Ejecución de un cuaderno de Databricks con la actividad Notebook de Databricks en Azure Data Factory
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, va a utilizar Azure Portal para crear una canalización de Azure Data Factory que ejecuta un cuaderno de Databricks en el clúster de trabajos de Databricks. También pasa parámetros de Azure Data Factory al cuaderno de Databricks durante la ejecución.
En este tutorial, realizará los siguientes pasos:
Creación de una factoría de datos.
Cree una canalización que utiliza la actividad Notebook de Databricks.
Desencadenamiento de una ejecución de la canalización
Supervisión de la ejecución de la canalización
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Si desea una introducción y demostración de once minutos de esta característica, vea el siguiente vídeo:
Prerrequisitos
- Área de trabajo de Azure Databricks. Cree un área de trabajo de Databricks o use una existente. Va a crear un cuaderno de Python en el área de trabajo de Azure Databricks. Después, va a ejecutar el cuaderno y le pasará parámetros mediante Azure Data Factory.
Crear una factoría de datos
Inicie el explorador web Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
Seleccione Crear un recurso en el menú de Azure Portal, después, Integración y Data Factory.
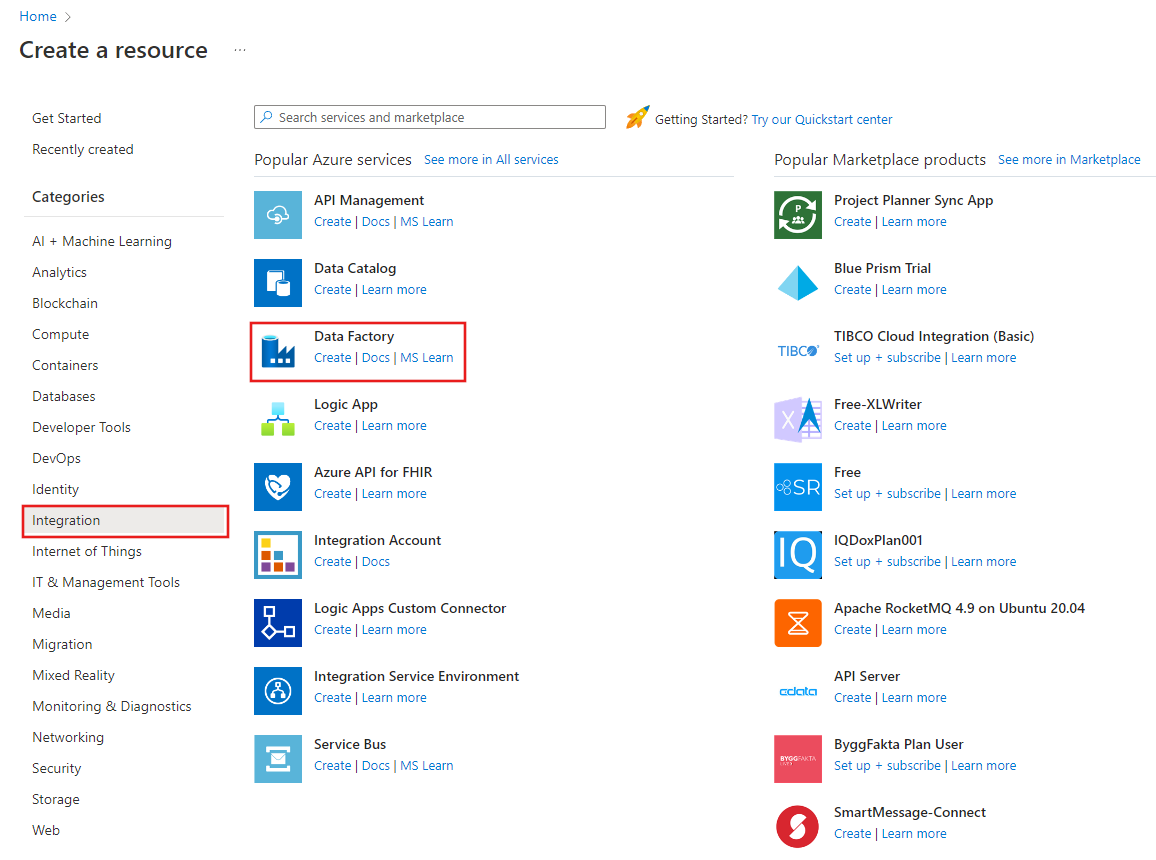
En la página Create Data Factory (Crear factoría de datos), en la pestaña Aspectos básicos, seleccione su suscripción de Azure en la que desea crear la factoría de datos.
