Copia diferencial desde una base de datos con una tabla de control
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se describe una plantilla que está disponible para cargar filas nuevas o actualizadas de forma incremental desde una tabla de base de datos en Azure mediante una tabla de control externa que almacena un valor de límite máximo.
Esta plantilla requiere que el esquema de la base de datos de origen contenga una columna de marca de tiempo o una clave de incremento para identificar las filas nuevas o actualizadas.
Nota
Si tiene una columna de marca de tiempo en su base de datos de origen para identificar las filas nuevas o actualizadas, pero no desea crear una tabla de control externa para usarla para la copia diferencial, puede utilizar en su lugar la herramienta Copiar datos de Azure Data Factory para obtener una canalización. Esa herramienta usa una hora programada por el desencadenador como variable para leer las nuevas filas desde la base de datos de origen.
Acerca de esta plantilla de solución
Esta plantilla recupera primero el valor de límite anterior y lo compara con el actual. Después, solo copia los cambios de la base de datos de origen, según una comparación entre dos valores de límite. Por último, almacena el nuevo valor de límite máximo en una tabla de control externa para la carga de datos diferencial de la próxima vez.
La plantilla contiene cuatro actividades:
- Búsqueda recupera el valor de límite máximo anterior, el cual se almacena en una tabla de control externa.
- Otra actividad de búsqueda recupera el valor de límite máximo actual de la base de datos de origen.
- Copia copia solo los cambios de la base de datos de origen en el almacén de destino. La consulta que identifica los cambios de la base de datos de origen es similar a "SELECT * FROM Data_Source_Table WHERE TIMESTAMP_Column > “last high-watermark” and TIMESTAMP_Column <= “current high-watermark”".
- SqlServerStoredProcedure escribe el valor de límite máximo actual en una tabla de control externa para la copia diferencial de la próxima vez.
La plantilla define los parámetros siguientes:
- Data_Source_Table_Name es la tabla de la base de datos de origen de donde desea cargar los datos.
- Data_Source_WaterMarkColumn es el nombre de columna en la tabla de origen que se usa para identificar las filas nuevas o actualizadas. El tipo de esta columna suele ser datetime, INT o similar.
- Data_Destination_Container es la ruta de acceso raíz del lugar donde los datos se copian en el almacén de destino.
- Data_Destination_Directory es la ruta de acceso del directorio en la raíz del lugar donde los datos se copian en el almacén de destino.
- Data_Destination_Table_Name es el lugar en el que se copian los datos en el almacén de destino (aplicable cuando se selecciona "Azure Synapse Analytics" como destino de los datos).
- Data_Destination_Folder_Path es el lugar en el que se copian los datos en el almacén de destino (aplicable cuando se selecciona "Sistema de archivos" o "Azure Data Lake Storage Gen1" como destino de los datos).
- Control_Table_Table_Name es la tabla de control externa que almacena el valor de límite máximo.
- Control_Table_Column_Name es la columna en la tabla de control externa que almacena el valor de límite máximo.
Uso de esta plantilla de solución
Explore la tabla de origen que desea cargar y defina la columna de límite máximo que puede usarse para identificar las filas nuevas o actualizadas. El tipo de esta columna podría ser datetime, INT o similar. El valor de esta columna aumenta a medida que se agregan nuevas filas. En la siguiente tabla de origen de ejemplo (data_source_table), podemos usar la columna LastModifytime como la columna de límite máximo.
PersonID Name LastModifytime 1 aaaa 2017-09-01 00:56:00.000 2 bbbb 2017-09-02 05:23:00.000 3 cccc 2017-09-03 02:36:00.000 4 dddd 2017-09-04 03:21:00.000 5 eeee 2017-09-05 08:06:00.000 6 fffffff 2017-09-06 02:23:00.000 7 gggg 2017-09-07 09:01:00.000 8 hhhh 2017-09-08 09:01:00.000 9 iiiiiiiii 2017-09-09 09:01:00.000Cree una tabla de control en SQL Server o Azure SQL Database para almacenar el valor de límite máximo para cargar los datos diferenciales. En el siguiente ejemplo, el nombre de la tabla de control es watermarktable. En esta tabla, WatermarkValue es la columna que almacena el valor de límite máximo y su tipo es datetime.
create table watermarktable ( WatermarkValue datetime, ); INSERT INTO watermarktable VALUES ('1/1/2010 12:00:00 AM')Cree un procedimiento almacenado en la misma instancia de SQL Server o Azure SQL Database que utiliza para crear la tabla de control. El procedimiento almacenado se utiliza para escribir el nuevo valor de límite máximo en la tabla de control externa para la carga de datos diferencial de la próxima vez.
