Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Los flujos de datos están disponibles tanto en canalizaciones de Azure Data Factory como en canalizaciones de Azure Synapse Analytics. Este artículo se aplica a los flujos de datos de mapeo. Si no está familiarizado con las transformaciones, consulte el artículo introductorio Transformación de datos mediante flujos de datos de asignación.
Sugerencia
Para obtener la transformación equivalente (Elegir columnas) en Dataflow Gen2, consulte Una guía de Dataflow Gen2 para asignar usuarios de flujo de datos.
Utilice la transformación de selección para cambiar el nombre, eliminar o reordenar las columnas. Esta transformación no modifica los datos de fila, pero elige qué columnas se propagan hacia abajo.
En una transformación Selección, los usuarios pueden especificar asignaciones fijas, usar patrones para realizar la asignación basada en reglas o habilitar la asignación automática. Las asignaciones fijas y basadas en reglas se pueden usar en la misma transformación Selección. Si una columna no coincide con una de las asignaciones definidas, se quitará.
Asignación fija
Si hay menos de 50 columnas definidas en la proyección, todas las columnas definidas tendrán una asignación fija de forma predeterminada. Una asignación fija toma una columna de entrada definida y le asigna un nombre exacto.
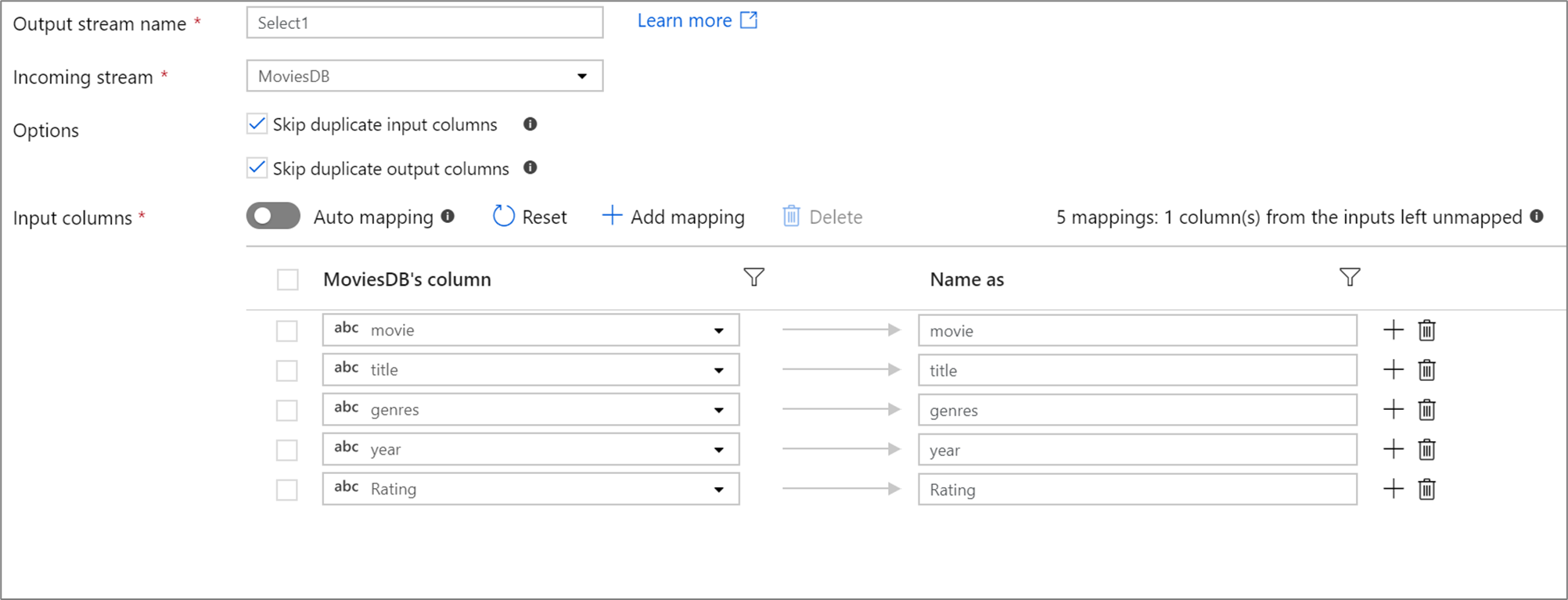
Nota
No puede asignar ni cambiar el nombre de una columna desviada mediante un mapeo fijo
Asignación de columnas jerárquicas
Las asignaciones fijas se pueden usar para asignar una subcolumna de una columna jerárquica a una columna de nivel superior. Si tiene una jerarquía definida, use la lista desplegable de columnas para seleccionar una subcolumna. La transformación de selección creará una columna nueva con el valor y el tipo de datos del subcolumna.