Para Grupo de recursos, realice uno de los siguientes pasos:
Seleccione un grupo de recursos existente de la lista desplegable.
Seleccione Crear nuevo y escriba el nombre de un nuevo grupo de recursos.
Para obtener más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
En Región, seleccione la ubicación de la factoría de datos.
En la lista solo se muestran las ubicaciones que admite Data Factory y dónde se almacenarán los metadatos de Azure Data Factory. Los almacenes de datos asociados (como Azure Storage y Azure SQL Database) y los procesos (como Azure HDInsight) que usa Data Factory se pueden ejecutar en otras regiones.
En Nombre, escriba ADFTutorialDataFactory.
El nombre de la instancia de Azure Data Factory debe ser único de forma global. Si ve el siguiente error, cambie el nombre de la factoría de datos (por ejemplo, use <suNombre>ADFTutorialDataFactory). Para conocer las reglas de nomenclatura de los artefactos de Data Factory, consulte el artículo Azure Data Factory: reglas de nomenclatura.
En Versión, seleccione V2.
Seleccione Siguiente: Configuración de Git y, después, seleccione la casilla Configurar Git más adelante.
Seleccione Revisar y crear y elija Crear una vez superada la validación.
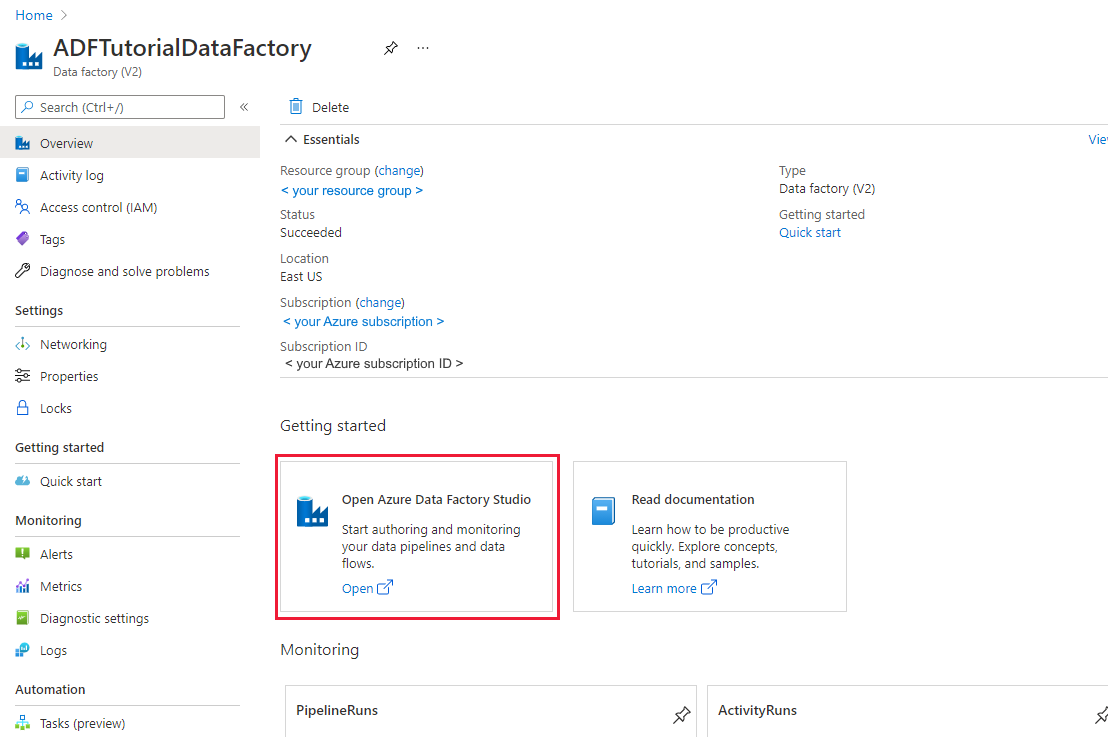
Una vez que finalice la creación, seleccione Ir al recurso para ir a la página de Data Factory. Seleccione el icono Open Azure Data Factory Studio (Abrir Azure Data Factory Studio) para iniciar la aplicación de interfaz de usuario (IU) de Azure Data Factory en una pestaña independiente del explorador.