CREATE PROCEDURE update_watermark @LastModifiedtime datetime AS BEGIN UPDATE watermarktable SET [WatermarkValue] = @LastModifiedtime ENDVaya a la plantilla Copia diferencial desde base de datos. Cree una nueva conexión a la base de datos de origen desde la que desea copiar datos.
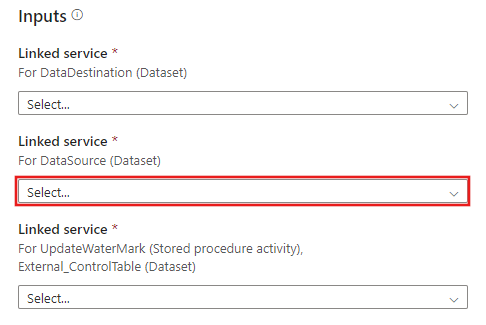
Cree una nueva conexión al almacén de datos de destino en el que desea copiar los datos.
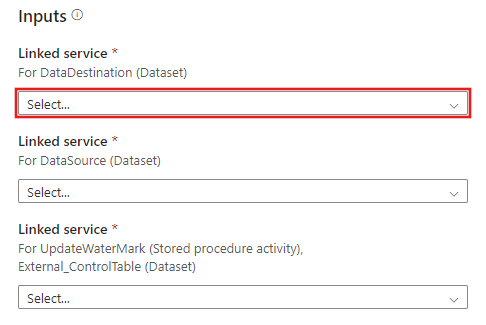
Cree una nueva conexión a la tabla de control externa y al procedimiento almacenado que ha creado en los pasos 2 y 3.
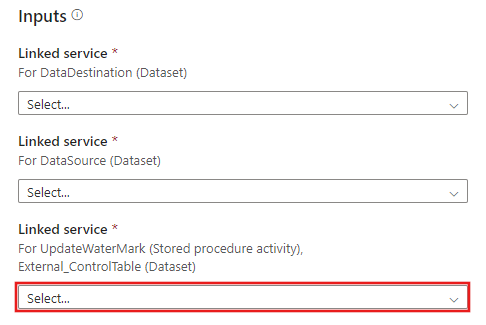
Seleccione Usar esta plantilla.
Verá la canalización disponible, como se muestra en el ejemplo siguiente:
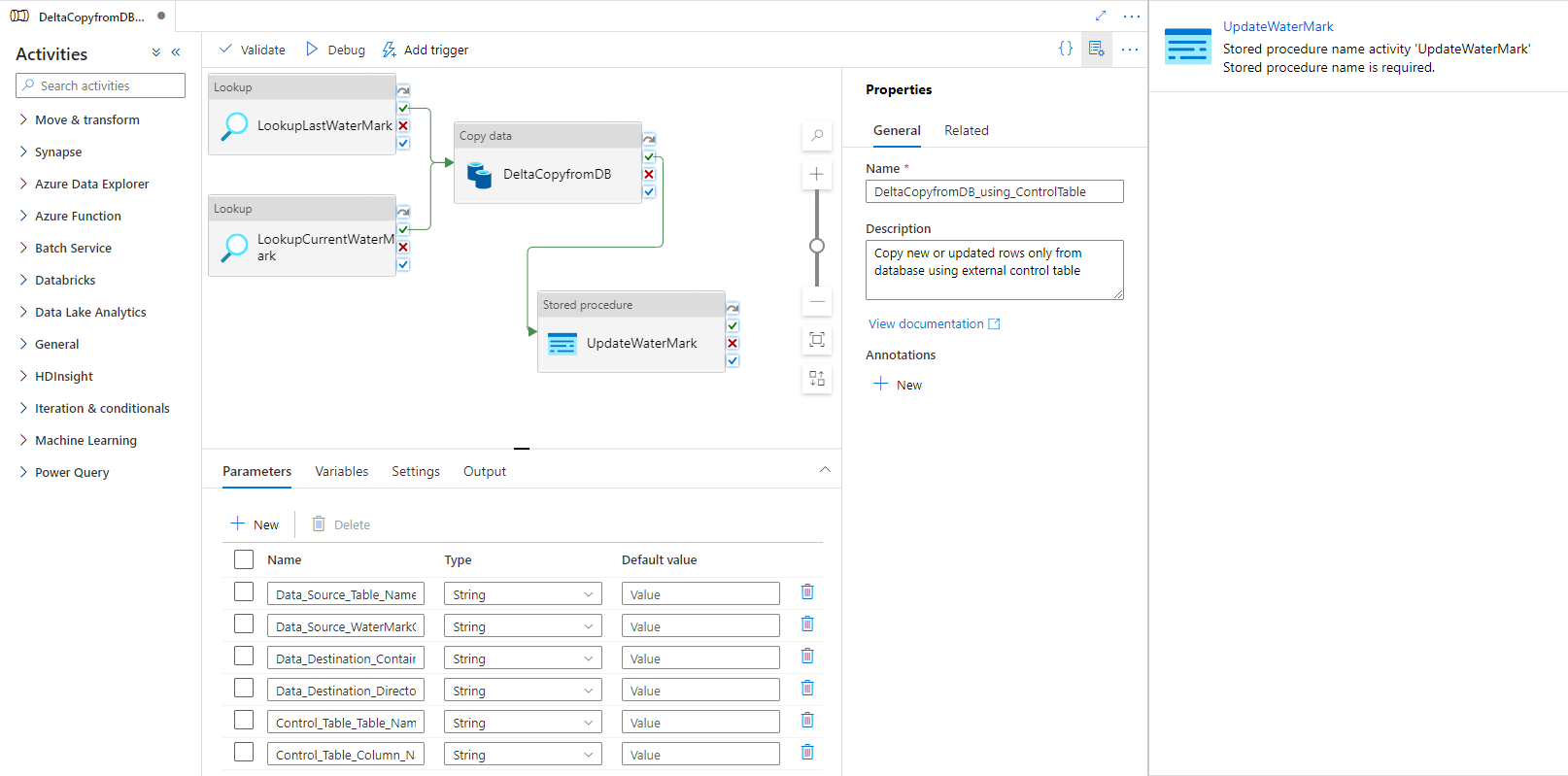
Seleccione Procedimiento almacenado. En Nombre del procedimiento almacenado, elija [dbo].[update_watermark] . Seleccione Importar parámetro y, a continuación, seleccione Agregar contenido dinámico.
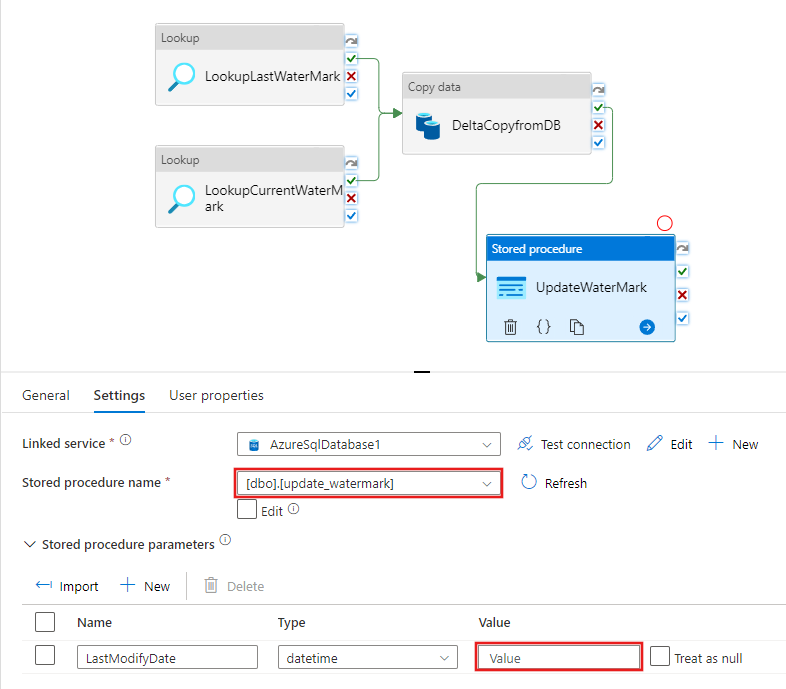
Escriba el contenido {activity('LookupCurrentWaterMark').output.firstRow.NewWatermarkValue} y, a continuación, seleccione Finalizar.