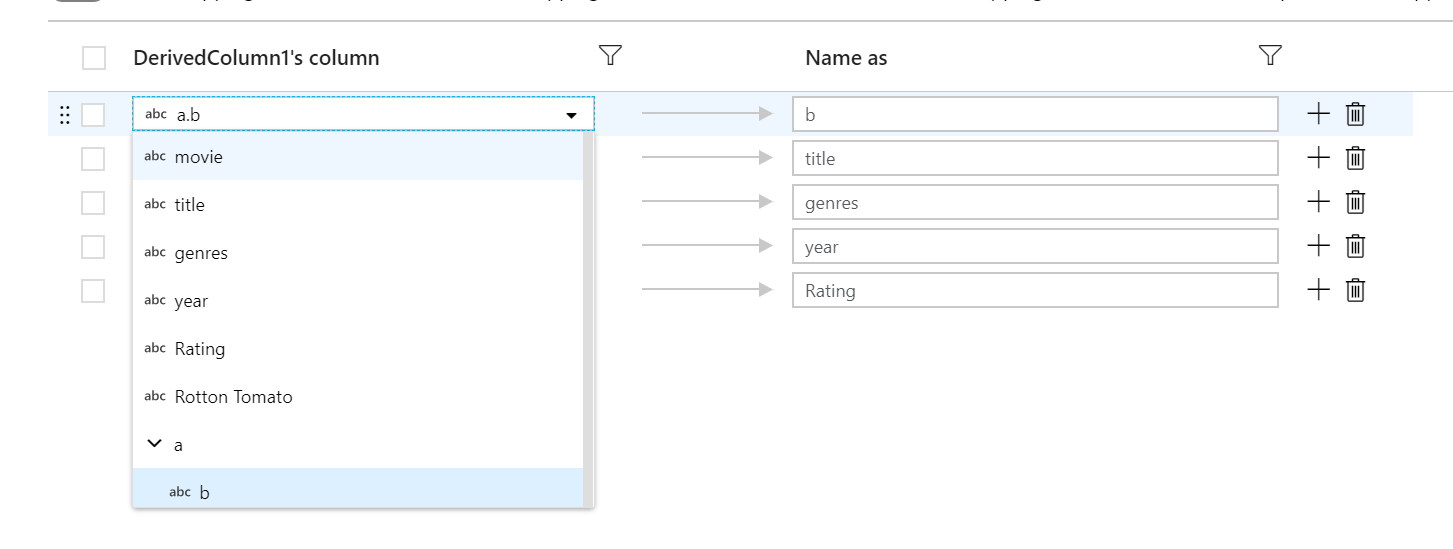
Asignación basada en reglas
Si desea asignar muchas columnas a la vez o pasar las columnas desfasadas a un nivel inferior, use la asignación basada en reglas para definir las asignaciones mediante patrones de columna. Coincidencia basada en los valores name, type, stream y position de las columnas. Puede usar cualquier combinación de asignaciones basadas en reglas y fijas. De forma predeterminada, todas las proyecciones con más de 50 columnas tendrán como valor predeterminado una asignación basada en reglas que coincida con todas las columnas y que genere el nombre insertado.
Para agregar una asignación basada en reglas, haga clic en Agregar asignación y seleccione Rule based mapping (Asignación basada en reglas).

Cada asignación basada en reglas requiere dos entradas: la condición por la que buscar coincidencias y el nombre de cada columna asignada. Ambos valores se insertaron a través del generador de expresiones. En el cuadro de expresión de la izquierda, escriba la condición de coincidencia booleana. En el cuadro de expresión de la derecha, especifique a qué se asignará la columna coincidente.

Use la sintaxis de $$ para hacer referencia al nombre de entrada de una columna coincidente. Utilizando la imagen anterior como ejemplo, supongamos que un usuario desea buscar coincidencias en todas las columnas de cadena cuyos nombres tengan menos de seis caracteres. Si una columna de entrada se denomina test, la expresión $$ + '_short' cambiará el nombre de la columna test_short. Si este es el único mapeo que existe, todas las columnas que no cumplan la condición serán eliminadas de los datos resultantes.
Los patrones coinciden con las columnas desfasadas y definidas. Para ver qué columnas definidas están asignadas mediante una regla, haga clic en el icono de las gafas junto a la regla. Compruebe la salida mediante la vista previa de los datos.
Mapeo de regex
Si hace clic en el icono del botón de contenido adicional hacia abajo, puede especificar una condición de asignación de regex. Una condición de mapeo de regex coincide con todos los nombres de columna que cumplen con la condición regex especificada. Se puede usar en combinación con las asignaciones estándar basadas en reglas.

El ejemplo anterior coincide con el patrón regex (r) o cualquier nombre de columna que contenga un "r" en minúscula. De forma similar a la asignación basada en reglas estándar, todas las columnas coincidentes se modifican por la condición de la derecha con $$ sintaxis.