Crear servicios vinculados
En esta sección, va a crear un servicio vinculado de Databricks. Este servicio vinculado contiene la información de conexión al clúster de Databricks:
Creación de un servicio vinculado de Azure Databricks
En la página principal, cambie a la pestaña Administrar del panel de la izquierda.
Seleccione Servicios vinculados en Conexiones y, después, + Nuevo.
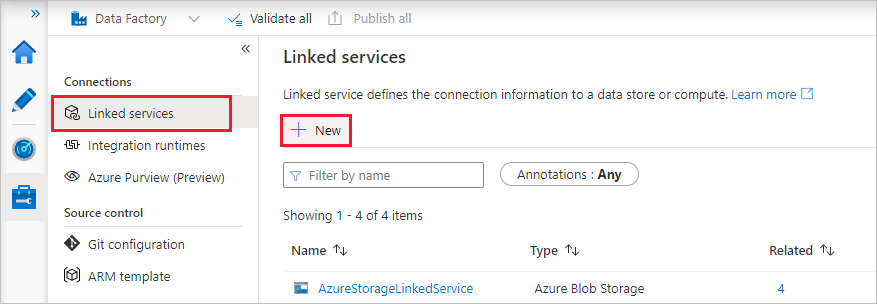
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Compute (Proceso)>Azure Databricks y, luego, seleccione Continue (Continuar).

En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
En Name (Nombre) escriba AzureDatabricks_LinkedService.
Seleccione el área de trabajo de Databricks adecuado en el que ejecutará el cuaderno.
En Select cluster (Seleccionar clúster), seleccione New job cluster (Nuevo clúster de trabajo).
La información de Databrick Workspace URL (Dirección URL del área de trabajo de Databricks) se debe rellenar automáticamente.
En Tipo de autenticación, si selecciona Token de acceso, puede generarlo desde el área de trabajo de Azure Databricks. Puede encontrar los pasos aquí. En Identidad de servicio administrada y Identidad administrada asignada por el usuario, conceda el rol Colaborador a ambas identidades en el menú Control de acceso del recurso de Azure Databricks.
En Versión de clúster, seleccione la versión que desea usar.
En Cluster node type (Tipo de nodo de clúster), seleccione Standard_D3_v2 en la categoría General Purpose (HDD) (Uso general [HDD]) para los fines de este tutorial.
En Workers (Trabajadores), escriba 2.
Seleccione Crear.
Crear una canalización
Seleccione el botón + (Más) y, después, seleccione Canalización en el menú.
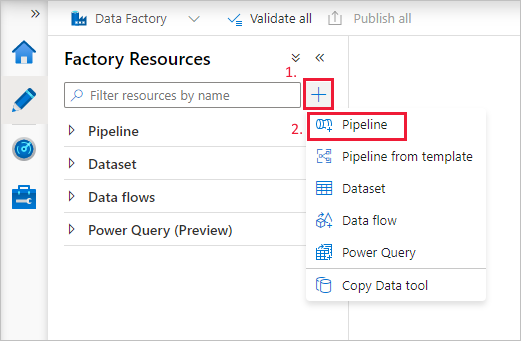
Cree un parámetro para su uso en la canalización. Más adelante va a pasar este parámetro a la actividad Notebook de Databricks. En la canalización vacía, haga seleccione la pestaña Parameters (Parámetros) y New (Nuevo), y asígnele el nombre de "name".
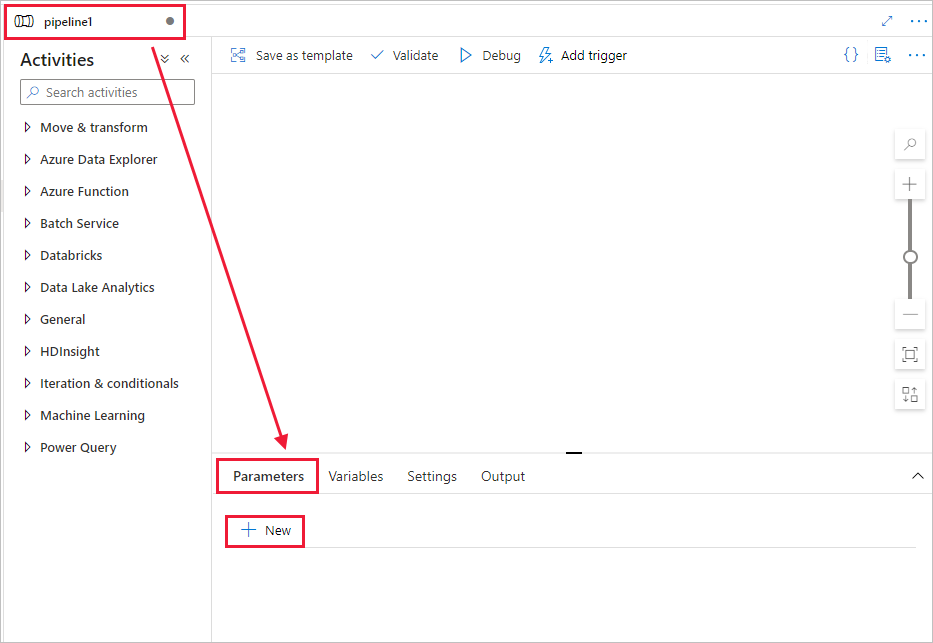
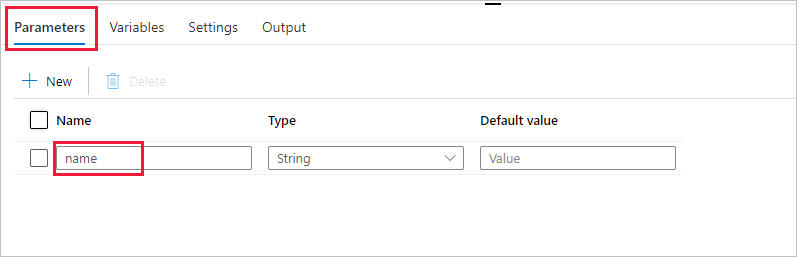
En el cuadro de herramientas Activities (Actividades), expanda Databricks. Arrastre la actividad Notebook del cuadro de herramientas Activities (Actividades) a la superficie del diseñador de canalizaciones.
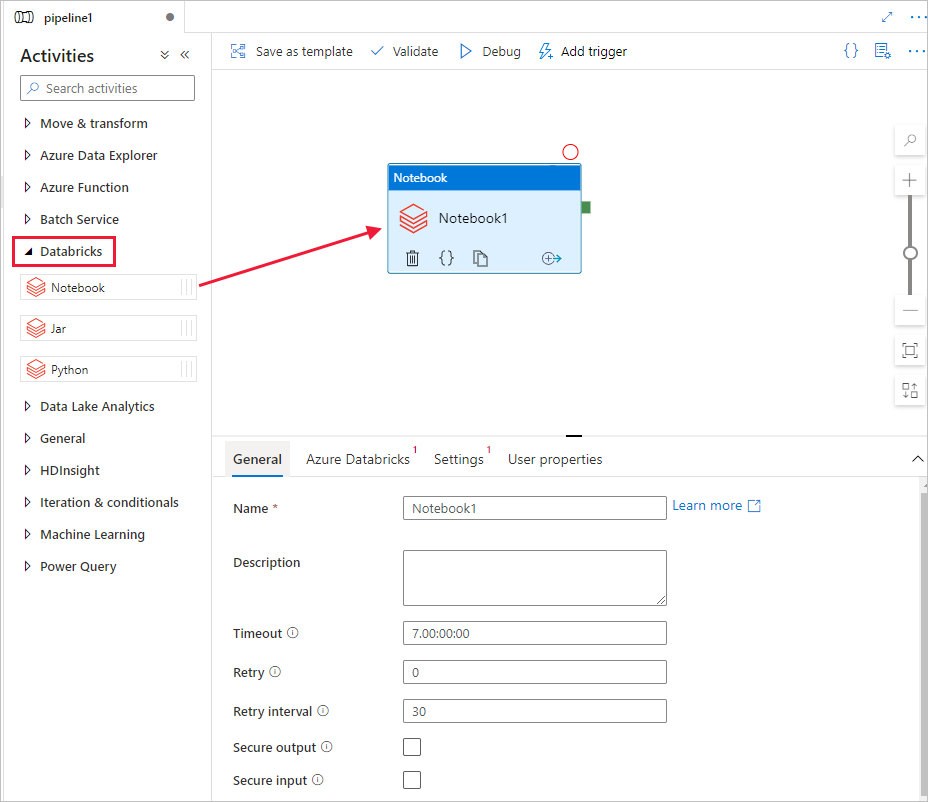
En las propiedades de la ventana de actividad Notebook de Databricks de la parte inferior, realice los pasos siguientes:
Cambie a la pestaña Azure Databricks.
Seleccione AzureDatabricks_LinkedService (que creó en el procedimiento anterior).
Cambie a la pestaña Configuración .
Seleccione una ruta de acceso de cuaderno para Databricks. Vamos a crear un cuaderno y especifique aquí la ruta de acceso. Para obtener la ruta de acceso del cuaderno, siga los pasos siguientes.
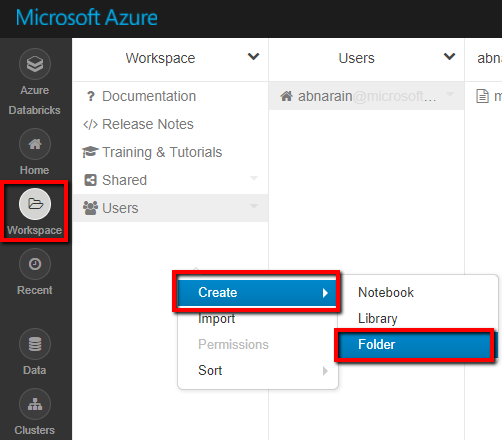
Inicie el área de trabajo de Azure Databricks.
Cree una carpeta en el área de trabajo y llámela adftutorial.
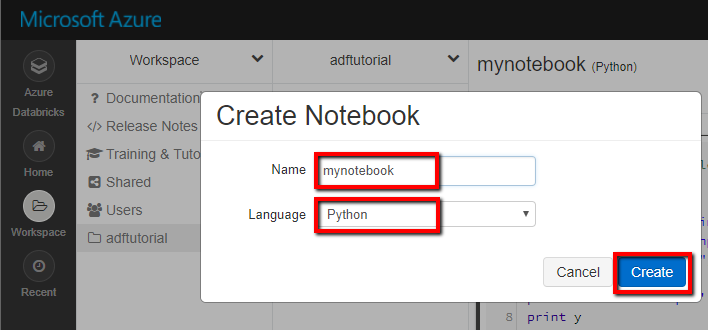
Captura de pantalla que muestra cómo crear un cuaderno. (Python). Vamos a llamarle mynotebook, en la carpeta adftutorial. Haga clic en Crear.

