Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Una canalización en un área de trabajo de Azure Data Factory o Synapse Analytics procesa los datos de los servicios de almacenamiento vinculados mediante el uso de servicios de proceso vinculados. Contiene una secuencia de actividades donde cada actividad realiza una operación de procesamiento específica. En este artículo se describe la actividad de U-SQL de Data Lake Analytics que ejecuta un script U-SQL en un Azure Data Lake Analytics servicio vinculado de cómputo.
Cree una cuenta de Azure Data Lake Analytics antes de crear una canalización con una actividad de Data Lake Analytics U-SQL. Para obtener información sobre Azure Data Lake Analytics, consulte
Adición de una actividad de U-SQL para Azure Data Lake Analytics a una canalización con interfaz de usuario
Para usar una actividad de U-SQL para Azure Data Lake Analytics en una canalización, complete los pasos siguientes:
Busque Data Lake en el panel Actividades de canalización y arrastre una actividad de U-SQL al lienzo de la canalización.
Seleccione la nueva actividad de U-SQL en el lienzo si aún no está seleccionada.
Seleccione la pestaña ADLA Account para seleccionar o crear un nuevo servicio vinculado Azure Data Lake Analytics que se usará para ejecutar la actividad de U-SQL.
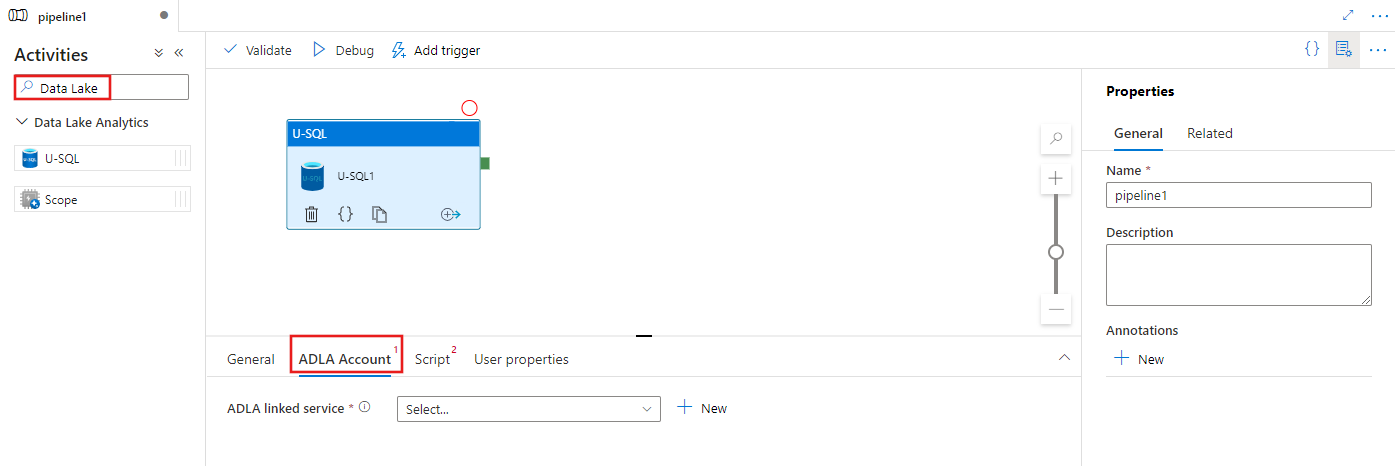
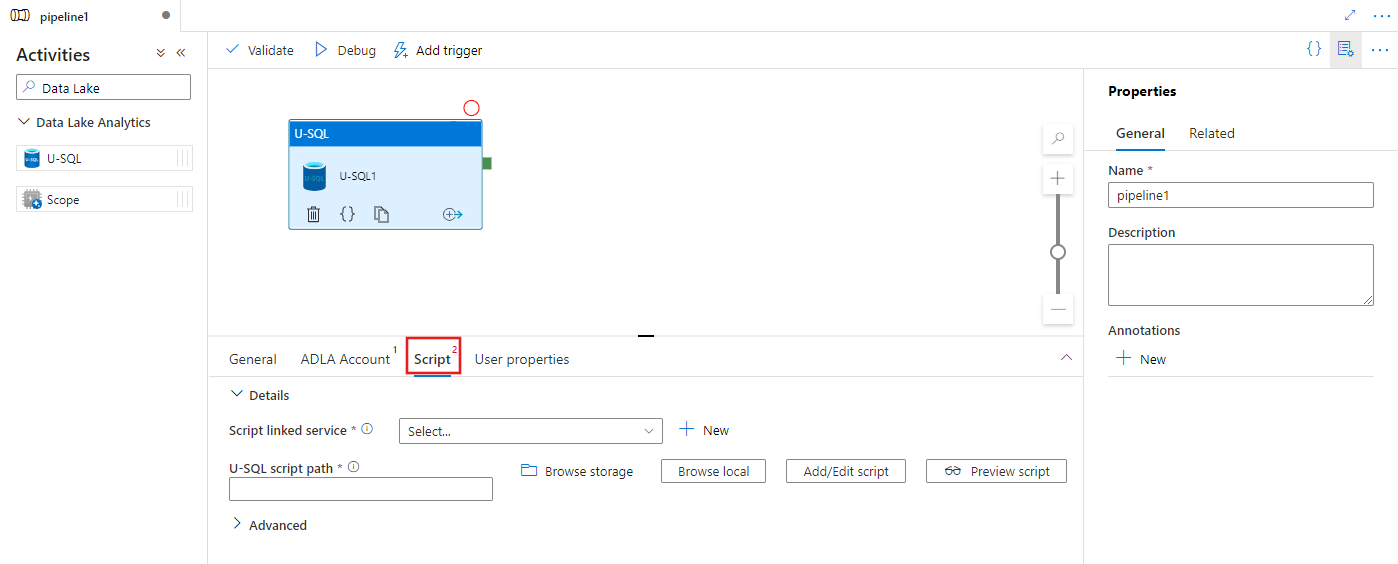
Seleccione la pestaña Script para seleccionar o crear un servicio vinculado de almacenamiento y una ruta de acceso dentro de la ubicación de almacenamiento, que hospedará el script.