Si tiene múltiples coincidencias de regex en el nombre de columna, puede referirse a coincidencias específicas mediante $n, donde "n" indica a cuál coincidencia se refiere. Por ejemplo, "$2" hace referencia a la segunda coincidencia de un nombre de columna.
Jerarquías basadas en reglas
Si la proyección definida tiene una jerarquía, puede usar la asignación basada en reglas para asignar las subcolumnas de las jerarquías. Especifique una condición de correspondencia y la columna compleja cuyas subcolumnas desee vincular. Todas las subcolumnas coincidentes se mostrarán utilizando la regla 'Nombre como' especificada a la derecha.
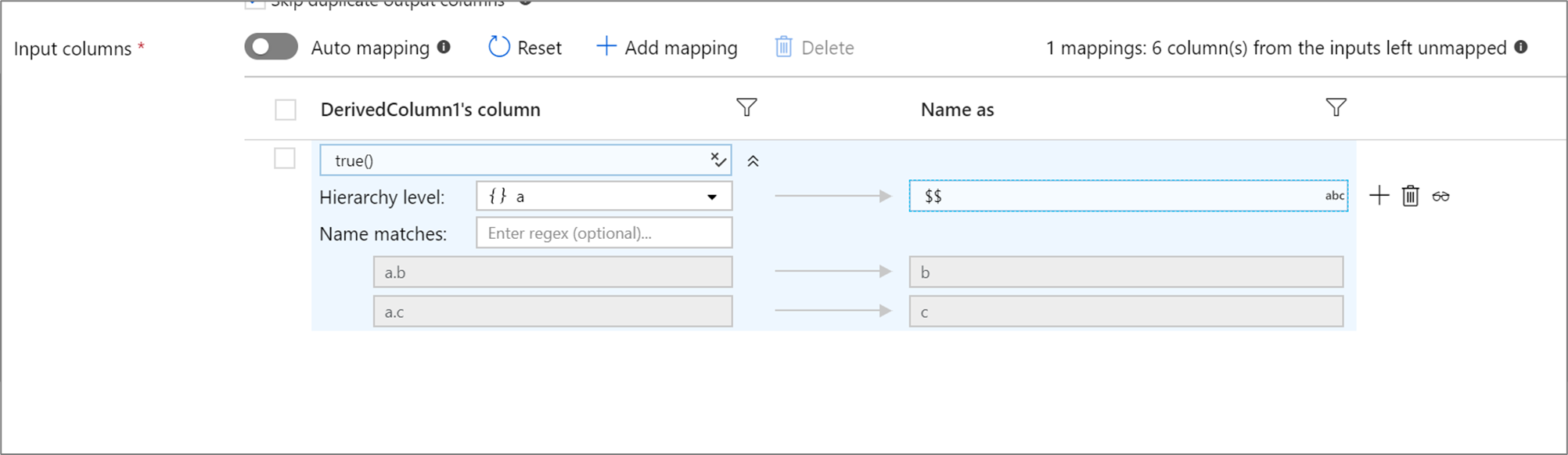
El ejemplo anterior coincide con todas las subcolumnas de la columna compleja a.
a contiene dos subcolumnas b y c. El esquema de salida incluirá dos columnas b y c, ya que la condición para asignar un nombre de salida es $$.
Parametrización
Puede parametrizar mediante asignación basada en reglas los nombres de las columnas. Use la palabra clave name para hacer coincidir los nombres de columna de entrada con un parámetro. Por ejemplo, si tiene un parámetro de flujo de datos mycolumn, puede crear una regla que coincida con cualquier nombre de columna que sea igual a mycolumn. Puede cambiar el nombre de la columna coincidente por una cadena codificada de forma rígida, como "clave empresarial", y hacer referencia a esta explícitamente. En este ejemplo, la condición de coincidencia es name == $mycolumn y la condición de nombre es "clave empresarial".
Asignación automática
Al agregar una transformación Selección, para habilitar la opción Asignación automática se puede cambiar el control deslizante de Asignación automática. Con la asignación automática, la transformación Selección asigna todas las columnas de entrada, excepto las duplicadas, con el mismo nombre que su entrada. Se incluirán las columnas desviadas, lo que significa que los datos de salida pueden contener columnas no definidas en el esquema. Para obtener más información sobre las columnas desfasadas, consulte Desfase de esquema.
Con la asignación automática activada, la transformación Selección respetará la configuración para omitir duplicados y proporcionará un nuevo alias para las columnas existentes. La asignación de alias es útil cuando se realizan varias combinaciones o búsquedas en el mismo flujo y en escenarios de autocombinación.
Columnas duplicadas
De forma predeterminada, la transformación Selección quita las columnas duplicadas en ambas proyecciones de entrada y de salida. Las columnas de entrada duplicadas suelen provenir de las transformaciones Combinación y Búsqueda, en las que los nombres de columna se duplican en cada lado de la combinación. Pueden producirse columnas de salida duplicadas si se asignan dos columnas de entrada diferentes al mismo nombre. Active o desactive la casilla de verificación según si desea quitar o pasar las columnas duplicadas.
Ordenación de columnas
El orden de las asignaciones determina el orden de las columnas de salida. Si una columna de entrada se asigna varias veces, solo se respetará la primera asignación. Si se quita alguna columna duplicada, se conservará la primera coincidencia.
Script de flujo de datos
Sintaxis
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Ejemplo
A continuación se muestra un ejemplo de mapa de selección y su script de flujo de datos:
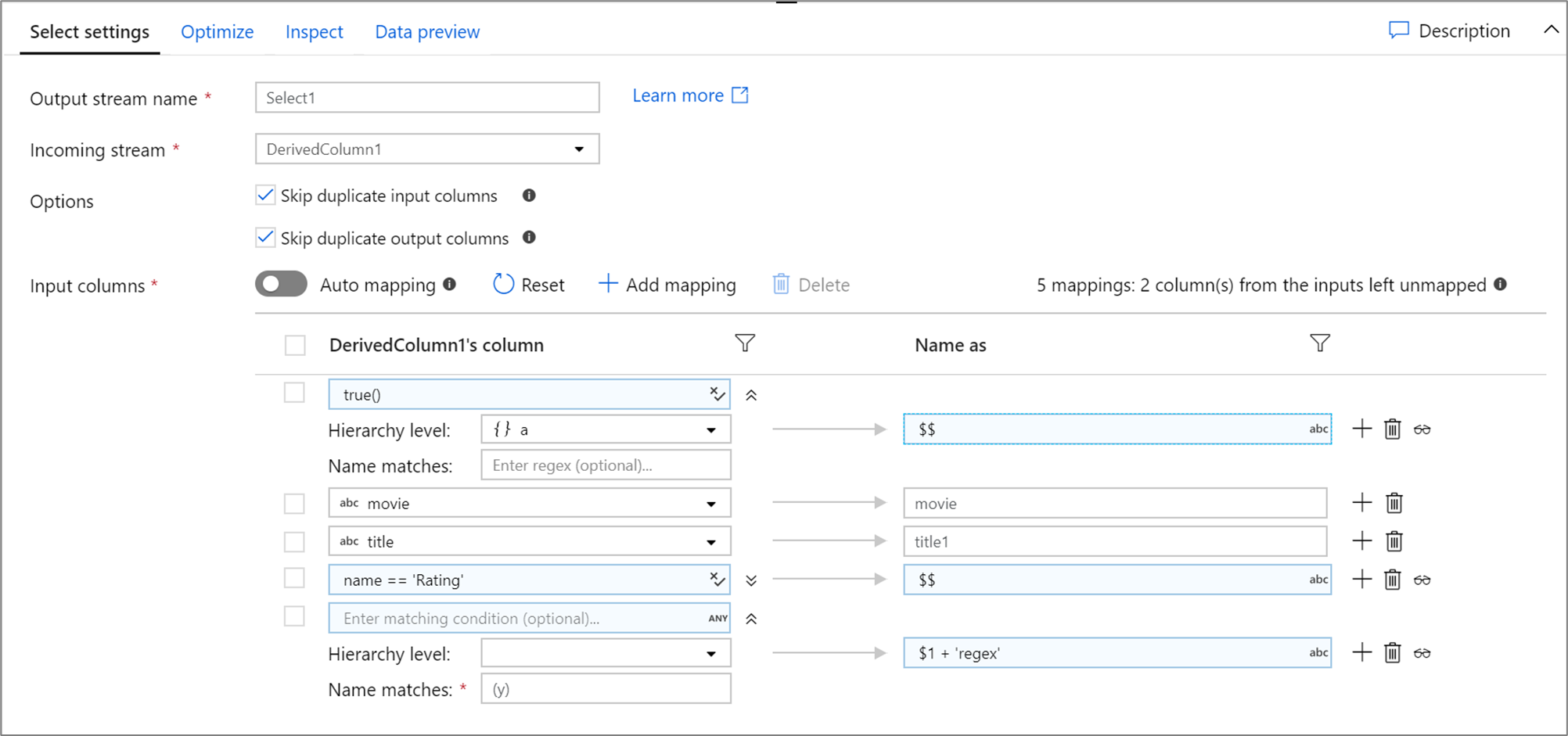
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Contenido relacionado
- Después de usar Selección para cambiar el nombre de las columnas, reordenarlas y crear alias, use la transformación del receptor para enviar los datos a un almacén de datos.