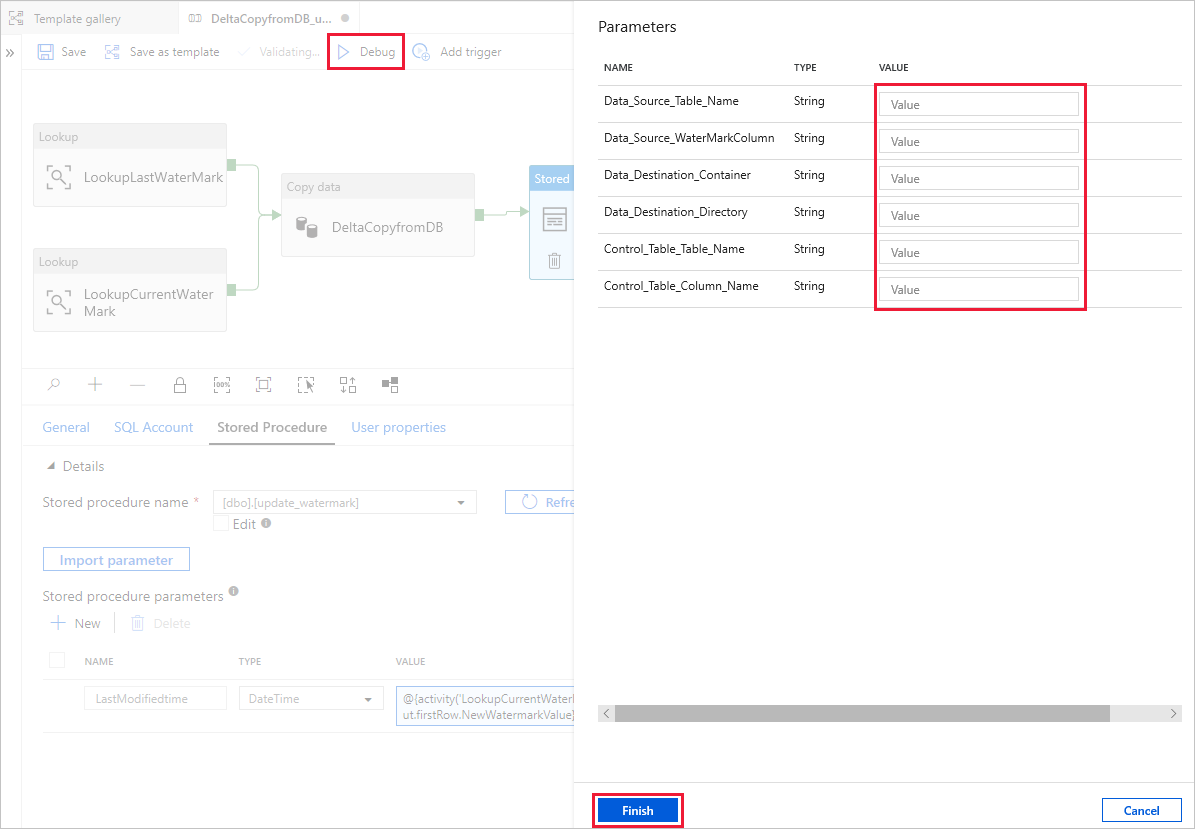
Seleccione Depurar, escriba los parámetros y, a continuación, seleccione Finalizar.
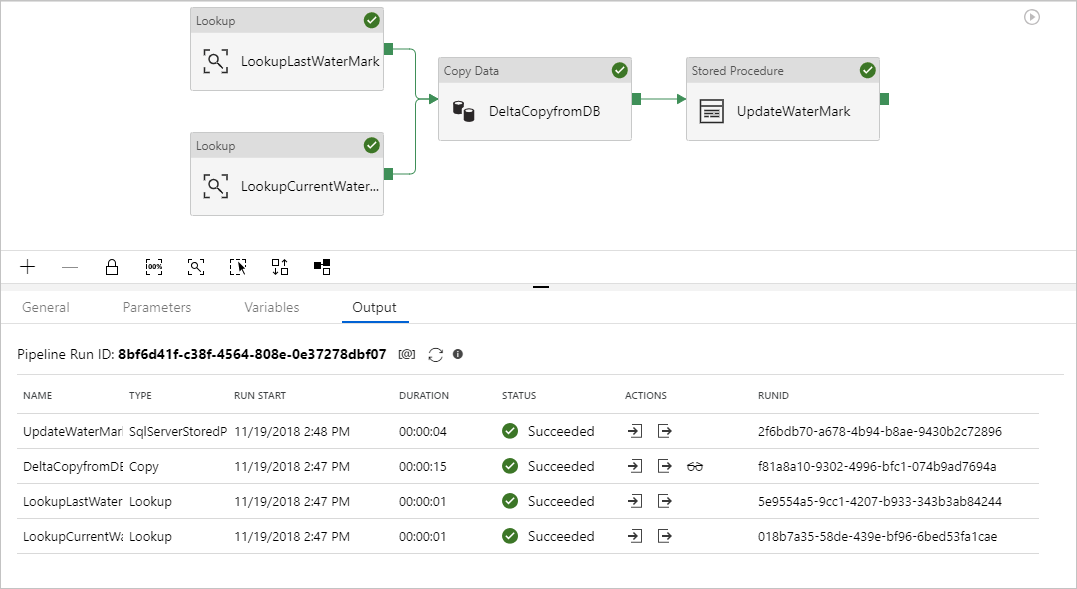
Se muestran resultados similares a los del ejemplo siguiente:
Puede crear nuevas filas en la tabla de origen. Este es el lenguaje SQL de ejemplo para crear nuevas filas:
INSERT INTO data_source_table VALUES (10, 'newdata','9/10/2017 2:23:00 AM') INSERT INTO data_source_table VALUES (11, 'newdata','9/11/2017 9:01:00 AM')Para volver a ejecutar la canalización, seleccione Depurar, escriba los parámetros y, a continuación, seleccione Finalizar.
Verá que solo se copiaron en el destino las filas nuevas.
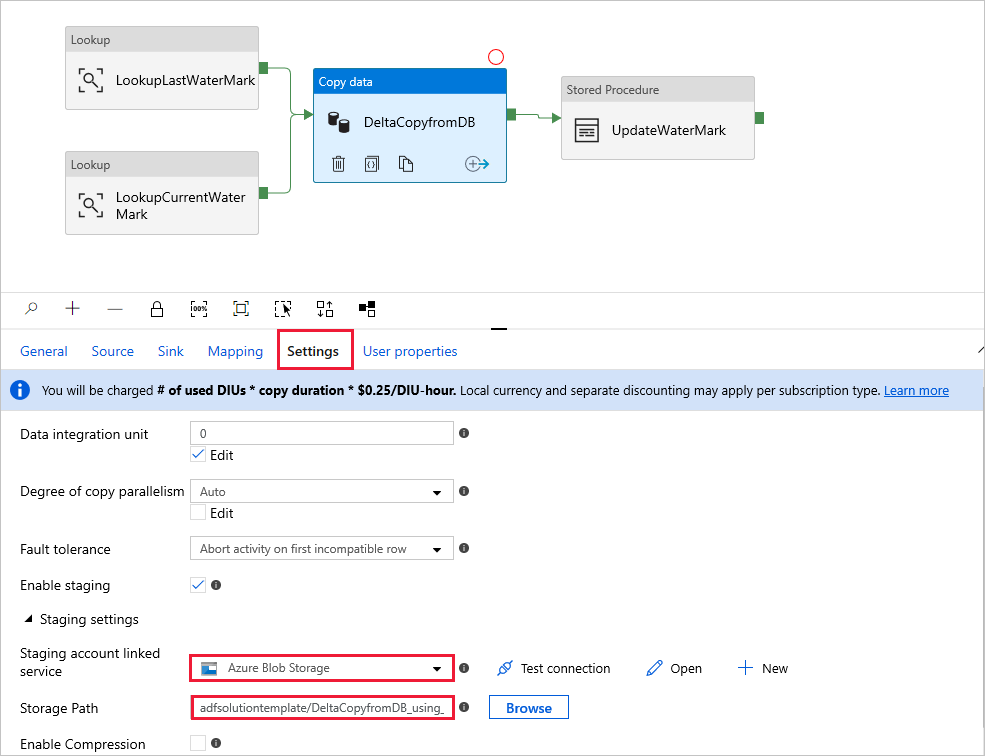
(Opcional): Si selecciona Azure Synapse Analytics como destino de datos, también debe proporcionar una conexión a una instancia de Azure Blob Storage como almacenamiento provisional, porque así lo requiere Polybase de Azure Synapse Analytics. La plantilla generará una ruta de acceso del contenedor automáticamente. Después de la ejecución de la canalización, compruebe si el contenedor se ha creado en Blob Storage.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de