Servicio vinculado de Azure Data Lake Analytics
Cree un servicio vinculado Azure Data Lake Analytics para vincular un servicio de proceso de Azure Data Lake Analytics a un área de trabajo de Azure Data Factory o Synapse Analytics. La actividad de U-SQL de Data Lake Analytics de la canalización hace referencia a este servicio vinculado.
En la siguiente tabla se ofrecen descripciones de las propiedades genéricas que se usan en la definición de JSON.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| tipo | La propiedad type se debe establecer en: AzureDataLakeAnalytics. | Sí |
| accountName | Nombre de cuenta de Azure Data Lake Analytics. | Sí |
| dataLakeAnalyticsUri | URI de Azure Data Lake Analytics. | No |
| subscriptionId | identificador de suscripción de Azure | No |
| resourceGroupName | Nombre del grupo de recursos de Azure | No |
Autenticación de entidad de servicio
El servicio vinculado de Azure Data Lake Analytics requiere una autenticación de entidad de servicio para conectarse al servicio Azure Data Lake Analytics. Para usar la autenticación de la entidad de servicio, registre una entidad de aplicación en Microsoft Entra ID y concédale acceso a Data Lake Analytics y al almacén de Data Lake Store que utiliza. Consulte Autenticación entre servicios para ver los pasos detallados. Anote los siguientes valores; los usará para definir el servicio vinculado:
- Identificador de aplicación
- Clave de la aplicación
- Id. de inquilino
Conceda permiso de entidad de servicio a su instancia de Azure Data Lake Analytics mediante el Asistente para agregar usuarios.
