integración en todas las fases, considere la posibilidad de usar una factoría ternaria solo para contener los entornos de ejecución de integración compartidos. Puede usar esta factoría compartida en todos los entornos como un tipo de entorno de ejecución de integración vinculado.
Nota:
El uso compartido del entorno de ejecución de integración solo está disponible para entornos de ejecución de integración autohospedados. Azure-SSIS Integration Runtime no admiten el uso compartido.
Implementación de un punto de conexión privado administrado. Si ya existe un punto de conexión privado en una fábrica y se intenta implementar una plantilla de Resource Manager que contiene un punto de conexión privado con el mismo nombre pero con propiedades modificadas, se produce un error en la implementación. Es decir, se puede implementar correctamente un punto de conexión privado siempre que tenga las mismas propiedades que el que ya existe en la fábrica. Si alguna propiedad difiere entre entornos, se puede invalidar si se parametriza esa propiedad y se proporciona el valor respectivo durante la implementación.
Key Vault. Cuando se usan servicios vinculados cuya información de conexión se almacena en Azure Key Vault, se recomienda mantener almacenes de claves independientes para distintos entornos. También puede configurar niveles de permisos individuales para cada bóveda de claves. Por ejemplo, es posible que no quiera que los miembros del equipo tengan permisos para ver los secretos de producción. Si sigue este enfoque, recomendamos que mantenga los mismos nombres secretos en todas las fases. Si mantiene los mismos nombres secretos, no es necesario parametrizar cada connection string entre entornos de CI/CD porque lo único que cambia es el nombre del almacén de claves, que es un parámetro independiente.
Nomenclatura de recursos. Debido a las restricciones de las plantillas de ARM, pueden surgir problemas en la implementación si los recursos contienen espacios en el nombre. El equipo de Azure Data Factory recomienda usar caracteres "_" o "-" en lugar de espacios para recursos. Por ejemplo, 'Canalización_1' sería un nombre preferible en vez de 'Canalización 1'.
Modificación del repositorio. ADF administra automáticamente el contenido del repositorio GIT. La modificación o adición manual de archivos o carpetas no relacionados en cualquier lugar de la carpeta de datos del repositorio de Git de ADF podría provocar errores de carga de recursos. Por ejemplo, la presencia de archivos .bak puede provocar un error de CI/CD de ADF, por lo que deben eliminarse para permitir que ADF cargue correctamente.
Control de exposición y marcas de características. Cuando se trabaja en equipo, hay casos en los que se pueden combinar los cambios, pero no se desea que se ejecuten en entornos con privilegios elevados, como PROD y QA. Para abordar este escenario, el equipo de ADF recomienda el concepto de DevOps de uso de marcas de características. En ADF, puede combinar parámetros globales y la actividad de la condición if para ocultar conjuntos de lógica basados en estas marcas de entorno.
Para información sobre cómo configurar una marca de características, vea el siguiente tutorial en vídeo:
Características no admitidas
Por diseño, Data Factory no permite la selección exclusiva de confirmaciones ni la publicación selectiva de recursos. Las publicaciones incluirán todos los cambios realizados en la factoría de datos.
- Las entidades de Data Factory dependen unas de otras. Por ejemplo, los desencadenadores dependen de las tuberías, y las tuberías dependen de los conjuntos de datos y de otras tuberías. La publicación selectiva de un subconjunto de recursos podría provocar comportamientos y errores inesperados.
- En casos excepcionales, cuando necesite la publicación selectiva, considere la posibilidad de usar una revisión. Para más información, vea Entorno de producción de hotfix.
El equipo de Azure Data Factory no recomienda asignar controles RBAC de Azure a entidades individuales (canalizaciones, conjuntos de datos, etc.) en una fábrica de datos. Por ejemplo, si un desarrollador tiene acceso a una canalización o un conjunto de datos, debe poder acceder a todas las canalizaciones o conjuntos de datos de la factoría de datos. Si cree que necesita implementar muchos roles de Azure dentro de una factoría de datos, examine la implementación de una segunda factoría de datos.
No puedes publicar desde ramas privadas.
En la actualidad no se pueden hospedar proyectos en Bitbucket.
Actualmente no se pueden exportar ni importar alertas y matrices como parámetros.
Las plantillas parciales de ARM de la rama de publicación ya no se admiten a partir del 1 de noviembre de 2021. Si el proyecto ha usado esta característica, cambie a un mecanismo compatible para las implementaciones mediante: archivos
ARMTemplateForFactory.jsonolinkedTemplates.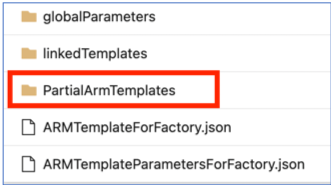
Contenido relacionado
- Mejoras de implementación continua
- Automatización de la integración continua mediante versiones de Azure Pipelines
- Promover manualmente una plantilla de Resource Manager a cada entorno
- Utilice parámetros personalizados con una plantilla de Resource Manager
- Plantillas enlazadas de Resource Manager
- Uso de un entorno de producción de parche rápido
- Script de ejemplo anterior y posterior a la implementación