En el cuaderno "mynotebook" recién creado, agregue el código siguiente:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)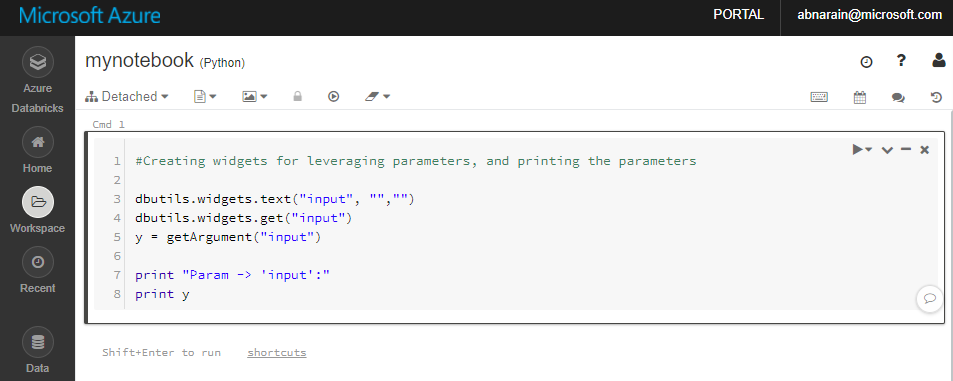
La ruta de acceso del cuaderno en este caso es /adftutorial/mynotebook.
Vuelva a la herramienta de creación de interfaz de usuario de Data Factory. Vaya a la pestaña Configuración en la actividad Notebook1.
a. Agregue un parámetro a la actividad Notebook. Utilice el mismo parámetro que se ha agregado antes a la canalización.
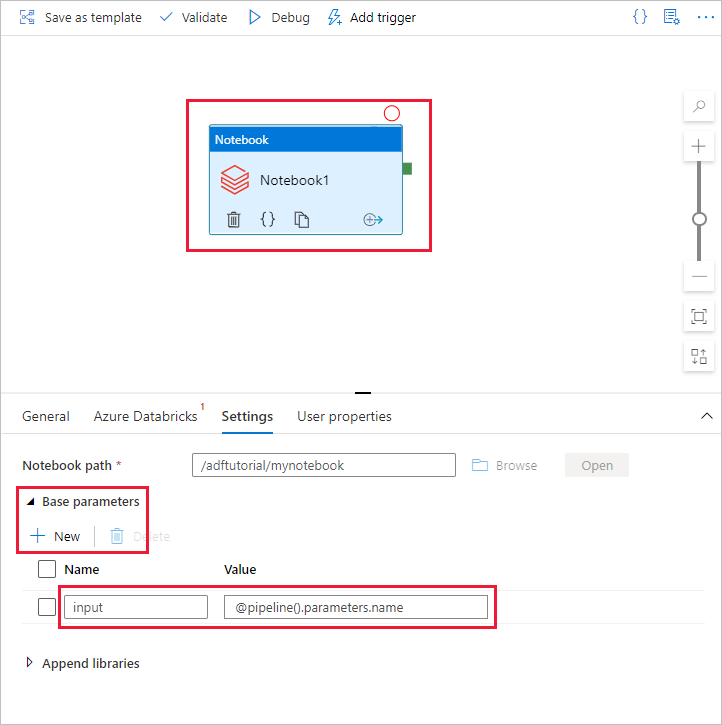
b. Denomine input al parámetro y proporcione el valor como expresión @pipeline().parameters.name.
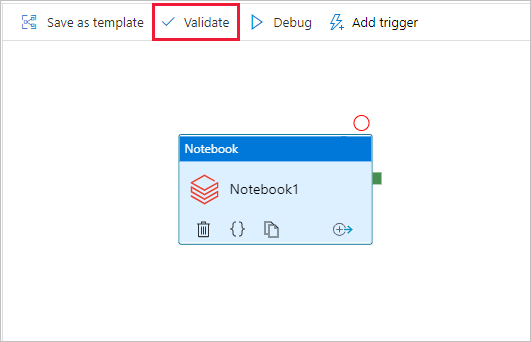
Para comprobar la canalización, seleccione el botón Validate (Comprobar) en la barra de herramientas. Para cerrar la ventana de validación, seleccione el botón Cerrar.
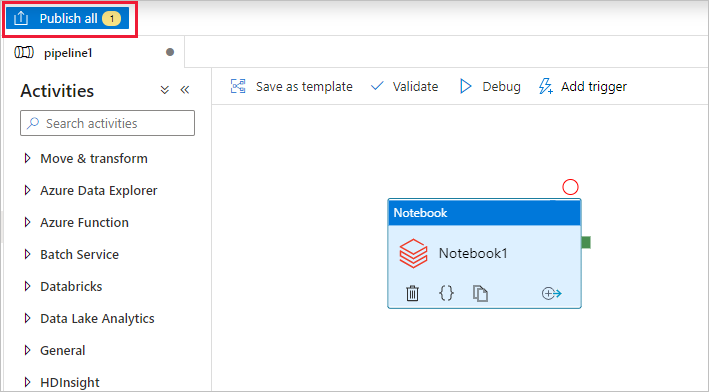
Seleccione Publicar todo. La interfaz de usuario de Data Factory permite publicar entidades (servicios vinculados y canalizaciones) en el servicio Azure Data Factory.
Desencadenamiento de una ejecución de la canalización
Seleccione Agregar desencadenador en la barra de herramientas y, después, Trigger Now (Desencadenar ahora).
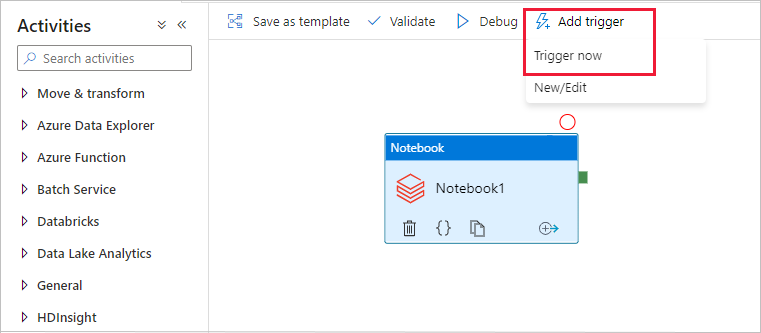
En el cuadro de diálogo Ejecución de canalización se solicita el parámetro name. Utilice /path/filename como parámetro aquí. Seleccione Aceptar.
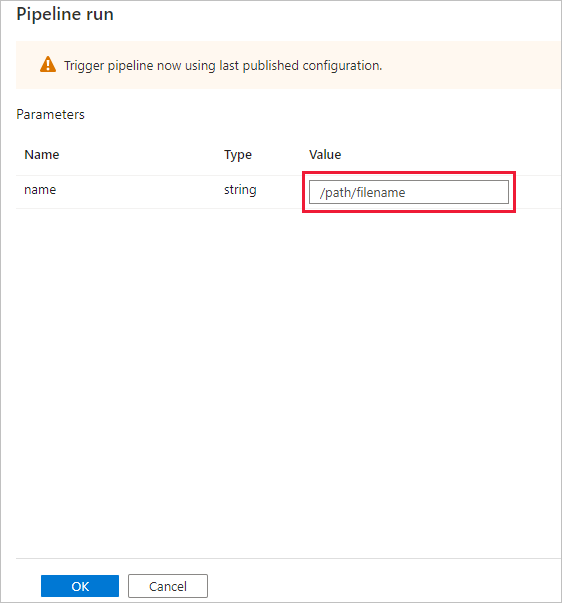
Supervisión de la ejecución de la canalización
Vaya a la pestaña Monitor (Supervisar). Confirme que ve una ejecución de canalización. Se tarda aproximadamente entre 5 y 8 minutos crear un clúster de trabajo de Databricks, donde se ejecuta el cuaderno.
Seleccione Actualizar periódicamente para comprobar el estado de la ejecución de canalización.
Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, seleccione el vínculo pipeline1 en la columna Nombre de canalización.
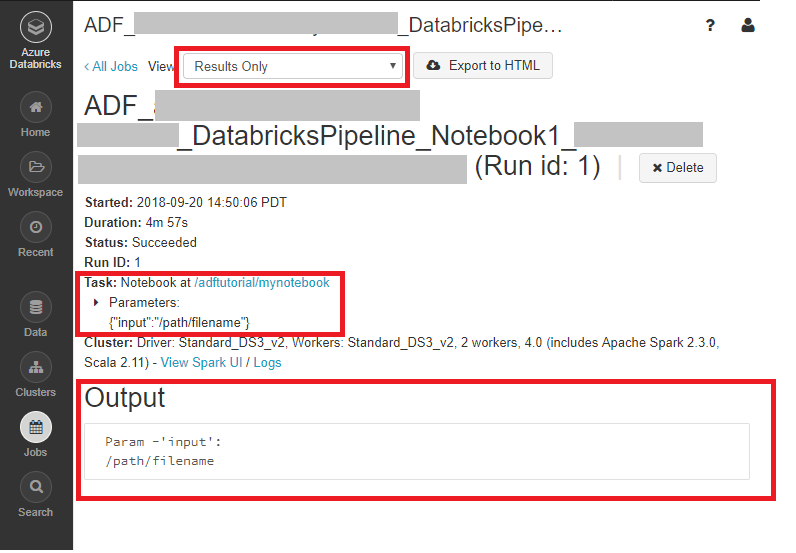
En la página Ejecuciones de actividad, seleccione Salida en la columna Nombre de la actividad para ver la salida de cada actividad y puede encontrar el vínculo a los registros de Databricks en el panel Salida para obtener registros de Spark más detallados.
Para volver a la vista de ejecuciones de canalización, seleccione el vínculo Todas las ejecuciones de la canalización en el menú de la ruta de navegación de la parte superior.
Comprobación del resultado
Puede iniciar sesión en el área de trabajo de Azure Databricks, ir a Clusters (Clústeres) y ver el estado del trabajo como ejecución pendiente, en ejecución o finalizado.
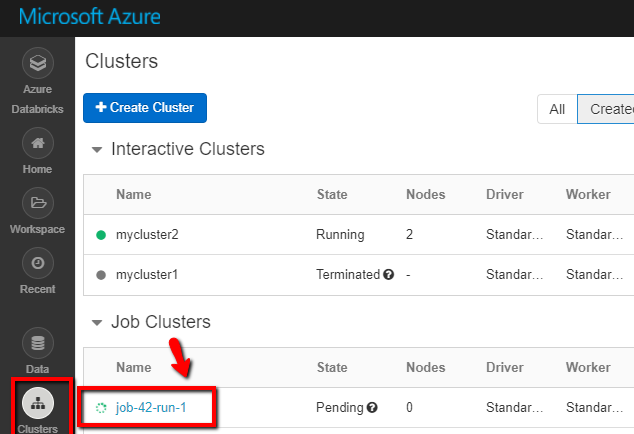
Puede hacer clic en el nombre del trabajo y desplazarse para ver más detalles. Si la ejecución se realiza correctamente, puede validar los parámetros pasados y la salida del cuaderno de Python.
Contenido relacionado
La canalización de este ejemplo desencadena una actividad Notebook de Databricks y le pasa un parámetro. Ha aprendido a:
Creación de una factoría de datos.
Creación de una canalización que utiliza la actividad Notebook de Databricks.
Desencadenamiento de una ejecución de la canalización
Supervisión de la ejecución de la canalización
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de