Para usar la autenticación de la entidad de servicio, especifique las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| servicePrincipalId | Especifique el id. de cliente de la aplicación. | Sí |
| servicePrincipalKey | Especifique la clave de la aplicación. | Sí |
| inquilino | Especifique la información del tenant (nombre de dominio o identificador de tenant) donde se encuentra la aplicación. Para recuperarlo, mantenga el mouse en la esquina superior derecha del portal de Azure. | Sí |
Ejemplo: Autenticación de entidad de servicio
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Para más información sobre el servicio vinculado, consulte Servicios vinculados de Compute.
Actividad de U-SQL de Data Lake Analytics
El siguiente fragmento de código JSON define una canalización con una actividad de Data Lake Analytics U-SQL. La definición de actividad tiene una referencia al servicio vinculado Azure Data Lake Analytics que creó anteriormente. Para ejecutar un script U-SQL en Data Lake Analytics, el servicio envía el script especificado a Data Lake Analytics, donde las entradas y salidas necesarias se definen en el script para que Data Lake Analytics captura y genera.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
En la tabla siguiente se describen los nombres y descripciones de las propiedades que son específicas de esta actividad.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| nombre | Nombre de la actividad en la canalización | Sí |
| descripción | Texto que describe para qué se usa la actividad. | No |
| tipo | Para Data Lake Analytics actividad U-SQL, el tipo de actividad es DataLakeAnalyticsU-SQL. | Sí |
| nombreDelServicioVinculado | Servicio vinculado a Azure Data Lake Analytics. Para obtener más información sobre este servicio vinculado, consulte el artículo Servicios vinculados de cómputo. | Sí |
| scriptPath | Ruta de acceso a la carpeta que contiene el script U-SQL. El nombre del archivo distingue mayúsculas de minúsculas. | Sí |
| scriptLinkedService | Servicio vinculado que vincula el Azure Data Lake Store o Azure Storage que contiene el script | Sí |
| gradoDeParalelismo | Número máximo de nodos que se usará de forma simultánea para ejecutar el trabajo. | No |
| prioridad | Determina qué trabajos de todos los están en cola deben seleccionarse para ejecutarse primero. Cuanto menor sea el número, mayor será la prioridad. | No |
| parámetros | Parámetros para pasar al script de U-SQL. | No |
| runtimeVersion | Versión en tiempo de ejecución del motor de U-SQL que se usará. | No |
| compilationMode | Modo de compilación de U-SQL. Debe ser uno de los valores siguientes: Semantic: solo realiza comprobaciones semánticas y comprobaciones de integridad necesarias. Full: realiza la compilación completa (comprobación de sintaxis, optimización, generación de código, etc.), SingleBox: realiza la compilación completa, con la opción TargetType establecida en SingleBox. Si no se especifica ningún valor para esta propiedad, el servidor determina el modo de compilación óptimo. |
No |
Para ver la definición del script, consulte SearchLogProcessing.txt.
Script U-SQL de ejemplo
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
En el ejemplo anterior de script, la entrada y salida del script se definen en los parámetros @in y @out. El servicio pasa dinámicamente los valores de los parámetros @in y @out en el script de U-SQL usando la sección "parámetros".
Puede especificar otras propiedades, como degreeOfParallelism y prioridad, también en la definición de la canalización para los trabajos que se ejecutan en el servicio de Azure Data Lake Analytics.
Parámetros dinámicos
En la definición de canalización de ejemplo, se asignan los parámetros in y out con valores codificados de forma rígida.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
Es posible usar los parámetros dinámicos en su lugar. Por ejemplo:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
En este caso, los archivos de entrada se siguen tomando de la carpeta /datalake/input; los de salida se generan en la carpeta /datalake/output. Los nombres de archivo son dinámicos en función del tiempo de inicio de ventana que se pasa cuando se desencadena la canalización.
Contenido relacionado
Vea los siguientes artículos, en los que se explica cómo transformar datos de otras maneras: